Recognition: 2 theorem links
· Lean TheoremFew-Shot Synthetic Data Generation with Diffusion Models for Downstream Vision Tasks
Pith reviewed 2026-05-13 06:49 UTC · model grok-4.3
The pith
LoRA-adapted diffusion models generate synthetic images from 20-50 real examples that raise rare-class recall and F1 in vision tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
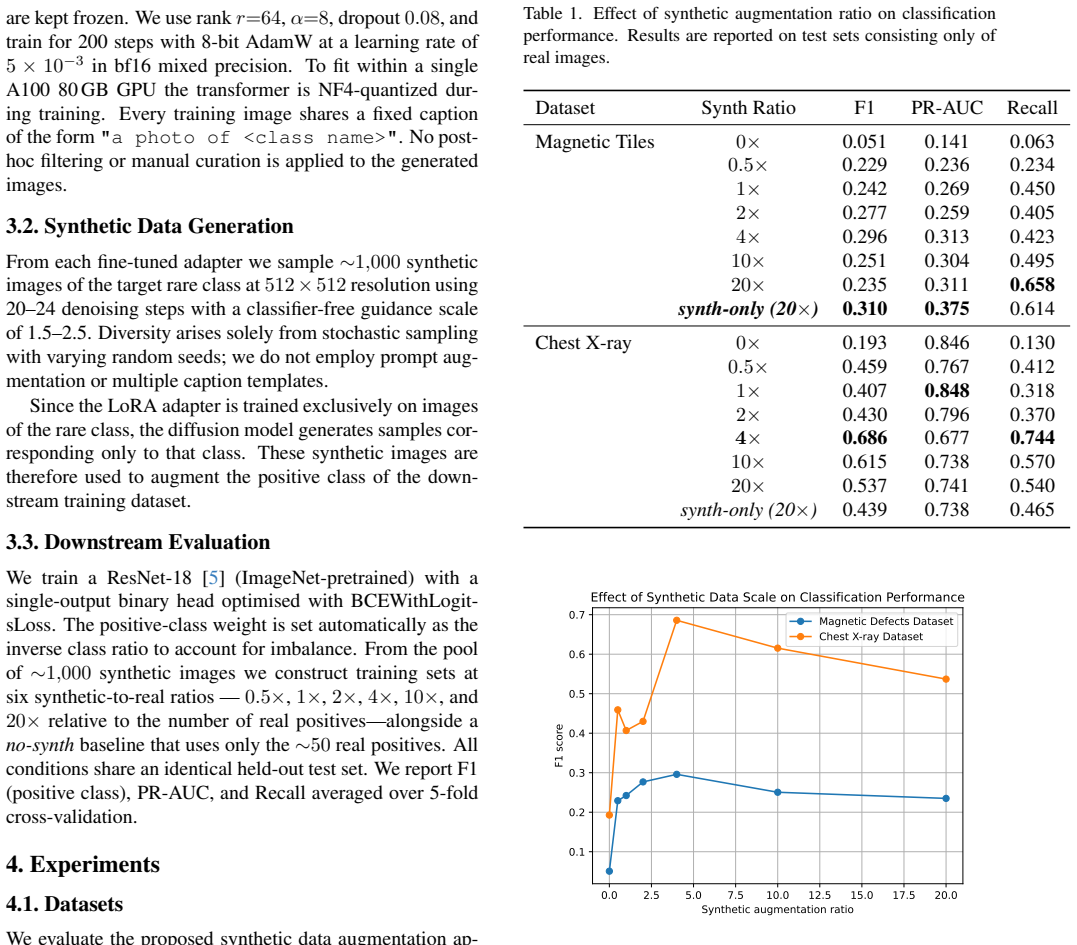
Fine-tuning a LoRA adapter on 20-50 real images of a rare class inside a pretrained diffusion model produces synthetic samples whose addition at moderate ratios to real training data raises rare-class recall and F1 on real-only test sets in both medical and industrial vision tasks.
What carries the argument
LoRA adapter fine-tuned on few real images of a rare class to steer a pretrained diffusion model toward generating useful synthetic training samples.
If this is right
- Moderate synthetic augmentation improves rare-class detection without further real data collection.
- Performance peaks at moderate synthetic-to-real ratios and declines with higher ratios.
- The same pipeline works for both medical pathology classification and industrial defect detection.
- All reported gains are measured on held-out real images, confirming the synthetics aid generalization.
Where Pith is reading between the lines
- If the quality assumption holds, the method could cut the cost of building detectors for rare events in safety-critical settings.
- The optimal mixing ratio may need domain-specific tuning to avoid the observed diminishing returns.
- Similar few-shot LoRA adaptation of generative models could be tested on sequence or tabular data tasks with class imbalance.
Load-bearing premise
The synthetic images must be close enough in quality and distribution to real images that they help rather than harm generalization on real data.
What would settle it
Training with the generated synthetics produces lower rare-class recall or F1 on real test images than training on real data alone.
Figures


read the original abstract
Class imbalance is a persistent challenge in visual recognition, particularly in safety-critical domains where collecting positive examples is expensive and rare events are inherently underrepresented. We propose a lightweight synthetic data augmentation pipeline that fine-tunes a LoRA adapter on as few as 20-50 real images of a rare class and uses a pretrained diffusion model to generate synthetic samples for training. We systematically vary the synthetic-to-real ratio and evaluate the approach across two structurally different domains: chest X-ray pathology classification (NIH ChestX-ray14) and industrial surface crack detection (Magnetic Tile Defect dataset). All evaluations are performed on held-out sets of real images only. Across both domains, synthetic augmentation consistently improves rare-class recall and F1 compared to training with real data alone. Performance improves with moderate synthetic augmentation and shows diminishing returns as the synthetic ratio increases. These results suggest that LoRA-adapted diffusion models provide a simple and scalable mechanism for augmenting rare classes, enabling effective learning in data-scarce scenarios across heterogeneous visual domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight pipeline that fine-tunes a LoRA adapter on 20-50 real images of a rare class and uses a pretrained diffusion model to generate synthetic samples. It evaluates the approach by systematically varying the synthetic-to-real ratio on two domains (NIH ChestX-ray14 pathology classification and Magnetic Tile Defect crack detection), reporting that moderate synthetic augmentation improves rare-class recall and F1 on held-out real test sets relative to real data alone, with diminishing returns at higher ratios.
Significance. If the gains can be attributed to the quality of the generated images rather than increased training volume, the method would offer a practical, low-data way to address class imbalance in safety-critical vision tasks across medical and industrial domains.
major comments (1)
- The experimental protocol varies the synthetic-to-real ratio while holding the real-sample count fixed, so total training-set cardinality grows with the ratio. No control is described that matches total sample count using only real data (e.g., duplication or oversampling of the scarce real examples). Because the central claim attributes performance gains to the distributional fidelity of the LoRA-generated images, the absence of this control leaves the attribution open to the alternative explanation that gains arise simply from larger training-set size.
minor comments (1)
- The abstract asserts that synthetic augmentation 'consistently improves' rare-class recall and F1 but supplies no numerical deltas, standard deviations, or statistical-test results to quantify the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the constructive comment on our experimental controls. We respond to the major comment below.
read point-by-point responses
-
Referee: The experimental protocol varies the synthetic-to-real ratio while holding the real-sample count fixed, so total training-set cardinality grows with the ratio. No control is described that matches total sample count using only real data (e.g., duplication or oversampling of the scarce real examples). Because the central claim attributes performance gains to the distributional fidelity of the LoRA-generated images, the absence of this control leaves the attribution open to the alternative explanation that gains arise simply from larger training-set size.
Authors: We agree that our experiments hold the number of real samples fixed while increasing the total training set size through the addition of synthetic samples. This design choice was made to simulate realistic data-scarce scenarios where additional real data is unavailable. However, we recognize that this leaves open the possibility that gains are due to increased volume rather than the quality of the generated images. To address this, we will include in the revised manuscript additional baseline experiments that match the total training set cardinality by oversampling (duplicating) the real rare-class examples. We will report the performance of these controls alongside the synthetic augmentation results to better attribute the observed improvements to the distributional properties of the LoRA-adapted diffusion outputs. revision: yes
Circularity Check
No circularity: purely empirical evaluation on held-out data
full rationale
The paper describes an experimental pipeline for few-shot LoRA fine-tuning of diffusion models to generate synthetic images for rare-class augmentation, followed by training classifiers and measuring recall/F1 on fixed held-out real test sets. No equations, derivations, or fitted parameters are used to define or predict the central performance claims; results are obtained by direct measurement against external real-data benchmarks. The synthetic-to-real ratio is varied as an experimental factor, but the reported improvements are not constructed from the method's own inputs or self-citations. This is a standard empirical study whose validity rests on experimental controls rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A pretrained diffusion model can be effectively adapted via LoRA using only 20-50 images to generate useful synthetic samples for a target visual domain.
- domain assumption Mixing synthetic images generated this way with real data improves rare-class performance on held-out real test sets without introducing net-negative distribution shift.
Reference graph
Works this paper leans on
-
[1]
Are synthetic corruptions a reliable proxy for real-world corruptions?arXiv, 2025
Akshay Agnihotri et al. Are synthetic corruptions a reliable proxy for real-world corruptions?arXiv, 2025. 2
work page 2025
-
[2]
Synthetic data from diffusion models improves imagenet classification
Shekoofeh Azizi et al. Synthetic data from diffusion models improves imagenet classification. InCVPR, 2023. 2
work page 2023
-
[3]
Black Forest Labs. FLUX2. 2025. 2
work page 2025
-
[4]
Roentgen: Vision-language founda- tion model for chest x-ray generation.arXiv, 2023
Ibrahim Hamamci et al. Roentgen: Vision-language founda- tion model for chest x-ray generation.arXiv, 2023. 2
work page 2023
-
[5]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 3
work page 2016
-
[6]
LoRA: Low-Rank Adaptation of Large Language Models
Edward Hu et al. Lora: Low-rank adaptation of large lan- guage models.arXiv preprint arXiv:2106.09685, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Multi-concept customization of text-to- image diffusion
Nupur Kumari et al. Multi-concept customization of text-to- image diffusion. InCVPR, 2023. 2
work page 2023
-
[8]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz et al. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InCVPR,
-
[9]
Augmenting medical image clas- sifiers with synthetic data from latent diffusion models
Christopher Sagers et al. Augmenting medical image clas- sifiers with synthetic data from latent diffusion models. In MICCAI, 2023. 2
work page 2023
-
[10]
Bounding box-guided diffusion for synthesizing industrial images and segmenta- tion maps.arXiv, 2025
Andrea Simoni and Matteo Pelosin. Bounding box-guided diffusion for synthesizing industrial images and segmenta- tion maps.arXiv, 2025. 2
work page 2025
-
[11]
Effective data augmentation with diffusion models
Brandon Trabucco et al. Effective data augmentation with diffusion models. InICLR, 2023. 2
work page 2023
-
[12]
Controllable image synthesis of in- dustrial data using stable diffusion
Gabriele Valvano et al. Controllable image synthesis of in- dustrial data using stable diffusion. InWACV, 2024. 2
work page 2024
-
[13]
Xiaosong Wang et al. Chestx-ray8: Hospital-scale chest x- ray database and benchmarks on weakly supervised classifi- cation and localization of common thorax diseases. InCVPR,
-
[14]
You don’t have to be perfect to be amazing: Unveil the utility of synthetic images.arXiv, 2023
Yue Xing et al. You don’t have to be perfect to be amazing: Unveil the utility of synthetic images.arXiv, 2023. 2
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.