Recognition: 2 theorem links
· Lean TheoremCluster-Aware Neural Collapse Prompt Tuning for Long-Tailed Generalization of Vision-Language Models
Pith reviewed 2026-05-13 05:53 UTC · model grok-4.3
The pith
Cluster-aware neural collapse prompt tuning sharpens tail-class discriminability in vision-language models while preserving generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mining semantic assignments from the pre-trained VLM to construct a cluster-invariant space, CPT computes local cluster boundaries that restrict neural-collapse constraints to neighborhoods around each class. The resulting optimization uses a textual ETF separation loss, a class-wise convergence loss, and a rotation stabilization loss to tighten intra-cluster geometry, yielding stronger inter-class separation and intra-class alignment for tail classes without altering the global semantic structure learned during pre-training.
What carries the argument
The cluster-invariant space obtained by mapping pre-trained VLM semantic assignments onto prompt-tuned features, together with the three neural-collapse losses that enforce local ETF geometry and convergence.
If this is right
- Tail classes receive stronger discriminability inside prompt-tuned VLMs.
- Generalization to classes never seen during prompt tuning remains at least as good as baseline methods.
- The three-loss neural-collapse objective produces measurable intra-cluster tightening and inter-class separation on imbalanced data.
- Local neighborhood constraints reduce unintended changes to the pre-trained model's global feature layout.
Where Pith is reading between the lines
- The cluster-mining step could be reused with other parameter-efficient adaptation techniques that operate on the same pre-trained embedding space.
- The rotation stabilization loss may stabilize training in any neural-collapse setting where class centroids can rotate freely.
- Testing CPT on long-tail distributions more extreme than the eleven datasets would reveal whether the cluster boundaries remain stable when tail classes become rarer.
Load-bearing premise
Mining semantic assignments from the pre-trained VLM yields reliable cluster-level boundaries whose local constraints leave the global semantic structure of the original model intact.
What would settle it
Replace the mined semantic assignments with random cluster labels on the same datasets; if CPT then loses its reported advantage on tail classes relative to plain prompt tuning, the central mechanism is falsified.
Figures




read the original abstract
Prompt learning has emerged as an efficient alternative to fine-tuning pre-trained vision-language models (VLMs). Despite its promise, current methods still struggle to maintain tail-class discriminability when adapting to class-imbalanced datasets. In this work, we propose cluster-aware neural collapse prompt tuning (CPT), which enhances the discriminability of tail classes in prompt-tuned VLMs without sacrificing their overall generalization. First, we design a cluster-invariant space by mining semantic assignments from the pre-trained VLM and mapping them to prompt-tuned features. This computes cluster-level boundaries and restricts the constraints to local neighborhoods, which reduces interference with the global semantic structure of the pre-trained VLM. Second, we introduce neural-collapse-driven discriminability optimization with three losses: textual Equiangular Tight Frame (ETF) separation loss, class-wise convergence loss, and rotation stabilization loss. These losses work together to shape intra-cluster geometry for better inter-class separation and intra-class alignment. Extensive experiments on 11 diverse datasets demonstrate that CPT outperforms SOTA methods, with stronger performance on long-tail classes and good generalization to unseen classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes cluster-aware neural collapse prompt tuning (CPT) for vision-language models on long-tailed data. It first mines semantic assignments from the pre-trained VLM to build a cluster-invariant space that maps to prompt-tuned features and restricts constraints to local neighborhoods. It then optimizes three neural-collapse losses (textual ETF separation, class-wise convergence, and rotation stabilization) to improve intra-cluster geometry. Experiments across 11 datasets claim superior performance over SOTA methods, especially on tail classes and generalization to unseen classes.
Significance. If the local cluster constraints provably preserve global semantics and the three losses deliver the claimed separation without data-dependent tuning, CPT would offer a targeted improvement to prompt tuning under class imbalance, with potential impact on real-world VLM deployment where tail classes matter. The explicit use of neural-collapse geometry and the cluster-mapping step are technically interesting if supported by direct diagnostics.
major comments (3)
- [§3.1] §3.1 (cluster-invariant space construction): the central non-interference claim—that mining semantic assignments and restricting constraints locally does not degrade the pre-trained VLM’s global semantic geometry—is load-bearing for the tail-class and unseen-class gains, yet no quantitative check (pre/post cosine similarity on global vs. local features, cluster purity against ground-truth labels, or tail-class-specific alignment metrics) is reported. Without this, it remains possible that noisy boundaries for weak tail representations simply add variance rather than benefit.
- [§3.2] §3.2 (three-loss formulation): the textual ETF separation loss, class-wise convergence loss, and rotation stabilization loss are presented as jointly shaping intra-cluster geometry, but the manuscript must supply the exact equations, the schedule for their relative weights, and an ablation showing that performance is insensitive to those weights rather than the result of post-hoc fitting on the evaluation splits. The reader’s circularity concern is directly applicable here.
- [Experiments] Experiments section (Tables 1–4 and long-tail/unseen splits): the reported outperformance on tail classes and unseen classes must be accompanied by per-class or head/tail accuracy breakdowns and statistical significance tests across the 11 datasets; aggregate “outperforms SOTA” statements are insufficient to confirm that the cluster-aware mechanism, rather than prompt-tuning alone, drives the tail-class lift.
minor comments (2)
- [§3.1] Notation for the cluster mapping function and the three loss terms should be introduced once with consistent symbols; currently the transition from pre-trained features to prompt-tuned features is described in prose without an explicit equation.
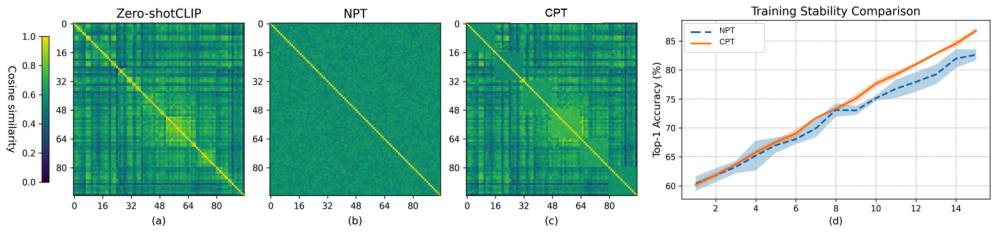
- [Figures] Figure captions for any t-SNE or cluster visualizations should state whether the plots are on training or test features and whether they are averaged over multiple runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We value the opportunity to address the concerns regarding the cluster-invariant space, the loss formulations, and the experimental validation. We will revise the manuscript accordingly to strengthen the presentation and provide the requested evidence.
read point-by-point responses
-
Referee: [§3.1] §3.1 (cluster-invariant space construction): the central non-interference claim—that mining semantic assignments and restricting constraints locally does not degrade the pre-trained VLM’s global semantic geometry—is load-bearing for the tail-class and unseen-class gains, yet no quantitative check (pre/post cosine similarity on global vs. local features, cluster purity against ground-truth labels, or tail-class-specific alignment metrics) is reported. Without this, it remains possible that noisy boundaries for weak tail representations simply add variance rather than benefit.
Authors: We agree that explicit quantitative validation is needed to support the claim that the cluster-invariant space preserves global semantics. In the revised manuscript, we will add pre/post cosine similarity metrics comparing global and local features, cluster purity scores against ground-truth labels, and tail-class-specific alignment metrics. These diagnostics will confirm that local constraints enhance discriminability without introducing harmful variance or degrading the pre-trained geometry. revision: yes
-
Referee: [§3.2] §3.2 (three-loss formulation): the textual ETF separation loss, class-wise convergence loss, and rotation stabilization loss are presented as jointly shaping intra-cluster geometry, but the manuscript must supply the exact equations, the schedule for their relative weights, and an ablation showing that performance is insensitive to those weights rather than the result of post-hoc fitting on the evaluation splits. The reader’s circularity concern is directly applicable here.
Authors: We will include the precise equations for the textual ETF separation loss, class-wise convergence loss, and rotation stabilization loss in the revised §3.2. We will also specify the fixed relative weight schedule (λ1, λ2, λ3) used throughout the experiments. To address potential circularity, we will add an ablation study varying the weights over a broad range and demonstrate that performance remains stable and superior to baselines without any tuning on evaluation or test splits. revision: yes
-
Referee: [Experiments] Experiments section (Tables 1–4 and long-tail/unseen splits): the reported outperformance on tail classes and unseen classes must be accompanied by per-class or head/tail accuracy breakdowns and statistical significance tests across the 11 datasets; aggregate “outperforms SOTA” statements are insufficient to confirm that the cluster-aware mechanism, rather than prompt-tuning alone, drives the tail-class lift.
Authors: We will expand Tables 1–4 to report per-class accuracies and explicit head/tail class breakdowns for all 11 datasets. We will also include statistical significance tests (paired t-tests over multiple random seeds) for the observed gains on tail and unseen classes. These additions will isolate the contribution of the cluster-aware neural collapse components beyond standard prompt tuning. revision: yes
Circularity Check
No significant circularity; method and claims are empirically validated without self-referential reduction.
full rationale
The paper describes a prompt-tuning method using a cluster-invariant space construction and three explicit losses (textual ETF separation, class-wise convergence, rotation stabilization) to improve tail-class discriminability. These are presented as design choices whose effects are measured on held-out evaluation sets across 11 datasets. No equation or step reduces a reported prediction or performance gain to a fitted parameter or self-citation by construction; the central claims rest on comparative experiments rather than definitional equivalence. The reader's concern about loss weights is a hyperparameter-tuning issue, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- Weights of the three losses
axioms (1)
- domain assumption Semantic assignments mined from the pre-trained VLM define stable cluster boundaries that can be transferred to prompt-tuned features without distorting global semantics.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe design a cluster-invariant space by mining semantic assignments from the pre-trained VLM and mapping them to prompt-tuned features. This computes cluster-level boundaries and restricts the constraints to local neighborhoods... textual ETF separation loss... LTETF = 1/M ∑ ||Cm + 1/(km−1)(1−I)||_F²
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearNeural Collapse... prototypes form an Equiangular Tight Frame (ETF)... global ETF flattens hierarchy... CPT applies the ETF constraint only within clusters
Reference graph
Works this paper leans on
-
[1]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InECCV, 2014. 5
work page 2014
-
[2]
Learning imbalanced datasets with label- distribution-aware margin loss
Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning imbalanced datasets with label- distribution-aware margin loss. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2019. 3
work page 2019
-
[3]
Eulrang Cho, Jooyeon Kim, and Hyunwoo J. Kim. Distribution-aware prompt tuning for vision-language models,
-
[4]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InCVPR, 2014. 5
work page 2014
-
[5]
Class-balanced loss based on effective number of samples
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9268–9277, 2019. 3
work page 2019
-
[6]
Stochas- tic context consistency reasoning for domain adaptive object detection
Yiming Cui, Liang Li, Jiehua Zhang, Chenggang Yan, Hongkui Wang, Shuai Wang, Heng Jin, and Li Wu. Stochas- tic context consistency reasoning for domain adaptive object detection. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1331–1340, 2024. 2
work page 2024
-
[7]
Debiased teacher for day-to-night domain adaptive object detection
Yiming Cui, Liang Li, Haibing Yin, Yuhan Gao, Yaoqi Sun, and Chenggang Yan. Debiased teacher for day-to-night domain adaptive object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2577–2587, 2025. 2
work page 2025
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009. 5
work page 2009
-
[9]
Lpt: Long-tailed prompt tuning for image classification
Bowen Dong, Pan Zhou, Shuicheng Yan, and Wangmeng Zuo. Lpt: Long-tailed prompt tuning for image classification. InInternational Conference on Learning Representations (ICLR), 2023. 3
work page 2023
-
[10]
Weinan E and Stephan Wojtowytsch. On the emergence of simplex symmetry in the final and penultimate layers of neural network classifiers. InMathematical and Scientific Machine Learning, pages 270–290, 2021. 3
work page 2021
-
[11]
Cong Fang, Hangfeng He, Qi Long, and Weijie J. Su. Explor- ing deep neural networks via layer-peeled model: Minority collapse in imbalanced training.Proceedings of the National Academy of Sciences, 118(43):e2103091118, 2021. 3
work page 2021
-
[12]
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning gener- ative visual models from few training examples: An incre- mental bayesian approach tested on 101 object categories. In CVPRW, 2004. 5
work page 2004
-
[13]
Clip- adapter: Better vision-language models with feature adapters
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip- adapter: Better vision-language models with feature adapters. arXiv preprint arXiv:2110.04544, 2021. 2
-
[14]
Mmrl: Multi-modal repre- sentation learning for vision-language models
Yuncheng Guo and Xiaodong Gu. Mmrl: Multi-modal repre- sentation learning for vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25015–25025, 2025. 1
work page 2025
-
[15]
Controlling neural collapse enhances out-of-distribution de- tection and transfer learning, 2025
Md Yousuf Harun, Jhair Gallardo, and Christopher Kanan. Controlling neural collapse enhances out-of-distribution de- tection and transfer learning, 2025. 2
work page 2025
-
[16]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019. 5
work page 2019
-
[17]
Shihao Hou, Xinyi Shang, Shreyank N Gowda, Yang Lu, Chao Wu, Yan Yan, and Hanzi Wang. Capt: Class-aware prompt tuning for federated long-tailed learning with vision- language model.arXiv preprint arXiv:2503.06993, 2025. 3
-
[18]
Limitations of neural collapse for understanding generalization in deep learning, 2022
Like Hui, Mikhail Belkin, and Preetum Nakkiran. Limitations of neural collapse for understanding generalization in deep learning, 2022. 2
work page 2022
- [19]
-
[20]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InICML, pages 4904–
-
[21]
Decoupling representation and classifier for long-tailed recognition
Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition. InIn- ternational Conference on Learning Representations (ICLR),
-
[22]
Self-regulating prompts: Foundational model adap- tation without forgetting
Muhammad Uzair Khattak, Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Self-regulating prompts: Foundational model adap- tation without forgetting. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15190–15200, 2023. 1
work page 2023
-
[23]
Neural collapse: A review on modelling principles and generalization, 2023
Vignesh Kothapalli. Neural collapse: A review on modelling principles and generalization, 2023. 1
work page 2023
-
[24]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In ICCVW, 2013. 5
work page 2013
-
[25]
Dpc: Dual-prompt collaboration for tun- ing vision-language models
Haoyang Li, Liang Wang, Chao Wang, Jing Jiang, Yan Peng, and Guodong Long. Dpc: Dual-prompt collaboration for tun- ing vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25623– 25632, 2025. 5
work page 2025
-
[26]
Liang Li, Gaoxiang Cong, Yuankai Qi, Zheng-Jun Zha, Qi Wu, Michael Sheng, Qingming Huang, and Ming-Hsuan Yang. Dubbing movies via hierarchical phoneme modeling and acoustic diffusion denoising.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 47(11):10361–10377,
-
[27]
Divergence-enhanced knowledge-guided context optimiza- tion for visual-language prompt tuning
Yilun Li, Miaomiao Cheng, Xu Han, and Wei Song. Divergence-enhanced knowledge-guided context optimiza- tion for visual-language prompt tuning. InProceedings of the International Conference on Learning Representations (ICLR), 2025. 1, 5
work page 2025
-
[28]
Understanding and mitigating overfitting in prompt tuning for vision-language models, 2023
Chengcheng Ma, Yang Liu, Jiankang Deng, Lingxi Xie, Weiming Dong, and Changsheng Xu. Understanding and mitigating overfitting in prompt tuning for vision-language models, 2023. 2
work page 2023
-
[29]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual clas- sification of aircraft.arXiv preprint arXiv:1306.5151, 2013. 5
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
Long-tail learning via logit adjustment
Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. InInternational Con- ference on Learning Representations (ICLR), 2021. 3
work page 2021
-
[31]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, 2008. 5
work page 2008
-
[32]
Vardan Papyan, X. Y . Han, and David L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020. 1, 3
work page 2020
-
[33]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. InCVPR, 2012. 5
work page 2012
-
[34]
Yuxin Peng, Zishuo Wang, Geng Li, Xiangtian Zheng, Sibo Yin, and Hulingxiao He. A survey on fine-grained multimodal large language models.Chinese Journal of Electronics, 35 (2):1–33, 2026. 2
work page 2026
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021. 1, 2
work page 2021
-
[36]
Bridg- ing the gap between object and image-level representations for open-vocabulary detection
Hanoona Rasheed, Muhammad Maaz, Muhammad Uzair Khattak, Salman Khan, and Fahad Shahbaz Khan. Bridg- ing the gap between object and image-level representations for open-vocabulary detection. InNeurIPS, 2022. 2
work page 2022
-
[37]
Balanced meta-softmax for long- tailed visual recognition
Jiawei Ren, Cunjun Yu, Shunan Sheng, Xiao Ma, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Balanced meta-softmax for long- tailed visual recognition. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. 3
work page 2020
-
[38]
Consistency-guided prompt learning for vision-language models
Shuvendu Roy and Ali Etemad. Consistency-guided prompt learning for vision-language models. 2024. 2
work page 2024
-
[39]
Exploring embedding priors in prompt- tuning for improved interpretability and control, 2024
Sergey Sedov, Sumanth Bharadwaj Hachalli Karanam, and Venu Gopal Kadamba. Exploring embedding priors in prompt- tuning for improved interpretability and control, 2024. 1, 3
work page 2024
-
[40]
Ef- ficient and long-tailed generalization for pre-trained vision- language model, 2024
Jiang-Xin Shi, Chi Zhang, Tong Wei, and Yu-Feng Li. Ef- ficient and long-tailed generalization for pre-trained vision- language model, 2024. 1
work page 2024
-
[41]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 5
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[42]
Eva-clip: Improved training techniques for clip at scale,
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale,
-
[43]
Jingyi Tang, Li Liang, Beichen Zhang, and Qingming Huang. Lmda: Llm-guided marginal distribution alignment for open- set active learning.Chinese Journal of Electronics, 2026. 2
work page 2026
-
[44]
Extended unconstrained features model for exploring deep neural collapse
Tom Tirer and Joan Bruna. Extended unconstrained features model for exploring deep neural collapse. InProceedings of Machine Learning Research, pages 21478–21505, 2022. 3
work page 2022
-
[45]
Yunbin Tu, Liang Li, Li Su, Zheng-Jun Zha, and Qingming Huang. Smart: Syntax-calibrated multi-aspect relation trans- former for change captioning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(7):4926–4943, 2024. 2
work page 2024
-
[46]
Sun database: Large-scale scene recog- nition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recog- nition from abbey to zoo. InCVPR, 2010. 5
work page 2010
-
[47]
Hantao Yao and et al. Bi-modality individual-aware prompt tuning for visual-language model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 1
work page 2025
-
[48]
Visual- language prompt tuning with knowledge-guided context op- timization
Hantao Yao, Rui Zhang, and Changsheng Xu. Visual- language prompt tuning with knowledge-guided context op- timization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6757–6767, 2023
work page 2023
-
[49]
Tcp: Textual- based class-aware prompt tuning for visual-language model
Hantao Yao, Rui Zhang, and Changsheng Xu. Tcp: Textual- based class-aware prompt tuning for visual-language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1
work page 2024
-
[50]
Filip: Fine-grained interactive language-image pre-training
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training.arXiv preprint arXiv:2111.07783, 2021. 2
-
[51]
Zhaoda Ye, Xiangteng He, and Yuxin Peng. Unsupervised cross-media hashing learning via knowledge graph.Chinese Journal of Electronics, 31(6):1081–1091, 2022. 2
work page 2022
-
[52]
Florence: A new foundation model for computer vision
Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. Florence: A new foundation model for computer vision.arXiv preprint arXiv:2111.11432,
-
[53]
Lit: Zero-shot transfer with locked-image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. InCVPR, pages 18123–18133, 2022. 2
work page 2022
-
[54]
Beichen Zhang, Liang Li, Shuhui Wang, Shaofei Cai, Zheng- Jun Zha, Qi Tian, and Qingming Huang. Inductive state- relabeling adversarial active learning with heuristic clique rescaling.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 46(12):9780–9796, 2024. 2
work page 2024
-
[55]
Tip- adapter: Training-free clip-adapter for better vision-language modeling
Renrui Zhang, Rongyao Fang, Peng Gao, Wei Zhang, Kun- chang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. Tip- adapter: Training-free clip-adapter for better vision-language modeling. InECCV, 2022. 2
work page 2022
-
[56]
Conditional prompt learning for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. InCVPR, pages 16816–16825, 2022. 2
work page 2022
-
[57]
Debiased fine-tuning for vision-language models by prompt regularization
Beier Zhu, Yulei Niu, Saeil Lee, Minhoe Hur, and Hanwang Zhang. Debiased fine-tuning for vision-language models by prompt regularization. InProceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelli- gence and Thirteenth Symposium on Educational Advances in Arti...
work page 2023
-
[58]
Beier Zhu, Kaihua Tang, Qianru Sun, and Hanwang Zhang. Generalized logit adjustment: Calibrating fine-tuned models by removing label bias in foundation models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 3
work page 2023
-
[59]
Neural collapse anchored prompt tuning for generalizable vision-language models
Didi Zhu, Zexi Li, Min Zhang, Junkun Yuan, Jiashuo Liu, Kun Kuang, and Chao Wu. Neural collapse anchored prompt tuning for generalizable vision-language models. InProceed- ings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, page 4631–4640, New York, NY , USA, 2024. Association for Computing Machinery. 1, 3, 5
work page 2024
-
[60]
A geometric analysis of neural collapse with unconstrained features
Zhihui Zhu, Tianyu Ding, Jinxin Zhou, Xiao Li, Chong You, Jeremias Sulam, and Qing Qu. A geometric analysis of neural collapse with unconstrained features. 34:29820–29834, 2021. 3 Cluster-Aware Neural Collapse Prompt Tuning for Long-Tailed Generalization of Vision-Language Models Supplementary Material
work page 2021
-
[61]
Experiments Setting 6.1. Training Details. We evaluate our CPT under base-to-new generalization, do- main generalization, and cross-dataset transfer generaliza- tion over 11 image classification benchmark datasets. We conduct the experiments based on the vision backbone with Vit-B/16. We set the number of visual and textual prompts to 4, initializing them...
-
[62]
Ablation on the Number of Samples per Cluster
Ablative Analysis 7.1. Ablation on the Number of Samples per Cluster . To investigate the sensitivity of our method to the number of samples per cluster, we conduct an ablation study by varying this value across a range of settings. This analysis explores how the granularity of semantic grouping—measured by how many class prototypes are grouped into each ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.