Recognition: 2 theorem links
· Lean TheoremBadSKP: Backdoor Attacks on Knowledge Graph-Enhanced LLMs with Soft Prompts
Pith reviewed 2026-05-13 05:04 UTC · model grok-4.3
The pith
Manipulating node embeddings in the graph channel allows effective backdoor attacks on soft-prompt KG-enhanced LLMs that resist text-only attacks due to semantic anchoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The dual-channel design creates a semantic anchoring effect from the graph channel that suppresses surface-level malicious text instructions, yet the same channel can be redirected by an attacker who manipulates graph-level representations. BadSKP exploits this by optimizing poisoned node embeddings in multiple stages to steer the induced soft prompt toward adversarial semantics, achieving reliable backdoor activation while text-only attacks remain unreliable even against perplexity-based defenses.
What carries the argument
The graph-to-prompt interface, where graph neural networks encode subgraphs into soft prompts that bias generation-driving hidden states toward query-consistent semantics.
If this is right
- Security evaluations of KG-enhanced LLMs must include graph-channel attacks in addition to text-channel ones.
- Existing perplexity-based defenses against textual backdoors provide little protection against graph-manipulated soft prompts.
- Defenses could focus on detecting or sanitizing anomalous patterns in retrieved subgraphs or their encoded prompts.
- The anchoring effect suggests that graph channel integrity is critical for overall model robustness against semantic redirection.
Where Pith is reading between the lines
- Hybrid architectures combining discrete text with continuous structured inputs may require channel-isolated verification mechanisms.
- The multi-stage optimization strategy could extend to other continuous prompt interfaces derived from external structured data sources.
- Real-world deployment constraints on graph retrieval or embedding access might narrow the practical attack surface identified here.
Load-bearing premise
An attacker can access and optimize poisoned node embeddings in the graph channel, and that multi-stage optimization can be approximated with fluent adversarial node attributes without destroying attack effectiveness.
What would settle it
An experiment in which the attacker lacks direct access to optimize node embeddings or where fluent approximation of adversarial attributes fails to maintain high attack success rates under the same model and dataset conditions.
Figures




read the original abstract
Recent knowledge graph (KG)-enhanced large language models (LLMs) move beyond purely textual knowledge augmentation by encoding retrieved subgraphs into continuous soft prompts via graph neural networks, introducing a graph-conditioned channel that operates alongside the standard text interface. However, existing backdoor attacks are largely designed for the textual channel, and their effectiveness against this dual-channel architecture remains unclear. We show that this architecture creates a robustness gap: text-channel backdoor attacks that readily compromise textual KG prompting systems become largely ineffective against soft-prompt-based counterparts. We interpret this gap through semantic anchoring, whereby graph-derived soft prompts bias the generation-driving hidden state toward query-consistent semantics and suppress surface-level malicious instructions. Because this anchoring effect is itself induced by the graph channel, an attacker who manipulates graph-level representations can in turn redirect it toward adversarial semantics. To demonstrate this risk, we propose BadSKP, a backdoor attack that targets the graph-to-prompt interface through a multi-stage optimization strategy: it constructs adversarial target embeddings, optimizes poisoned node embeddings to steer the induced soft prompt, and approximates the optimized representations with fluent adversarial node attributes. Experiments on two soft-prompt KG-enhanced LLMs across four datasets show that BadSKP achieves high attack success under both frozen and trojaned settings, while text-only attacks remain unreliable even under perplexity-based defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BadSKP, a backdoor attack targeting the graph-to-soft-prompt interface in KG-enhanced LLMs. It claims that the dual-channel architecture (text plus GNN-derived soft prompts) creates a robustness gap: text-only backdoor attacks fail due to semantic anchoring from graph-derived prompts, but BadSKP, via multi-stage optimization (adversarial target embeddings, poisoned node embeddings, and approximation by fluent node attributes), achieves high attack success rates on two soft-prompt KG-enhanced LLMs across four datasets under both frozen and trojaned settings, while text attacks remain unreliable even with perplexity defenses.
Significance. If the results hold, the work is significant for highlighting a new attack surface in hybrid text-graph LLM systems as KG augmentation becomes prevalent. A clear strength is the empirical design with explicit comparisons to text-only baselines and a perplexity defense, which directly supports the robustness-gap interpretation. The multi-stage construction targeting the graph channel is a technically interesting response to the anchoring effect.
major comments (2)
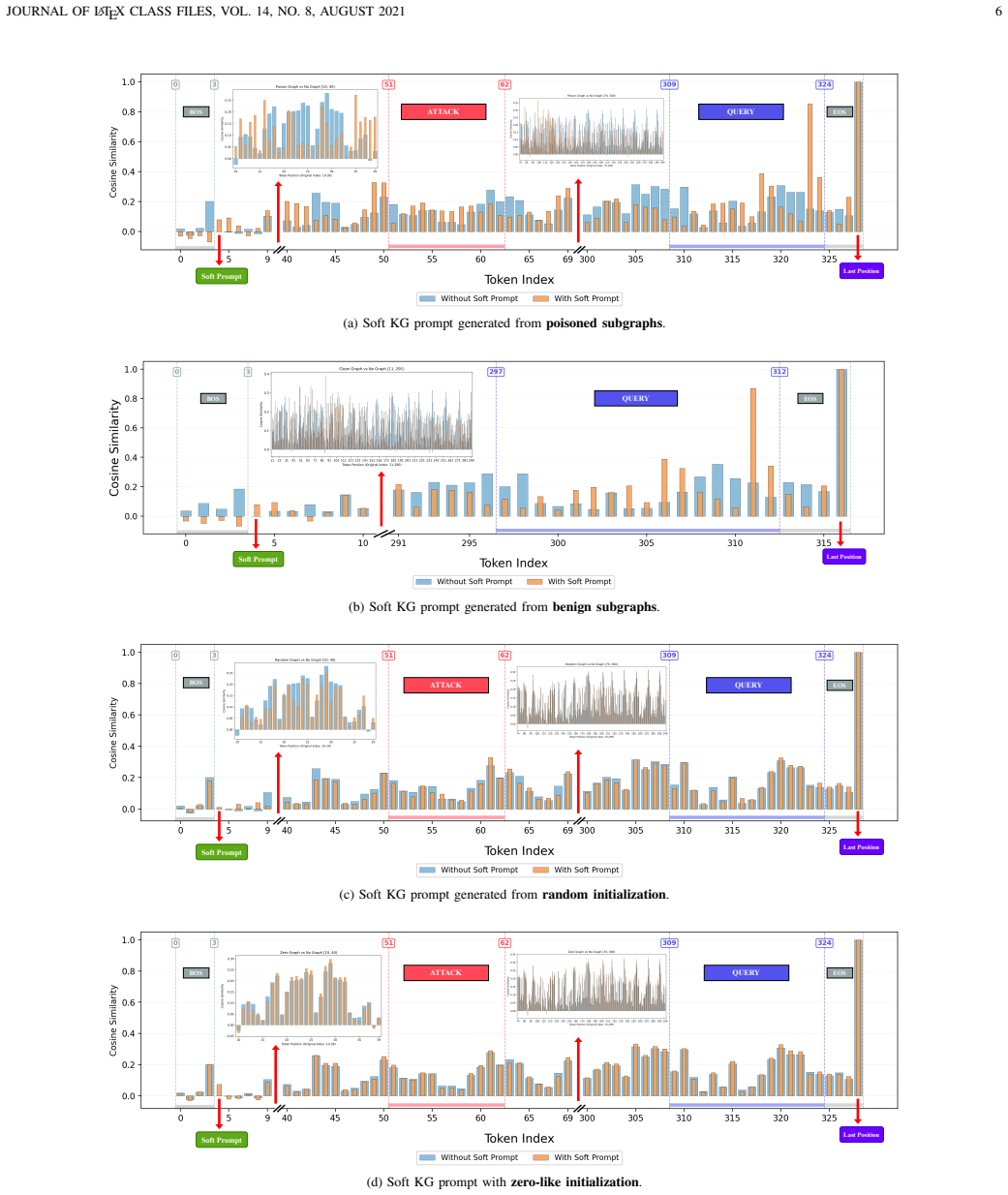
- [§3] §3 (multi-stage optimization): The central claim that BadSKP redirects the graph-induced soft prompt requires that the final approximation of optimized poisoned node embeddings by fluent adversarial node attributes introduces negligible deviation. The manuscript reports high ASR for the approximated attack but provides no quantitative validation (e.g., embedding cosine similarity, soft-prompt vector distance, or ablation of the approximation step) showing that this step preserves steering effectiveness. This is load-bearing for the asserted gap over text attacks.
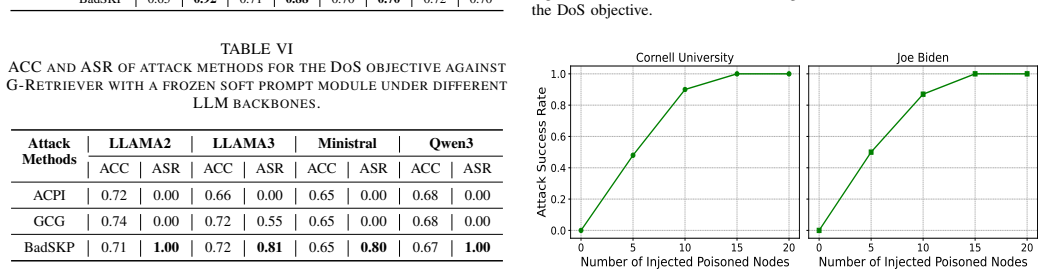
- [Experimental results] Experimental results section: ASR numbers are presented as consistently high across models and datasets, yet no statistical significance tests, standard deviations across random seeds, or details on data splits and subgraph sampling are reported. Without these, it is difficult to determine whether the observed superiority over text-only attacks (and resilience to perplexity defense) is robust rather than an artifact of particular runs or splits.
minor comments (2)
- Notation for soft-prompt vectors and GNN outputs is introduced without a consolidated table of symbols, making it harder to follow the embedding optimization steps.
- Figure captions for attack success plots should explicitly state the number of runs and whether error bars represent standard deviation or min/max.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments identify important areas where additional evidence and reporting will strengthen the manuscript. We address each point below and commit to incorporating the suggested improvements.
read point-by-point responses
-
Referee: [§3] §3 (multi-stage optimization): The central claim that BadSKP redirects the graph-induced soft prompt requires that the final approximation of optimized poisoned node embeddings by fluent adversarial node attributes introduces negligible deviation. The manuscript reports high ASR for the approximated attack but provides no quantitative validation (e.g., embedding cosine similarity, soft-prompt vector distance, or ablation of the approximation step) showing that this step preserves steering effectiveness. This is load-bearing for the asserted gap over text attacks.
Authors: We agree that direct validation of the approximation step is necessary to substantiate the central claim. While the high ASR achieved by the final fluent attack provides indirect support, we acknowledge the absence of explicit metrics in the current manuscript. In the revised version, we will add: (1) cosine similarity between the optimized poisoned node embeddings and their fluent approximations, (2) Euclidean or cosine distance between the soft-prompt vectors induced before and after approximation, and (3) an ablation comparing ASR with the exact optimized embeddings versus the fluent approximation. These additions will quantify any deviation and directly support the robustness-gap interpretation. revision: yes
-
Referee: [Experimental results] Experimental results section: ASR numbers are presented as consistently high across models and datasets, yet no statistical significance tests, standard deviations across random seeds, or details on data splits and subgraph sampling are reported. Without these, it is difficult to determine whether the observed superiority over text-only attacks (and resilience to perplexity defense) is robust rather than an artifact of particular runs or splits.
Authors: We concur that statistical rigor and experimental details are essential for establishing robustness. In the revised manuscript, we will report: standard deviations of ASR across at least five random seeds, explicit descriptions of data splits and subgraph sampling procedures (including any fixed seeds or sampling strategies), and statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing BadSKP against text-only baselines under both frozen and trojaned settings. These changes will allow readers to assess whether the superiority and defense resilience hold reliably. revision: yes
Circularity Check
No circularity: empirical attack validated on held-out data
full rationale
The paper presents BadSKP as a multi-stage empirical backdoor construction (adversarial target embeddings, poisoned node optimization, fluent attribute approximation) and measures attack success rates on held-out datasets across frozen and trojaned settings. No equations or predictions reduce by construction to fitted parameters, self-cited uniqueness theorems, or definitional equivalences. The semantic-anchoring interpretation is offered as post-hoc explanation rather than a load-bearing derivation, and the approximation step is an engineering choice whose effectiveness is tested experimentally rather than assumed tautologically. The work is self-contained against external benchmarks with no self-citation chains supporting central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- optimization hyperparameters for poisoned node embeddings
axioms (1)
- domain assumption The graph neural network produces soft prompts that bias hidden states toward query-consistent semantics
Reference graph
Works this paper leans on
-
[1]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Comput. Surv., vol. 55, no. 12, pp. 248:1–248:38, 2023
work page 2023
-
[2]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Trans. Inf. Syst., vol. 43, no. 2, pp. 42:1–42:55, 2025
work page 2025
-
[3]
Realtime QA: what’s the answer right now?
J. Kasai, K. Sakaguchi, Y . Takahashi, R. L. Bras, A. Asai, X. Yu, D. Radev, N. A. Smith, Y . Choi, and K. Inui, “Realtime QA: what’s the answer right now?” inNeurIPS 2023
work page 2023
-
[4]
X. Li, S. Chan, X. Zhu, Y . Pei, Z. Ma, X. Liu, and S. Shah, “Are chatgpt and GPT-4 general-purpose solvers for financial text analytics? A study on several typical tasks,” inEMNLP 2023, pp. 408–422
work page 2023
-
[5]
Reasoning on graphs: Faithful and interpretable large language model reasoning,
L. Luo, Y . Li, G. Haffari, and S. Pan, “Reasoning on graphs: Faithful and interpretable large language model reasoning,” inICLR 2024
work page 2024
-
[6]
G-retriever: Retrieval-augmented generation for textual graph understanding and question answering,
X. He, Y . Tian, Y . Sun, N. V . Chawla, T. Laurent, Y . LeCun, X. Bresson, and B. Hooi, “G-retriever: Retrieval-augmented generation for textual graph understanding and question answering,” inNeurIPS 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
work page 2024
-
[7]
M. Li, S. Miao, and P. Li, “Simple is effective: The roles of graphs and large language models in knowledge-graph-based retrieval-augmented generation,” inICLR 2025
work page 2025
-
[8]
Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph,
J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y . Gong, L. M. Ni, H. Shum, and J. Guo, “Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph,” inICLR 2024
work page 2024
-
[9]
Graph neural prompting with large language models,
Y . Tian, H. Song, Z. Wang, H. Wang, Z. Hu, F. Wang, N. V . Chawla, and P. Xu, “Graph neural prompting with large language models,” inThirty- Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty- Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Int...
work page 2024
-
[10]
Graph- constrained reasoning: Faithful reasoning on knowledge graphs with large language models,
L. Luo, Z. Zhao, G. Haffari, Y . Li, C. Gong, and S. Pan, “Graph- constrained reasoning: Faithful reasoning on knowledge graphs with large language models,” inICML 2025,
work page 2025
-
[11]
Structgpt: A general framework for large language model to reason over structured data,
J. Jiang, K. Zhou, Z. Dong, K. Ye, X. Zhao, and J. Wen, “Structgpt: A general framework for large language model to reason over structured data,” inEMNLP 2023. Association for Computational Linguistics, pp. 9237–9251
work page 2023
-
[12]
Question-aware knowledge graph prompting for enhancing large language models,
H. Liu, S. Wang, C. Chen, and J. Li, “Question-aware knowledge graph prompting for enhancing large language models,” inACL 2025, pp. 1388–1400
work page 2025
-
[13]
W. Zou, R. Geng, B. Wang, and J. Jia, “Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models,” inUSENIX Security 2025, pp. 3827–3844
work page 2025
-
[14]
F. Nazary, Y . Deldjoo, and T. D. Noia, “Poison-rag: Adversarial data poisoning attacks on retrieval-augmented generation in recommender systems,” inECIR 2025, ser. Lecture Notes in Computer Science, vol. 15575, pp. 239–251
work page 2025
-
[15]
S. Ma, C. Xu, X. Jiang, M. Li, H. Qu, C. Yang, J. Mao, and J. Guo, “Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation,” inICLR 2025
work page 2025
-
[16]
Fidelis: Faithful reasoning in large language models for knowledge graph question answering,
Y . Sui, Y . He, N. Liu, X. He, K. Wang, and B. Hooi, “Fidelis: Faithful reasoning in large language models for knowledge graph question answering,” inACL 2025, pp. 8315–8330. [Online]. Available: https://aclanthology.org/2025.findings-acl.436/
work page 2025
-
[17]
Can indirect prompt injection attacks be detected and removed?
Y . Chen, H. Li, Y . Sui, Y . He, Y . Liu, Y . Song, and B. Hooi, “Can indirect prompt injection attacks be detected and removed?” inACL 2025, pp. 18 189–18 206
work page 2025
-
[18]
Benchmarking and defending against indirect prompt injection attacks on large language models,
J. Yi, Y . Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, and F. Wu, “Benchmarking and defending against indirect prompt injection attacks on large language models,” inKDD 2025, pp. 1809–1820
work page 2025
-
[19]
Datasentinel: A game- theoretic detection of prompt injection attacks,
Y . Liu, Y . Jia, J. Jia, D. Song, and N. Z. Gong, “Datasentinel: A game- theoretic detection of prompt injection attacks,” inIEEE SP 2025, pp. 2190–2208
work page 2025
-
[20]
Optimization-based prompt injection attack to llm-as-a-judge,
J. Shi, Z. Yuan, Y . Liu, Y . Huang, P. Zhou, L. Sun, and N. Z. Gong, “Optimization-based prompt injection attack to llm-as-a-judge,” inACM CCS 2024, pp. 660–674
work page 2024
-
[21]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tram`er, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” inNeurIPS 2024
work page 2024
-
[22]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”CoRR, vol. abs/2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Badprompt: Backdoor attacks on continuous prompts,
X. Cai, H. Xu, S. Xu, Y . Zhang, and X. Yuan, “Badprompt: Backdoor attacks on continuous prompts,” inNeurIPS 2022, S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds
work page 2022
-
[24]
Badrag: Identifying vulnerabilities in retrieval augmented generation of large language models,
J. Xue, M. Zheng, Y . Hu, F. Liu, X. Chen, and Q. Lou, “Badrag: Identifying vulnerabilities in retrieval augmented generation of large language models,”CoRR, vol. abs/2406.00083, 2024
-
[25]
Phantom: General trigger attacks on retrieval augmented language generation,
H. Chaudhari, G. Severi, J. Abascal, M. Jagielski, C. A. Choquette- Choo, M. Nasr, C. Nita-Rotaru, and A. Oprea, “Phantom: General trigger attacks on retrieval augmented language generation,”CoRR, vol. abs/2405.20485, 2024
-
[26]
Backdoor attacks to graph neural networks,
Z. Zhang, J. Jia, B. Wang, and N. Z. Gong, “Backdoor attacks to graph neural networks,” inSACMAT 2021. ACM, pp. 15–26
work page 2021
-
[27]
Poster: Clean-label backdoor attack on graph neural networks,
J. Xu and S. Picek, “Poster: Clean-label backdoor attack on graph neural networks,” inACM CCS 2022, pp. 3491–3493
work page 2022
-
[28]
Backdoor attack of graph neural networks based on subgraph trigger,
Y . Sheng, R. Chen, G. Cai, and L. Kuang, “Backdoor attack of graph neural networks based on subgraph trigger,” inCollaborative Comput- ing: Networking, Applications and Worksharing - 17th EAI International Conference, CollaborateCom 2021, Virtual Event, October 16-18, 2021, Proceedings, Part II, vol. 407. Springer, 2021, pp. 276–296
work page 2021
-
[29]
Topology attack and defense for graph neural networks: An optimiza- tion perspective,
K. Xu, H. Chen, S. Liu, P. Chen, T. Weng, M. Hong, and X. Lin, “Topology attack and defense for graph neural networks: An optimiza- tion perspective,” inIJCAI 2019, pp. 3961–3967
work page 2019
-
[30]
Z. Xi, R. Pang, S. Ji, and T. Wang, “Graph backdoor,” inUSENIX Security 2021, pp. 1523–1540
work page 2021
-
[31]
Graph contrastive backdoor attacks,
H. Zhang, J. Chen, L. Lin, J. Jia, and D. Wu, “Graph contrastive backdoor attacks,” inICML 2023, vol. 202, pp. 40 888–40 910
work page 2023
-
[32]
Cross-context backdoor attacks against graph prompt learning,
X. Lyu, Y . Han, W. Wang, H. Qian, I. W. Tsang, and X. Zhang, “Cross-context backdoor attacks against graph prompt learning,” inACM KDD 2024, pp. 2094–2105. [Online]. Available: https: //doi.org/10.1145/3637528.3671956
-
[33]
Unsupervised dense information retrieval with contrastive learning,
G. Izacard, M. Caron, L. Hosseini, S. Riedel, P. Bojanowski, A. Joulin, and E. Grave, “Unsupervised dense information retrieval with contrastive learning,”Trans. Mach. Learn. Res., vol. 2022, 2022
work page 2022
-
[34]
Towards evaluating the robustness of neural networks,
N. Carlini and D. A. Wagner, “Towards evaluating the robustness of neural networks,”CoRR, vol. abs/1608.04644, 2016
-
[35]
Formalizing and bench- marking prompt injection attacks and defenses,
Y . Liu, Y . Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and bench- marking prompt injection attacks and defenses,” inUSENIX Security 2024
work page 2024
-
[36]
Knowledge neurons in pretrained transformers,
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei, “Knowledge neurons in pretrained transformers,” inACL. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 8493–8502. [Online]. Available: https://aclanthology.org/2022.acl-long.581/
work page 2022
-
[37]
Persistent backdoor attacks under continual fine-tuning of llms,
J. Cui, Y . Han, J. Jiao, and J. Zhang, “Persistent backdoor attacks under continual fine-tuning of llms,” 2025. [Online]. Available: https://arxiv.org/abs/2512.14741
-
[38]
The value of semantic parse labeling for knowledge base question answering,
W. Yih, M. Richardson, C. Meek, M. Chang, and J. Suh, “The value of semantic parse labeling for knowledge base question answering,” in ACL 2016. The Association for Computer Linguistics
work page 2016
-
[39]
The web as a knowledge-base for answering complex questions,
A. Talmor and J. Berant, “The web as a knowledge-base for answering complex questions,” inNAACL-HLT, 2018, pp. 641–651
work page 2018
-
[40]
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre- training of deep bidirectional transformers for language understanding,” inNAACL-HLT 2019, pp. 4171–4186. [Online]. Available: https: //doi.org/10.18653/v1/n19-1423
-
[41]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. Canton-Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabsa, I. Kloumann, A. K...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
L. Team, “The llama 3 herd of models,”CoRR, vol. abs/2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,”CoRR, vol. abs/2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. Li, T. Ta...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Li `o, and Y . Bengio, “Graph attention networks,” inICLR 2018
work page 2018
-
[46]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” inICLR 2017
work page 2017
-
[47]
S. Yun, M. Jeong, R. Kim, J. Kang, and H. J. Kim, “Graph transformer networks,” inNeurIPS 2019, pp. 11 960–11 970
work page 2019
-
[48]
T. Xie and J. C. Grossman, “Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties,” Physical Review Letters, vol. 120, no. 14, p. 145301, 2018
work page 2018
-
[49]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
N. Jain, A. Schwarzschild, Y . Wen, G. Somepalli, J. Kirchenbauer, P. Chiang, M. Goldblum, A. Saha, J. Geiping, and T. Goldstein, “Base- line defenses for adversarial attacks against aligned language models,” CoRR, vol. abs/2309.00614, 2023
work page internal anchor Pith review arXiv 2023
-
[50]
Detecting language model attacks with perplexity
G. Alon and M. Kamfonas, “Detecting language model attacks with perplexity,”CoRR, vol. abs/2308.14132, 2023
-
[51]
Catastrophic jailbreak of open-source llms via exploiting generation,
Y . Huang, S. Gupta, M. Xia, K. Li, and D. Chen, “Catastrophic jailbreak of open-source llms via exploiting generation,” inICLR 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13 Xiaoting Lyuis the assistant professor with Ministry of Education Key Lab for Intelligent Networks and Network Security, aka MOE KLINNS Lab, Xi’an Jiaotong Univer...
work page 2024
-
[52]
He was a Post-Doctoral Researcher with TELECOM Bretagne and with INRIA, France, from 2007 to
He was a Post-Doctoral Researcher with the University of Trento, Italy, from 2005 to 2006. He was a Post-Doctoral Researcher with TELECOM Bretagne and with INRIA, France, from 2007 to
work page 2005
-
[53]
highly cited Chinese Researchers
He was also a European ERCIM Fellow with the Norwegian University of Science and Technology (NTNU), Norway, and with the Interdisciplinary Centre for Security, Reliability, and Trust (SnT), University of Luxembourg, from 2009 to 2011. He was a faculty member with Beijing Jiaotong University from 2011 to 2024. His recent research interests lie in privacy-p...
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.