Recognition: no theorem link
Learn to Think: Improving Multimodal Reasoning through Vision-Aware Self-Improvement Training
Pith reviewed 2026-05-13 06:04 UTC · model grok-4.3
The pith
VISTA corrects data imbalance and language prior bias in self-improvement training to boost multimodal reasoning in MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
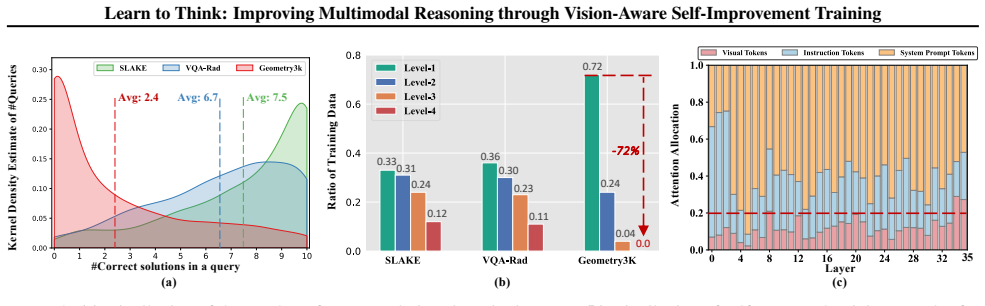
By introducing a prefix resampling strategy to reuse partial correct reasoning traces for efficient data collection and a vision-aware attention score to quantify the model's focus on visual information, VISTA mitigates data imbalance and language prior bias in self-generated reasoning data, resulting in improved multimodal reasoning capabilities when applied to supervised fine-tuning and preference learning across various MLLMs and tasks.
What carries the argument
VISTA's prefix resampling strategy paired with its vision-aware attention score, where the score calculates attention directed to visual tokens to promote image-grounded reasoning over linguistic shortcuts.
Load-bearing premise
That the prefix resampling strategy reuses partial traces without introducing new biases and that the vision-aware attention score reliably quantifies and corrects language prior bias in a way that directly causes performance gains.
What would settle it
Ablating the vision-aware attention score during training and checking whether performance gains disappear on tasks that require strong visual grounding, such as diagram-based problem solving or counting objects in complex scenes.
Figures











read the original abstract
Post-training with explicit reasoning traces is common to improve the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, acquiring high-quality reasoning traces is often costly and time-consuming. Hence, the self-improvement paradigm has emerged, enabling MLLMs to self-generate reasoning traces for training without external supervision. Despite its effectiveness, we reveal two shortcomings in the self-improvement training of MLLMs: 1) data imbalance, where simple samples are over-trained, but the challenging yet crucial samples are under-trained; 2) language prior bias, where MLLMs overly rely on linguistic priors while neglecting the visual cues. To this end, we propose VISTA, a vision-aware self-improvement training framework for enhancing the multimodal reasoning of MLLMs. Specifically, VISTA first introduces a prefix resampling strategy to reuse the partial correct reasoning traces for efficient data collection, and then designs a vision-aware attention score to quantify the model's focus on visual information. Extensive experiments show that VISTA can be applied to various post-training scenarios, i.e., supervised fine-tuning and preference learning, and effectively enhances the multimodal reasoning performance across various MLLMs and tasks, e.g., bringing up to +13.66% average performance gains for Qwen2.5-VL-3B-Instruct.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper presents VISTA as an empirical self-improvement method using prefix resampling and a vision-aware attention score, with all performance claims (+13.66% on Qwen2.5-VL-3B-Instruct) reported strictly as outcomes of experiments across MLLMs and tasks. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmarks and ablations rather than reducing to inputs by construction, making the work self-contained with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of gradient-based optimization and attention mechanisms in transformer models
invented entities (1)
-
Vision-aware attention score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Azaria, A. and Mitchell, T. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023,
work page 2023
-
[2]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3- vl technical report.arXiv preprint arXiv:2511.21631, 2025a. Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025b. Bai, Z., Wang,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Huatuogpt-o1, towards medical com- plex reasoning with llms.arXiv:2412.18925, 2024
Chen, J., Cai, Z., Ji, K., Wang, X., Liu, W., Wang, R., Hou, J., and Wang, B. Huatuogpt-o1, towards medical complex reasoning with llms.arXiv preprint arXiv:2412.18925,
-
[4]
Vision-language models can self-improve reasoning via reflection
Cheng, K., YanTao, L., Xu, F., Zhang, J., Zhou, H., and Liu, Y . Vision-language models can self-improve reasoning via reflection. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),
work page 2025
-
[5]
Self- improvement in multimodal large language models: A survey
Deng, S., Wang, K., Yang, T., Singh, H., and Tian, Y . Self- improvement in multimodal large language models: A survey. InFindings of the Association for Computational Linguistics: EMNLP 2025,
work page 2025
-
[6]
Mitigating tail narrowing in llm self-improvement via socratic-guided sampling
Ding, Y ., Xi, Z., He, W., Lizhuoyuan, L., Zhai, Y ., Xi- aowei, S., Cai, X., Gui, T., Zhang, Q., and Huang, X.-J. Mitigating tail narrowing in llm self-improvement via socratic-guided sampling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies,
work page 2025
-
[7]
Reinforced Self-Training (ReST) for Language Modeling
Gulcehre, C., Paine, T. L., Srinivasan, S., Konyushkova, K., Weerts, L., Sharma, A., Siddhant, A., Ahern, A., Wang, M., Gu, C., et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998,
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
PathVQA: 30000+ Questions for Medical Visual Question Answering
He, X., Zhang, Y ., Mou, L., Xing, E., and Xie, P. Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286,
work page internal anchor Pith review arXiv 2003
-
[10]
J., Rohatgi, D., Zhang, C., Simchowitz, M., Ash, J
Huang, A., Block, A., Foster, D. J., Rohatgi, D., Zhang, C., Simchowitz, M., Ash, J. T., and Krishnamurthy, A. Self-improvement in language models: The sharpening mechanism. InThe Thirteenth International Conference on Learning Representations, 2025a. Huang, J., Gu, S., Hou, L., Wu, Y ., Wang, X., Yu, H., and Han, J. Large language models can self-improve...
work page 2023
-
[11]
Visual hallucina- tions of multi-modal large language models
Huang, W., Liu, H., Guo, M., and Gong, N. Visual hallucina- tions of multi-modal large language models. InFindings of the Association for Computational Linguistics: ACL 2024,
work page 2024
-
[12]
Huang, X., Wu, J., Liu, H., Tang, X., and Zhou, Y . Medvl- thinker: Simple baselines for multimodal medical reason- ing.arXiv preprint arXiv:2508.02669, 2025b. Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
-
[13]
Ji, K., Xu, J., Liang, T., Liu, Q., He, Z., Chen, X., Liu, X., Wang, Z., Chen, J., Wang, B., et al. The first few tokens are all you need: An efficient and effective unsupervised prefix fine-tuning method for reasoning models.arXiv preprint arXiv:2503.02875,
-
[14]
Liu, C., Xu, Z., Wei, Q., Wu, J., Zou, J., Wang, X. E., Zhou, Y ., and Liu, S. More thinking, less seeing? assessing amplified hallucination in multimodal reasoning models. arXiv preprint arXiv:2505.21523, 2025a. Liu, N. F., Gardner, M., Belinkov, Y ., Peters, M. E., and Smith, N. A. Linguistic knowledge and transferability of contextual representations. ...
-
[15]
Masry, A., Do, X. L., Tan, J. Q., Joty, S., and Hoque, E. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022,
work page 2022
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Wang, Y ., Chen, W., Han, X., Lin, X., Zhao, H., Liu, Y ., Zhai, B., Yuan, J., You, Q., and Yang, H. Exploring the reasoning abilities of multimodal large language models (mllms): A comprehensive survey on emerging trends in multimodal reasoning.arXiv preprint arXiv:2401.06805, 2024b. Wang, Y ., Wu, S., Zhang, Y ., Yan, S., Liu, Z., Luo, J., and Fei, H. M...
-
[18]
Wen, X., Liu, Z., Zheng, S., Ye, S., Wu, Z., Wang, Y ., Xu, Z., Liang, X., Li, J., Miao, Z., et al. Reinforcement learn- ing with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245,
work page internal anchor Pith review arXiv
-
[19]
arXiv preprint arXiv:2506.07044 (2025)
Xu, W., Chan, H. P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu, C., Li, Z., et al. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044,
-
[20]
arXiv preprint arXiv:2504.15895 , year=
Yang, C., Si, Q., Duan, Y ., Zhu, Z., Zhu, C., Li, Q., Lin, Z., Cao, L., and Wang, W. Dynamic early exit in reasoning models.arXiv preprint arXiv:2504.15895, 2025a. Yang, S., Tong, Y ., Niu, X., Neubig, G., and Yue, X. Demys- tifying long chain-of-thought reasoning. InForty-second International Conference on Machine Learning, 2025b. Yuan, Z., Yuan, H., Li...
-
[21]
Zhang, Y ., Zhang, Z., Wei, X., Liu, X., Zhai, G., and Min, X. Illusionbench: A large-scale and comprehensive bench- mark for visual illusion understanding in vision-language models.arXiv preprint arXiv:2501.00848,
-
[22]
Zheng, H., Xu, T., Sun, H., Pu, S., Chen, R., and Sun, L. Thinking before looking: Improving multimodal llm rea- soning via mitigating visual hallucination.arXiv preprint arXiv:2411.12591,
-
[23]
Kaft: Knowledge-aware fine-tuning for boosting llms’ domain-specific question-answering performance
Zhong, Q., Ding, L., Cai, X., Liu, J., Du, B., and Tao, D. Kaft: Knowledge-aware fine-tuning for boosting llms’ domain-specific question-answering performance. In Findings of the Association for Computational Linguis- tics: ACL 2025,
work page 2025
-
[24]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhong, Q., Ding, L., Liu, J., Du, B., Rutkowski, L., and Tao, D. Better, faster: Harnessing self-improvement in large reasoning models.arXiv preprint, 2026a. Zhong, Q., Wang, K., Xu, Z., Ding, L., Liu, J., and Du, B. Achieving> 97% on gsm8k: Deeply understanding the problems makes llms better solvers for math word problems.Frontiers of Computer Science, 2...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
and OpenAI o1 (Jaech et al., 2024), in a diversity of natural language processing tasks (Shao et al., 2024; Chen et al., 2024; Zhong et al., 2026b). Motivated by this, extending the advantage of long-CoT reasoning to multimodal context has attracted significant interest (Wang et al., 2024b; 2025; Zhu et al., 2025; Bai et al., 2025b;a). To achieve this goa...
work page 2024
-
[26]
does not strictly require the explicit reasoning trajectories, cold-start training with these trajectories can effectively improve the performance and training efficiency (Yang et al., 2025b), which also underscores the importance of these trajectories. Self-improvement Training for MLLMs.To reduce the reliance on explicit reasoning trajectories, a “self-...
work page 2022
-
[27]
In the preference learning setting, Pang et al
extend STaR by sampling multiple responses for each question. In the preference learning setting, Pang et al. (2024) and Wang et al. (2024a) propose to construct preference pairs by using the self-generated correct responses as the pair winners and the incorrect responses as the pair losers. Recent advances attempt to extend self-improvement training to m...
work page 2024
-
[28]
and designing metrics to measure the language priors (He et al., 2025; Liu et al., 2025a). However, these efforts either fail to exploit prior failed solutions fully or rely on external models and additional computational overhead to estimate the language prior bias. Different from them, we propose two simple-yet-effective approaches to address these prob...
work page 2025
-
[29]
is a widely-used medical visual question-answering (VQA) task, which contains both 13 Learn to Think: Improving Multimodal Reasoning through Vision-Aware Self-Improvement Training Does the picture contain lung?A.Yes B.No SLAKE ✔ <think>Todetermineiftheimagecontainslung,Ianalyzedthecontent.Theimageappearstobeacross-secDonalscanofathoracicregion,typicallyus...
work page 2017
-
[30]
In the DPO training phase, the batch size is set to 16, and the peak learning rate is set to 1e-5
The max image pixels are set to 512×512 . In the DPO training phase, the batch size is set to 16, and the peak learning rate is set to 1e-5. All models are trained for 3 epochs. Both SFT and DPO training are performed using the popular LLaMA-Factory4 toolkit, following prior work (Zhong et al., 2025). As for GRPO training, the batch size is set to 32, and...
work page 2025
-
[31]
We use the EasyR15 as the training framework of GRPO
Each model is trained for 3 epochs. We use the EasyR15 as the training framework of GRPO. Notably, for the model optimizer of all settings, we keep the vision encoder and multimodal projector fixed, and only update the parameters of the LLM backbone. All experiments are conducted on 8 NVIDIA A800 (80GB) GPUs. For the model evaluation, we use the greedy de...
work page 2025
-
[32]
We observe that when k is too small (k=1), the model suffers from over-calibration, truncating at very early prefix tokens and degrading sampling efficiency. Conversely, when k is too large (k=50), the model overlooks many critical tokens, reducing the effectiveness of prefix resampling. With k=5, the model achieves the best overall performance, and we th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.