Recognition: 2 theorem links
· Lean TheoremInteractive State Space Model with Cross-Modal Local Scanning for Depth Super-Resolution
Pith reviewed 2026-05-13 05:57 UTC · model grok-4.3
The pith
The paper claims that an Interactive State Space Model with cross-modal local scanning enables dense semantic interactions between RGB and depth features for guided super-resolution while keeping global modeling at linear complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
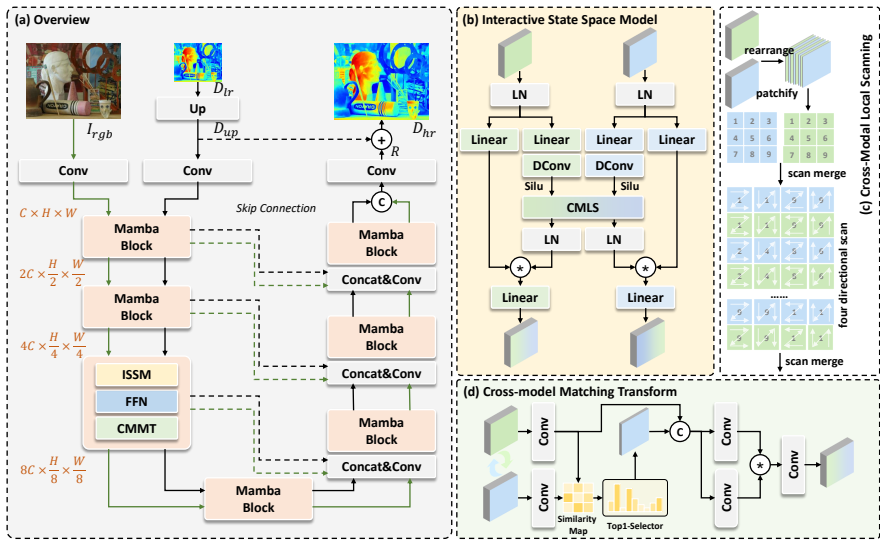
We propose a novel GDSR framework centered around the Interactive State Space Model. We design a cross-modal local scanning mechanism that enables fine-grained semantic interactions between RGB and depth features. Leveraging the Mamba architecture, our framework achieves global modeling with linear complexity. A cross-modal matching transform module is introduced to enhance interactive modeling quality by utilizing representative features from both modalities.
What carries the argument
The Interactive State Space Model equipped with cross-modal local scanning and a matching transform, which performs dense semantic exchanges between RGB and depth feature maps inside a linear-complexity global model.
If this is right
- Global context is modeled across both modalities at linear rather than quadratic cost.
- Fine-grained semantic interactions occur through local cross-modal scanning without separate per-modality processing.
- Representative features selected by the matching transform improve the quality of those interactions.
- The resulting depth maps achieve competitive accuracy against attention-heavy state-of-the-art methods on existing datasets.
Where Pith is reading between the lines
- The same local-scanning pattern could be tested on other paired-modality tasks such as RGB-guided semantic segmentation or optical-flow estimation.
- Linear scaling makes higher-resolution or video-rate depth reconstruction feasible on resource-limited hardware.
- If the observed semantic correlations weaken under heavy sensor noise or domain shift, performance would be expected to degrade unless the scanning window is adapted.
Load-bearing premise
Feature maps from RGB and depth inputs develop semantic-level correlations that cross-modal local scanning and matching can reliably exploit to produce useful dense interactions.
What would settle it
Removing the cross-modal local scanning and matching modules produces no measurable drop in depth reconstruction accuracy on standard GDSR benchmarks while still preserving linear runtime.
Figures

read the original abstract
Guided depth super-resolution (GDSR) reconstructs HR depth maps from LR inputs with HR RGB guidance. Existing methods either model each modality independently or rely on computationally expensive attention mechanisms with quadratic complexity, hindering the establishment of efficient and semantically interactive joint representations. In this paper, we observe that feature maps from different modalities exhibit semantic-level correlations during feature extraction. This motivates us to develop a more flexible approach enabling dense, semantically-aware deep interactions between modalities. To this end, we propose a novel GDSR framework centered around the Interactive State Space Model. Specifically, we design a cross-modal local scanning mechanism that enables fine-grained semantic interactions between RGB and depth features. Leveraging the Mamba architecture, our framework achieves global modeling with linear complexity. Furthermore, a cross-modal matching transform module is introduced to enhance interactive modeling quality by utilizing representative features from both modalities. Extensive experiments demonstrate competitive performance against state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel Guided Depth Super-Resolution (GDSR) framework centered on an Interactive State Space Model. It introduces a cross-modal local scanning mechanism to enable fine-grained semantic interactions between RGB and depth features, combined with a cross-modal matching transform module that uses representative features from both modalities. Leveraging the Mamba architecture, the method claims to achieve global modeling with linear complexity while delivering competitive performance against state-of-the-art approaches.
Significance. If the empirical claims hold, the work could advance efficient multi-modal fusion by replacing quadratic attention with linear-complexity state-space modeling for cross-modal tasks. The emphasis on semantic-level interactions via local scanning offers a potentially scalable direction for depth super-resolution and related vision problems where computational cost is a bottleneck.
major comments (2)
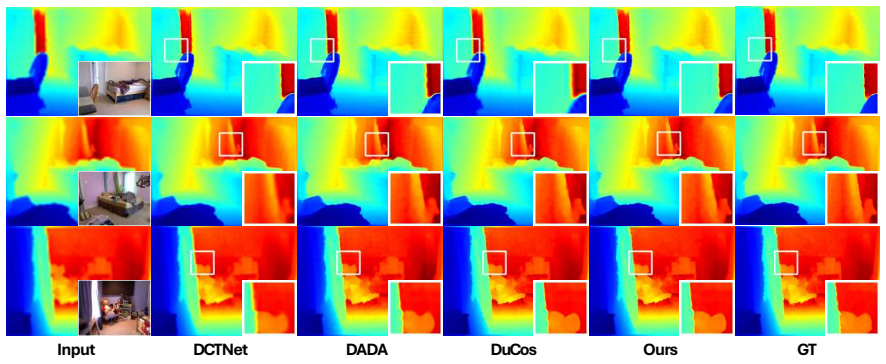
- [Abstract and §4] Abstract and §4 (Experiments): the claim of 'competitive performance against state-of-the-art methods' is unsupported by any reported PSNR, SSIM, or error metrics, ablation tables, or quantitative comparisons; without these numbers the central claim that the proposed modules deliver measurable dense semantic fusion cannot be evaluated.
- [§3.2 and §3.3] §3.2 (Cross-Modal Local Scanning Mechanism) and §3.3 (Cross-Modal Matching Transform): the load-bearing assumption that feature maps exhibit exploitable semantic-level correlations and that the scanning-plus-matching modules produce denser interactions than prior fusion methods is stated motivationally but lacks isolated ablation or visualization evidence showing the interactions are semantic rather than superficial concatenation.
minor comments (2)
- [§3.1] Clarify the precise definition of the Interactive State Space Model and its departure from standard Mamba blocks, including any additional parameters introduced by the cross-modal components.
- [§3 and Appendix] Add a table or figure caption that explicitly lists the Mamba and scanning hyperparameters so readers can reproduce the linear-complexity claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the empirical support and clarity of our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of 'competitive performance against state-of-the-art methods' is unsupported by any reported PSNR, SSIM, or error metrics, ablation tables, or quantitative comparisons; without these numbers the central claim that the proposed modules deliver measurable dense semantic fusion cannot be evaluated.
Authors: We agree that the current presentation does not sufficiently support the performance claim with explicit numbers. Although the manuscript states that extensive experiments were conducted, we will revise the abstract and §4 to include quantitative tables reporting PSNR, SSIM, and RMSE on standard GDSR benchmarks (e.g., NYU-Depth-V2, Middlebury) with direct comparisons to recent state-of-the-art methods. We will also add a summary of these results in the abstract to make the competitive performance claim verifiable. revision: yes
-
Referee: [§3.2 and §3.3] §3.2 (Cross-Modal Local Scanning Mechanism) and §3.3 (Cross-Modal Matching Transform): the load-bearing assumption that feature maps exhibit exploitable semantic-level correlations and that the scanning-plus-matching modules produce denser interactions than prior fusion methods is stated motivationally but lacks isolated ablation or visualization evidence showing the interactions are semantic rather than superficial concatenation.
Authors: We accept that additional evidence is required to demonstrate the semantic nature of the interactions. In the revised version, we will insert isolated ablation studies that isolate the contribution of the cross-modal local scanning mechanism and the cross-modal matching transform, including quantitative metrics on their effect on fusion quality. We will also add visualizations of representative feature maps before and after the modules to illustrate the captured semantic correlations, thereby distinguishing the approach from simple feature concatenation. revision: yes
Circularity Check
No circularity: novel architectural components introduced without reduction to inputs or self-citations
full rationale
The paper's derivation chain consists of an empirical observation about semantic correlations in feature maps, followed by the proposal of new modules (cross-modal local scanning, Interactive State Space Model based on Mamba, and cross-modal matching transform) to enable dense interactions with linear complexity. These are presented as design choices motivated by the observation and the limitations of prior attention-based methods, with no equations or steps that define a quantity in terms of itself, rename a fitted parameter as a prediction, or rely on load-bearing self-citations whose validity depends on the current work. The central claims concern the architecture's efficiency and performance, which are evaluated empirically rather than derived tautologically from the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Mamba and scanning hyperparameters
axioms (1)
- standard math State-space models can capture long-range dependencies with linear complexity
invented entities (3)
-
Interactive State Space Model
no independent evidence
-
cross-modal local scanning mechanism
no independent evidence
-
cross-modal matching transform module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearwe observe that feature maps from different modalities exhibit semantic-level correlations... cross-modal local scanning mechanism... Leveraging the Mamba architecture, our framework achieves global modeling with linear complexity... cross-modal matching transform module
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCMLS mechanism... rearrange, patchify, and S6 scanning... CMMT... similarity matrix M... Top1-Selector
Reference graph
Works this paper leans on
-
[1]
Y . Wang, W.-L. Chao, D. Garg, B. Hariharan, M. Campbell, and K. Q. Weinberger, “Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8445–8453
work page 2019
-
[2]
A survey of autonomous driving: Common practices and emerging technologies,
E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda, “A survey of autonomous driving: Common practices and emerging technologies,” IEEE access, vol. 8, pp. 58 443–58 469, 2020
work page 2020
-
[3]
3d object recognition system based on local shape descriptors and depth data analysis,
C. L. Chowdhary, “3d object recognition system based on local shape descriptors and depth data analysis,”Recent Patents on Computer Science, vol. 12, no. 1, pp. 18–24, 2019
work page 2019
-
[4]
F. Bonetti, G. Warnaby, and L. Quinn, “Augmented reality and virtual reality in physical and online retailing: A review, synthesis and research agenda,”Augmented reality and virtual reality, pp. 119–132, 2018
work page 2018
-
[5]
G. C. Burdea and P. Coiffet,Virtual reality technology. John Wiley & Sons, 2003
work page 2003
-
[6]
Sgnet: Structure guided network via gradient-frequency awareness for depth map super-resolution,
Z. Wang, Z. Yan, and J. Yang, “Sgnet: Structure guided network via gradient-frequency awareness for depth map super-resolution,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5823–5831
work page 2024
-
[7]
Atgv-net: Accurate depth super- resolution,
G. Riegler, M. R ¨uther, and H. Bischof, “Atgv-net: Accurate depth super- resolution,” inEuropean conference on computer vision. Springer, 2016, pp. 268–284
work page 2016
-
[8]
X. Song, Y . Dai, and X. Qin, “Deep depth super-resolution: Learning depth super-resolution using deep convolutional neural network,” in Asian conference on computer vision. Springer, 2016, pp. 360–376
work page 2016
-
[9]
Perceptual deep depth super-resolution,
O. V oynov, A. Artemov, V . Egiazarian, A. Notchenko, G. Bobrovskikh, E. Burnaev, and D. Zorin, “Perceptual deep depth super-resolution,” in Proceedings of the ieee/cvf international conference on computer vision, 2019, pp. 5653–5663
work page 2019
-
[10]
Ultra-high- definition image restoration via high-frequency enhanced transformer,
C. Wu, L. Wang, Z. Zheng, W. Jiang, Y . Cui, and J. Xia, “Ultra-high- definition image restoration via high-frequency enhanced transformer,” IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[11]
Dap-led: Learning degradation-aware priors with clip for joint low-light enhancement and deblurring,
L. Wang, C. Wu, and L. Wang, “Dap-led: Learning degradation-aware priors with clip for joint low-light enhancement and deblurring,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 15 791–15 797
work page 2025
-
[12]
Adaptive feature selection modulation network for efficient image super-resolution,
C. Wu, L. Wang, X. Su, and Z. Zheng, “Adaptive feature selection modulation network for efficient image super-resolution,”IEEE Signal Processing Letters, 2025
work page 2025
-
[13]
Mixnet: Efficient global modeling for ultra-high-definition image restoration,
W. Chen, S. Sun, Y . Zhang, and Z. Zheng, “Mixnet: Efficient global modeling for ultra-high-definition image restoration,”Neurocomputing, p. 131130, 2025
work page 2025
-
[14]
Recurrent structure attention guidance for depth super-resolution,
J. Yuan, H. Jiang, X. Li, J. Qian, J. Li, and J. Yang, “Recurrent structure attention guidance for depth super-resolution,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 3, 2023, pp. 3331–3339
work page 2023
-
[15]
Delving into transformer-based network architecture for guided depth super-resolution,
X. Ye, A. Zhang, R. Xu, and H. Li, “Delving into transformer-based network architecture for guided depth super-resolution,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[16]
Symmetric uncertainty-aware feature transmission for depth super-resolution,
W. Shi, M. Ye, and B. Du, “Symmetric uncertainty-aware feature transmission for depth super-resolution,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 3867–3876
work page 2022
-
[17]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inFirst Conference on Language Modeling, 2024
work page 2024
-
[18]
arXiv preprint arXiv:2501.16583 (2025)
L. Peng, X. Di, Z. Feng, W. Li, R. Pei, Y . Wang, X. Fu, Y . Cao, and Z.-J. Zha, “Directing mamba to complex textures: An efficient texture-aware state space model for image restoration,”arXiv preprint arXiv:2501.16583, 2025
-
[19]
Multi-scale representation learning for image restoration with state-space model,
Y . He, L. Peng, Q. Yi, C. Wu, and L. Wang, “Multi-scale representation learning for image restoration with state-space model,”arXiv preprint arXiv:2408.10145, 2024
-
[20]
S3mamba: Arbitrary-scale super-resolution via scaleable state space model,
P. Xia, L. Peng, X. Di, R. Pei, Y . Wang, Y . Cao, and Z.-J. Zha, “S3mamba: Arbitrary-scale super-resolution via scaleable state space model,”arXiv preprint arXiv:2411.11906, vol. 6, 2024
-
[21]
W. Xu, C. Wu, Q. Yin, L. Wang, Z. Zheng, and D. Huang, “Fusion requires interaction: A hybrid mamba-transformer architecture for deep interactive fusion of multi-modal images,”Expert Systems with Appli- cations, p. 131309, 2026
work page 2026
-
[22]
Localmamba: Visual state space model with windowed selective scan,
T. Huang, X. Pei, S. You, F. Wang, C. Qian, and C. Xu, “Localmamba: Visual state space model with windowed selective scan,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 12–22
work page 2024
-
[23]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
work page 2016
-
[24]
Metaformer is actually what you need for vision,
W. Yu, M. Luo, P. Zhou, C. Si, Y . Zhou, X. Wang, J. Feng, and S. Yan, “Metaformer is actually what you need for vision,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 819–10 829
work page 2022
-
[25]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5728–5739
work page 2022
-
[26]
Y . Li, J.-B. Huang, N. Ahuja, and M.-H. Yang, “Deep joint image filtering,” inEuropean conference on computer vision. Springer, 2016, pp. 154–169
work page 2016
-
[27]
Joint image filtering with deep convolutional networks,
——, “Joint image filtering with deep convolutional networks,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 8, pp. 1909–1923, 2019
work page 1909
-
[28]
Deep convolutional neural network for multi-modal image restoration and fusion,
X. Deng and P. L. Dragotti, “Deep convolutional neural network for multi-modal image restoration and fusion,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 10, pp. 3333–3348, 2020
work page 2020
-
[29]
Deformable kernel networks for joint image filtering,
B. Kim, J. Ponce, and B. Ham, “Deformable kernel networks for joint image filtering,”International Journal of Computer Vision, vol. 129, no. 2, pp. 579–600, 2021
work page 2021
-
[30]
Towards fast and accurate real-world depth super-resolution: Benchmark dataset and baseline,
L. He, H. Zhu, F. Li, H. Bai, R. Cong, C. Zhang, C. Lin, M. Liu, and Y . Zhao, “Towards fast and accurate real-world depth super-resolution: Benchmark dataset and baseline,” inProceedings of the ieee/cvf confer- ence on computer vision and pattern recognition, 2021, pp. 9229–9238
work page 2021
-
[31]
Discrete cosine trans- form network for guided depth map super-resolution,
Z. Zhao, J. Zhang, S. Xu, Z. Lin, and H. Pfister, “Discrete cosine trans- form network for guided depth map super-resolution,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5697–5707
work page 2022
-
[32]
Guided depth super- resolution by deep anisotropic diffusion,
N. Metzger, R. C. Daudt, and K. Schindler, “Guided depth super- resolution by deep anisotropic diffusion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 237–18 246
work page 2023
-
[33]
Ducos: Duality constrained depth super-resolution via foundation model,
Z. Yan, Z. Wang, H. Dong, J. Li, J. Yang, and G. H. Lee, “Ducos: Duality constrained depth super-resolution via foundation model,”arXiv preprint arXiv:2503.04171, 2025
-
[34]
Indoor segmentation and support inference from rgbd images,
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus, “Indoor segmentation and support inference from rgbd images,” inEuropean conference on computer vision. Springer, 2012, pp. 746–760
work page 2012
-
[35]
Evaluation of cost functions for stereo matching,
H. Hirschmuller and D. Scharstein, “Evaluation of cost functions for stereo matching,” in2007 IEEE conference on computer vision and pattern recognition. IEEE, 2007, pp. 1–8
work page 2007
-
[36]
Learning conditional random fields for stereo,
D. Scharstein and C. Pal, “Learning conditional random fields for stereo,” in2007 IEEE conference on computer vision and pattern recognition. IEEE, 2007, pp. 1–8
work page 2007
-
[37]
Depth enhancement via low-rank matrix completion,
S. Lu, X. Ren, and F. Liu, “Depth enhancement via low-rank matrix completion,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 3390–3397
work page 2014
-
[38]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind, “Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 912–10 922
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.