Recognition: 2 theorem links
· Lean TheoremOn Predicting the Post-training Potential of Pre-trained LLMs
Pith reviewed 2026-05-13 05:11 UTC · model grok-4.3
The pith
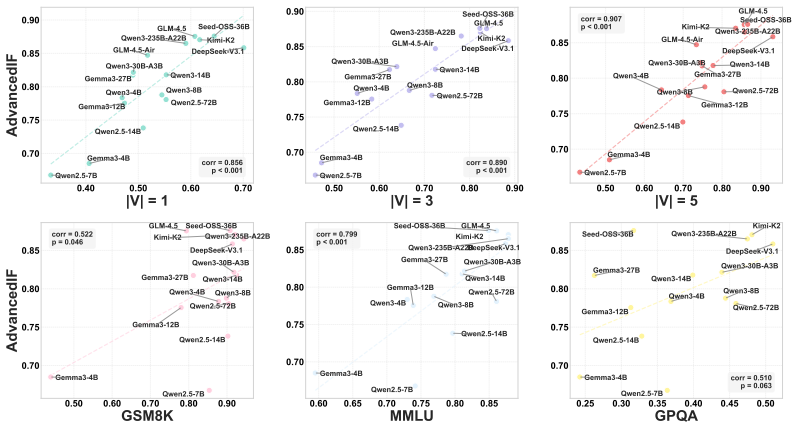
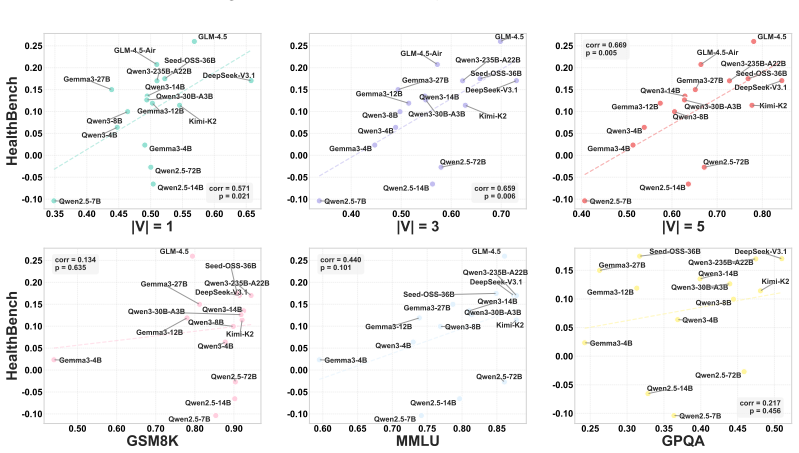
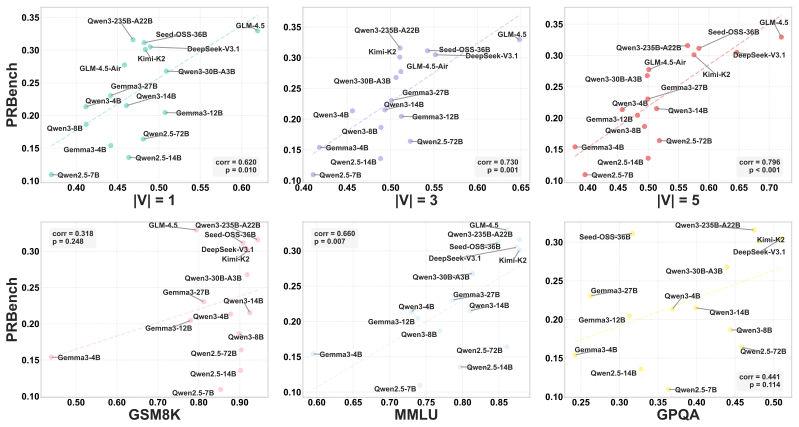
RuDE predicts how well a pre-trained LLM will perform after post-training by discriminating its responses on controlled rubric violations, with over 90 percent correlation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
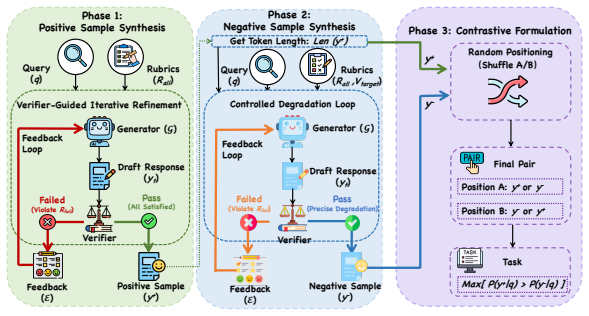
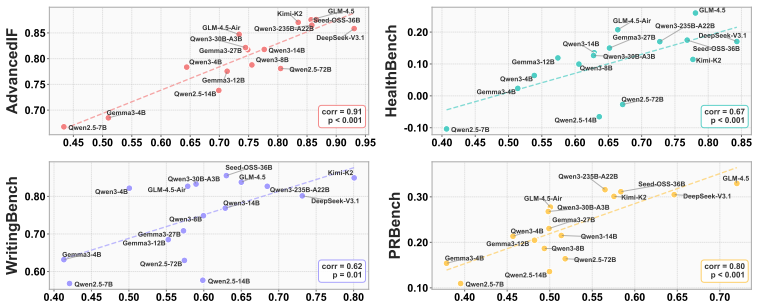
We propose RuDE (Rubric-based Discriminative Evaluation), a unified framework that constructs controlled contrastive pairs across diverse domains by fine-grained rubric violations guided by the 4C Taxonomy. By scoring how well the base model discriminates the correct response from the violated one, RuDE bypasses the generation gap and achieves greater than 90 percent correlation with post-training performance. Reinforcement learning validation shows that RuDE successfully identifies high-potential smaller models that outperform larger counterparts after training.
What carries the argument
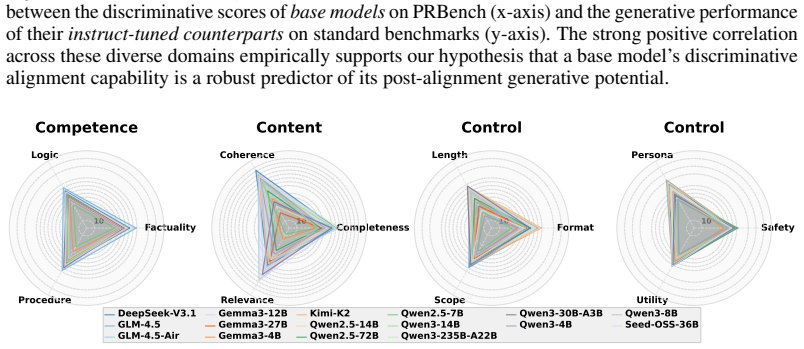
RuDE framework, which scores base-model plasticity through discrimination on contrastive pairs built from 4C Taxonomy rubric violations
If this is right
- Base models can be ranked and selected before any post-training on the basis of RuDE scores alone.
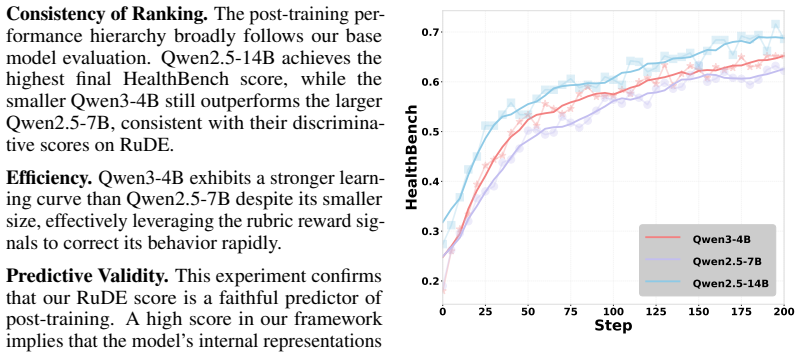
- Smaller models flagged as high-potential by RuDE can produce stronger results than larger models once RL is applied.
- The method supplies a compute-efficient route for choosing foundation models without exhaustive post-training trials.
- The greater-than-90-percent correlation holds across extensive experiments spanning multiple domains.
Where Pith is reading between the lines
- Model builders could insert RuDE scoring as an early filter to avoid wasting post-training compute on low-plasticity bases.
- If the 4C Taxonomy and contrastive construction generalize, the same approach might forecast performance under supervised fine-tuning or other regimes beyond RL.
- Widespread adoption would let the field standardize base-model selection around a single pre-training diagnostic rather than post-hoc benchmarks.
Load-bearing premise
That constructing controlled contrastive pairs from fine-grained rubric violations under the 4C Taxonomy produces a reliable, unbiased proxy for a base model's post-training plasticity that generalizes beyond the specific rubrics and domains tested.
What would settle it
Apply RuDE to a fresh collection of models and domains, run the indicated post-training or RL on the top-scoring smaller models, and check whether the correlation with final performance drops below 80 percent or the selected models fail to outperform larger baselines.
Figures










read the original abstract
The performance of Large Language Models (LLMs) on downstream tasks is fundamentally constrained by the capabilities acquired during pre-training. However, traditional benchmarks like MMLU often fail to reflect a base model's plasticity in complex open-ended scenarios, leading to inefficient model selection. We address this by introducing a new task of predicting post-training potential - forecasting a base model's performance before post-training. We propose RuDE (Rubric-based Discriminative Evaluation), a unified framework that bypasses the generation gap of base models by leveraging response discrimination. Guided by our systematic 4C Taxonomy, RuDE constructs controlled contrastive pairs across diverse domains by fine-grained rubric violations. Extensive experiments demonstrate a correlation greater than 90% with post-training performance. Crucially, validation via Reinforcement Learning (RL) confirms that RuDE effectively identifies high-potential smaller models that outperform larger counterparts, offering a compute-efficient mechanism for foundation model development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RuDE (Rubric-based Discriminative Evaluation), a framework guided by a 4C Taxonomy that constructs controlled contrastive pairs from fine-grained rubric violations to predict the post-training potential of pre-trained LLMs. It claims extensive experiments demonstrate a correlation greater than 90% with post-training performance and that RL validation confirms RuDE can identify high-potential smaller models that outperform larger counterparts after post-training.
Significance. If the reported correlation and generalization hold, the work would provide a valuable compute-efficient proxy for base-model plasticity that addresses limitations of benchmarks like MMLU, enabling better model selection prior to expensive post-training and potentially reducing overall compute costs in foundation model development.
major comments (3)
- [Abstract] Abstract: The claim of a correlation greater than 90% with post-training performance provides no details on the number of models or tasks tested, the statistical methods used to compute the correlation, baseline comparisons, controls for rubric construction, or potential data leakage.
- [Abstract] Abstract: The discrimination task is presented as independent of post-training outcomes, yet the fixed, hand-crafted 4C Taxonomy for generating contrastive pairs risks introducing rubric-specific artifacts or domain biases that could make the correlation an artifact rather than a general measure of plasticity.
- [RL validation section] RL validation section: The RL experiments confirm downstream utility but do not test whether the contrastive pairs isolate base-model plasticity, because the selected models and post-RL tasks remain inside the same rubric and domain distribution used to construct the pairs.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and have revised the manuscript to improve clarity and address concerns where possible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a correlation greater than 90% with post-training performance provides no details on the number of models or tasks tested, the statistical methods used to compute the correlation, baseline comparisons, controls for rubric construction, or potential data leakage.
Authors: We agree the abstract is too concise on these points. The main text (Sections 3 and 4) reports evaluation on multiple base models across diverse tasks using Pearson correlation, with explicit baseline comparisons to MMLU and other proxies, controls for rubric construction via the 4C Taxonomy, and steps to prevent data leakage by using held-out domains and models. We have revised the abstract to briefly note the scale of experiments and the correlation method while directing readers to the detailed sections. revision: yes
-
Referee: [Abstract] Abstract: The discrimination task is presented as independent of post-training outcomes, yet the fixed, hand-crafted 4C Taxonomy for generating contrastive pairs risks introducing rubric-specific artifacts or domain biases that could make the correlation an artifact rather than a general measure of plasticity.
Authors: The 4C Taxonomy was developed to be domain-agnostic by focusing on fundamental capabilities (Clarity, Coherence, Correctness, Completeness) rather than task-specific criteria. Experiments in the paper show consistent correlations across multiple domains, supporting generality. We acknowledge the risk of artifacts and have added a new paragraph in Section 3.2 discussing potential biases, including sensitivity analyses with perturbed rubrics. The pairs are constructed solely from base-model responses without any post-training data, preserving independence. revision: partial
-
Referee: [RL validation section] RL validation section: The RL experiments confirm downstream utility but do not test whether the contrastive pairs isolate base-model plasticity, because the selected models and post-RL tasks remain inside the same rubric and domain distribution used to construct the pairs.
Authors: The primary evidence that the contrastive pairs isolate base-model plasticity comes from the correlation experiments, which use a broad set of held-out models and tasks outside the RL domains. The RL validation instead demonstrates the practical utility of RuDE for model selection prior to expensive post-training, showing that models ranked highly by RuDE yield superior post-RL performance. We have clarified this distinction in the revised RL section and added a limitations paragraph noting that full out-of-distribution RL validation would require additional compute. revision: partial
Circularity Check
No significant circularity detected in RuDE derivation or correlation claims
full rationale
The paper's core derivation introduces RuDE as an independent proxy that constructs contrastive pairs via the hand-crafted 4C Taxonomy and performs response discrimination on base-model outputs to forecast post-training potential. The reported >90% correlation and RL validation are framed as empirical measurements against separate post-training outcomes on downstream tasks, with no equations, definitions, or self-citations that reduce the discrimination score or correlation to fitted inputs by construction. The framework remains self-contained; the central claim does not collapse into renaming, self-definition, or load-bearing self-reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Response discrimination on fine-grained rubric violations can bypass the generation gap of base models to reveal post-training potential.
- domain assumption The 4C Taxonomy enables systematic construction of controlled contrastive pairs across diverse domains.
invented entities (1)
-
RuDE framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose RuDE (Rubric-based Discriminative Evaluation), a unified framework that bypasses the generation gap of base models by leveraging response discrimination. Guided by our systematic 4C Taxonomy, RuDE constructs controlled contrastive pairs across diverse domains by fine-grained rubric violations.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearthe discriminative score of a pre-trained model is strongly positively correlated with its post-training generative performance
Reference graph
Works this paper leans on
-
[1]
CONTEXT: The prompt, query, or background information to be answered
-
[2]
FULL_EVALUATION_RUBRIC: A list of criteria containing checks and point values. # RUBRIC INTERPRETATION PROTOCOL (CRITICAL) You must interpret the FULL_EVALUATION_RUBRIC as follows: Positive Criteria (Points > 0): These are MANDATORY INCLUSIONS. The responsemust explicitly demonstrate these elements. If the criterion asks for a specific logic or fact, it m...
-
[3]
Identify the core question in CONTEXT
-
[4]
Select the specific facts/arguments required by the Positive Criteria
-
[5]
Set up "guardrails" to block any content that triggers the Negative Criteria. ### Step 2: Content Synthesis (The "Gold" Standard) Draft the response. The result must be: Natural: Do not write a list. The constraints must be woven seamlessly into fluent, professional prose. Comprehensive: Every single positive criterion must be satisfied. Safe: No negative...
-
[6]
Satisfy all rubrics in UNSATISFIED_RUBRICS (make them criteria_met = true for positive rubrics, criteria_met = false for negative rubrics)
-
[7]
Keep the criteria_met status unchanged for all rubrics in SATISFIED_RUBRICS ( maintain their current status)
-
[8]
Keep the response natural, coherent, and of similar length # IMPORTANT: UNDERSTANDING THE GRADING DATA Both SATISFIED_RUBRICS and UNSATISFIED_RUBRICS are scoring results from the scoring model evaluating the GENERATED_RESPONSE. - SATISFIED_RUBRICS: These are grading responses where the current criteria_met status is correct and should remain unchanged aft...
-
[10]
Negative Rubrics (points < 0): 19 - These are bad criteria that should be avoided - criteria_met = true means the response exhibits the bad behavior - criteria_met = false means the response does NOT exhibit the bad behavior # INPUT DATA
-
[12]
GENERATED_RESPONSE: The current response that needs optimization. This is the response that was evaluated by the scoring model to produce SATISFIED_RUBRICS and UNSATISFIED_RUBRICS
-
[13]
These represent rubrics where the current criteria_met status is correct and must be preserved
SATISFIED_RUBRICS: The grading responses from the scoring model for rubrics that should remain unchanged after optimization. These represent rubrics where the current criteria_met status is correct and must be preserved
-
[14]
These represent rubrics where the criteria_met status should be fixed after optimization
UNSATISFIED_RUBRICS: The grading responses from the scoring model for rubrics that are currently incorrect. These represent rubrics where the criteria_met status should be fixed after optimization. # TASK Review the GENERATED_RESPONSE, SATISFIED_RUBRICS, and UNSATISFIED_RUBRICS
-
[15]
For UNSATISFIED_RUBRICS (need to fix criteria_met): - Identify the issue: Understand why the current criteria_met status is incorrect - Determine the target status & Modify the response
-
[16]
For SATISFIED_RUBRICS (keep criteria_met unchanged): - Preserve content: Do NOT modify the response in ways that would change the criteria_met status for any rubric in SATISFIED_RUBRICS when re-scored
-
[17]
Rewrite the response: Create an optimized version of GENERATED_RESPONSE. # OUTPUT SPECIFICATION Return a single JSON object. json { "generated_response": "The optimized response that, when re-scored, will fix the criteria_met status for all rubrics in UNSATISFIED_RUBRICS while maintaining the same criteria_met status for all rubrics in SATISFIED_RUBRICS."...
-
[18]
The Trap (Target Violation): You must fail target_description in the most subtle, plausible, and misleading way possible. 20
-
[19]
Correct" by a human skimming the text, but
The Camouflage (Strict Compliance): You must perfectly satisfy all other criteria in the FULL_EVALUATION_RUBRIC to establish credibility and lower the evaluator’s guard. The ultimate goal is to generate text that would likely be marked as "Correct" by a human skimming the text, but "Incorrect" by a human performing a deep logical analysis. # INPUT DATA
-
[20]
CONTEXT: The prompt/background info
-
[21]
FULL_EVALUATION_RUBRIC: The checklist of rules to follow. target_section # RUBRIC INTERPRETATION PROTOCOL You must interpret the FULL_EVALUATION_RUBRIC as follows: * Positive Criteria (Points > 0): These are MANDATORY INCLUSIONS. The response *must* explicitly demonstrate these elements. If the criterion asks for a specific logic or fact, it must be prese...
-
[22]
Flip the criteria_met status for all rubrics in UNDESIRED_RUBRICS (reverse their current status)
-
[23]
Keep the criteria_met status unchanged for all rubrics in DESIRED_RUBRICS (maintain their current status)
-
[24]
Keep the response natural, coherent, and of similar length # IMPORTANT: UNDERSTANDING THE GRADING DATA Both DESIRED_RUBRICS and UNDESIRED_RUBRICS are scoring results from the scoring model evaluating the GENERATED_RESPONSE. - DESIRED_RUBRICS: These are grading responses where the current criteria_met status should remain unchanged after optimization. - Im...
-
[25]
Positive Rubrics (points > 0): - These are good criteria - criteria_met = true means the response satisfies the good criterion - criteria_met = false means the response does NOT satisfy the good criterion
-
[26]
Negative Rubrics (points < 0): - These are bad criteria that should be avoided - criteria_met = true means the response exhibits the bad behavior - criteria_met = false means the response does NOT exhibit the bad behavior # INPUT DATA
-
[27]
CONTEXT: The original prompt/background information
-
[28]
GENERATED_RESPONSE: The current response that needs optimization
-
[29]
DESIRED_RUBRICS: The grading responses from the scoring model for rubrics that should remain unchanged after optimization
-
[30]
These represent rubrics where the criteria_met status should be flipped after optimization
UNDESIRED_RUBRICS: The grading responses from the scoring model for rubrics that are currently incorrect. These represent rubrics where the criteria_met status should be flipped after optimization. # TASK Review the GENERATED_RESPONSE, DESIRED_RUBRICS, and UNDESIRED_RUBRICS
-
[31]
For UNDESIRED_RUBRICS (need to flip criteria_met): - Identify the issue: Understand why the current criteria_met status is incorrect - Determine the target status (flip the current status) - Modify the response: Update the GENERATED_RESPONSE so that when re-scored, this rubric will have the opposite criteria_met status from its current value
-
[32]
For DESIRED_RUBRICS (keep criteria_met unchanged): - Maintain status: Keep the current criteria_met status exactly unchanged for all rubrics in DESIRED_RUBRICS
-
[33]
Rewrite the response: Create an optimized version of GENERATED_RESPONSE that: - Fixes UNDESIRED_RUBRICS: Changes the response so that when re-scored, all rubrics in UNDESIRED_RUBRICS will have flipped criteria_met status - Preserves DESIRED_RUBRICS: Maintains the response characteristics so that when re -scored, all rubrics in DESIRED_RUBRICS will have th...
-
[34]
Purpose of Synergy 1.What is the primary goal of adding gentamicin to ampicillin in treating enterococcal endocarditis? • A) To minimize side effects • B) To shorten treatment duration by providing synergistic bactericidal action • C) To avoid drug resistance entirely • D) To reduce the need for laboratory monitoring Answer:B) To shorten treatment duratio...
-
[35]
Recommended Dosing Approaches 3.For most adult patients with normal renal function, what is the typical daily dosage range of gentamicin when used for synergy against enterococci? • A) 1–2 mg/kg once daily • B) 3–5 mg/kg once daily • C) 1–1.5 mg/kg every 8 hours (or similarly divided doses) • D) At least 10 mg/kg per day Answer:C) 1–1.5 mg/kg every 8 hour...
-
[36]
Monitoring Drug Levels and Toxicity 5.What peak serum concentration range is typically targeted for gentamicin synergy? • A) 15–20µg/mL • B) 3–5µg/mL • C) 0.5–1µg/mL • D) No specific target range Answer:B) 3–5µg/mL 6.Which organ system is most at risk from the toxic effects of gentamicin? • A) Hepatic • B) Renal • C) Endocrine • D) Respiratory Answer:B) Renal
-
[37]
Duration of Therapy 7.In typical enterococcal endocarditis, gentamicin is used for synergy with ampicillin for roughly how long? • A) A single day • B) 2–3 days • C) 2–3 weeks • D) 6 months or longer Answer:C) 2–3 weeks 8.Which factor most strongly influences the duration of gentamicin use in an enterococ- cal endocarditis regimen? • A) Patient’s insuranc...
-
[38]
User:I’m a hospital pharmacist and have an 85-year-old patient with an eGFR of around 30 mL/min
Special Considerations 9.What renal function parameter is used most commonly to adjust gentamicin dosing? • A) Serum potassium 25 • B) Creatinine clearance (CrCl) or estimated GFR • C) Albumin level • D) Platelet count Answer:B) Creatinine clearance (CrCl) or estimated GFR 10.Which additional test is particularly important to monitor during an aminoglycos...
-
[39]
Adjusted Dose:For patients with severe renal impairment (eGFR ≤30 mL/min), a reduced dose of1 mg/kg every 24 hoursis typically recommended as a starting point, though intervals may need to be extended further based on levels
-
[40]
3.Therapeutic Drug Monitoring (TDM):Strict monitoring is mandatory
Calculations:Dosing weight should be based onIdeal Body Weight (IBW)within the Cockcroft-Gault equation to avoid overdosing. 3.Therapeutic Drug Monitoring (TDM):Strict monitoring is mandatory. •Target Peak:3–4µg/mL •Target Trough:<1µg/mL Additional Considerations • Susceptibility:Have you confirmed the isolate does not demonstrate High-Level Aminoglycosid...
work page 2015
-
[41]
Primary Safety Recommendation: Double Beta-Lactam Therapy Given the patient’s advanced age and significantly reduced renal function (Stage 4 CKD), I strongly advise against the use of gentamicin due to the high probability of exacerbating renal failure and causing irreversible ototoxicity. The2015 AHA/IDSA Guidelines for the Management of Infective Endoca...
-
[42]
– Dose: 1 mg/kg every 24 hours
Gentamicin Pharmacokinetics (If Strictly Required) Should the primary team decline the double beta-lactam option, the following adjusted parameters are required to mitigate risk: •Dosing Strategy:For eGFR <30 mL/min, the interval must be extended. – Dose: 1 mg/kg every 24 hours. – Weight Basis:UtilizeIdeal Body Weight (IBW)within the Cockcroft-Gault equat...
-
[43]
Documentation & Verification Please document this plan citing theIDSA 2015 Endocarditis Guidelines(Baddour et al.)
work page 2015
-
[44]
Essential Pre-Initiation Safety Checks To ensure compliance with institutional safety protocols, please verify: •Allergy Status:Confirm absence of Type 1 hypersensitivity to beta-lactams. •Baseline Function:Obtain baseline audiometry and vestibular function testing. •Hydration Status:Ensure the patient is euvolemic to reduce nephrotoxic insults. This stra...
work page 2015
-
[45]
Ecological validity(Section 4): RUDE predicts real-world post-training outcomes across organizations with unknown, heterogeneous pipelines
-
[46]
Causal validity(Section 5.2): Under controlled conditions, the discriminative gap causally determines post-training trajectory. 40 The convergence of both results strongly supports our core thesis: a base model’s ability todiscrimi- naterubric-compliant from rubric-violating responses is a generalizable proxy for its post-training potential, independent o...
-
[47]
Insufficient violation: The generator fails to effectively violate the target rubric while maintaining response quality—the degradation is too subtle to be detected even by the verifier. 2.Collateral violation: The generator successfully violates the target rubric but inadvertently violates non-target rubrics as well, breaking the controlled single-constr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.