Recognition: unknown
Modulation Consistency-based Contrastive Learning for Self-Supervised Automatic Modulation Classification
Pith reviewed 2026-05-13 05:23 UTC · model grok-4.3
The pith
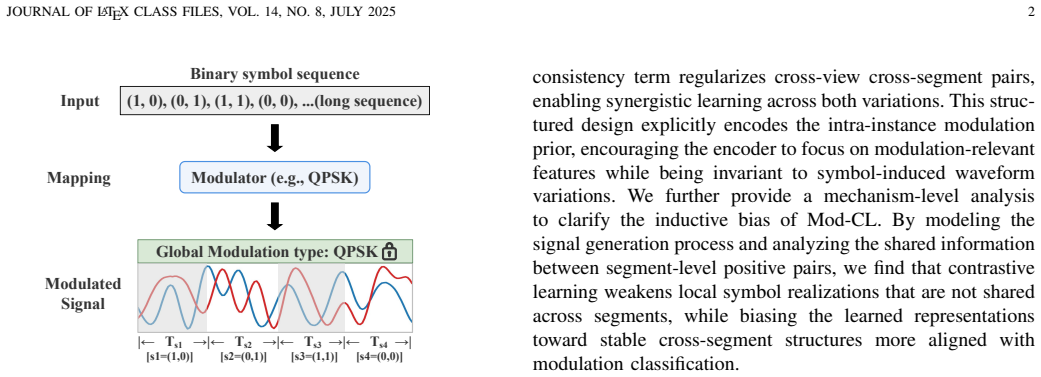
Mod-CL learns shared modulation types from unlabeled radio signals by contrasting different temporal segments of the same instance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
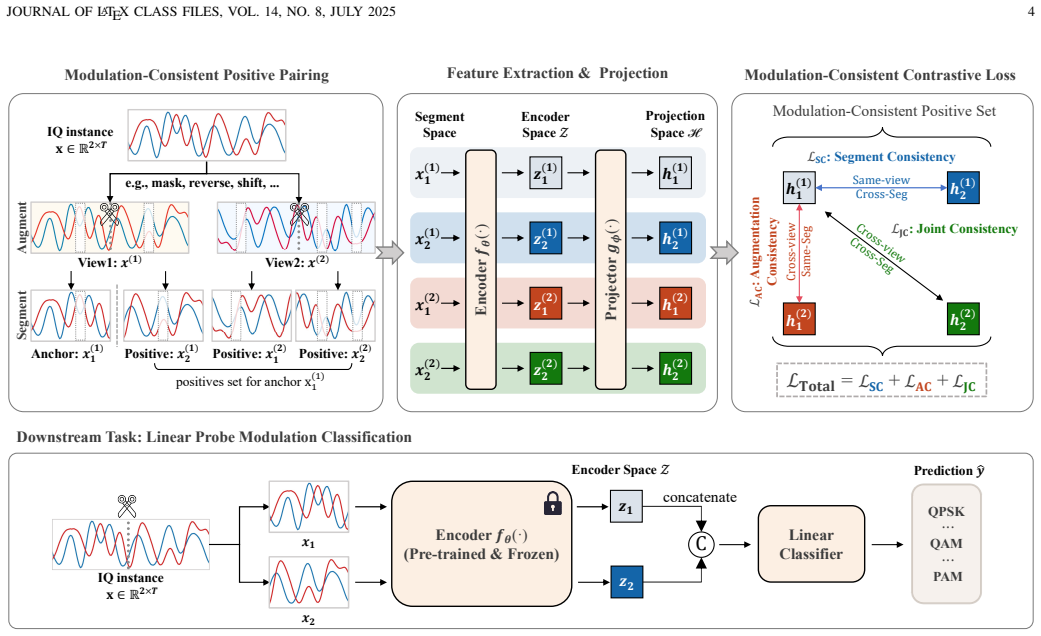
Intra-instance modulation consistency is a task-aware prior in which different temporal segments of one signal instance preserve the same modulation type while varying in waveform details, channel effects, and noise. Mod-CL exploits this by sampling positive pairs from segmented views of the identical instance, combined with augmentations, inside a contrastive loss that avoids intra-instance supervisory conflicts and forces the encoder to retain only the invariant modulation information.
What carries the argument
The intra-instance modulation consistency prior together with the Mod-CL contrastive objective that constructs positive pairs from temporal segments of the same signal.
If this is right
- Mod-CL produces representations that outperform existing self-supervised baselines on RadioML datasets for automatic modulation classification.
- The gains are largest when only a small fraction of labels is available for the final linear probe.
- The learned features suppress entanglement with symbol, channel, and noise variations compared with task-agnostic SSL methods.
- A single pretraining stage on unlabeled data yields improved downstream accuracy without changes to the classifier architecture.
Where Pith is reading between the lines
- The same segment-consistency idea could be tested on other time-series classification problems where intra-instance labels remain constant, such as speech or vibration analysis.
- If the prior generalizes, it would reduce reliance on simulated channel models by allowing direct use of real over-the-air recordings for pretraining.
- One could measure whether the contrastive objective also improves robustness to unseen modulation variants or new noise distributions not present in RadioML.
Load-bearing premise
Different temporal segments of the same transmitted signal always share the identical modulation type and differ only in unrelated nuisance factors such as noise or channel effects.
What would settle it
Run Mod-CL on a dataset where positive pairs are deliberately drawn from segments carrying different modulations; if linear probing accuracy then falls to or below that of standard augmentation-based contrastive baselines, the utility of the consistency prior is refuted.
Figures




read the original abstract
Deep learning-based AMC methods have achieved remarkable performance, but their practical deployment remains constrained by the high cost of labeled data. Although self-supervised learning (SSL) reduces the reliance on labels, existing SSL-based AMC methods often rely on task-agnostic pretext objectives misaligned with modulation classification, leading to representations entangled with nuisance factors such as symbol, channel, and noise. In this paper, we identify intra-instance modulation consistency as a task-aware structural prior, whereby different temporal segments of the same signal may differ in waveform while preserving the same modulation type, thus providing a principled cue for task-aligned self-supervision. Based on this prior, we propose Mod-CL, a Modulation consistency-based Contrastive Learning framework that constructs positive pairs from different temporal segments of the same signal instance, to encourage the model to learn shared modulation information while suppressing nuisance variations. We further develop a contrastive objective tailored to Mod-CL, which jointly exploits temporal segmentation and data augmentation to pull together views sharing the same modulation semantics while avoiding supervisory conflicts within each signal instance. Extensive experiments on RadioML datasets show that Mod-CL consistently outperforms strong baselines, especially in low-label regimes, achieving substantial improvements in linear probing accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Mod-CL, a self-supervised contrastive learning framework for automatic modulation classification (AMC). It introduces intra-instance modulation consistency as a task-aware prior, forming positive pairs from different temporal segments of the same RadioML-style signal instance. A tailored contrastive objective combines this segmentation with data augmentation to encourage learning of shared modulation semantics while suppressing nuisance factors such as channel and noise. The paper reports that Mod-CL outperforms strong baselines on RadioML datasets, with particularly strong gains in low-label regimes via linear probing accuracy.
Significance. If the central claim holds and the method successfully achieves nuisance-invariant representations aligned with modulation classification, this could meaningfully advance label-efficient SSL approaches for AMC. The use of a domain-specific structural prior (modulation consistency) rather than generic pretext tasks is a clear strength, offering a more principled alternative to existing SSL-AMC methods and potentially improving robustness in practical wireless scenarios with scarce labels.
major comments (1)
- Section 3 (Method): The positive-pair construction from temporal segments of the same instance (detailed around the description of Mod-CL) assumes these segments differ primarily in waveform while sharing modulation type. However, under the standard RadioML signal model, such segments share identical channel realizations (fading, phase offset) and exhibit correlated noise. The paper invokes 'data augmentation' to jointly exploit segmentation, but does not specify whether independent per-view channel randomization (e.g., distinct fading or phase draws) is applied to each segment. Without this, the contrastive pull provides no explicit gradient signal for invariance to channel/noise, which is load-bearing for the claimed suppression of nuisance factors and the reported linear-probing gains in low-label regimes.
minor comments (2)
- Abstract: The claims of 'substantial improvements' and 'consistent outperformance' would be strengthened by including at least one or two key quantitative results (e.g., accuracy deltas on specific RadioML datasets and label fractions) to allow immediate assessment of effect size.
- Notation and figures: Ensure all augmentation operations (segmentation, noise addition, etc.) are explicitly labeled in the framework diagram and that the contrastive loss formulation (likely Eq. in Section 3) clearly distinguishes the positive-pair sampling strategy from standard SimCLR-style objectives.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of our work, as well as for the detailed major comment. We address the point below and will incorporate the necessary clarification in the revised manuscript.
read point-by-point responses
-
Referee: Section 3 (Method): The positive-pair construction from temporal segments of the same instance (detailed around the description of Mod-CL) assumes these segments differ primarily in waveform while sharing modulation type. However, under the standard RadioML signal model, such segments share identical channel realizations (fading, phase offset) and exhibit correlated noise. The paper invokes 'data augmentation' to jointly exploit segmentation, but does not specify whether independent per-view channel randomization (e.g., distinct fading or phase draws) is applied to each segment. Without this, the contrastive pull provides no explicit gradient signal for invariance to channel/noise, which is load-bearing for the claimed suppression of nuisance factors and the reported linear-probing gains in low-label regimes.
Authors: We appreciate this observation and agree that the current description in Section 3 lacks sufficient detail on the augmentation pipeline for the positive pairs. In the revised version, we will explicitly state that independent data augmentations—including distinct channel realizations such as independently drawn fading coefficients, phase offsets, and noise—are applied to each temporal segment. This ensures the contrastive objective generates gradients that promote invariance to channel and noise variations while aligning on shared modulation semantics. We will also include a brief description of the augmentation implementation to make this aspect unambiguous. revision: yes
Circularity Check
No circularity: Mod-CL follows from stated signal prior without reduction to inputs
full rationale
The paper grounds its method in the observable property that temporal segments of one signal instance share modulation type while differing in waveform details. It then defines positive pairs for contrastive learning directly from this prior and augments with standard data transforms. No equation or claim reduces the learned representation or objective back to a fitted parameter, self-citation chain, or renamed input; the contrastive loss is a standard InfoNCE variant applied to the constructed pairs. Experiments on RadioML supply independent empirical checks rather than tautological validation. The derivation therefore remains self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different temporal segments of the same signal instance share the same modulation type while differing in waveform, symbol, channel, and noise.
Reference graph
Works this paper leans on
-
[1]
Revolution of wireless signal recognition for 6g: Recent advances, challenges and future directions,
H. Zhang, F. Zhou, H. Du, Q. Wu, and C. Yuen, “Revolution of wireless signal recognition for 6g: Recent advances, challenges and future directions,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 3521–3563, 2026
work page 2026
-
[2]
Recent advances in automatic modulation classification technology: Methods, results, and prospects,
Q. Zheng, X. Tian, L. Yu, A. Elhanashi, and S. Saponara, “Recent advances in automatic modulation classification technology: Methods, results, and prospects,”International Journal of Intelligent Systems, vol. 2025, no. 1, p. 4067323, 2025
work page 2025
-
[3]
Boosting robustness in automatic modulation recognition for wireless communications,
Y . Zhao, Y . Wang, C. Zhang, C. Li, Z. Xiong, L. Zhu, and D. Niyato, “Boosting robustness in automatic modulation recognition for wireless communications,”IEEE Transactions on Cognitive Communications and Networking, vol. 11, no. 3, pp. 1635–1648, 2025
work page 2025
-
[4]
A hybrid approach for cross-dataset modulation recognition of wireless inter- ference,
Z. Zhang, H. Li, Y . Li, Z. Chen, S. Wang, and T. Luo, “A hybrid approach for cross-dataset modulation recognition of wireless inter- ference,”IEEE Transactions on Communications, vol. 73, no. 12, pp. 13 677–13 690, 2025
work page 2025
-
[5]
Deep learning models for wireless signal classification with distributed low- cost spectrum sensors,
S. Rajendran, W. Meert, D. Giustiniano, V . Lenders, and S. Pollin, “Deep learning models for wireless signal classification with distributed low- cost spectrum sensors,”IEEE Transactions on Cognitive Communica- tions and Networking, vol. 4, no. 3, pp. 433–445, 2018
work page 2018
-
[6]
A ultra-low cost and accurate amc algorithm and its hardware implementation,
Y . Zhao, T. Deng, B. Gavin, E. A. Ball, and L. Seed, “A ultra-low cost and accurate amc algorithm and its hardware implementation,”IEEE Open Journal of the Computer Society, vol. 6, pp. 460–467, 2025
work page 2025
-
[7]
Contrastive self- supervised clustering for specific emitter identification,
X. Hao, Z. Feng, R. Liu, S. Yang, L. Jiao, and R. Luo, “Contrastive self- supervised clustering for specific emitter identification,”IEEE Internet of Things Journal, vol. 10, no. 23, pp. 20 803–20 818, 2023
work page 2023
-
[8]
Learn to defend: Adversarial multi-distillation for automatic modulation recognition models,
Z. Chen, Z. Wang, D. Xu, J. Zhu, W. Shen, S. Zheng, Q. Xuan, and X. Yang, “Learn to defend: Adversarial multi-distillation for automatic modulation recognition models,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 3690–3702, 2024
work page 2024
-
[9]
Generalized automatic modulation classification for ofdm systems under unseen synthetic channels,
S. Huang, J. He, Z. Yang, Y . Chen, S. Chang, Y . Zhang, and Z. Feng, “Generalized automatic modulation classification for ofdm systems under unseen synthetic channels,”IEEE Transactions on Wireless Com- munications, vol. 23, no. 9, pp. 11 931–11 941, 2024
work page 2024
-
[10]
X. Yan, X. Zhong, H.-C. Wu, P. Yang, Q. Wang, and Y . Chen, “Automatic composite-modulation classification using cyclic-paw-print features for cognitive aerospace communications,”IEEE Transactions on Communications, vol. 72, no. 9, pp. 5486–5502, 2024
work page 2024
-
[11]
Online hybrid likelihood based modulation classification us- ing multiple sensors,
B. Dulek, “Online hybrid likelihood based modulation classification us- ing multiple sensors,”IEEE Transactions on Wireless Communications, vol. 16, no. 8, pp. 4984–5000, 2017
work page 2017
-
[12]
A likelihood-based algo- rithm for blind identification of qam and psk signals,
D. Zhu, V . J. Mathews, and D. H. Detienne, “A likelihood-based algo- rithm for blind identification of qam and psk signals,”IEEE Transactions on Wireless Communications, vol. 17, no. 5, pp. 3417–3430, 2018
work page 2018
-
[13]
Deep learning for modulation recognition: A survey with a demonstration,
R. Zhou, F. Liu, and C. W. Gravelle, “Deep learning for modulation recognition: A survey with a demonstration,”IEEE Access, vol. 8, pp. 67 366–67 376, 2020
work page 2020
-
[14]
Automatic modulation classification: A deep architecture survey,
T. Huynh-The, Q.-V . Pham, T.-V . Nguyen, T. T. Nguyen, R. Ruby, M. Zeng, and D.-S. Kim, “Automatic modulation classification: A deep architecture survey,”IEEE Access, vol. 9, pp. 142 950–142 971, 2021
work page 2021
-
[15]
C. Xiao, S. Yang, Z. Feng, and L. Jiao, “Mclhn: Toward automatic modulation classification via masked contrastive learning with hard negatives,”IEEE Transactions on Wireless Communications, vol. 23, no. 10, pp. 14 304–14 319, 2024
work page 2024
-
[16]
W. Kong, X. Jiao, Y . Xu, B. Zhang, and Q. Yang, “A transformer-based contrastive semi-supervised learning framework for automatic modula- tion recognition,”IEEE Transactions on Cognitive Communications and Networking, vol. 9, no. 4, pp. 950–962, 2023
work page 2023
-
[17]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inProceedings of the 37th International Conference on Machine Learning, H. D. III and A. Singh, Eds., 2020, pp. 1597–1607
work page 2020
-
[18]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 16 000–16 009
work page 2022
-
[19]
Self-contrastive learning based semi-supervised radio modulation classification,
D. Liu, P. Wang, T. Wang, and T. Abdelzaher, “Self-contrastive learning based semi-supervised radio modulation classification,” inMILCOM 2021 - 2021 IEEE Military Communications Conference (MILCOM), 2021, pp. 777–782
work page 2021
-
[20]
Y . Shi, H. Xu, Y . Zhang, Z. Qi, and D. Wang, “Gaf-mae: A self- supervised automatic modulation classification method based on gramian angular field and masked autoencoder,”IEEE Transactions on Cognitive Communications and Networking, vol. 10, no. 1, pp. 94–106, 2024
work page 2024
-
[21]
Predicting spectral information for self-supervised signal classification,
Y . Xu, S. W. 0001, H. Xing, C. Wang, D. Quan, R. Y . 0038, D. Zhao, and L. Mei, “Predicting spectral information for self-supervised signal classification,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2025, Montreal, Canada, August 16-22, 2025, 2025, pp. 6758–6766
work page 2025
-
[22]
An introduction to deep learning for the physical layer,
T. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer,”IEEE Transactions on Cognitive Communications and Networking, vol. 3, no. 4, pp. 563–575, 2017
work page 2017
-
[23]
Rml22: Realistic dataset generation for wireless modulation classification,
V . Sathyanarayanan, P. Gerstoft, and A. E. Gamal, “Rml22: Realistic dataset generation for wireless modulation classification,”IEEE Trans- actions on Wireless Communications, vol. 22, no. 11, pp. 7663–7675, 2023
work page 2023
-
[24]
S. S. Haykin,Digital communications. Wiley New York, 1988
work page 1988
-
[25]
Radio machine learning dataset generation with gnu radio,
T. J. O’shea and N. West, “Radio machine learning dataset generation with gnu radio,” inProceedings of the GNU radio conference, vol. 1, no. 1, 2016
work page 2016
-
[26]
Convolutional radio modula- tion recognition networks,
T. J. O’Shea, J. Corgan, and T. C. Clancy, “Convolutional radio modula- tion recognition networks,” inInternational conference on engineering applications of neural networks. Springer, 2016, pp. 213–226
work page 2016
-
[27]
V . D. Orlic and M. L. Dukic, “Automatic modulation classification algorithm using higher-order cumulants under real-world channel con- ditions,”IEEE Communications Letters, vol. 13, no. 12, pp. 917–919, 2009
work page 2009
-
[28]
Automatic modulation classification of overlapped sources using multiple cumulants,
S. Huang, Y . Yao, Z. Wei, Z. Feng, and P. Zhang, “Automatic modulation classification of overlapped sources using multiple cumulants,”IEEE Transactions on Vehicular Technology, vol. 66, no. 7, pp. 6089–6101, 2017
work page 2017
-
[29]
Performance study of cyclostationary based digital modulation classification schemes,
U. Satija, M. S. Manikandan, and B. Ramkumar, “Performance study of cyclostationary based digital modulation classification schemes,” in2014 9th International Conference on Industrial and Information Systems (ICIIS), 2014, pp. 1–5
work page 2014
-
[30]
T. V . R. O. C ˆamara, A. D. L. Lima, B. M. M. Lima, A. I. R. Fontes, A. D. M. Martins, and L. F. Q. Silveira, “Automatic modulation classification architectures based on cyclostationary features in impulsive environments,”IEEE Access, vol. 7, pp. 138 512–138 527, 2019
work page 2019
-
[31]
Cnn-based automatic modulation classification under phase imperfections,
T. K. Oikonomou, N. G. Evgenidis, D. G. Nixarlidis, D. Tyrovolas, S. A. Tegos, P. D. Diamantoulakis, P. G. Sarigiannidis, and G. K. Karagiannidis, “Cnn-based automatic modulation classification under phase imperfections,”IEEE Wireless Communications Letters, vol. 13, no. 5, pp. 1508–1512, 2024
work page 2024
-
[32]
Signet: A novel deep learning framework for radio signal classification,
Z. Chen, H. Cui, J. Xiang, K. Qiu, L. Huang, S. Zheng, S. Chen, Q. Xuan, and X. Yang, “Signet: A novel deep learning framework for radio signal classification,”IEEE Transactions on Cognitive Communi- cations and Networking, vol. 8, no. 2, pp. 529–541, 2022
work page 2022
-
[33]
Real-time radio technology and modulation classification via an lstm auto-encoder,
Z. Ke and H. Vikalo, “Real-time radio technology and modulation classification via an lstm auto-encoder,”IEEE Transactions on Wireless Communications, vol. 21, no. 1, pp. 370–382, 2022
work page 2022
-
[34]
Mcformer: A transformer based deep neural network for automatic modulation classification,
S. Hamidi-Rad and S. Jain, “Mcformer: A transformer based deep neural network for automatic modulation classification,” in2021 IEEE Global Communications Conference (GLOBECOM), 2021, pp. 1–6
work page 2021
-
[35]
Amc-transformer: Automatic modulation classification based on enhanced attention model,
Y . Xu, “Amc-transformer: Automatic modulation classification based on enhanced attention model,”INFOCOMMUNICATIONS JOURNAL, vol. 17, no. 4, pp. 32–40, 2025
work page 2025
-
[36]
Y . Li, X. Shi, H. Tan, Z. Zhang, X. Yang, and F. Zhou, “Multi- representation domain attentive contrastive learning based unsupervised automatic modulation recognition,”Nature Communications, vol. 16, no. 1, p. 5951, 2025
work page 2025
-
[37]
Aflnet: Auxiliary feature learning-guided cross-channel automatic modulation classification,
H. Xing, S. Wang, C. Wang, D. Quan, H. Mo, L. Mei, H. Zhou, and L. Jiao, “Aflnet: Auxiliary feature learning-guided cross-channel automatic modulation classification,”IEEE Transactions on Communi- cations, vol. 73, no. 12, pp. 13 519–13 534, 2025
work page 2025
-
[38]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 9729–9738
work page 2020
-
[39]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Sigda: A superimposed domain adaptation framework for automatic modulation classification,
S. Wang, H. Xing, C. Wang, H. Zhou, B. Hou, and L. Jiao, “Sigda: A superimposed domain adaptation framework for automatic modulation classification,”IEEE Transactions on Wireless Communications, vol. 23, no. 10, pp. 13 159–13 172, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.