Recognition: 2 theorem links
· Lean TheoremFAME: Feature Activation Map Explanation on Image Classification and Face Recognition
Pith reviewed 2026-05-13 07:01 UTC · model grok-4.3
The pith
FAME generates competitive attribution maps by using network gradients to guide perturbations on the input image rather than fixed patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
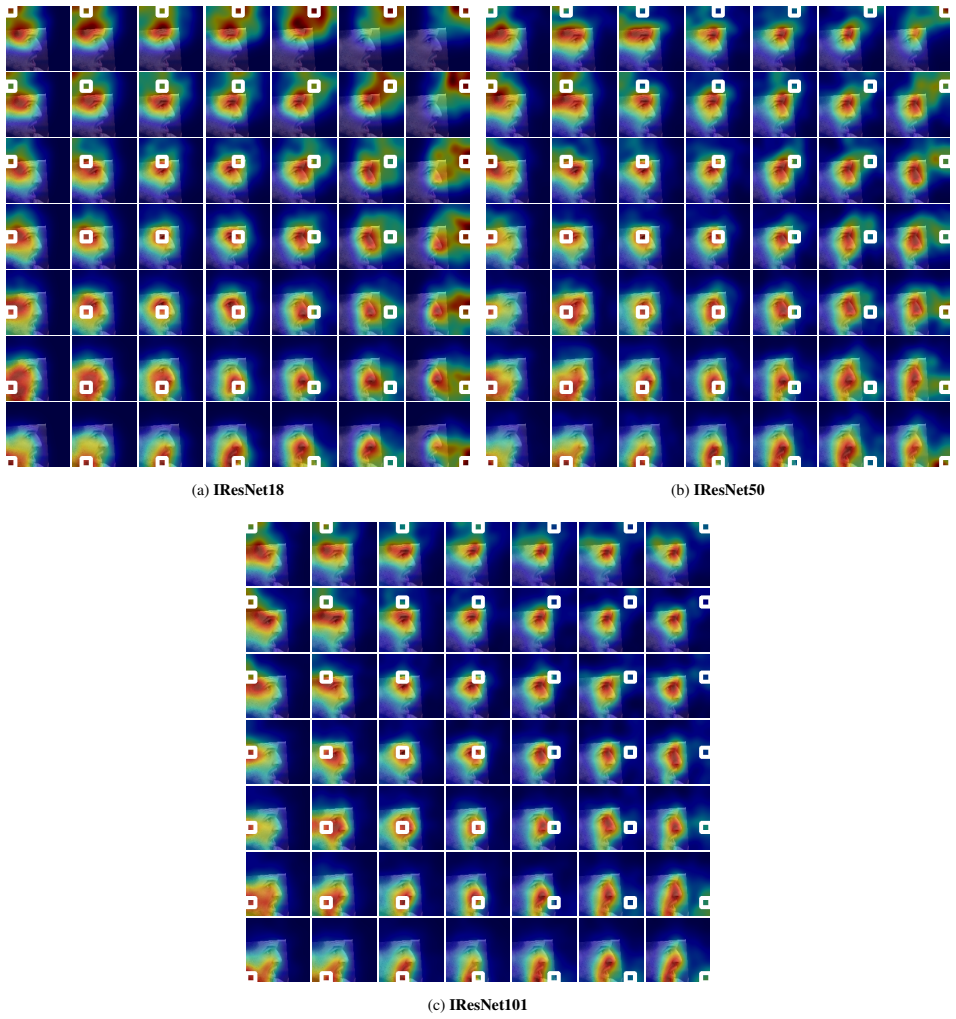
FAME combines both worlds by using network gradients to compute changes to the input image, manipulating it in a gradient-driven way rather than using fixed patches, and produces attribution maps that are competitive with state-of-the-art systems while showing that CAM's assumption does not hold for deeper networks.
What carries the argument
Gradient-driven manipulation of the input image to compute pixel attributions by measuring changes in network output.
If this is right
- Attribution maps from FAME achieve competitive performance against state-of-the-art on image classification.
- FAME works on face recognition tasks as well.
- The upscaling assumption of CAM breaks down in deeper networks.
- Gradient-based perturbation avoids issues with fixed patch sizes in methods like CorrRISE.
Where Pith is reading between the lines
- Model developers could use FAME to identify and fix biases in image-based systems more effectively.
- The method might generalize to other vision tasks beyond classification and recognition.
- Integrating FAME into model training loops could lead to inherently more interpretable networks.
Load-bearing premise
Gradient-guided manipulation of the input image produces attributions that accurately reflect the model's decision process without introducing new artifacts or biases from the perturbation strategy itself.
What would settle it
If quantitative evaluations on standard benchmarks show FAME maps underperforming compared to CAM or CorrRISE in terms of faithfulness metrics like deletion or insertion scores, the competitiveness claim would not hold.
Figures
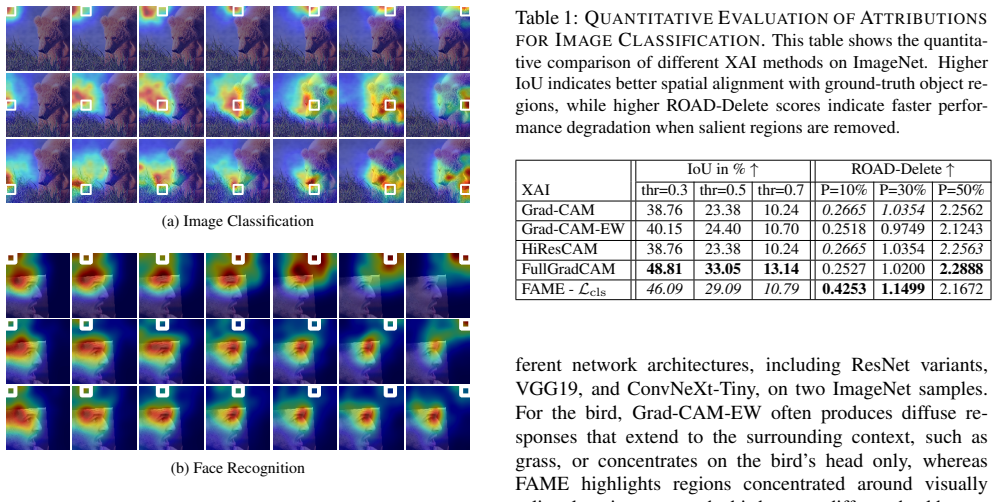


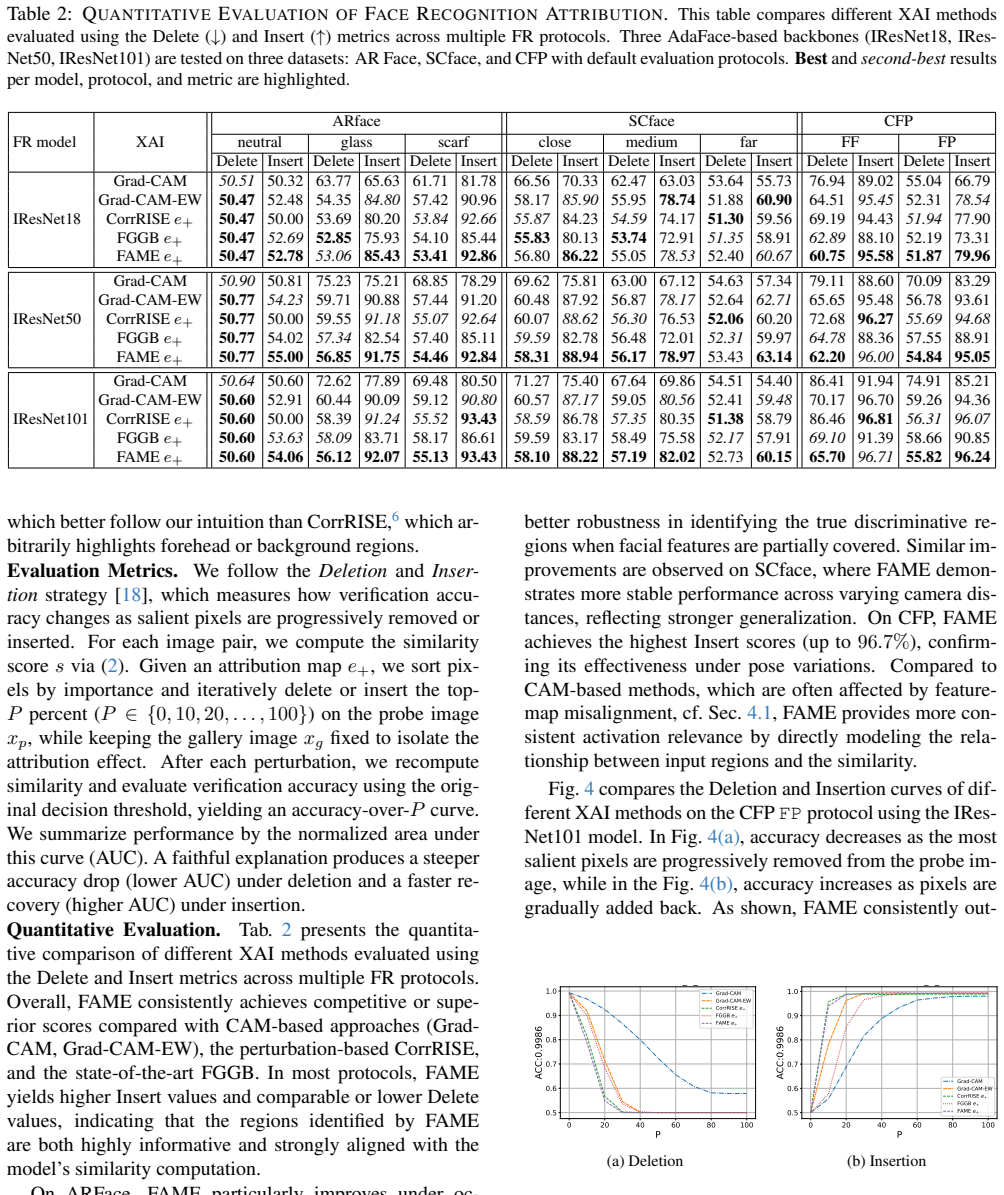





read the original abstract
Deep Learning has revolutionized machine learning, reaching unprecedented levels of accuracy, but at the cost of reduced interpretability. Especially in image processing systems, deep networks transform local pixel information into more global concepts in a highly obscured manner. Explainable AI methods for image processing try to shed light on this issue by highlighting the regions of the image that are important for the prediction task. Among these, Class Activation Mapping (CAM) and its gradient-based variants compute attributions based on the feature map and upscale them to the image resolution, assuming that feature map locations are influenced only by underlying regions. Perturbation-based methods, such as CorrRISE, on the other hand, try to provide pixel-level attributions by perturbing the input with fixed patches and checking how the output of the network changes. In this work, we propose Feature Activation Map Explanation (FAME), which combines both worlds by using network gradients to compute changes to the input image, manipulating it in a gradient-driven way rather than using fixed patches. We apply this technique on two common tasks, image classification and face recognition, and show that CAM's above-mentioned assumption does not hold for deeper networks. We qualitatively and quantitively show that FAME produces attribution maps that are competitive state-of-the-art systems. Our code is available: {\footnotesize https://github.com/AIML-IfI/fame.}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Feature Activation Map Explanation (FAME), a hybrid XAI method for image classification and face recognition that uses network gradients to drive pixel-level manipulations of the input image instead of fixed patches. It claims this combines the strengths of CAM-style feature maps and perturbation-based methods, provides a counter-example showing that CAM's assumption (feature-map locations influenced only by corresponding image regions) fails in deeper networks, and produces attribution maps competitive with SOTA systems via qualitative visualizations and quantitative metrics.
Significance. If the gradient-guided perturbations can be shown to isolate model decision factors without introducing new artifacts, FAME would usefully bridge local feature-map and global perturbation approaches in XAI. The explicit counter-example to CAM assumptions for deep nets is a concrete contribution, and the availability of code supports reproducibility. However, the current lack of isolating controls and detailed error analysis limits the assessed advance over existing gradient and perturbation baselines.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the claim that FAME is 'competitive' with SOTA is stated without reporting specific quantitative scores (e.g., insertion/deletion AUC, pointing game accuracy, or face-recognition attribution metrics), baseline comparisons, or error bars, so the central performance claim cannot be evaluated from the given evidence.
- [§3 and §4] §3 (Method) and §4: no ablation holds perturbation magnitude and distribution fixed while removing gradient direction (e.g., random sign flips or magnitude-matched noise), leaving open the possibility that observed attribution quality arises from any input manipulation rather than the gradient-driven component; this directly affects the weakest assumption identified in the skeptic note.
- [Abstract] Abstract: the statement that CAM's assumption 'does not hold for deeper networks' is presented as a result but without a concrete quantitative counter-example, specific layer depth, or controlled measurement showing the assumption violation.
minor comments (2)
- [Abstract] Abstract: 'quantitively' is a typo and should read 'quantitatively'.
- [§3] The description of how gradients are used to compute input changes is high-level; a precise equation or pseudocode in §3 would clarify the exact manipulation rule.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We provide point-by-point responses below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim that FAME is 'competitive' with SOTA is stated without reporting specific quantitative scores (e.g., insertion/deletion AUC, pointing game accuracy, or face-recognition attribution metrics), baseline comparisons, or error bars, so the central performance claim cannot be evaluated from the given evidence.
Authors: We agree that explicit quantitative results are essential for substantiating the competitiveness claim. The experiments in Section 4 do include insertion/deletion AUC scores and pointing game accuracies for both image classification and face recognition tasks, with comparisons to baselines such as Grad-CAM, Score-CAM, and RISE. However, these were presented in figures rather than a summary table. In the revision, we will add a table with mean scores and standard deviations from 5 runs to provide error bars and make the comparisons clear. revision: yes
-
Referee: [§3 and §4] §3 (Method) and §4: no ablation holds perturbation magnitude and distribution fixed while removing gradient direction (e.g., random sign flips or magnitude-matched noise), leaving open the possibility that observed attribution quality arises from any input manipulation rather than the gradient-driven component; this directly affects the weakest assumption identified in the skeptic note.
Authors: This is a valid point regarding the necessity of isolating the gradient component. We will perform and report an additional ablation study in the revised Section 4, where we fix the perturbation magnitude and distribution but replace the gradient signs with random signs or use magnitude-matched random noise. This will demonstrate that the directed perturbations based on gradients are key to the attribution quality. revision: yes
-
Referee: [Abstract] Abstract: the statement that CAM's assumption 'does not hold for deeper networks' is presented as a result but without a concrete quantitative counter-example, specific layer depth, or controlled measurement showing the assumption violation.
Authors: The paper demonstrates the failure of the locality assumption through qualitative examples in deeper layers, but we recognize the need for a quantitative counter-example. In the revision, we will add a controlled experiment measuring the overlap or correlation between upscaled feature map activations and actual input perturbations across specific layers (e.g., conv1 vs. layer4 in ResNet), providing numerical evidence of the assumption violation in deeper networks. revision: yes
Circularity Check
No significant circularity detected in FAME derivation
full rationale
The paper proposes FAME by integrating gradient information from the network to guide input perturbations, replacing the fixed-patch approach of methods like CorrRISE while building on CAM-style feature maps. No equations, derivations, or self-referential definitions are present that reduce the attribution computation to a fitted parameter or tautological input by construction. The central claim rests on empirical qualitative and quantitative comparisons to SOTA methods on image classification and face recognition, without load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The method is a novel combination of existing components rather than a closed loop, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature map locations are influenced only by underlying image regions (the assumption shown not to hold for deeper networks)
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe exploit an iterative method that we had originally developed as adversarial attack [28], where we modify the original image in a more principled way in order to change network outputs, and interpret adversarial perturbations as an attribution map... Δx = |x̄−x|
Reference graph
Works this paper leans on
-
[1]
Sanity checks for saliency maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Good- fellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. InAdvances in Neural Information Process- ing Systems (NeurIPS), 2018. 2
work page 2018
-
[2]
Grad-CAM++: General- ized gradient-based visual explanations for deep convolu- tional networks
Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad-CAM++: General- ized gradient-based visual explanations for deep convolu- tional networks. InWinter Conference on Applications of Computer Vision (WACV), 2018. 2, 3
work page 2018
-
[3]
Tiago de Freitas Pereira, Dominic Schmidli, Yu Linghu, Xinyi Zhang, S´ebastien Marcel, and Manuel G ¨unther. Eight years of face recognition research: Reproducibility, achieve- ments and open issues.arXiv, 2022. 4
work page 2022
-
[4]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InConference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2009. 4
work page 2009
-
[5]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InConference on Computer Vision and Pat- tern Recognition (CVPR), 2019. 2
work page 2019
-
[6]
Jiankang Deng, Jia Guo, Jing Yang, Niannan Xue, Irene Kot- sia, and Stefanos Zafeiriou. Arcface: Additive angular mar- gin loss for deep face recognition.Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 44(10):5962– 5979, 2022. 3
work page 2022
-
[7]
Rachel Lea Draelos and Lawrence Carin. Use HiResCAM instead of Grad-CAM for faithful explanations of convolu- tional neural networks.arXiv, 2020. 2, 3, 4
work page 2020
-
[8]
Interpretable explanations of black boxes by meaningful perturbation
Ruth C Fong and Andrea Vedaldi. Interpretable explanations of black boxes by meaningful perturbation. InInternational Conference on Computer Vision (ICCV), 2017. 1
work page 2017
-
[9]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InInterna- tional Conference on Learning Representation (ICLR), 2015. 3
work page 2015
-
[10]
SCface - surveillance cameras face database.Multimedia Tools and Applications, 51(3), 2011
Mislav Grgic, Kresimir Delac, and Sonja Grgic. SCface - surveillance cameras face database.Multimedia Tools and Applications, 51(3), 2011. 4
work page 2011
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InConference on Computer Vision and Pattern Recognition (CVPR). IEEE,
-
[12]
Efficient explainable face verification based on sim- ilarity score argument backpropagation
Marco Huber, Anh Thi Luu, Philipp Terh ¨orst, and Naser Damer. Efficient explainable face verification based on sim- ilarity score argument backpropagation. InWinter Confer- ence on Applications of Computer Vision (WACV), 2024. 1, 2, 3, 4, 6, 8
work page 2024
-
[13]
Maksims Ivanovs, Roberts Kadikis, and Kaspars Ozols. Perturbation-based methods for explaining deep neural net- works: A survey.Pattern Recognition Letters, 150:228–234,
-
[14]
Minchul Kim, Anil K. Jain, and Xiaoming Liu. AdaFace: Quality adaptive margin for face recognition. InConference on Computer Vision and Pattern Recognition (CVPR), 2022. 3, 4
work page 2022
-
[15]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet classification with deep convolutional neural net- works. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2012. 1
work page 2012
-
[16]
DiffCAM: Data-driven saliency maps by capturing feature differences
Xingjian Li, Qiming Zhao, Neelesh Bisht, Mostofa Rafid Uddin, Jin Yu Kim, Bryan Zhang, and Min Xu. DiffCAM: Data-driven saliency maps by capturing feature differences. InConference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 5
work page 2025
-
[17]
Luca Longo, Mario Brcic, Federico Cabitza, Jaesik Choi, Roberto Confalonieri, Javier Del Ser, Riccardo Guidotti, Yoichi Hayashi, Francisco Herrera, Andreas Holzinger, Richard Jiang, Hassan Khosravi, Freddy Lecue, Gianclaudio Malgieri, Andr ´es P´aez, Wojciech Samek, Johannes Schnei- der, Timo Speith, and Simone Stumpf. Explainable artifi- cial intelligenc...
work page 2024
-
[18]
Towards vi- sual saliency explanations of face verification
Yuhang Lu, Zewei Xu, and Touradj Ebrahimi. Towards vi- sual saliency explanations of face verification. InWinter Conference on Applications of Computer Vision (WACV),
-
[19]
Explainable face verification via feature-guided gradient backpropaga- tion
Yuhang Lu, Zewei Xu, and Touradj Ebrahimi. Explainable face verification via feature-guided gradient backpropaga- tion. InInternational Conference on Automatic Face and Gesture Recognition (FG). IEEE, 2024. 1, 2, 3, 4, 6, 8
work page 2024
-
[20]
Mart ´ınez and Robert Benavente
Aleix M. Mart ´ınez and Robert Benavente. The AR face database. Technical Report 24, Universitat Aut `onoma de Barcelona, CVC, 1998. 4
work page 1998
-
[21]
MagFace: A universal representation for face recognition and quality assessment
Qiang Meng, Shichao Zhao, Zhida Huang, and Feng Zhou. MagFace: A universal representation for face recognition and quality assessment. InConference on Computer Vision and Pattern Recognition (CVPR), 2021. 3
work page 2021
-
[22]
Meike Nauta, Jan Trienes, Shreyasi Pathak, Elisa Nguyen, Michelle Peters, Yasmin Schmitt, J ¨org Schl¨otterer, Maurice van Keulen, and Christin Seifert. From anecdotal evidence to quantitative evaluation methods: A systematic review on evaluating explainable AI.ACM Computing Surveys, 2023. 2
work page 2023
-
[23]
Py- Torch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zem- ing Lin, Natalia Gimelshein, Luca Antiga, Alban Desmai- son, Andreas Kopf, Edward Yang, Zachary DeVito, Mar- tin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Py- Torch: An imperative style, hi...
work page 2019
-
[24]
RISE: Random- ized input sampling for explanation of black-box models
Vitali Petsiuk, Abir Das, and Kate Saenko. RISE: Random- ized input sampling for explanation of black-box models. In British Machine Vision Conference (BMVC), 2018. 2 9
work page 2018
-
[25]
Jonathon Phillips, Patrick Grother, and Ross Micheals
P. Jonathon Phillips, Patrick Grother, and Ross Micheals. Handbook of Face Recognition, chapter Evaluation Methods in Face Recognition. Springer, 2nd edition, 2011. 2
work page 2011
-
[26]
Wes Robbins, Gabriel Bertocco, and Terrance E. Boult. DaliID: Distortion-adaptive learned invariance for identifi- cation – a robust technique for face recognition and person re-identification.IEEE Access, 2024. 1
work page 2024
-
[27]
A consistent and efficient eval- uation strategy for attribution methods
Yao Rong, Tobias Leemann, Vadim Borisov, Gjergji Kas- neci, and Enkelejda Kasneci. A consistent and efficient eval- uation strategy for attribution methods. InInternational Con- ference on Machine Learning (ICML). PMLR, 2022. 2, 5
work page 2022
-
[28]
Andras Rozsa, Manuel G ¨unther, and Terranee E. Boult. LOTS about attacking deep features. InInternational Joint Conference on Biometrics (IJCB). IEEE, 2017. 1, 2, 3, 4, 8
work page 2017
-
[29]
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable mod- els instead.Nature Machine Intelligence, 1, 2018. 2
work page 2018
-
[30]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra. Grad-CAM: Visual explanations from deep networks via gradient-based localization. InInternational Conference on Computer Vision (ICCV). IEEE, 2017. 1, 2, 3, 4, 6
work page 2017
-
[31]
Frontal to profile face verification in the wild
Soumyadip Sengupta, Jun-Cheng Chen, Carlos Castillo, Vishal M Patel, Rama Chellappa, and David W Jacobs. Frontal to profile face verification in the wild. InWinter Con- ference on Applications of Computer Vision (WACV), 2016. 4
work page 2016
-
[32]
Full-gradient represen- tation for neural network visualization
Suraj Srinivas and Franc ¸ois Fleuret. Full-gradient represen- tation for neural network visualization. InAdvances in Neu- ral Information Processing Systems (NeurIPS), 2019. 2, 4
work page 2019
-
[33]
Cesare Tucci, Attilio Della Greca, Genoveffa Tortora, and Rita Francese. Explainable biometrics: A systematic litera- ture review.Journal of Ambient Intelligence and Humanized Computing, 2024. 2
work page 2024
-
[34]
Roy Wallace, Mitchell McLaren, Chris McCool, and S´ebastien Marcel. Cross-pollination of normalisation tech- niques from speaker to face authentication using Gaussian mixture models.Transactions on Information Forensics and Security (TIFS), 7(2), 2012. 4
work page 2012
-
[35]
Matthew D. Zeiler and Rob Fergus. Visualizing and under- standing convolutional networks. InEuropean Conference on Computer Vision (ECCV), 2014. 1
work page 2014
-
[36]
Learning deep features for discrimi- native localization
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discrimi- native localization. InConference on Computer Vision and Pattern Recognition (CVPR), 2016. 2
work page 2016
-
[37]
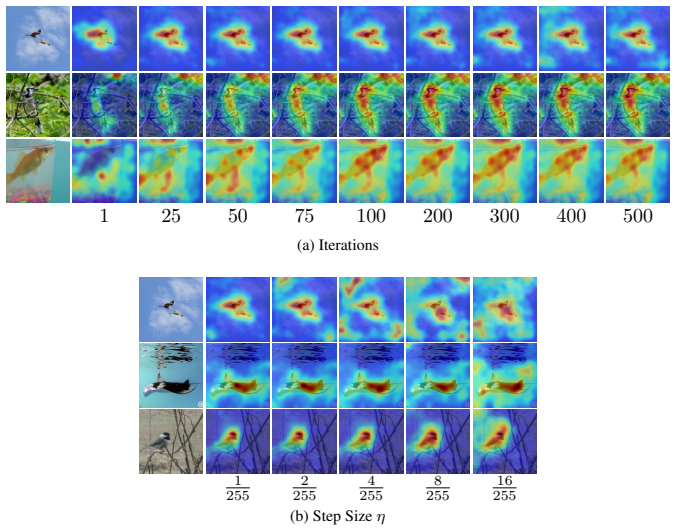
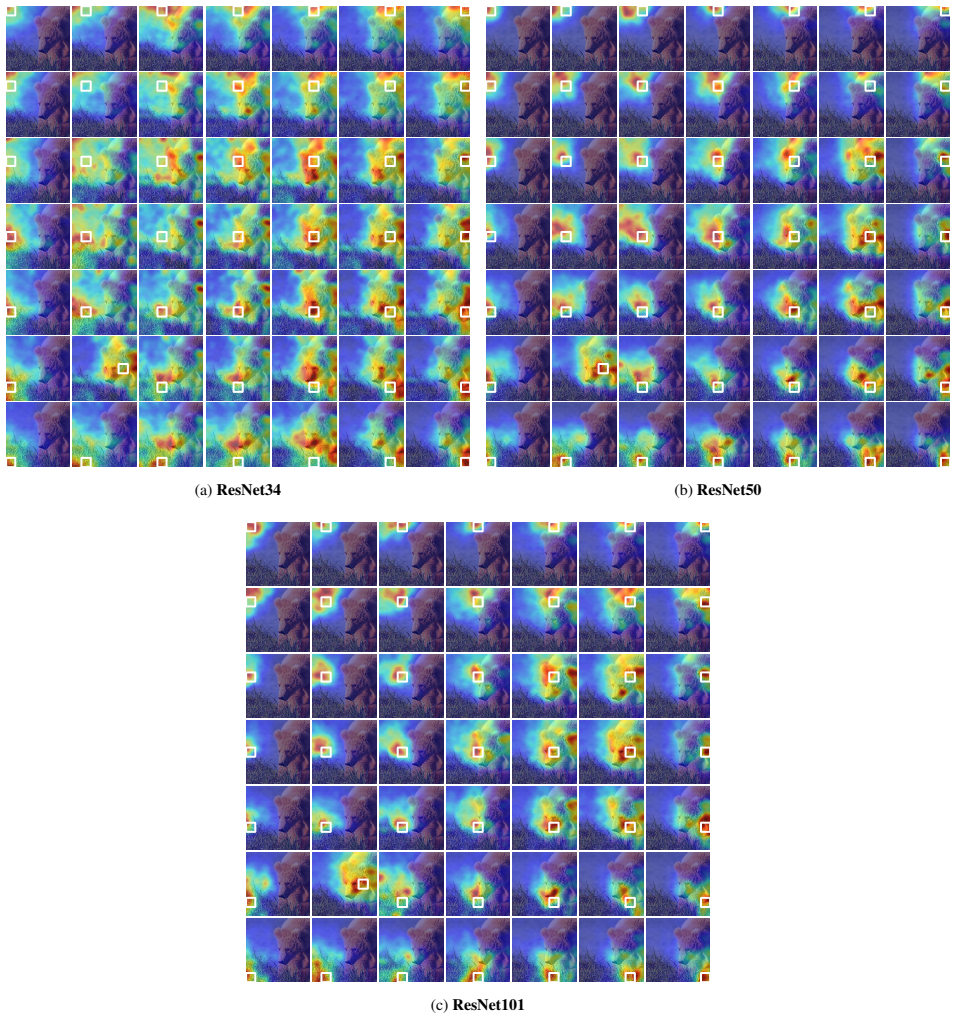
Sijie Zhu, Taojiannan Yang, and Chen Chen. Visual expla- nation for deep metric learning.Transactions on Image Pro- cessing (TIP), 30:7593–7607, 2021. 3, 4 10 Supplemental Material A. Parameter Sensitivity and Optimization This section provides additional observations on how sev- eral hyperparameters influence the runtime and stability of our visualizatio...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.