Recognition: 2 theorem links
· Lean TheoremAssessing and Mitigating Miscalibration in LLM-Based Social Science Measurement
Pith reviewed 2026-05-13 05:20 UTC · model grok-4.3
The pith
LLM confidence scores for social science text measurements are poorly aligned with actual correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
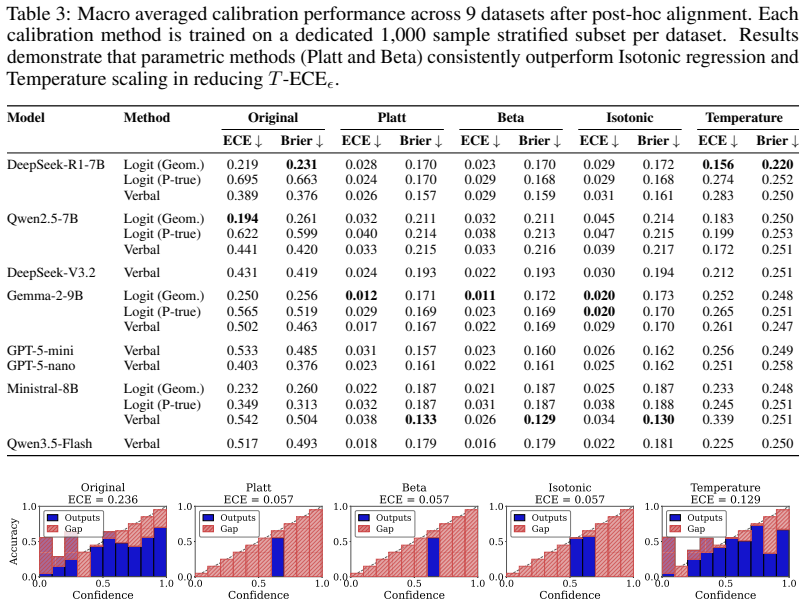
Across tasks and model families, reported confidence is poorly aligned with tolerance-based correctness. A case study demonstrates that confidence-based filtering alters downstream regression estimates when miscalibration is present. The proposed soft label distillation pipeline converts LLM scores and verbalized confidences into soft targets for training smaller encoder models, achieving average reductions of 43.2% in expected calibration error and 34.0% in Brier score.
What carries the argument
Soft label distillation pipeline that turns an LLM's numerical score and verbalized confidence into a soft target distribution for training a discriminative classifier.
If this is right
- Confidence-based filtering of LLM outputs can change the results of empirical social science analyses if calibration is poor.
- Measurement validity for LLM-derived variables requires explicit calibration assessment.
- Smaller models trained via distillation can inherit better calibration properties from larger LLMs.
- The misalignment appears consistently across both proprietary and open-source model families.
Where Pith is reading between the lines
- Social scientists adopting LLMs for large-scale text coding should build calibration checks into their workflows to avoid biased estimates.
- The distillation technique could be adapted to create specialized, efficient models for other text annotation tasks in research.
- Improved calibration might enable more trustworthy use of LLM measurements in policy or economic modeling applications.
Load-bearing premise
The tolerance-based definition of correctness serves as a stable and meaningful ground truth that applies uniformly across the fourteen social science constructs.
What would settle it
Observing no meaningful reduction in calibration error when applying the distillation method to a fresh collection of social science measurement tasks would indicate the approach does not generalize.
Figures




read the original abstract
Large language models (LLMs) are increasingly used in social science as scalable measurement tools for converting unstructured text into variables that can enter standard empirical designs. Measurement validity demands more than high average accuracy, which requires well calibrated confidence that faithfully reflects the empirical probability of each measurement being correct. This paper studies the model miscalibration in LLM-based social science measurement. We begin with a case study on FOMC and show that confidence based filtering can change downstream regression estimates when LLM confidence is miscalibrated. We then audit calibration across 14 social science constructs covering both proprietary models, including GPT-5-mini, DeepSeek-V3.2, and open source models. Across tasks and model families, reported confidence is poorly aligned with tolerance-based correctness. As a simple mitigation, we propose a soft label distillation pipeline for calibrating Bert with LLM. The method converts an LLM score and its verbalized confidence into a soft target distribution, then trains a smaller discriminative classifier on encoder models for these targets. Averaged across datasets, this approach reduces ECE by 43.2\% and Brier by 34.0\%. These results suggest that LLM-based social science pipelines should treat calibration as part of measurement validity, rather than as an optional post-processing concern.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs used as measurement tools in social science exhibit miscalibration between reported confidence and tolerance-based correctness, demonstrates this via a FOMC case study (where filtering alters regression estimates) and an audit across 14 constructs with multiple model families, and proposes a soft-label distillation pipeline that trains a BERT classifier on LLM-derived soft targets, yielding average ECE reductions of 43.2% and Brier reductions of 34.0%.
Significance. If the tolerance-based ground truth is stable and the gains generalize, the work usefully flags calibration as a core validity requirement for LLM-derived variables in empirical designs and supplies a practical, smaller-model calibration method. The cross-model audit and reported quantitative improvements are concrete strengths that could inform measurement pipelines.
major comments (1)
- [Methods / Audit procedure (tolerance-based correctness definition)] The operationalization of tolerance-based correctness (used as ground truth for both the misalignment audit and the soft-label targets) is not specified in sufficient detail: it is unclear what tolerance thresholds are applied (absolute vs. relative, fixed vs. construct-specific), how they were selected for each of the 14 constructs, or whether they were validated against human annotations. This definition is load-bearing for the central claims, as the reported poor alignment and the 43.2%/34.0% ECE/Brier reductions are computed directly against it; without explicit justification or sensitivity checks, both the audit findings and the mitigation gains could be artifacts of the tolerance choice rather than intrinsic miscalibration.
minor comments (2)
- [Results / Abstract] The abstract and results report averaged ECE/Brier reductions without error bars, standard errors, or per-construct breakdowns, which makes it difficult to judge consistency across the 14 datasets and model families.
- [Audit section] The criteria used to select the 14 social science constructs are not stated, limiting assessment of how representative the audit is of broader LLM measurement use cases.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The concern about the operationalization of tolerance-based correctness is important, as this definition is central to the audit results and the reported calibration improvements. We address the comment below and will revise the manuscript to provide the requested details and robustness checks.
read point-by-point responses
-
Referee: [Methods / Audit procedure (tolerance-based correctness definition)] The operationalization of tolerance-based correctness (used as ground truth for both the misalignment audit and the soft-label targets) is not specified in sufficient detail: it is unclear what tolerance thresholds are applied (absolute vs. relative, fixed vs. construct-specific), how they were selected for each of the 14 constructs, or whether they were validated against human annotations. This definition is load-bearing for the central claims, as the reported poor alignment and the 43.2%/34.0% ECE/Brier reductions are computed directly against it; without explicit justification or sensitivity checks, both the audit findings and the mitigation gains could be artifacts of the tolerance choice rather than intrinsic miscalibration.
Authors: We agree that the manuscript would benefit from greater explicitness on this point. In the revised version we will add a dedicated subsection in the Methods section that, for each of the 14 constructs: (i) states whether the tolerance is absolute or relative, (ii) reports the precise numerical threshold(s) used, (iii) explains the selection rationale (domain literature, expert input, or inter-annotator agreement statistics), and (iv) indicates whether and how the thresholds were cross-checked against human annotations. We will also include a sensitivity table showing how the reported ECE and Brier reductions change under alternative tolerance values (e.g., ±5 %, ±10 %, ±15 %). These additions will make clear that the miscalibration findings and mitigation gains are not artifacts of a single arbitrary choice. revision: yes
Circularity Check
No circularity: empirical audit and mitigation pipeline are self-contained
full rationale
The paper's core contribution consists of an empirical case study on FOMC data, an audit of calibration across 14 social science constructs using tolerance-based correctness as ground truth, and an experimental soft-label distillation procedure that trains a BERT classifier on LLM-generated soft targets. These steps involve data collection, metric computation (ECE, Brier), and model training with reported average improvements; none reduce by construction to fitted parameters renamed as predictions, self-definitions, or load-bearing self-citations. The methodology is externally falsifiable via replication on the same datasets and does not invoke uniqueness theorems or ansatzes from prior author work. The derivation chain is therefore independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM verbalized confidence can be treated as a probability distribution suitable for soft-label supervision
- domain assumption Tolerance-based correctness provides a stable external ground truth for calibration evaluation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe adapt the standard Expected Calibration Error (ECE) to accommodate continuous measurements with error boundaries... T-ECEϵ = ... accϵ(Bm) = proportion of predictions within tolerance ϵ
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearsoft label distillation pipeline... converts an LLM score and its verbalized confidence into a soft target distribution, then trains a smaller discriminative classifier
Reference graph
Works this paper leans on
-
[1]
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference. Science, 382 0 (6671): 0 669--674, 2023
work page 2023
-
[2]
Towards automatic generation of messages countering online hate speech and microaggressions
Mana Ashida and Mamoru Komachi. Towards automatic generation of messages countering online hate speech and microaggressions. In Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH), pages 11--23, 2022
work page 2022
-
[3]
Hemanth Asirvatham, Elliott Mokski, and Andrei Vasiliev Dmitry Shleifer. Gpt as a measurement tool. SSRN Electronic Journal, 2026. URL https://api.semanticscholar.org/CorpusID:285809516
work page 2026
-
[4]
Christopher A Bail. Can generative ai improve social science? Proceedings of the National Academy of Sciences of the United States of America, 121, 2024. URL https://api.semanticscholar.org/CorpusID:269646697
work page 2024
-
[5]
The isotonic regression problem and its dual
Richard E Barlow and Hugh D Brunk. The isotonic regression problem and its dual. Journal of the American Statistical Association, 67 0 (337): 0 140--147, 1972
work page 1972
-
[6]
Sven Buechel and Udo Hahn. Emobank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 578--585, 2017
work page 2017
-
[7]
A computational approach to politeness with application to social factors
Cristian Danescu-Niculescu-Mizil, Moritz Sudhof, Dan Jurafsky, Jure Leskovec, and Christopher Potts. A computational approach to politeness with application to social factors. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 250--259, 2013
work page 2013
-
[8]
Rodrigo de Oliveira, Matthew Garber, James M Gwinnutt, Emaan Rashidi, Jwu-Hsuan Hwang, William Gilmour, Jay Nanavati, Khaldoun Zine El Abidine, and Christina DeFilippo Mack. A study of calibration as a measurement of trustworthiness of large language models in biomedical natural language processing. JAMIA open, 8 0 (4): 0 ooaf058, 2025
work page 2025
-
[10]
Local temperature scaling for probability calibration
Zhipeng Ding, Xu Han, Peirong Liu, and Marc Niethammer. Local temperature scaling for probability calibration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6889--6899, 2021
work page 2021
-
[12]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML'17, page 1321–1330. JMLR.org, 2017
work page 2017
-
[13]
Can chatgpt decipher fedspeak? SSRN Electronic Journal, 2023
Anne Lundgaard Hansen and Sophia Kazinnik. Can chatgpt decipher fedspeak? SSRN Electronic Journal, 2023. URL https://api.semanticscholar.org/CorpusID:258039570
work page 2023
-
[16]
From entropy to calibrated uncertainty: Training language models to reason about uncertainty
Azza Jenane, Nassim Walha, Lukas Kuhn, and Florian Buettner. From entropy to calibrated uncertainty: Training language models to reason about uncertainty. 2026. URL https://api.semanticscholar.org/CorpusID:286367709
work page 2026
-
[17]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Thomas Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zachary Dodds, Nova Dassarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, John Kernion, Shauna Kravec, Lian...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Large language models must be taught to know what they don't know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew Gordon Wilson. Large language models must be taught to know what they don't know. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[20]
Meelis Kull, Telmo Silva Filho, and Peter Flach. Beta calibration: a well-founded and easily implemented improvement on logistic calibration for binary classifiers. In Artificial intelligence and statistics, pages 623--631. PMLR, 2017
work page 2017
-
[21]
Verified uncertainty calibration
Ananya Kumar, Percy S Liang, and Tengyu Ma. Verified uncertainty calibration. Advances in neural information processing systems, 32, 2019
work page 2019
-
[22]
Uncovering the semantics of concepts using gpt-4
Ga \"e l Le Mens, Bal \'a zs Kov \'a cs, Michael T Hannan, and Guillem Pros. Uncovering the semantics of concepts using gpt-4. Proceedings of the National Academy of Sciences, 120 0 (49): 0 e2309350120, 2023
work page 2023
-
[23]
Think through uncertainty: Improving long-form generation factuality via reasoning calibration
Xin Liu and Lu Wang. Think through uncertainty: Improving long-form generation factuality via reasoning calibration. 2026. URL https://api.semanticscholar.org/CorpusID:287436193
work page 2026
-
[25]
Enhancing language model factuality via activation-based confidence calibration and guided decoding
Xin Liu, Farima Fatahi Bayat, and Lu Wang. Enhancing language model factuality via activation-based confidence calibration and guided decoding. In Conference on Empirical Methods in Natural Language Processing, 2024. URL https://api.semanticscholar.org/CorpusID:270620078
work page 2024
-
[26]
Mastakouri, Elke Kirschbaum, Shiva Prasad Kasiviswanathan, and Aaditya Ramdas
Putra Manggala, Atalanti A. Mastakouri, Elke Kirschbaum, Shiva Prasad Kasiviswanathan, and Aaditya Ramdas. Qa-calibration of language model confidence scores. In International Conference on Learning Representations, 2024. URL https://api.semanticscholar.org/CorpusID:273228151
work page 2024
-
[27]
Uncertainty-aware self-training for few-shot text classification
Subhabrata Mukherjee and Ahmed Hassan Awadallah. Uncertainty-aware self-training for few-shot text classification. In Neural Information Processing Systems, 2020. URL https://api.semanticscholar.org/CorpusID:227276483
work page 2020
-
[28]
u ller, Nicholas Popovic, Michael F \
Philip M \"u ller, Nicholas Popovic, Michael F \"a rber, and P \'e ter Steinbach. Benchmarking uncertainty calibration in large language model long-form question answering. ArXiv, abs/2602.00279, 2026. URL https://api.semanticscholar.org/CorpusID:285270867
-
[29]
Bias and efficiency loss due to misclassified responses in binary regression
John M Neuhaus. Bias and efficiency loss due to misclassified responses in binary regression. Biometrika, 86 0 (4): 0 843--855, 1999
work page 1999
-
[30]
An empirical analysis of formality in online communication
Ellie Pavlick and Joel Tetreault. An empirical analysis of formality in online communication. Transactions of the Association for Computational Linguistics, 2016
work page 2016
-
[31]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods
John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in large margin classifiers, 10 0 (3): 0 61--74, 1999
work page 1999
-
[32]
Gpt is an effective tool for multilingual psychological text analysis
Steve Rathje, Dan-Mircea Mirea, Ilia Sucholutsky, Raja Marjieh, Claire E Robertson, and Jay J Van Bavel. Gpt is an effective tool for multilingual psychological text analysis. Proceedings of the National Academy of Sciences, 121 0 (34): 0 e2308950121, 2024
work page 2024
-
[33]
Alexander J. Ratner, Stephen H. Bach, Henry R. Ehrenberg, Jason Alan Fries, Sen Wu, and Christopher R \'e . Snorkel: Rapid training data creation with weak supervision. Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases, 11 3: 0 269--282, 2017. URL https://api.semanticscholar.org/CorpusID:6730236
work page 2017
-
[34]
Trillion dollar words: A new financial dataset, task & market analysis
Agam Shah, Suvan Paturi, and Sudheer Chava. Trillion dollar words: A new financial dataset, task & market analysis. In Annual Meeting of the Association for Computational Linguistics, 2023. URL https://api.semanticscholar.org/CorpusID:258685646
work page 2023
-
[35]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages...
work page 2023
-
[36]
Evaluating and calibrating llm confidence on questions with multiple correct answers
Yuhang Wang, Shiyu Ni, Zhikai Ding, Zihang Zhan, Yuanzi Li, and Keping Bi. Evaluating and calibrating llm confidence on questions with multiple correct answers. ArXiv, abs/2602.07842, 2026. URL https://api.semanticscholar.org/CorpusID:285452681
-
[37]
Influences on llm calibration: A study of response agreement, loss functions, and prompt styles
Yuxi Xia, Pedro Henrique Luz de Araujo, Klim Zaporojets, and Benjamin Roth. Influences on llm calibration: A study of response agreement, loss functions, and prompt styles. In Annual Meeting of the Association for Computational Linguistics, 2025. URL https://api.semanticscholar.org/CorpusID:275342783
work page 2025
-
[39]
Calibrating the confidence of large language models by eliciting fidelity
Mozhi Zhang, Mianqiu Huang, Rundong Shi, Linsen Guo, Chong Peng, Peng Yan, Yaqian Zhou, and Xipeng Qiu. Calibrating the confidence of large language models by eliciting fidelity. In Conference on Empirical Methods in Natural Language Processing, 2024. URL https://api.semanticscholar.org/CorpusID:268876453
work page 2024
-
[40]
Rethinking soft labels for knowledge distillation: A bias-variance tradeoff perspective
Helong Zhou, Liangchen Song, Jiajie Chen, Ye Zhou, Guoli Wang, Junsong Yuan, and Qian Zhang. Rethinking soft labels for knowledge distillation: A bias-variance tradeoff perspective. ArXiv, abs/2102.00650, 2021. URL https://api.semanticscholar.org/CorpusID:231740588
-
[41]
SSRN Electronic Journal , year=
GPT as a Measurement Tool , author=. SSRN Electronic Journal , year=
-
[42]
Proceedings of the National Academy of Sciences of the United States of America , year=
Can Generative AI improve social science? , author=. Proceedings of the National Academy of Sciences of the United States of America , year=
-
[43]
SSRN Electronic Journal , year=
Can ChatGPT Decipher Fedspeak? , author=. SSRN Electronic Journal , year=
-
[44]
Annual Meeting of the Association for Computational Linguistics , year=
Influences on LLM Calibration: A Study of Response Agreement, Loss Functions, and Prompt Styles , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[45]
Advances in Neural Information Processing Systems , year =
Large Language Models Must Be Taught to Know What They Don't Know , author =. Advances in Neural Information Processing Systems , year =
- [46]
- [47]
-
[48]
Calibration of Pre-trained Transformers
Desai, Shrey and Durrett, Greg. Calibration of Pre-trained Transformers. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.21
-
[49]
Conference on Empirical Methods in Natural Language Processing , year=
Calibrating the Confidence of Large Language Models by Eliciting Fidelity , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[50]
Uncertainty in Language Models: Assessment through Rank-Calibration
Huang, Xinmeng and Li, Shuo and Yu, Mengxin and Sesia, Matteo and Hassani, Hamed and Lee, Insup and Bastani, Osbert and Dobriban, Edgar. Uncertainty in Language Models: Assessment through Rank-Calibration. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.18
-
[51]
Conference on Empirical Methods in Natural Language Processing , year=
Enhancing Language Model Factuality via Activation-Based Confidence Calibration and Guided Decoding , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[52]
International Conference on Learning Representations , year=
QA-Calibration of Language Model Confidence Scores , author=. International Conference on Learning Representations , year=
-
[53]
From Entropy to Calibrated Uncertainty: Training Language Models to Reason About Uncertainty , author=. 2026 , url=
work page 2026
-
[54]
Think Through Uncertainty: Improving Long-Form Generation Factuality via Reasoning Calibration , author=. 2026 , url=
work page 2026
-
[55]
Benchmarking Uncertainty Calibration in Large Language Model Long-Form Question Answering , author=. ArXiv , year=
-
[56]
Evaluating and Calibrating LLM Confidence on Questions with Multiple Correct Answers , author=. ArXiv , year=
-
[57]
Annual Meeting of the Association for Computational Linguistics , year=
Trillion Dollar Words: A New Financial Dataset, Task & Market Analysis , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[58]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. arXiv preprint arXiv:2306.13063 , year=
work page internal anchor Pith review arXiv
-
[59]
Bias and efficiency loss due to misclassified responses in binary regression , author=. Biometrika , volume=. 1999 , publisher=
work page 1999
-
[60]
A study of calibration as a measurement of trustworthiness of large language models in biomedical natural language processing , author=. JAMIA open , volume=. 2025 , publisher=
work page 2025
-
[61]
Rethinking Soft Labels for Knowledge Distillation: A Bias-Variance Tradeoff Perspective , author=. ArXiv , year=
-
[62]
Proceedings of the VLDB Endowment
Snorkel: Rapid Training Data Creation with Weak Supervision , author=. Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases , year=
-
[63]
Neural Information Processing Systems , year=
Uncertainty-aware Self-training for Few-shot Text Classification , author=. Neural Information Processing Systems , year=
-
[64]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[65]
arXiv preprint arXiv:2310.19208 , year=
Litcab: Lightweight language model calibration over short-and long-form responses , author=. arXiv preprint arXiv:2310.19208 , year=
-
[66]
Proceedings of the National Academy of Sciences , volume=
GPT is an effective tool for multilingual psychological text analysis , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
work page 2024
-
[67]
Advances in Neural Information Processing Systems , volume=
Calibrating reasoning in language models with internal consistency , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Transactions of the Association for Computational Linguistics , year =
Ellie Pavlick and Joel Tetreault , title =. Transactions of the Association for Computational Linguistics , year =
-
[69]
A computational approach to politeness with application to social factors , author=. Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[70]
arXiv preprint arXiv:2009.10277 , year=
Constructing interval variables via faceted Rasch measurement and multitask deep learning: a hate speech application , author=. arXiv preprint arXiv:2009.10277 , year=
-
[71]
President Vows to Cut< Taxes> Hair
" President Vows to Cut< Taxes> Hair": Dataset and Analysis of Creative Text Editing for Humorous Headlines , author=. arXiv preprint arXiv:1906.00274 , year=
-
[72]
Emobank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis , author=. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , pages=
-
[73]
Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH) , pages=
Towards automatic generation of messages countering online hate speech and microaggressions , author=. Proceedings of the Sixth Workshop on Online Abuse and Harms (WOAH) , pages=
-
[74]
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis , journal =
Shai Gretz and Roni Friedman and Edo Cohen. A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis , journal =. 2019 , url =. 1911.11408 , timestamp =
-
[75]
Proceedings of the National Academy of Sciences , volume=
Uncovering the semantics of concepts using GPT-4 , author=. Proceedings of the National Academy of Sciences , volume=. 2023 , publisher=
work page 2023
-
[76]
Advances in large margin classifiers , volume=
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods , author=. Advances in large margin classifiers , volume=. 1999 , publisher=
work page 1999
-
[77]
Artificial intelligence and statistics , pages=
Beta calibration: a well-founded and easily implemented improvement on logistic calibration for binary classifiers , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
work page 2017
-
[78]
Journal of the American Statistical Association , volume=
The isotonic regression problem and its dual , author=. Journal of the American Statistical Association , volume=. 1972 , publisher=
work page 1972
-
[79]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Local temperature scaling for probability calibration , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[80]
Advances in neural information processing systems , volume=
Verified uncertainty calibration , author=. Advances in neural information processing systems , volume=
-
[81]
Prediction-powered inference , author=. Science , volume=. 2023 , publisher=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.