Recognition: no theorem link
Incentivizing Truthfulness and Collaborative Fairness in Bayesian Learning
Pith reviewed 2026-05-13 05:48 UTC · model grok-4.3
The pith
A mechanism pairing semivalues with a validation set unknown to sources ensures both fairness and truthfulness at equilibrium in Bayesian collaborative learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
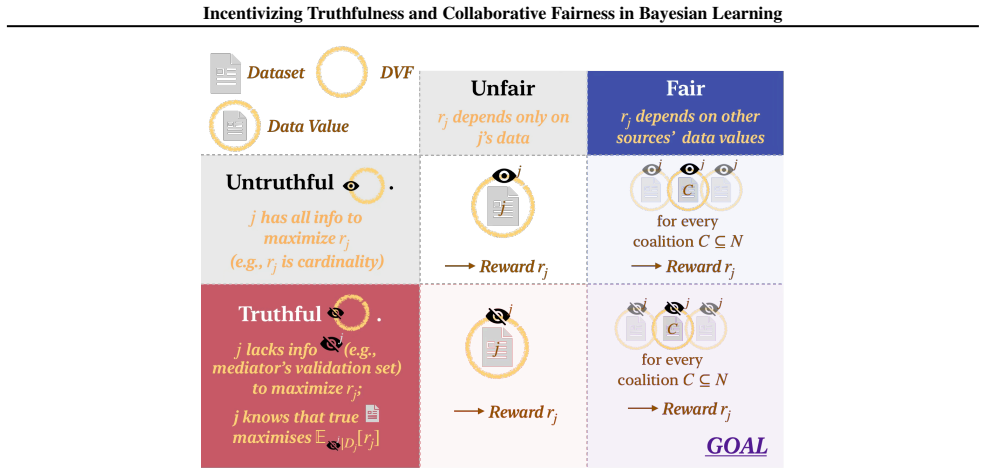
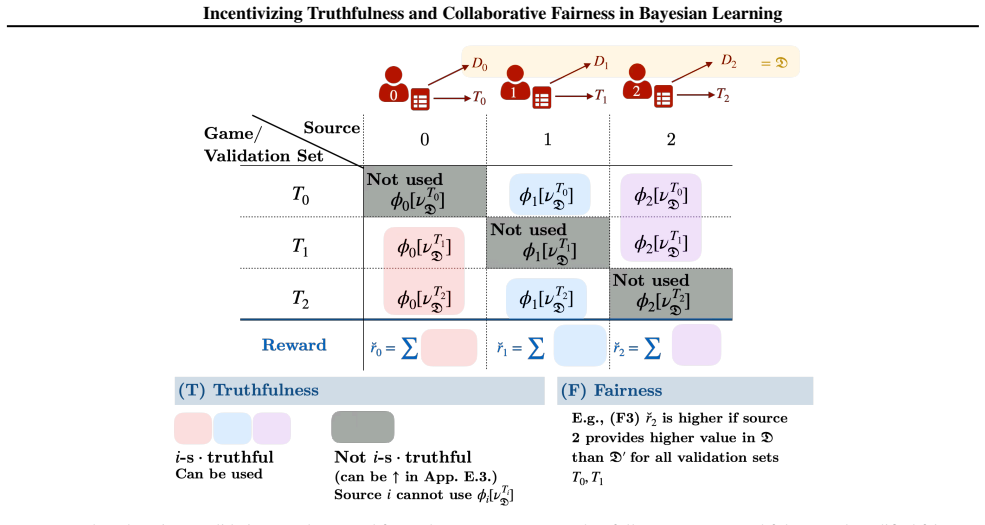
The paper presents the first mechanism that provably ensures collaborative fairness and incentivizes truthfulness at equilibrium for Bayesian models. It achieves this by combining semivalues, which guarantee fair reward allocation based on data contributions, with a truthful data valuation function that depends on a validation set unknown to the sources. An additional condition is shown to hold under which each source maximizes its expected data values across coalitions and semivalues precisely by submitting a dataset that captures its true knowledge.
What carries the argument
The mechanism that integrates semivalues for fair allocation with a data valuation function based on performance against a validation set kept secret from all sources.
If this is right
- Truthful data submission becomes the unique equilibrium strategy for reward maximization.
- Rewards are allocated strictly according to true marginal contributions rather than manipulated submissions.
- Collaborative models reach higher test accuracy because training data reflects genuine source knowledge.
- When budgets are limited the mechanism admits relaxed fairness notions while preserving the truthfulness incentive.
- Without a validation set the framework can fall back to budget-constrained or approximate fairness conditions.
Where Pith is reading between the lines
- The same combination of hidden validation and semivalues might stabilize cooperation in non-Bayesian settings if the valuation function is replaced by an appropriate surrogate.
- Running the mechanism on datasets where sources have known conflicting interests would provide a direct test of whether the equilibrium remains at truthful submission.
- If validation data cannot be kept secret, cross-validation among participating sources could serve as a practical proxy worth formal analysis.
Load-bearing premise
A validation set unknown to the sources exists and can measure true knowledge, and sources choose datasets to maximize their expected semivalue rewards.
What would settle it
A controlled experiment in which sources submit duplicated or noisy versions of their data yet receive strictly higher expected rewards under the mechanism than when they submit their true datasets.
Figures















read the original abstract
Collaborative machine learning involves training high-quality models using datasets from a number of sources. To incentivize sources to share data, existing data valuation methods fairly reward each source based on its data submitted as is. However, as these methods do not verify nor incentivize data truthfulness, the sources can manipulate their data (e.g., by submitting duplicated or noisy data) to artificially increase their valuations and rewards or prevent others from benefiting. This paper presents the first mechanism that provably ensures (F) collaborative fairness and incentivizes (T) truthfulness at equilibrium for Bayesian models. Our mechanism combines semivalues (e.g., Shapley value), which ensure fairness, and a truthful data valuation function (DVF) based on a validation set that is unknown to the sources. As semivalues are influenced by others' data, we introduce an additional condition to prove that a source can maximize its expected data values in coalitions and semivalues by submitting a dataset that captures its true knowledge. Additionally, we discuss the implications and suitable relaxations of (F) and (T) when the mediator has a limited budget for rewards or lacks a validation set. Our theoretical findings are validated on synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first mechanism for collaborative Bayesian machine learning that simultaneously guarantees collaborative fairness (F) via semivalues such as the Shapley value and incentivizes truthfulness (T) at equilibrium. It combines semivalues for fair reward allocation with a truthful data valuation function (DVF) that relies on a validation set unknown to the data sources. An additional condition is introduced to prove that sources maximize expected coalition values and semivalue rewards by submitting datasets that capture their true knowledge rather than manipulating data (e.g., via duplication or noise). The paper also discusses relaxations of (F) and (T) under limited mediator budgets or absent validation sets, with theoretical results validated on synthetic and real-world datasets.
Significance. If the central claims hold, the work would represent a meaningful advance in incentivizing honest data sharing for collaborative ML, addressing a practical gap where existing valuation methods permit manipulation that inflates rewards or harms others. The integration of semivalues with an unknown validation set offers a clean theoretical separation between fairness and truthfulness, and the discussion of budget-limited relaxations broadens applicability. Experimental validation on both synthetic and real datasets provides initial evidence of practicality, though the strength depends on the unexamined additional condition.
major comments (2)
- [Abstract and theoretical analysis section] Abstract and the section introducing the additional condition: the truthfulness guarantee at equilibrium is asserted to hold via an 'additional condition' when semivalues depend on other agents' submissions, yet this condition is never explicitly formulated or stated. Without its precise statement, it is impossible to verify whether it holds for standard Bayesian setups (conjugate priors, non-i.i.d. likelihoods) or whether profitable deviations such as duplication remain possible.
- [Theoretical analysis] Proof of equilibrium properties (central claim of (T)): the argument that submitting a dataset capturing 'true knowledge' maximizes expected semivalue rewards relies on the unstated condition and the existence of an unknown validation set. No derivation shows that this condition is necessary or sufficient for Bayesian models, leaving the no-deviation claim unverified and load-bearing for the 'first provable mechanism' assertion.
minor comments (2)
- [Method section] The definition of the truthful data valuation function (DVF) should be given an explicit mathematical formulation (e.g., as an equation) immediately after its introduction rather than relying on descriptive text.
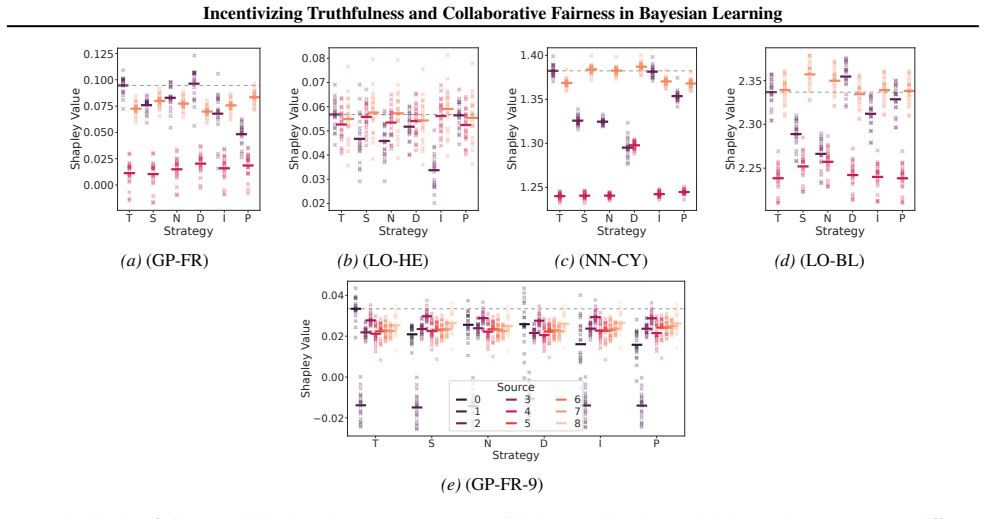
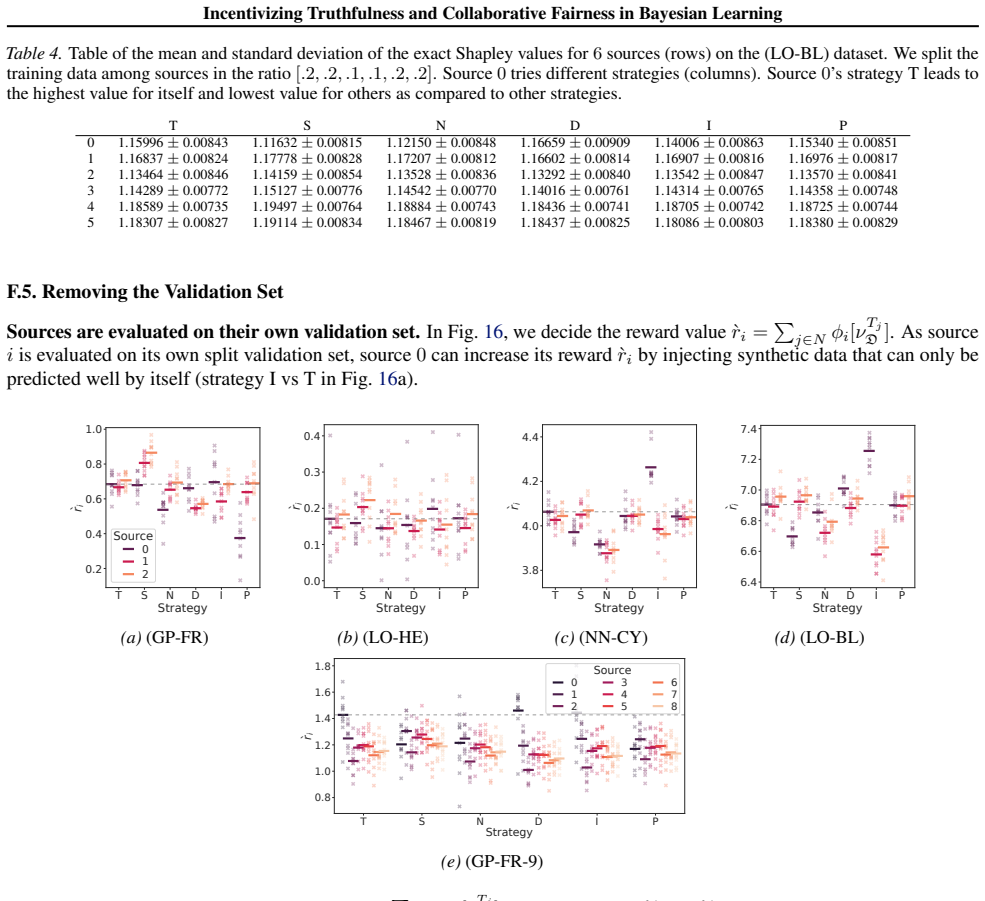
- [Experiments] Experimental figures lack sufficient detail in captions regarding the exact Bayesian model, prior choices, and how the unknown validation set is simulated, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review. We address the two major comments point by point below and will revise the manuscript to improve the explicitness and completeness of the theoretical claims.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis section] Abstract and the section introducing the additional condition: the truthfulness guarantee at equilibrium is asserted to hold via an 'additional condition' when semivalues depend on other agents' submissions, yet this condition is never explicitly formulated or stated. Without its precise statement, it is impossible to verify whether it holds for standard Bayesian setups (conjugate priors, non-i.i.d. likelihoods) or whether profitable deviations such as duplication remain possible.
Authors: We agree that the additional condition was referenced but not stated with sufficient precision or formality. In the revised manuscript we will add an explicit mathematical formulation of the condition immediately after its introduction, together with a short paragraph verifying its satisfaction under conjugate priors and non-i.i.d. likelihoods and confirming that duplication cannot increase expected semivalue rewards. revision: yes
-
Referee: [Theoretical analysis] Proof of equilibrium properties (central claim of (T)): the argument that submitting a dataset capturing 'true knowledge' maximizes expected semivalue rewards relies on the unstated condition and the existence of an unknown validation set. No derivation shows that this condition is necessary or sufficient for Bayesian models, leaving the no-deviation claim unverified and load-bearing for the 'first provable mechanism' assertion.
Authors: We acknowledge that the current proof sketch is too terse. The revised theoretical analysis section will contain a self-contained derivation establishing that the (now explicitly stated) condition is sufficient to guarantee that truthful submission is a dominant strategy for any Bayesian model whose posterior is well-defined; we will also note the cases in which the condition is necessary. This will directly support the central truthfulness claim. revision: yes
Circularity Check
No significant circularity; relies on external validation set and standard semivalue properties
full rationale
The derivation chain uses an external validation set unknown to sources to define the truthful DVF, combined with standard semivalue fairness properties. The additional condition is introduced explicitly to address inter-agent dependencies in semivalues and does not reduce the truthfulness result to a self-definition, fitted parameter, or self-citation chain. No load-bearing step equates the claimed equilibrium to its inputs by construction, and the mechanism remains falsifiable via the validation set. This yields a minor score for the presence of an unverified auxiliary assumption but no circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semivalues (e.g., Shapley value) ensure collaborative fairness when applied to data contributions.
- domain assumption Sources are rational and maximize expected values over coalitions.
invented entities (1)
-
Truthful data valuation function (DVF) based on unknown validation set
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gradient driven rewards to guarantee fairness in collaborative machine learning , author=. Proc. NeurIPS , pages="16104--16117", year=
-
[2]
Collaborative Machine Learning with Incentive-Aware Model Rewards , author=. Proc. ICML
-
[3]
Incentives in private collaborative machine learning , author=. Proc
-
[4]
Mathematics of Operations Research , volume=
Value theory without efficiency , author=. Mathematics of Operations Research , volume=. 1981 , publisher=
work page 1981
-
[5]
Truthful data acquisition via peer prediction , author=. Proc
- [6]
-
[7]
Data-free evaluation of user contributions in federated learning , author=. Proc. WiOpt , pages=. 2021 , organization=
work page 2021
-
[8]
Incentives for federated learning: a hypothesis elicitation approach , author=
-
[9]
Incentivizing Honesty among Competitors in Collaborative Learning and Optimization , author=
-
[10]
Truthful Dataset Valuation by Pointwise Mutual Information , author=
-
[11]
Peer truth serum: incentives for crowdsourcing measurements and opinions , author=
-
[12]
Validation free and replication robust volume-based data valuation , author=. Proc. NeurIPS , volume=
-
[13]
Replication Robust Payoff Allocation in Submodular Cooperative Games , year =
Han, Dongge and Wooldridge, Michael and Rogers, Alex and Ohrimenko, Olga and Tschiatschek, Sebastian , journal =. Replication Robust Payoff Allocation in Submodular Cooperative Games , year =
-
[14]
Trade-off between Payoff and Model Rewards in
Nguyen, Quoc Phong and Low, Bryan Kian Hsiang and Jaillet, Patrick , booktitle =. Trade-off between Payoff and Model Rewards in
-
[15]
Scoring Rules for Continuous Probability Distributions , author=. Management Science , volume=. 1976 , publisher=
work page 1976
-
[16]
Nonparametric scoring rules , author=. Proc. AAAI , volume=
-
[17]
Game-theoretic mechanisms for eliciting accurate information , author=. Proc. IJCAI , year=
-
[18]
Federated Learning: Privacy and Incentive , pages=
Budget-bounded incentives for federated learning , author=. Federated Learning: Privacy and Incentive , pages=. 2020 , publisher=
work page 2020
- [19]
-
[20]
Jia, R. and Dao, D. and Wang, B. and Hubis, F. A. and Hynes, N. and Gurel, N. M. and Li, B. and Zhang, C. and Song, D. and Spanos, C. , booktitle="Proc. Towards efficient data valuation based on the. 2019
work page 2019
-
[21]
ACM Transactions on Economics and Computation , volume=
Surrogate scoring rules , author=. ACM Transactions on Economics and Computation , volume=. 2023 , publisher=
work page 2023
-
[22]
Data-oob: Out-of-bag estimate as a simple and efficient data value , author=. Proc. ICML , pages=. 2023 , organization=
work page 2023
-
[23]
Data Valuation in Machine Learning: “ingredients”, strategies, and open challenges , author=. Proc. IJCAI , pages = "5607--5614", year=
-
[24]
Kwon, Yongchan and Zou, James , booktitle =
-
[25]
ACM Transactions on Intelligent Systems and Technology , volume=
Federated Machine Learning: Concept and Applications , author=. ACM Transactions on Intelligent Systems and Technology , volume=
-
[26]
Sharing and Utilizing Health Data for
-
[27]
Incentivizing the sharing of healthcare data in the
Panagopoulos, Andreas and Minssen, Timo and Sideri, Katerina and Yu, Helen and Compagnucci, Marcelo Corrales , journal=. Incentivizing the sharing of healthcare data in the. 2022 , publisher=
work page 2022
-
[28]
Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data , author=. Scientific reports , volume=. 2020 , publisher=
work page 2020
-
[29]
NVIDIA Technical Blog , author=
Using federated learning to Bridge Data Silos in financial services , url=. NVIDIA Technical Blog , author=. 2022 , month=
work page 2022
-
[30]
Incentive-Aware Federated Learning with Training-Time Model Rewards , author=. Proc. ICLR , year=
-
[31]
Faster Approximation of Probabilistic and Distributional Values via Least Squares , author=. Proc. ICLR , year=
-
[32]
Some properties for probabilistic and multinomial (probabilistic) values on cooperative games , author=. Optimization , volume=. 2016 , publisher=
work page 2016
-
[33]
Logic, game theory and social choice , pages=
Some theoretical reasons for using (regular) semivalues , author=. Logic, game theory and social choice , pages=. 1999 , publisher=
work page 1999
-
[34]
A Value for n -person Games , author=. Contributions to the Theory of Games , editor = "H. W. Kuhn and A. W. Tucker", volume=
- [35]
-
[36]
Hidden trigger backdoor attacks , author=. Proc. AAAI , volume=
-
[37]
Probabilistic Machine Learning: An Introduction , author=. 2022 , publisher=
work page 2022
-
[38]
Variational Learning of inducing variables in sparse
Titsias, Michalis , booktitle=. Variational Learning of inducing variables in sparse
-
[39]
Aarti Singh and Danai Koutra , title =
- [40]
-
[41]
C. E. Rasmussen and C. K. I. Williams. Gaussian Processes for Machine Learning
-
[42]
IEEE Computational Intelligence Magazine , volume=
Hands-on Bayesian neural networks—A tutorial for deep learning users , author=. IEEE Computational Intelligence Magazine , volume=. 2022 , publisher=
work page 2022
-
[43]
Artificial intelligence and statistics , pages=
Deep kernel learning , author=. Artificial intelligence and statistics , pages=. 2016 , organization=
work page 2016
-
[44]
Workshop on Social Computing and User Generated Content, EC-11 , year=
Incentives for answering hypothetical questions , author=. Workshop on Social Computing and User Generated Content, EC-11 , year=
-
[45]
Eliciting informative feedback: The peer-prediction method , author=. Management Science , volume=. 2005 , publisher=
work page 2005
-
[46]
Computational intelligence and neuroscience , volume=
Prediction of heart disease using a combination of machine learning and deep learning , author=. Computational intelligence and neuroscience , volume=. 2021 , publisher=
work page 2021
-
[47]
IEEE 18th International Symposium on Biomedical Imaging (ISBI) , pages=
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis , author=. IEEE 18th International Symposium on Biomedical Imaging (ISBI) , pages=
-
[48]
Hoffman, Matthew D and Gelman, Andrew , journal=. The
- [49]
-
[50]
Communication-efficient learning of deep networks from decentralized data , author=. Proc. AISTATS , pages=
-
[51]
Learning differentially private recurrent language models , author=. Proc. ICLR , year=
-
[52]
International Journal of Hybrid Intelligent Systems , pages=
A framework for learning from distributed data using sufficient statistics and its application to learning decision trees , author=. International Journal of Hybrid Intelligent Systems , pages=. 2004 , publisher=
work page 2004
-
[53]
Fair yet Asymptotically Equal Collaborative Learning , author=. Proc. ICML , year=
-
[54]
Composable Effects for Flexible and Accelerated Probabilistic Programming in NumPyro , author=
-
[55]
Approximating the shapley value without marginal contributions , author=. Proc. AAAI , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.