Recognition: no theorem link
Convergence of zeroth-order proximal point algorithms in the high-temperature regime
Pith reviewed 2026-05-13 05:14 UTC · model grok-4.3
The pith
ZOPPA converges at any fixed positive temperature by acting as the exact proximal point method on a smoothed auxiliary objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ZOPPA is equivalent to the exact proximal point algorithm on an auxiliary objective obtained by smoothing the original function at fixed positive temperature. Under standard assumptions that make the proximal operator well-defined, the sequence converges to a minimizer of this smoothed objective. Explicit guarantees connect the smoothed problem to the original objective, and the same convergence holds for the sampled S-ZOPPA estimator at fixed temperature.
What carries the argument
The auxiliary smoothed objective at fixed positive temperature, which turns ZOPPA into an exact proximal point method.
If this is right
- Convergence holds without driving temperature to zero.
- Explicit quantitative links exist between smoothed and original objectives.
- Sampled Monte Carlo versions converge at fixed temperature.
- Analysis applies under only the minimal conditions needed for proximal operators to exist.
Where Pith is reading between the lines
- Fixed temperature removes the variance explosion that occurs when sampling at vanishing temperature.
- The smoothing view may let practitioners choose temperature to balance bias and sampling cost independently of convergence.
- Similar exact-on-smoothed interpretations could be tested on other zeroth-order proximal variants.
Load-bearing premise
The objective allows the proximal operator of the smoothed auxiliary function to be well-defined at any fixed positive temperature.
What would settle it
A non-convex function satisfying standard lower-semicontinuity and coercivity where the ZOPPA iterates diverge or fail to approach a minimizer of the corresponding smoothed objective at some fixed positive temperature.
Figures

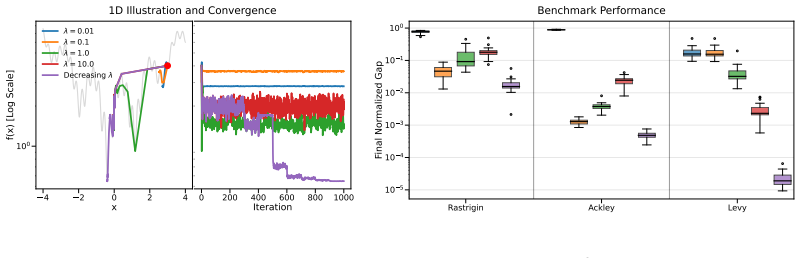

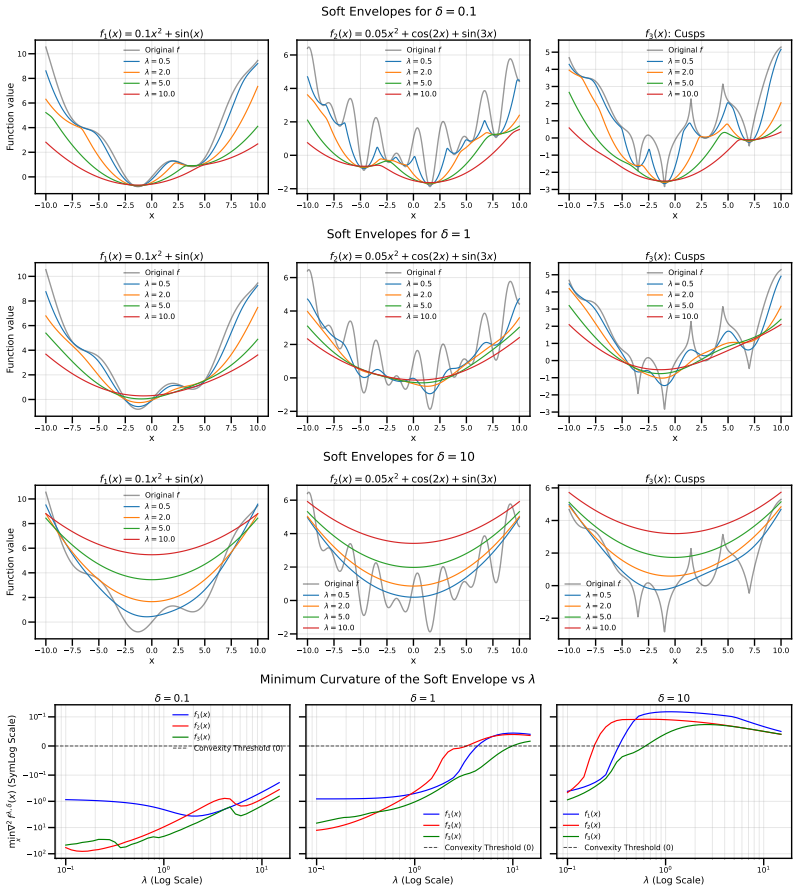


read the original abstract
Efficient methods for non-convex black-box optimization largely rely on sampling. In this context, the Zeroth-Order Proximal Operator (ZOPO) and the corresponding Zeroth-Order Proximal Point Algorithm (ZOPPA) have attracted significant interest, as they combine the advantage of requiring only objective evaluations with the powerful theoretical framework of proximal point algorithms. ZOPO depends on a temperature parameter which, when going to zero, reduces ZOPO to the exact proximal operator. By exploiting this property, the vanishing-temperature regime has been leveraged in several works to obtain theoretical guarantees via inexact proximal methods. However, this regime is computationally unsustainable when sampling is used to estimate ZOPO, since the corresponding Monte Carlo estimators suffer from severe variance issues. We therefore propose a comprehensive analysis of ZOPO for any fixed positive temperature, and prove convergence of ZOPPA under minimal assumptions on the objective function. We do so by demonstrating that ZOPPA can be interpreted as an exact proximal point method applied to an auxiliary smoothed objective, rather than an inexact method on the original function. Importantly, we further derive explicit guarantees connecting this smoothed problem back to the original objective and establish convergence results for the sampled method (S-ZOPPA) at a fixed temperature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes zeroth-order proximal point algorithms for non-convex black-box optimization. It focuses on the high-temperature (fixed positive temperature) regime and proves convergence of ZOPPA by reinterpreting the algorithm as an exact proximal-point iteration on an auxiliary smoothed objective function rather than an inexact iteration on the original objective. Explicit error bounds or guarantees are derived that connect the smoothed problem back to the original objective, and convergence is established for the sampled variant S-ZOPPA under minimal assumptions (lower semicontinuity and coercivity sufficient for the proximal operator to be well-defined).
Significance. If the derivations hold, the work supplies a clean theoretical justification for using fixed-temperature ZOPPA without invoking vanishing-temperature limits, which are impractical under sampling. The exact-proximal reinterpretation on the auxiliary smoothed objective, together with the explicit links to the original function, strengthens the applicability of proximal-point theory to zeroth-order methods and directly addresses variance issues in Monte Carlo estimation at low temperatures.
minor comments (3)
- The abstract states that 'explicit guarantees connecting this smoothed problem back to the original objective' are derived, but the precise form of these guarantees (e.g., whether they are in terms of function values, distances, or expectations) is not previewed; adding one sentence would improve readability.
- Notation for the temperature parameter and the smoothing operator should be introduced once in §2 and used consistently thereafter; occasional redefinition of the auxiliary objective risks minor confusion for readers.
- The manuscript would benefit from a short remark in the introduction clarifying how the minimal assumptions differ from (or coincide with) those used in prior vanishing-temperature analyses.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on the convergence of zeroth-order proximal point algorithms at fixed positive temperature, their assessment of its significance, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The derivation reinterprets ZOPPA at fixed positive temperature as an exact proximal-point iteration on an auxiliary smoothed objective, with explicit links back to the original function under standard lower-semicontinuity/coercivity assumptions. This step is independent of the target convergence result and does not reduce by construction to a fitted parameter, self-definition, or self-citation chain. The argument is self-contained against external proximal-analysis benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function satisfies the minimal assumptions required for the proximal operator to be well-defined at fixed positive temperature.
Reference graph
Works this paper leans on
-
[1]
S. Agapiou, O. Papaspiliopoulos, D. Sanz-Alonso, and A. M. Stuart. Importance sampling: Intrinsic dimension and computational cost.Statistical Science, pages 405–431, 2017
work page 2017
-
[2]
H. Attouch, J. Bolte, and B. F. Svaiter. Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward–backward splitting, and regularized Gauss–Seidel methods.Mathematical programming, 137(1):91–129, 2013
work page 2013
- [3]
-
[4]
Beck.First-Order Methods in Optimization
A. Beck.First-Order Methods in Optimization. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2017
work page 2017
-
[5]
A. Beck and M. Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems.SIAM J. Imaging Sci., 2:183–202, 2009
work page 2009
-
[6]
T. Bengtsson, P. Bickel, and B. Li. Curse-of-dimensionality revisited: Collapse of the particle filter in very large scale systems. InProbability and statistics: Essays in honor of David A. Freedman, volume 2, pages 316–334. Institute of Mathematical Statistics, 2008
work page 2008
- [7]
-
[8]
S. Boucheron, G. Lugosi, and P. Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013
work page 2013
-
[9]
K. Bredies, E. Chenchene, and E. Naldi. Graph and distributed extensions of the Dou- glas–Rachford method.SIAM Journal on Optimization, 34(2):1569–1594, 2024
work page 2024
-
[10]
P. Cattiaux and A. Guillin. Functional inequalities for perturbed measures with applications to log-concave measures and to some bayesian problems.Bernoulli, 28(4):2294–2321, 2022
work page 2022
-
[11]
fast iterative shrink- age/thresholding algorithm
A. Chambolle and C. Dossal. On the convergence of the iterates of the “fast iterative shrink- age/thresholding algorithm”.Journal of Optimization Theory and Applications, 166:968–982, 2015
work page 2015
-
[12]
A. Chambolle and T. Pock. A first-order primal-dual algorithm for convex problems with applications to imaging.J. Math. Imaging Vision, 40(1):120–145, 2011. 10
work page 2011
-
[13]
G. H.-G. Chen and R. T. Rockafellar. Convergence rates in forward–backward splitting.SIAM Journal on Optimization, 7(2):421–444, 1997
work page 1997
-
[14]
P.-Y . Chen, H. Zhang, Y . Sharma, J. Yi, and C.-J. Hsieh. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. InProceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pages 15–26. ACM, 2017
work page 2017
-
[15]
S. Chewi.Log-concave sampling. Forthcoming, 2026. Available online at https:// chewisinho.github.io/
work page 2026
-
[16]
K. Choromanski, M. Rowland, V . Sindhwani, R. Turner, and A. Weller. Structured evolution with compact architectures for scalable policy optimization. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 970–978, 2018
work page 2018
- [17]
-
[18]
P. L. Combettes and J.-C. Pesquet. Stochastic quasi-Fejér block-coordinate fixed point iterations with random sweeping.SIAM Journal on Optimization, 25(2):1221–1248, 2015
work page 2015
-
[19]
P. L. Combettes and V . R. Wajs. Signal recovery by proximal forward-backward splitting. Multiscale modeling & simulation, 4(4):1168–1200, 2005
work page 2005
-
[20]
A. R. Conn, K. Scheinberg, and L. N. Vicente.Introduction to Derivative-Free Optimization, volume 8 ofMPS-SIAM Series on Optimization. SIAM, Philadelphia, PA, 2009
work page 2009
-
[21]
M. G. Crandall and P.-L. Lions. Two approximations of solutions of Hamilton-Jacobi equations. Mathematics of Computation, 43(167):1–19, 1984
work page 1984
-
[22]
J. Darbon, G. P. Langlois, and T. Meng. Connecting Hamilton-Jacobi partial differential equations with maximum a posteriori and posterior mean estimators for some non-convex priors. InHandbook of Mathematical Models and Algorithms in Computer Vision and Imaging: Mathematical Imaging and Vision, pages 1–25. 2021
work page 2021
-
[23]
G. Deligiannidis, P. E. Jacob, E. M. Khribch, and G. Wang. On importance sampling and independent Metropolis-Hastings with an unbounded weight function, 2024. arXiv:2411.09514
-
[24]
N. Di, E. C. Chi, and S. W. Fung. Operator splitting with Hamilton-Jacobi-based proximals,
-
[25]
J. Dunn. Convexity, monotonicity, and gradient processes in Hilbert space.Journal of Mathe- matical Analysis and Applications, 53(1):145–158, 1976
work page 1976
-
[26]
L. C. Evans.Partial Differential Equations, volume 19 ofGraduate Studies in Mathematics. American Mathematical Society, Providence, RI, 2 edition, 2010
work page 2010
-
[27]
A. Flaxman, A. T. Kalai, and B. McMahan. Online convex optimization in the bandit setting: Gradient descent without a gradient. InSODA ’05 Proceedings of the sixteenth annual ACM- SIAM symposium on Discrete algorithms, pages 385–394, 2005
work page 2005
-
[28]
G. B. Folland.Real Analysis: Modern Techniques and Their Applications. Pure and Applied Mathematics. Wiley-Interscience, New York, 2 edition, 1999
work page 1999
-
[29]
M. Fornasier, H. Huang, J. Klemenc, and G. Malaspina. From consensus-based optimization to evolution strategies: Proof of global convergence, 2026. arXiv:2602.11677
- [30]
-
[31]
R. Gribonval and P. Machart. Reconciling “priors” & “priors” without prejudice? InAdvances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013
work page 2013
-
[32]
R. Gribonval and M. Nikolova. A characterization of proximity operators.Journal of Mathe- matical Imaging and Vision, 62(6):773–789, 2020. 11
work page 2020
-
[33]
T. C. Hesterberg.Advances in importance sampling. Stanford University, 1988
work page 1988
-
[34]
R. Holley and D. Stroock. Logarithmic sobolev inequalities and stochastic ising models.Journal of statistical physics, 46(5-6):1159–1194, 1987
work page 1987
- [35]
-
[36]
A. Kong. A note on importance sampling using standardized weights.University of Chicago, Dept. of Statistics, Tech. Rep, 348:14, 1992
work page 1992
- [37]
-
[38]
G. Lauga and S. Vaiter. Characterizations of inexact proximal operators, 2026. arXiv:2602.02022
-
[39]
Lemieux.Monte Carlo and Quasi-Monte Carlo Sampling
C. Lemieux.Monte Carlo and Quasi-Monte Carlo Sampling. Springer Series in Statistics. Springer, New York, NY , 2009
work page 2009
-
[40]
P. L. Lions and B. Mercier. Splitting algorithms for the sum of two nonlinear operators.SIAM Journal on Numerical Analysis, 16(6):964–979, 1979
work page 1979
-
[41]
J. S. Liu. Metropolized independent sampling with comparisons to rejection sampling and importance sampling.Statistics and computing, 6(2):113–119, 1996
work page 1996
-
[42]
S. Łojasiewicz. Une propriété topologique des sous-ensembles analytiques réels. InLes Équations aux Dérivées Partielles, pages 87–89, Paris, 1963. Éditions du Centre National de la Recherche Scientifique
work page 1963
-
[43]
X. Luo, X. Xu, and H. Rabitz. Asymptotic proximal point methods for global optimization. Journal of Scientific Computing, 105(3):87, 2025
work page 2025
- [44]
- [45]
-
[46]
D. Morales, P. Pérez-Aros, and E. Vilches. Convergence rates for stochastic proximal and projection estimators, 2026. arXiv:2602.06750
-
[47]
J.-J. Moreau. Proximité et dualité dans un espace hilbertien.Bulletin de la Société Mathématique de France, 93:273–299, 1965
work page 1965
-
[48]
Y . Nesterov and V . Spokoiny. Random gradient-free minimization of convex functions.Found. Comput. Math., 17(2):527–566, 2017
work page 2017
- [49]
-
[50]
M. Raginsky, A. Rakhlin, and M. Telgarsky. Non-convex learning via stochastic gradient Langevin dynamics: a nonasymptotic analysis. InProceedings of the 2017 Conference on Learning Theory, volume 65 ofProceedings of Machine Learning Research, pages 1674–1703. PMLR, 2017
work page 2017
-
[51]
M. Reed and B. Simon.Fourier Analysis, Self-Adjointness, volume 2 ofMethods of Modern Mathematical Physics. Academic Press, New York, 1975
work page 1975
-
[52]
K. Riedl, T. Klock, C. Geldhauser, and M. Fornasier. How consensus-based optimization can be interpreted as a stochastic relaxation of gradient descent. In2nd Differentiable Almost Everything Workshop at the 41st International Conference on Machine Learning (ICML), Vienna, Austria, 2024. 12
work page 2024
-
[53]
R. T. Rockafellar. Monotone operators and the proximal point algorithm.SIAM journal on control and optimization, 14(5):877–898, 1976
work page 1976
-
[54]
R. Y . Rubinstein and D. P. Kroese.Simulation and the Monte Carlo method. John Wiley & Sons, 2016
work page 2016
-
[55]
T. Salimans, J. Ho, X. Chen, S. Sidor, and I. Sutskever. Evolution strategies as a scalable alternative to reinforcement learning, 2017. arXiv:1703.03864
-
[56]
S. Salzo and S. Villa. Inexact and accelerated proximal point algorithms.Journal of Convex Analysis, 19(4):1167–1192, 2012
work page 2012
-
[57]
A. Saumard and J. A. Wellner. Log-concavity and strong log-concavity: a review.Statistics Surveys, 8:45–114, 2014
work page 2014
-
[58]
M. Schmidt, N. Le Roux, and F. Bach. Convergence rates of inexact proximal-gradient methods for convex optimization. InAdvances in Neural Information Processing Systems, volume 24, pages 1458–1466. Curran Associates, Inc., 2011
work page 2011
-
[59]
J. C. Spall.Introduction to Stochastic Search and Optimization. John Wiley & Sons, Inc., USA, 1 edition, 2003
work page 2003
-
[60]
R. J. Tibshirani, S. W. Fung, H. Heaton, and S. Osher. Laplace meets Moreau: Smooth approximation to infimal convolutions using Laplace’s method.Journal of Machine Learning Research, 26(72):1–36, 2025
work page 2025
-
[61]
M. J. Wainwright and M. I. Jordan. Graphical models, exponential families, and variational inference.Foundations and Trends in Machine Learning, 1(1–2):1–305, 2008
work page 2008
-
[62]
P. Xu, J. Chen, D. Zou, and Q. Gu. Global convergence of Langevin dynamics based algorithms for nonconvex optimization. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
work page 2018
-
[63]
X. Xu, Y . Sun, J. Liu, B. Wohlberg, and U. S. Kamilov. Provable convergence of Plug-and-Play priors with MMSE denoisers.IEEE Signal Processing Letters, 27:1280–1284, 2020
work page 2020
- [64]
-
[65]
Y . Zhang, P. Li, J. Hong, J. Li, Y . Zhang, W. Zheng, P.-Y . Chen, J. D. Lee, W. Yin, M. Hong, Z. Wang, S. Liu, and T. Chen. Revisiting zeroth-order optimization for memory-efficient LLM fine-tuning: A benchmark. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[66]
A. Åkerman, E. Chenchene, P. Giselsson, and E. Naldi. Splitting the forward-backward algorithm: A full characterization, 2025. arXiv:2504.10999. A Preliminaries Notation.To help the reader we summarize in Table 1 the notations used along the paper and in the appendix. A.1 Approximating the proximal operator with Hamilton-Jacobi Consider a functionf:R d →R...
-
[67]
and later extended to non-white noise B in [31]. The first result we give is partly a consequence of these works, but we also establish the surjectivity of the zeroth-order proximal operator zproxδ λ,f . By considering strictly positive Gibbs-type measures of the form e−f /δ satisfying Assumption 2.1, we demonstrate that the operator is not merely smooth,...
-
[68]
With the following result we provide convergence of the iterates and the rate on the residuals
Thus, fixed points are precisely stationary points off λ,δ (equivalently, stationary points ofZ λ,δ). With the following result we provide convergence of the iterates and the rate on the residuals. Theorem 10(Convergence of the iterates).Let f:R d →R satisfy Assumption 2.1. Then f λ,δ admits at least a minimizer, satisfies the KL property and the sequence...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.