Recognition: 1 theorem link
· Lean TheoremDomain Restriction via Multi SAE Layer Transitions
Pith reviewed 2026-05-13 05:51 UTC · model grok-4.3
The pith
Sparse autoencoders applied to layer transitions in LLMs can distinguish out-of-domain texts by capturing domain-specific signatures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Layer transitions provide a promising avenue for extracting domain-specific signatures. Lightweight methods of learning on internal dynamics encoded using a sparse autoencoder exhibit strong capability in distinguishing OOD texts, enabling better interpretation of the LLM's internal evolution of input processing.
What carries the argument
Multi SAE layer transitions, which encode the internal dynamics and changes in representations between layers of the LLM using sparse autoencoders.
If this is right
- LLMs can better restrict outputs to intended domains by monitoring internal layer changes.
- Internal processing provides fine-grained details for distinguishing input domains beyond surface-level checks.
- Interpretability of model decisions improves through analysis of SAE-encoded transitions.
- Lightweight learning methods on these transitions suffice for effective OOD detection without full model access.
Where Pith is reading between the lines
- Similar techniques might apply to other transformer-based models beyond the tested Gemma-2 variants for broader OOD detection.
- The method could extend to real-time monitoring in deployed systems to prevent unintended domain shifts.
- Further work might explore how specific layer transitions correspond to particular domain features.
Load-bearing premise
The assumption that SAE-encoded layer transitions reliably capture domain-specific information that works beyond the specific Gemma-2 2B and 9B models and benchmarks used in testing.
What would settle it
Demonstrating that the method fails to distinguish OOD texts on a different large language model family or on a new set of domain benchmarks where performance drops significantly.
Figures



read the original abstract
The general-purpose nature of Large Language Models (LLMs) presents a significant challenge for domain-specific applications, often leading to out-of-domain (OOD) interactions that undermine the provider's intent. Existing methods for detecting such scenarios treat the LLM as an uninterpretable black box and overlook the internal processing of inputs. In this work we show that layer transitions provide a promising avenue for extracting domain-specific signature. Specifically, we present several lightweight ways of learning on internal dynamics encoded using a sparse autoencoder (SAE) that exhibit great capability in distinguishing OOD texts. Building on top of SAEs representation transitions enables us to better interpret the LLM internal evolution of input processing and shed light on its decisions. We provide a comprehensive analysis of the method and benchmark it with the gemma-2 2B and 9B models. Our results emphasize the efficacy of the internal process in capturing fine-grained input-related details.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that layer transitions in LLMs, when encoded via sparse autoencoders (SAEs), enable several lightweight learning methods to extract domain-specific signatures that distinguish out-of-domain (OOD) texts. It provides a comprehensive analysis and benchmarks the approach on Gemma-2 2B and 9B models, arguing that this reveals interpretable internal dynamics of input processing.
Significance. If the empirical results hold under broader validation, the work could advance interpretable domain restriction techniques by shifting focus from black-box output monitoring to SAE-encoded internal state transitions, potentially improving reliability in domain-specific LLM deployments.
major comments (2)
- Abstract: The central claim of 'great capability' and 'efficacy' in distinguishing OOD texts rests on unverified experimental support, as no quantitative metrics (accuracy, F1, baselines, error bars, or exclusion criteria) are supplied to substantiate the assertion.
- The manuscript benchmarks exclusively on Gemma-2 2B and 9B; the generalization claim that SAE layer transitions reliably encode domain-specific information (rather than model-specific artifacts) lacks cross-architecture tests on different scales, training corpora, or attention mechanisms, which is load-bearing for the 'promising avenue' conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and have revised the manuscript to improve clarity and support for the claims.
read point-by-point responses
-
Referee: Abstract: The central claim of 'great capability' and 'efficacy' in distinguishing OOD texts rests on unverified experimental support, as no quantitative metrics (accuracy, F1, baselines, error bars, or exclusion criteria) are supplied to substantiate the assertion.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. The body of the manuscript reports benchmarks with accuracy, F1 scores, and comparisons to baselines on the Gemma-2 models. We have revised the abstract to incorporate key metrics (e.g., accuracy and F1) and a brief reference to the experimental setup and exclusion criteria used. revision: yes
-
Referee: The manuscript benchmarks exclusively on Gemma-2 2B and 9B; the generalization claim that SAE layer transitions reliably encode domain-specific information (rather than model-specific artifacts) lacks cross-architecture tests on different scales, training corpora, or attention mechanisms, which is load-bearing for the 'promising avenue' conclusion.
Authors: We acknowledge that the evaluation is restricted to the Gemma-2 2B and 9B models and does not include cross-architecture experiments. The manuscript presents the method as a promising avenue demonstrated on these models rather than claiming universal generalization. We have revised the discussion and conclusion to explicitly note the scope of the current results, highlight that domain signatures are observed consistently across the two model scales tested, and recommend future validation on additional architectures, corpora, and attention mechanisms. revision: partial
Circularity Check
No circularity: empirical method on SAE layer transitions with no self-referential derivations
full rationale
The paper describes an empirical approach: lightweight learning on SAE-encoded layer transitions to extract domain signatures for OOD detection, benchmarked on Gemma-2 2B/9B. No equations, predictions, or uniqueness claims reduce by construction to fitted inputs or prior self-citations. The central claim rests on experimental results rather than a derivation chain that loops back to its own definitions or parameters. Generalization limits are a separate empirical concern, not circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
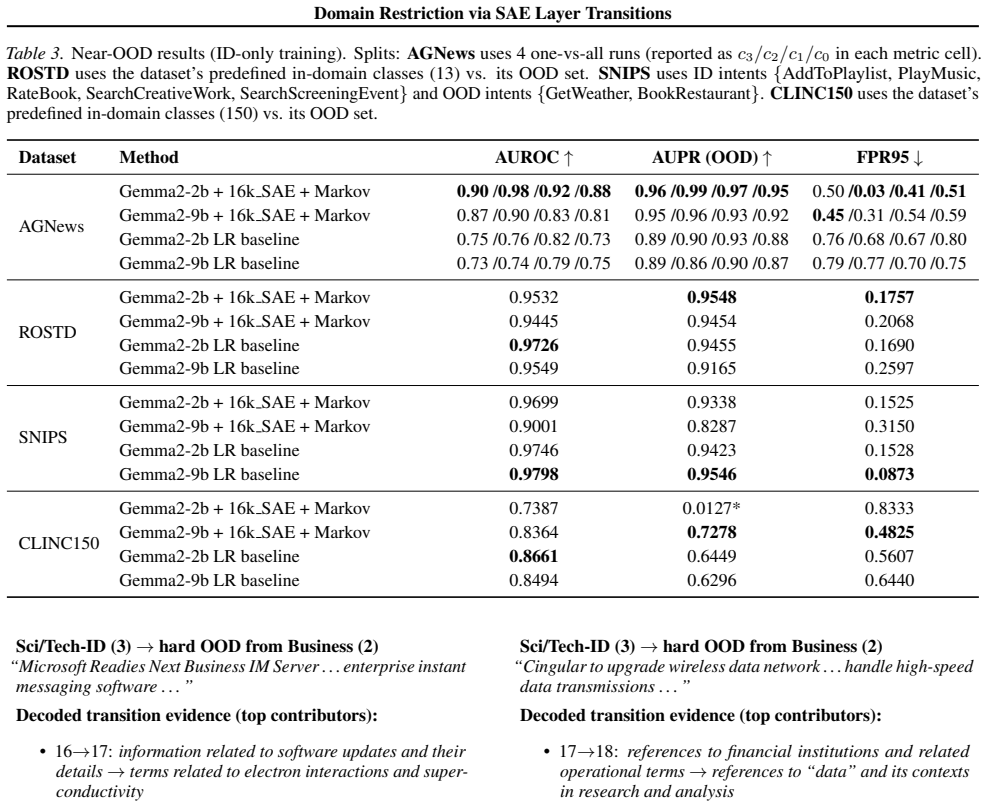
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose an ID-only scope-gating method that detects out-of-scope text by modeling depthwise transitions of sparse, interpretable SAE features... using a sparse first-order Markov transition model, HTM, and an RNN predictor
Reference graph
Works this paper leans on
-
[1]
Saes are good for steering – if you select the right features
Arad, D., Mueller, A., and Belinkov, Y . Saes are good for steering – if you select the right features. InProceedings of the 2025 Conference on Empirical Methods in Natu- ral Language Processing, pp. 10252–10270. Association for Computational Linguistics,
work page 2025
-
[2]
doi: 10.18653/v1/ 2025.emnlp-main.519. URL http://dx.doi.org/ 10.18653/v1/2025.emnlp-main.519. Bloom, J., Tigges, C., Duong, A., and Chanin, D. Sae- lens. https://github.com/decoderesearch/ SAELens,
-
[3]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
URL https://arxiv.org/ abs/2305.05176. Chen, S., Bi, X., Gao, R., and Sun, X. Holistic sentence embeddings for better out-of-distribution detection,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Cui, Y ., Ahmad, S., and Hawkins, J
URLhttps://arxiv.org/abs/2210.07485. Cui, Y ., Ahmad, S., and Hawkins, J. Continuous on- line sequence learning with an unsupervised neural net- work model.Neural Computation, 28(11):2474–2504, November
-
[5]
ISSN 1530-888X. doi: 10.1162/neco a 00893. URL http://dx.doi.org/10.1162/ NECO_a_00893. Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L. Sparse autoencoders find highly interpretable features in language models,
-
[6]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
URL https:// arxiv.org/abs/2309.08600. Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URL https://arxiv. org/abs/1810.04805. Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., Grosse, R., McCandlish, S., Kaplan, J., Amodei, D., Wattenberg, M., and Olah, C. Toy models of superposition,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URL https://arxiv.org/ abs/2209.10652. Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
URL https://arxiv.org/abs/ 1610.02136. Hendrycks, D., Liu, X., Wallace, E., Dziedzic, A., Krishnan, R., and Song, D. Pretrained transformers improve out-of- distribution robustness,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https://arxiv. org/abs/2004.06100. Hu, Q. J., Bieker, J., Li, X., Jiang, N., Keigwin, B., Ran- ganath, G., Keutzer, K., and Upadhyay, S. K. Router- bench: A benchmark for multi-llm routing system,
-
[11]
URLhttps://arxiv.org/abs/2403.12031. Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., and Liu, T. A survey on hallucination in large language models: Prin- ciples, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, Jan- uary
-
[12]
ISSN 1558-2868. doi: 10.1145/3703155. URLhttp://dx.doi.org/10.1145/3703155. Lang, H., Zheng, Y ., Li, Y ., Sun, J., Huang, F., and Li, Y . A survey on out-of-distribution detection in nlp,
-
[13]
Lee, K., Lee, K., Lee, H., and Shin, J
URL https://arxiv.org/abs/2305.03236. Lee, K., Lee, K., Lee, H., and Shin, J. A simple uni- fied framework for detecting out-of-distribution samples and adversarial attacks,
-
[14]
URL https://arxiv. org/abs/1807.03888. Liang, S., Li, Y ., and Srikant, R. Enhancing the relia- bility of out-of-distribution image detection in neural networks,
- [15]
-
[16]
Software available from neuronpedia.org
URL https: //www.neuronpedia.org. Software available from neuronpedia.org. Lindsey, J., Templeton, A., Marcus, J., Conerly, T., Batson, J., and Olah, C. Sparse cross- coders for cross-layer features and model diff- ing. https://transformer-circuits.pub/ 2024/crosscoders/index.html,
work page 2024
-
[17]
Ac- cessed: 2026-01-29. Liu, X., Yu, H., Zhang, H., Xu, Y ., Lei, X., Lai, H., Gu, Y ., Ding, H., Men, K., Yang, K., Zhang, S., Deng, X., Zeng, A., Du, Z., Zhang, C., Shen, S., Zhang, T., Su, Y ., Sun, H., Huang, M., Dong, Y ., and Tang, J. Agentbench: Evaluating llms as agents,
work page 2026
-
[18]
AgentBench: Evaluating LLMs as Agents
URL https://arxiv.org/abs/2308.03688. 9 Domain Restriction via SAE Layer Transitions Liu, Y ., Yao, Y ., Ton, J.-F., Zhang, X., Guo, R., Cheng, H., Klochkov, Y ., Taufiq, M. F., and Li, H. Trustworthy llms: a survey and guideline for evaluating large language mod- els’ alignment,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Lu, S., Wang, Y ., Sheng, L., He, L., Zheng, A., and Liang, J
URL https://arxiv.org/ abs/2308.05374. Lu, S., Wang, Y ., Sheng, L., He, L., Zheng, A., and Liang, J. Out-of-distribution detection: A task-oriented survey of recent advances,
-
[20]
Marks, S., Rager, C., Michaud, E
URL https://arxiv.org/ abs/2409.11884. Marks, S., Rager, C., Michaud, E. J., Belinkov, Y ., Bau, D., and Mueller, A. Sparse feature circuits: Discovering and editing interpretable causal graphs in language mod- els,
-
[21]
Automatically interpreting millions of features in large language models
URL https://arxiv.org/ abs/2410.13928. Podolskiy, A., Lipin, D., Bout, A., Artemova, E., and Pi- ontkovskaya, I. Revisiting mahalanobis distance for transformer-based out-of-domain detection,
-
[22]
R¨auker, T., Ho, A., Casper, S., and Hadfield-Menell, D
URL https://arxiv.org/abs/2101.03778. R¨auker, T., Ho, A., Casper, S., and Hadfield-Menell, D. Toward transparent ai: A survey on interpreting the inner structures of deep neural networks,
-
[23]
URL https: //arxiv.org/abs/2207.13243. Schick, T., Dwivedi-Yu, J., Dess`ı, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language models can teach themselves to use tools,
-
[24]
Toolformer: Language Models Can Teach Themselves to Use Tools
URL https://arxiv.org/abs/ 2302.04761. Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural net- works: The sparsely-gated mixture-of-experts layer,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
URLhttps://arxiv.org/abs/1701.06538. Sun, Y ., Ming, Y ., Zhu, X., and Li, Y . Out-of-distribution detection with deep nearest neighbors,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Team, G., Riviere, M., Pathak, S., Sessa, P
URL https://arxiv.org/abs/2204.06507. Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram´e, A., Ferret, J., Liu, P., Tafti, P., Friesen, A., Casbon, M., Ramos, S., Kumar, R., Lan, C. L., Jerome, S., Tsit- sulin, A., Vieillard, N., Stanczyk, P., Girgin, S., Momchev, N., Hoffman, M., T...
-
[27]
Gemma 2: Improving Open Language Models at a Practical Size
URL https://arxiv.org/abs/2408.00118. Uppaal, R., Hu, J., and Li, Y . Is fine-tuning needed? pre-trained language models are near perfect for out-of- domain detection,
work page internal anchor Pith review Pith/arXiv arXiv
- [28]
-
[29]
cc/paper_files/paper/1991/file/ ff4d5fbbafdf976cfdc032e3bde78de5-Paper
URL https://proceedings.neurips. cc/paper_files/paper/1991/file/ ff4d5fbbafdf976cfdc032e3bde78de5-Paper. pdf. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . React: Synergizing reasoning and act- 10 Domain Restriction via SAE Layer Transitions ing in language models,
work page 1991
-
[30]
ReAct: Synergizing Reasoning and Acting in Language Models
URL https://arxiv. org/abs/2210.03629. Zhang, A., Xiao, T. Z., Liu, W., Bamler, R., and Wis- chik, D. Your finetuned large language model is al- ready a powerful out-of-distribution detector,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
URL https://arxiv.org/abs/2404.08679. Zhou, S., Xu, F. F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y ., Fried, D., Alon, U., and Neubig, G. Webarena: A realistic web environment for building autonomous agents,
-
[32]
WebArena: A Realistic Web Environment for Building Autonomous Agents
URL https: //arxiv.org/abs/2307.13854. 11 Domain Restriction via SAE Layer Transitions A. Analysis of Layer-wise Domain Cohesion via Top-K Jaccard Similarity This analysis quantifies the evolution of domain-specific representations across the internal layers of a neural network. By processing the four distinct categories of ag news dataset —World, Sports,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Peak performance was achieved at the highest sparsity level (k= 10 ) for all methods
indicate a clear inverse relationship betweenK and detection accuracy. Peak performance was achieved at the highest sparsity level (k= 10 ) for all methods. Notably, theFirst-Order Markov Chainconsistently outperformed or matched more complex architectures, suggesting that local feature transitions are highly discriminative in SAE latent spaces. Table 6.M...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.