Recognition: no theorem link
When Simulation Lies: A Sim-to-Real Benchmark and Domain-Randomized RL Recipe for Tool-Use Agents
Pith reviewed 2026-05-13 05:48 UTC · model grok-4.3
The pith
Domain-randomized RL on perturbed trajectories lets a 3B tool-use model retain most accuracy and match larger baselines on real failures
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
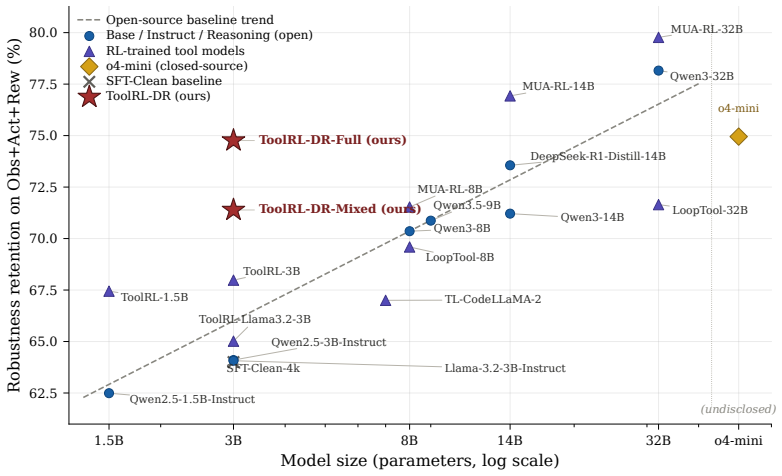
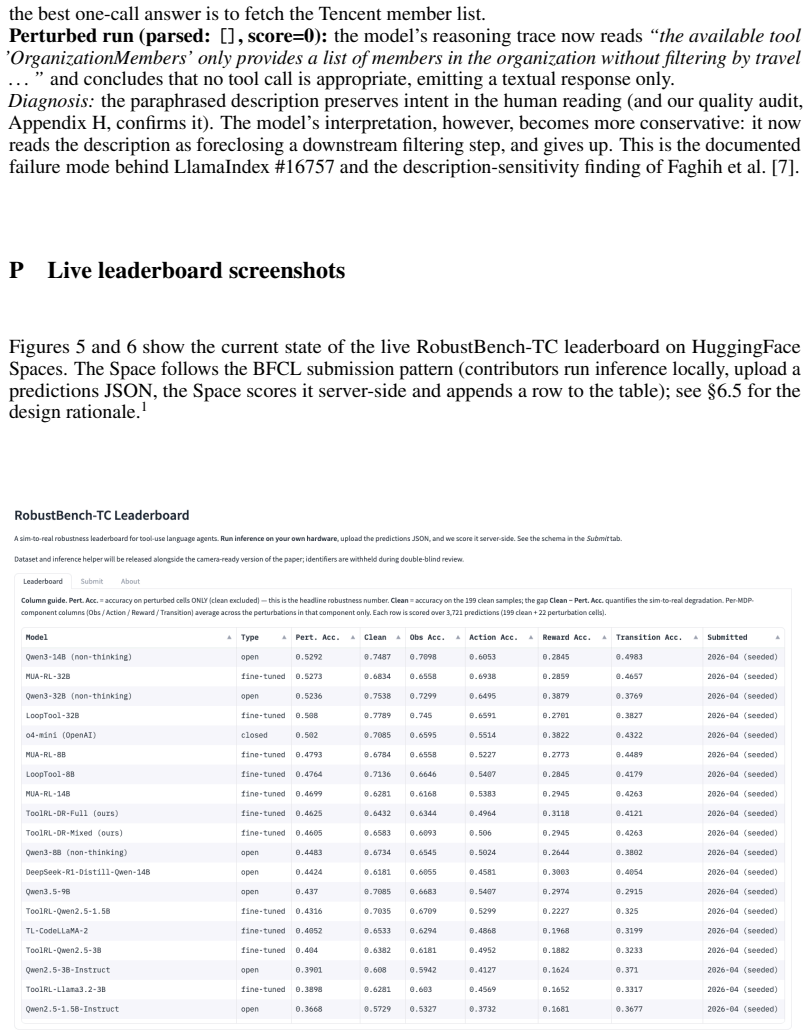
ToolRL-DR trains tool-use agents via reinforcement learning on trajectories that incorporate randomized perturbations to the observation, action, and reward components of the POMDP. On a 3B backbone the resulting agent retains roughly three-quarters of its clean accuracy and reaches an aggregate perturbed accuracy comparable to open-source 14B function-calling baselines while substantially narrowing the gap to o4-mini; it closes approximately 27 percent of the transition gap despite never seeing transition perturbations during training.
What carries the argument
ToolRL-DR, the domain-randomization reinforcement learning recipe that augments training trajectories with perturbations from three statically encodable POMDP components to induce more persistent retry policies.
If this is right
- A 3B-parameter model can reach perturbed accuracy comparable to open-source 14B function-calling baselines.
- Reinforcement learning on static perturbations produces retry policies that transfer to unseen dynamic transition failures.
- Observation perturbations reduce accuracy by less than 5 percent while reward and transition perturbations reduce it by roughly 40 percent and 30 percent.
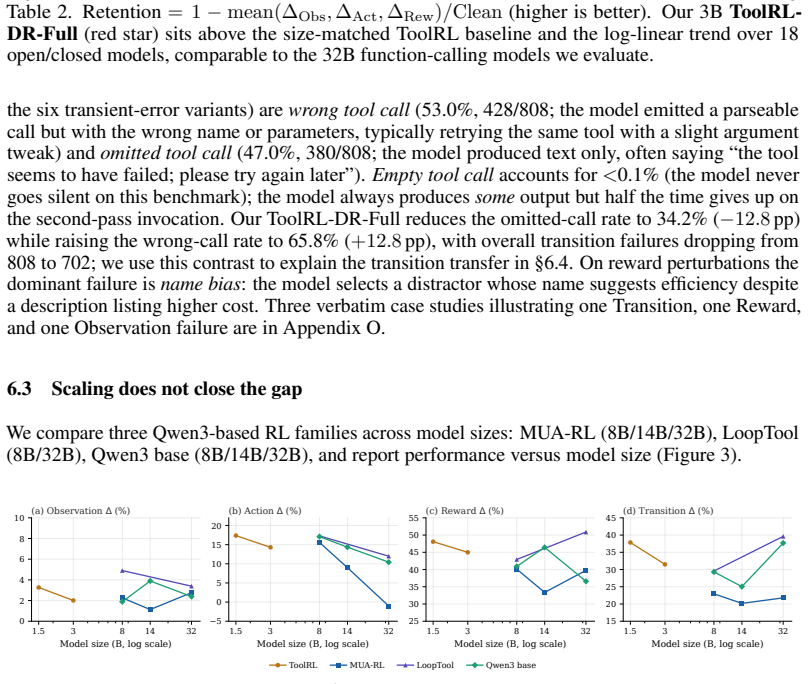
- Increasing model scale alone does not close the robustness gaps identified in the benchmark.
Where Pith is reading between the lines
- The same static-perturbation RL approach could be tested on other partially observable agent tasks that face runtime variability.
- Pairing the benchmark with production deployment logs might surface additional perturbation types not yet covered.
- The induced retry behavior suggests that explicit exploration during training can partially substitute for direct exposure to runtime noise.
Load-bearing premise
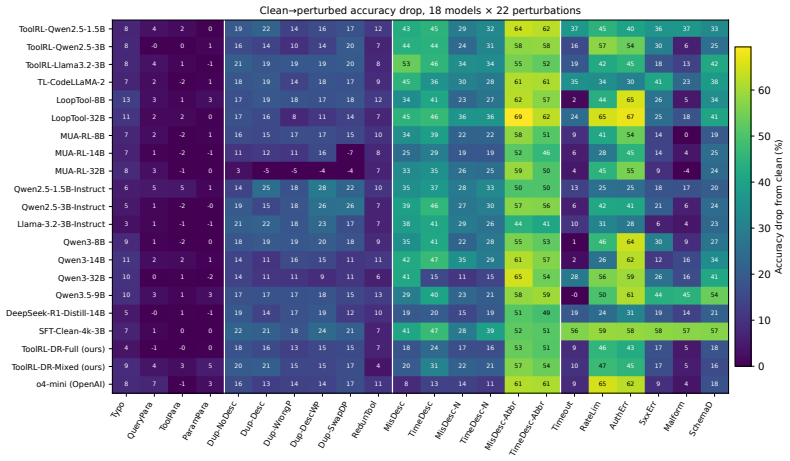
The 22 perturbation types, each grounded in a verified GitHub issue or documented tool-calling failure, adequately represent the sim-to-real gap that occurs in actual deployments.
What would settle it
Deploy the trained 3B agent against live tool APIs that exhibit the documented failure modes and measure whether its observed accuracy drop matches the benchmark's predicted robustness levels.
Figures


read the original abstract
Tool-use language agents are evaluated on benchmarks that assume clean inputs, unambiguous tool registries, and reliable APIs. Real deployments violate all these assumptions: user typos propagate into hallucinated tool names, a misconfigured request timeout can stall an agent indefinitely, and duplicate tool names across servers can freeze an SDK. We study these failures as a sim-to-real gap in the tool-use partially observable Markov decision process (POMDP), where deployment noise enters through the observation, action space, reward-relevant metadata, or transition dynamics. We introduce RobustBench-TC, a benchmark with 22 perturbation types organized by these four POMDP components, each grounded in a verified GitHub issue or documented tool-calling failure. Across 21 models from 1.5B to 32B parameters (including the closed-source o4-mini), the robustness profile is sharply uneven: observation perturbations reduce accuracy by less than 5%, while reward-relevant and transition perturbations reduce accuracy by roughly 40% and 30%, respectively; scale alone does not close these gaps. We then propose ToolRL-DR, a domain-randomization reinforcement learning (RL) recipe that trains a tool-use agent on perturbation-augmented trajectories spanning the three statically encodable POMDP components. On a 3B backbone, ToolRL-DR-Full retains roughly three-quarters of clean accuracy and reaches an aggregate perturbed accuracy comparable to open-source 14B function-calling baselines while substantially narrowing the gap to o4-mini. It closes approximately 27% of the Transition gap despite never seeing transition perturbations in training, suggesting that RL on adversarial static tool-use inputs induces a more persistent retry policy that transfers to unseen runtime failures. The dataset, code and benchmark leaderboard are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RobustBench-TC, a benchmark of 22 perturbation types organized along four POMDP axes (observation, action space, reward-relevant metadata, transition dynamics) for tool-use agents, with each type grounded in verified GitHub issues or documented failures. It evaluates 21 models (1.5B–32B, including o4-mini) and reports uneven robustness: <5% accuracy drop under observation perturbations versus ~40% and ~30% drops under reward and transition perturbations, respectively, with scale alone insufficient to close gaps. It then proposes ToolRL-DR, a domain-randomized RL recipe that augments trajectories with perturbations from the three statically encodable components; on a 3B backbone, ToolRL-DR-Full retains ~75% of clean accuracy, matches open-source 14B function-calling baselines on aggregate perturbed accuracy, narrows the gap to o4-mini, and closes ~27% of the unseen Transition gap.
Significance. If the benchmark is shown to be representative of real deployment noise and the empirical results hold under detailed scrutiny, the work supplies a concrete, publicly released benchmark and training recipe for improving robustness in tool-use agents. The observation that RL on static perturbations can induce a transferable retry policy to dynamic transition failures would be a useful empirical finding for reliable agent design.
major comments (2)
- [Benchmark Description] Benchmark construction: The claim that the 22 GitHub-grounded perturbations adequately span the sim-to-real gap in tool-use POMDPs is load-bearing for interpreting all reported accuracy drops and the 27% Transition-gap closure, yet the manuscript provides no quantitative comparison of their frequency, severity, or coverage against production tool-calling logs, SDK traces, or user studies.
- [Experiments and Results] Results and transfer claim: The headline numbers (3B model retaining ~75% clean accuracy, matching 14B baselines on perturbed aggregate, closing 27% of the Transition gap) rest on specific definitions of aggregate perturbed accuracy and the exact set of baselines; the paper must supply per-perturbation tables, error bars, and verification steps for these quantities to support the generalization and transfer narrative.
minor comments (2)
- [Abstract] The abstract states specific accuracy drops and gap closures but omits the total number of models and the precise backbone size used for the main ToolRL-DR claim; these should be stated explicitly.
- [Preliminaries] Notation for the four POMDP components and the distinction between statically encodable versus runtime perturbations should be introduced earlier and used consistently in figures and tables.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, indicating revisions where feasible while being transparent about limitations.
read point-by-point responses
-
Referee: [Benchmark Description] Benchmark construction: The claim that the 22 GitHub-grounded perturbations adequately span the sim-to-real gap in tool-use POMDPs is load-bearing for interpreting all reported accuracy drops and the 27% Transition-gap closure, yet the manuscript provides no quantitative comparison of their frequency, severity, or coverage against production tool-calling logs, SDK traces, or user studies.
Authors: We agree that quantitative validation against production data would strengthen claims of representativeness. However, such proprietary logs and traces are not publicly available. Perturbations were derived from verifiable public GitHub issues and documented failures. The revised manuscript expands the Benchmark Construction section with explicit selection criteria and adds a Limitations subsection discussing the absence of frequency statistics and potential selection biases. revision: partial
-
Referee: [Experiments and Results] Results and transfer claim: The headline numbers (3B model retaining ~75% clean accuracy, matching 14B baselines on perturbed aggregate, closing 27% of the Transition gap) rest on specific definitions of aggregate perturbed accuracy and the exact set of baselines; the paper must supply per-perturbation tables, error bars, and verification steps for these quantities to support the generalization and transfer narrative.
Authors: We agree that greater granularity is required. The revised manuscript now includes per-perturbation accuracy tables for all 21 models, error bars from multiple random seeds for the RL experiments, and an appendix with explicit verification steps for aggregate metrics and the 27% Transition gap calculation. These additions clarify definitions and bolster the reported results and transfer narrative. revision: yes
- Quantitative comparison of the 22 perturbations' frequency, severity, or coverage against production tool-calling logs, SDK traces, or user studies, as such proprietary data is unavailable.
Circularity Check
No circularity: purely empirical benchmark construction and RL evaluation
full rationale
The paper defines RobustBench-TC by enumerating 22 perturbation types each tied to specific GitHub issues or documented failures, then measures model accuracy and trains ToolRL-DR via domain-randomized RL on augmented trajectories. All reported numbers (accuracy drops, retention of three-quarters clean accuracy, 27% gap closure on unseen transitions) are direct experimental outcomes on held-out test sets. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citations are used to derive results; the central claims rest on external verification against the introduced benchmark rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tool-use agent interactions can be modeled as a POMDP where deployment noise enters through observation, action space, reward-relevant metadata, or transition dynamics.
Reference graph
Works this paper leans on
-
[1]
Solving rubik’s cube with a robot hand, 2019
Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, et al. Solving rubik’s cube with a robot hand, 2019
work page 2019
-
[2]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024
work page 2024
-
[3]
Closing the sim-to-real loop: Adapting simulation randomization with real world experience
Yevgen Chebotar, Ankur Handa, Viktor Makoviychuk, Miles Macklin, Jan Issac, Nathan Ratliff, and Dieter Fox. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2019
work page 2019
-
[4]
Chen Chen, Xinlong Hao, Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Yuefeng Huang, Xiangcheng Liu, Wang Xinzhi, et al. Acebench: A comprehensive evaluation of llm tool usage.Findings of the Association for Computational Linguistics: EMNLP, 2025: 12970–12998, 2025
work page 2025
-
[5]
crystaldba/postgres-mcp PR #157: Disambiguation clauses for sibling tools, 2025
crystaldba contributors. crystaldba/postgres-mcp PR #157: Disambiguation clauses for sibling tools, 2025. URLhttps://github.com/crystaldba/postgres-mcp/pull/157
work page 2025
-
[6]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025
work page 2025
-
[7]
Tool preferences in agentic llms are unreliable
Kazem Faghih, Wenxiao Wang, Yize Cheng, Siddhant Bharti, Gaurang Sriramanan, Sriram Balasubramanian, Parsa Hosseini, and Soheil Feizi. Tool preferences in agentic llms are unreliable. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20965–20980, 2025
work page 2025
-
[8]
Gorilla/BFCL issue #839: vllm server disconnects mid-inference, 2025
Gorilla contributors. Gorilla/BFCL issue #839: vllm server disconnects mid-inference, 2025. URLhttps://github.com/ShishirPatil/gorilla/issues/839
work page 2025
-
[9]
grafana/loki-mcp issue #27: Parameter description “1h ago” fails parser, 2025
Grafana Loki MCP contributors. grafana/loki-mcp issue #27: Parameter description “1h ago” fails parser, 2025. URLhttps://github.com/grafana/loki-mcp/issues/27
work page 2025
-
[10]
Sebastian Höfer, Kostas Bekris, Ankur Handa, Juan Camilo Gamboa, Melissa Mozifian, Florian Golemo, Christopher Atkeson, Dieter Fox, Ken Goldberg, John Leonard, et al. Sim2Real in robotics and automation: Applications and challenges.IEEE Transactions on Automation Science and Engineering, 2021
work page 2021
-
[11]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023
work page 2023
-
[12]
langchain issue #29596: Missing authorization header causes silent 401, 2025
LangChain contributors. langchain issue #29596: Missing authorization header causes silent 401, 2025. URLhttps://github.com/langchain-ai/langchain/issues/29596
work page 2025
-
[13]
langchain issue #34746: Ollama returns malformed json; tool call dropped, 2025
LangChain contributors. langchain issue #34746: Ollama returns malformed json; tool call dropped, 2025. URLhttps://github.com/langchain-ai/langchain/issues/34746
work page 2025
-
[14]
langchain issue #35597: Default request_timeout=None causes agent hang, 2025
LangChain contributors. langchain issue #35597: Default request_timeout=None causes agent hang, 2025. URL https://github.com/langchain-ai/langchain/issues/ 35597. 10
work page 2025
-
[15]
langchain issue #36032: anyOf schema crashes ollama after definition update, 2025
LangChain contributors. langchain issue #36032: anyOf schema crashes ollama after definition update, 2025. URLhttps://github.com/langchain-ai/langchain/issues/36032
work page 2025
-
[16]
API-Bank: A comprehensive benchmark for tool-augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A comprehensive benchmark for tool-augmented LLMs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
work page 2023
-
[17]
APIGen: Automated pipeline for generating verifiable and diverse function-calling datasets, 2024
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, et al. APIGen: Automated pipeline for generating verifiable and diverse function-calling datasets, 2024
work page 2024
-
[18]
LlamaIndex issue #7170: Tool name typo from user query crashes dispatcher, 2023
LlamaIndex contributors. LlamaIndex issue #7170: Tool name typo from user query crashes dispatcher, 2023. URLhttps://github.com/run-llama/llama_index/issues/7170
work page 2023
-
[19]
LlamaIndex issue #16757: Query paraphrase routes to wrong tool,
LlamaIndex contributors. LlamaIndex issue #16757: Query paraphrase routes to wrong tool,
-
[20]
URLhttps://github.com/run-llama/llama_index/issues/16757
-
[21]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, et al. Toolsandbox: A stateful, conversational, inter- active evaluation benchmark for llm tool use capabilities. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1160–1183, 2025
work page 2025
-
[22]
Microsoft Semantic Kernel contributors. microsoft/semantic-kernel issue #13690: Silent mid-session tool swap with abbreviated descriptions, 2025. URL https://github.com/ microsoft/semantic-kernel/issues/13690
work page 2025
-
[23]
netbox-mcp-server issue #79: Misleading filter description silently returns all records, 2025
NetBox Labs. netbox-mcp-server issue #79: Misleading filter description silently returns all records, 2025. URL https://github.com/netboxlabs/netbox-mcp-server/issues/ 79
work page 2025
-
[24]
GPT-4o-mini model specification, 2024
OpenAI. GPT-4o-mini model specification, 2024. URL https://platform.openai.com/ docs/models/gpt-4o-mini
work page 2024
-
[25]
GPT-5-mini model specification, 2025
OpenAI. GPT-5-mini model specification, 2025. URL https://platform.openai.com/ docs/models/gpt-5-mini
work page 2025
-
[26]
openai-agents-python issue #1167: Same-named tools across mcp servers cause sdk hang, 2025
openai-agents-python contributors. openai-agents-python issue #1167: Same-named tools across mcp servers cause sdk hang, 2025. URL https://github.com/openai/ openai-agents-python/issues/1167
work page 2025
-
[27]
openai-python issue #2699: Rate-limit asymmetry across end- points, 2025
OpenAI Python contributors. openai-python issue #2699: Rate-limit asymmetry across end- points, 2025. URLhttps://github.com/openai/openai-python/issues/2699
work page 2025
-
[28]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[29]
Sim-to-real trans- fer of robotic control with dynamics randomization
Xue Bin Peng, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Sim-to-real trans- fer of robotic control with dynamics randomization. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2018
work page 2018
-
[30]
ToolRL: Reward is all tool learning needs, 2025
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs, 2025
work page 2025
-
[31]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InProceedings of the 12th International Conference on Learning Representa- tions (ICLR), 2024
work page 2024
-
[32]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji 11 Lin, Tianhao ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
On the robustness of agentic function calling, 2025
Ella Rabinovich and Ateret Anaby-Tavor. On the robustness of agentic function calling, 2025
work page 2025
-
[34]
Measuring reliability of large language models through semantic consistency, 2022
Harsh Raj, Domenic Rosati, and Subhabrata Majumdar. Measuring reliability of large language models through semantic consistency, 2022
work page 2022
-
[35]
CAD2RL: Real single-image flight without a single real image
Fereshteh Sadeghi and Sergey Levine. CAD2RL: Real single-image flight without a single real image. InProceedings of Robotics: Science and Systems (RSS), 2017
work page 2017
-
[36]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[37]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models, 2024
work page 2024
-
[38]
tau-bench issue #39: Tool description vs
Sierra Research. tau-bench issue #39: Tool description vs. implementation mismatch, 2025. URLhttps://github.com/sierra-research/tau-bench/issues/39
work page 2025
-
[39]
Scaling LLM test-time compute optimally can be more effective than scaling model parameters, 2024
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters, 2024
work page 2024
-
[40]
Sim-to-real: Learning agile locomotion for quadruped robots
Jie Tan, Tingnan Zhang, Erwin Coumans, Atil Iscen, Yunfei Bai, Danijar Hafner, Steven Bohez, and Vincent Vanhoucke. Sim-to-real: Learning agile locomotion for quadruped robots. In Proceedings of Robotics: Science and Systems (RSS), 2018
work page 2018
-
[41]
ToolAlpaca: Generalized tool learning for language models with 3000 simulated cases, 2023
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. ToolAlpaca: Generalized tool learning for language models with 3000 simulated cases, 2023
work page 2023
-
[42]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017
work page 2017
-
[43]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InProceedings of the 11th International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[46]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
work page 2024
-
[47]
Junjie Ye, Guanyu Li, Songyang Gao, Caishuang Huang, Yilong Wu, et al. ToolEyes: Fine- grained evaluation for tool learning capabilities of large language models in real-world scenarios, 2024
work page 2024
-
[48]
Junjie Ye, Yilong Wu, Songyang Gao, Caishuang Huang, Sixian Li, Guanyu Li, Xiaoran Fan, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Rotbench: A multi-level benchmark for evaluating the robustness of large language models in tool learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 313–333, 2024. 12
work page 2024
-
[49]
Junjie Ye, Yilong Wu, Sixian Li, Yuming Yang, Zhiheng Xi, Tao Gui, Qi Zhang, Xuanjing Huang, Peng Wang, Zhongchao Shi, et al. Tl-training: A task-feature-based framework for training large language models in tool use.arXiv preprint arXiv:2412.15495, 2024
-
[50]
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su
Kangning Zhang, Wenxiang Jiao, Kounianhua Du, Yuan Lu, Weiwen Liu, Weinan Zhang, and Yong Yu. Looptool: Closing the data-training loop for robust llm tool calls.arXiv preprint arXiv:2511.09148, 2025
-
[51]
Weikang Zhao, Xili Wang, Chengdi Ma, Lingbin Kong, Zhaohua Yang, Mingxiang Tuo, Xiaowei Shi, Yitao Zhai, and Xunliang Cai. Mua-rl: Multi-turn user-interacting agent reinforcement learning for agentic tool use.arXiv preprint arXiv:2508.18669, 2025
-
[52]
Wenshuai Zhao, Jorge Peña Queralta, and Tomi Westerlund. Sim-to-real transfer in deep reinforcement learning for robotics: A survey. InIEEE Symposium Series on Computational Intelligence (SSCI), 2020. A Per-source benchmark statistics Table 3 gives the full per-source composition of RobustBench-TC: clean sub-sample counts, average evaluable samples per pe...
work page 2020
-
[53]
measure10×usage variance ParamPara grafana/loki-mcp #27 [9] parameter description lists “1h ago” default; agents send the literal string but parser only accepts- 1h/RFC3339/now Action perturbations(6 types) Dup-* openai-agents- python #1167 [25] two MCP servers register the same tool name; the SDK hangs indefinitely RedunTool tau-bench #39 [37] “direct fl...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.