Recognition: no theorem link
From Noise to Diversity: Random Embedding Injection in LLM Reasoning
Pith reviewed 2026-05-13 05:39 UTC · model grok-4.3
The pith
Appending fresh random embedding vectors to LLM inputs matches the accuracy of trained soft prompts on math reasoning by flattening early token probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Random Soft Prompts consist of a freshly sampled sequence of random embedding vectors drawn from an isotropic Gaussian fitted to the mean and variance of the pretrained embedding table; these vectors carry no task-specific information yet produce accuracy on math reasoning tasks that matches optimized soft prompts in multiple settings. The mechanism works in two stages: the unseen random position forces attention to flatten the distribution over the initial generated tokens, causing reasoning trajectories to branch, after which the effect naturally dilutes so the model settles on a single completion. During inference the prompts increase early-stage token diversity and, together with higher-
What carries the argument
Random Soft Prompts (RSPs): a training-free sequence of random embedding vectors freshly sampled from the model's embedding statistics and appended to the input, whose only role is to occupy an unseen position.
If this is right
- RSPs isolate the structural effect of injection that all soft-prompt variants share regardless of training.
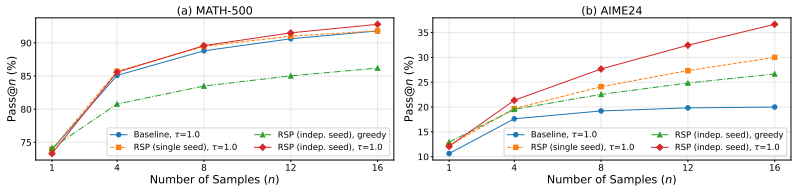
- Early token diversity rises during generation, which widens Pass@N when temperature sampling is applied.
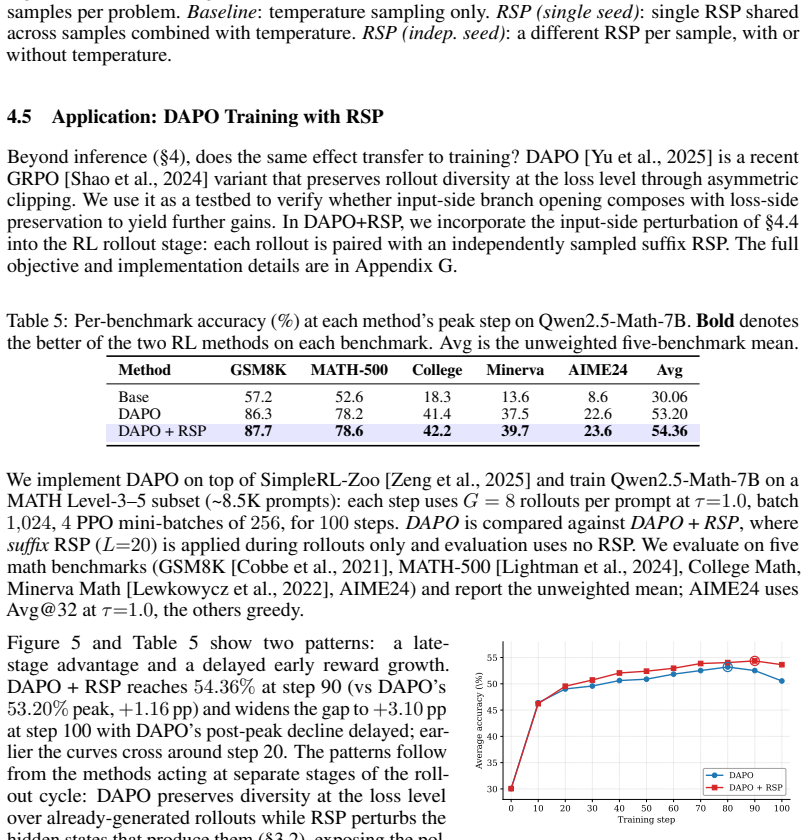
- The same injection effect transfers from inference into DAPO training and yields measurable gains there.
- The influence of the random position dilutes naturally as generation proceeds, allowing the model to converge on a coherent answer.
Where Pith is reading between the lines
- If the benefit is purely structural, then simpler forms of position noise such as random padding tokens or fixed but unseen vectors might produce similar diversity increases without sampling new vectors each time.
- The two-stage pattern (early branching followed by commitment) suggests the method could be tuned by varying the number of appended vectors to control how long the exploration phase lasts.
- Extending the approach to non-math domains would test whether the flattening effect generalizes beyond the structured step-by-step nature of mathematical reasoning.
Load-bearing premise
The accuracy and diversity gains are produced by the attention mechanism processing an unfamiliar random position rather than by any accidental statistical resemblance between the random vectors and the actual task.
What would settle it
Run the same benchmarks with random vectors whose entrywise statistics are deliberately altered to remove any possible match to task-related embeddings while still keeping them unseen; if performance remains equal to trained soft prompts the claim holds, but if the gains disappear the structural-injection account is falsified.
Figures



read the original abstract
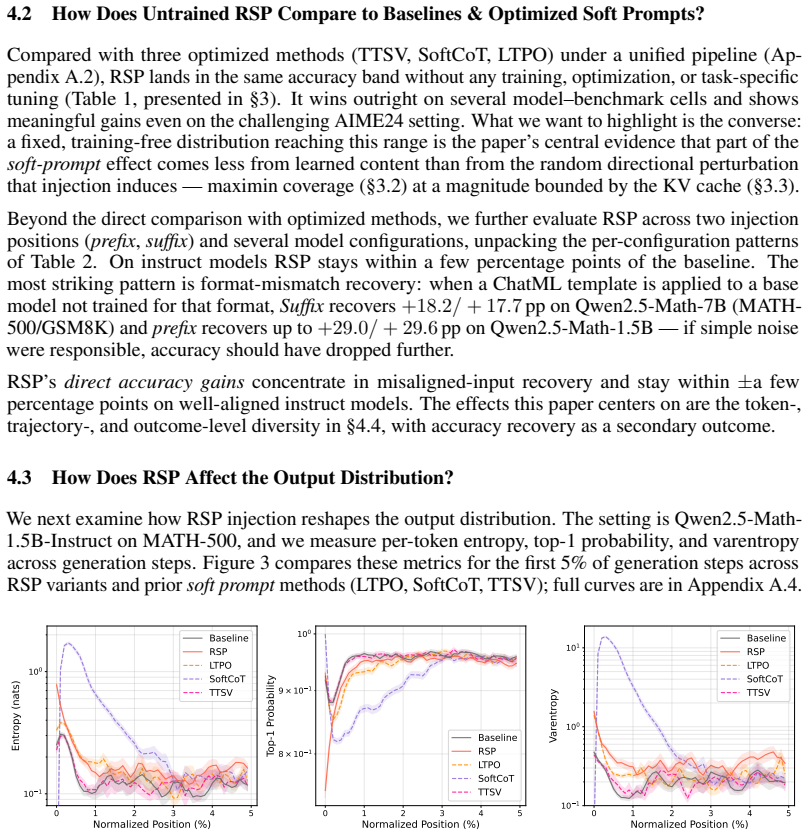
Recent soft prompt research has tried to improve reasoning by inserting trained vectors into LLM inputs, yet whether the gain comes from the learned content or from the act of injection itself has not been carefully separated. We study Random Soft Prompts (RSPs), which drop the training step entirely and append a freshly drawn sequence of random embedding vectors to the input. Each RSP vector is sampled from an isotropic Gaussian fitted to the entrywise mean and variance of the pretrained embedding table; the sequence carries no learned content, and yet reaches accuracy comparable to optimized soft prompts on math reasoning benchmarks in several settings. The mechanism unfolds in two stages: because attention has to absorb a never-seen-before random position, the distribution over the first few generated tokens flattens and reasoning trajectories branch, and as generation continues this influence dilutes naturally so the response commits to a single completion. We show that during inference RSPs lift early-stage token diversity and, combined with temperature sampling, widen Pass@N, the probability that at least one out of N attempts is correct. Beyond inference, we carry the same effect into DAPO training and demonstrate practical gains. Our contributions are: (i) RSP isolates the simplest form of soft prompt -- training-free, freshly resampled -- providing a unified lens for the structural effect of injection that variants otherwise differing in training and form all share; (ii) a theoretical and empirical validation of the underlying mechanism; and (iii) an extension from inference to training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that appending sequences of random embedding vectors—sampled from an isotropic Gaussian fitted once to the entrywise mean and variance of the pretrained embedding table—to LLM inputs, without any training, yields accuracy on math reasoning benchmarks comparable to optimized soft prompts. The mechanism is that attention must absorb a never-seen-before random position, flattening early-token distributions, increasing reasoning-trajectory diversity, and widening Pass@N under temperature sampling; the same injection is carried into DAPO training.
Significance. If the results hold after controls, the work supplies a clean training-free baseline that isolates the structural effect of injection itself, offering a unified lens on soft-prompt variants and a practical route to diversity gains in reasoning. The reported empirical comparability on math benchmarks and the extension to DAPO training are concrete strengths.
major comments (1)
- [mechanism validation and experimental results] § on mechanism validation and experimental results: the central claim that gains arise from the structural novelty of an unseen position (rather than residual statistical match) is load-bearing, yet no ablations are reported that keep injection format and length fixed while breaking the first- and second-moment match (e.g., zero vectors, shifted-mean Gaussians, or uniform sampling). Without these, the two-stage flattening-and-dilution account cannot be isolated from distributional compatibility.
minor comments (2)
- [Abstract and results] Abstract and results: accuracy comparisons are stated as 'comparable' without error bars, statistical tests, or explicit length-matched random-token baselines, making quantitative assessment of the claim difficult.
- [experimental results] No ablation on RSP vector length or sampling-distribution parameters is described, leaving the robustness of the reported gains unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address the single major comment on mechanism validation below and will revise the manuscript to incorporate the requested controls.
read point-by-point responses
-
Referee: § on mechanism validation and experimental results: the central claim that gains arise from the structural novelty of an unseen position (rather than residual statistical match) is load-bearing, yet no ablations are reported that keep injection format and length fixed while breaking the first- and second-moment match (e.g., zero vectors, shifted-mean Gaussians, or uniform sampling). Without these, the two-stage flattening-and-dilution account cannot be isolated from distributional compatibility.
Authors: We agree that the suggested ablations are necessary to rigorously separate the structural effect of an unseen position from any residual first- or second-moment compatibility. The current manuscript shows that moment-matched isotropic Gaussian sampling yields performance comparable to trained soft prompts and empirically increases early-token entropy, but does not report the exact controls listed. In the revised manuscript we will add a dedicated ablation subsection that keeps injection length and format identical while using (i) zero vectors, (ii) Gaussians whose mean is shifted by 2–4 standard deviations, and (iii) uniform sampling over the observed embedding range. These results will be placed alongside the existing RSP curves to test whether the flattening-and-dilution mechanism persists when moment matching is deliberately broken. We expect the diversity gains to remain driven primarily by positional novelty, but will report the data transparently regardless of outcome. revision: yes
Circularity Check
No significant circularity; empirical results independent of fitted sampling distribution
full rationale
The paper's core claims rest on empirical measurements of RSP performance on math reasoning benchmarks and observed changes in token diversity/Pass@N, rather than any closed-form derivation. The Gaussian parameters are fitted once to the fixed embedding table and then used only to draw fresh vectors at inference time; downstream accuracy and diversity metrics are evaluated on separate tasks and are not algebraically forced by the moment-matching step. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the central mechanism, and the proposed attention-flattening account is presented as an interpretation of the measurements rather than a reduction to the input distribution by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- embedding mean and variance
axioms (1)
- domain assumption Transformer attention allocates capacity to every input position regardless of content
Reference graph
Works this paper leans on
-
[1]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. Eliciting Latent Predictions from Transformers with the Tuned Lens . arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation . In Findings of ACL, 2024
work page 2024
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems . arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Jeremy M. Cohen, Elan Rosenfeld, and J. Zico Kolter. Certified Adversarial Robustness via Randomized Smoothing . In ICML, 2019
work page 2019
-
[6]
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise
Martin Ester, Hans-Peter Kriegel, J \"o rg Sander, and Xiaowei Xu. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise . In KDD, 1996
work page 1996
-
[7]
Noisy Networks for Exploration
Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Ian Osband, Alex Graves, Vlad Mnih, Remi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, and Shane Legg. Noisy Networks for Exploration . In ICLR, 2018
work page 2018
-
[8]
Transformer Feed-Forward Layers Are Key-Value Memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer Feed-Forward Layers Are Key-Value Memories . In EMNLP, 2021
work page 2021
-
[9]
Think before You Speak: Training Language Models with Pause Tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before You Speak: Training Language Models with Pause Tokens . In ICLR, 2024
work page 2024
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava S...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training Large Language Models to Reason in a Continuous Latent Space . In ICLR, 2025
work page 2025
-
[12]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-Efficient Transfer Learning for NLP . In ICML, 2019
work page 2019
-
[13]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models . In ICLR, 2022
work page 2022
-
[14]
Neel Jain, Ping-yeh Chiang, Yuxin Wen, John Kirchenbauer, Hong-Min Chu, Gowthami Somepalli, Brian R. Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. NEFTune: Noisy Embeddings Improve Instruction Finetuning . In ICLR, 2024
work page 2024
-
[15]
Model Whisper: Steering Vectors Unlock Large Language Models' Potential in Test-time
Xinyue Kang, Diwei Shi, and Li Chen. Model Whisper: Steering Vectors Unlock Large Language Models' Potential in Test-time . In AAAI, 2026
work page 2026
-
[16]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The Power of Scale for Parameter-Efficient Prompt Tuning . In EMNLP, 2021
work page 2021
-
[17]
Solving Quantitative Reasoning Problems with Language Models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving Quantitative Reasoning Problems with Language Models . In NeurIPS, 2022
work page 2022
-
[18]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation . In ACL-IJCNLP, 2021
work page 2021
-
[19]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's Verify Step by Step . In ICLR, 2024
work page 2024
-
[20]
Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. GPT Understands, Too . AI Open, 5: 0 208--215, 2024
work page 2024
-
[21]
Text and Patterns: For Effective Chain of Thought, It Takes Two to Tango
Aman Madaan and Amir Yazdanbakhsh. Text and Patterns: For Effective Chain of Thought, It Takes Two to Tango . arXiv:2209.07686, 2022
-
[22]
Aleksandar Petrov, Philip H. S. Torr, and Adel Bibi. When Do Prompting and Prefix-Tuning Work? A Theory of Capabilities and Limitations . In ICLR, 2024
work page 2024
-
[23]
Alexander Robey, Eric Wong, Hamed Hassani, and George J. Pappas. SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks . Transactions on Machine Learning Research, 2025
work page 2025
-
[24]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models . arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A Flexible and Efficient RLHF Framework . In EuroSys, 2025
work page 2025
-
[26]
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting . Journal of Machine Learning Research, 15: 0 1929--1958, 2014
work page 1929
-
[27]
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction . MIT Press, 2 edition, 2018
work page 2018
-
[28]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning . In NeurIPS, 2025
work page 2025
-
[29]
SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs
Yige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs . In ACL, 2025
work page 2025
-
[30]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement . arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization
Wengao Ye, Yan Liang, and Lianlei Shan. Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization . In ICLR, 2026
work page 2026
-
[32]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao...
work page 2025
-
[33]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild . In COLM, 2025
work page 2025
-
[34]
MemGen: Weaving Generative Latent Memory for Self-Evolving Agents
Guibin Zhang, Muxin Fu, and Shuicheng Yan. MemGen: Weaving Generative Latent Memory for Self-Evolving Agents . In ICLR, 2026
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.