Recognition: 2 theorem links
· Lean TheoremEfficient and Adaptive Human Activity Recognition via LLM Backbones
Pith reviewed 2026-05-13 06:48 UTC · model grok-4.3
The pith
Pretrained language models can serve as efficient temporal backbones for sensor-based human activity recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
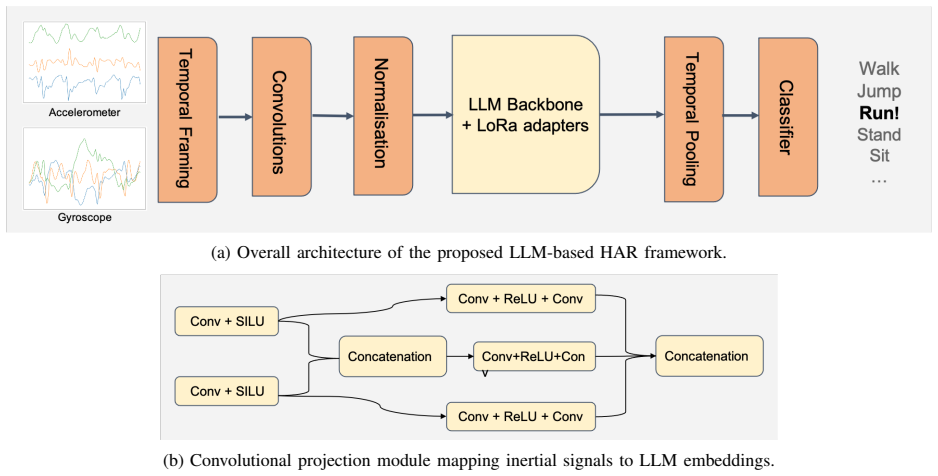
By mapping multivariate inertial sensor streams through a structured convolutional projection into the embedding space of a frozen pretrained LLM and then fine-tuning only with Low-Rank Adaptation, the resulting system achieves rapid convergence, strong accuracy in low-data regimes, and reliable transfer across standard HAR benchmarks while using far fewer trainable parameters than models built from scratch.
What carries the argument
Structured convolutional projection that maps inertial time-series signals into the latent space of a frozen pretrained language model, paired with LoRA adapters for parameter-efficient updates.
If this is right
- Training cost and data requirements drop sharply because only the projection head and LoRA adapters are updated.
- Cross-dataset transfer improves because the frozen backbone already encodes general temporal patterns learned from language.
- Local invariances in the raw signals are handled by the convolutional front-end while long-range dependencies are captured by the pretrained model.
- Few-shot and low-data scenarios become practical without sacrificing recognition performance on standard benchmarks.
Where Pith is reading between the lines
- Similar projection techniques could allow the same frozen LLM backbone to support other multivariate time-series tasks such as gesture recognition or anomaly detection in industrial sensors.
- If the alignment holds across additional sensor modalities, the approach would reduce the need to train separate foundation models for each physical sensing domain.
- Edge deployment becomes more feasible once the heavy pretrained weights are shared and only small adapters are stored per task.
Load-bearing premise
The convolutional projection must align the statistical structure of sensor time series with the pretrained language model's latent space closely enough for useful knowledge to transfer to activity labels.
What would settle it
A controlled comparison on the same low-data splits of standard HAR datasets in which the proposed system shows no accuracy or convergence advantage over a task-specific transformer trained from scratch would falsify the central claim.
Figures
read the original abstract
Human Activity Recognition (HAR) is a core task in pervasive computing systems, where models must operate under strict computational constraints while remaining robust to heterogeneous and evolving deployment conditions. Recent advances based on Transformer architectures have significantly improved recognition performance, but typically rely on task-specific models trained from scratch, resulting in high training cost, large data requirements, and limited adaptability to domain shifts. In this paper, we propose a paradigm shift that reuses large pretrained language models (LLMs) as generic temporal backbones for sensor-based HAR, instead of designing domain-specific Transformers. To bridge the modality gap between inertial time series and language models, we introduce a structured convolutional projection that maps multivariate accelerometer and gyroscope signals into the latent space of the LLM. The pretrained backbone is kept frozen and adapted using parameter-efficient Low-Rank Adaptation (LoRA), drastically reducing the number of trainable parameters and the overall training cost. Through extensive experiments on standard HAR benchmarks, we show that this approach enables rapid convergence, strong data efficiency, and robust cross-dataset transfer, particularly in low-data and few-shot settings. At the same time, our results highlight the complementary roles of convolutional frontends and LLMs, where local invariances are handled at the signal level while long-range temporal dependencies are captured by the pretrained backbone. Overall, this work demonstrates that LLMs can serve as a practical, frugal, and scalable foundation for adaptive HAR systems, opening new directions for reusing foundation models beyond their original language domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes reusing pretrained large language models (LLMs) as frozen temporal backbones for sensor-based human activity recognition (HAR). A structured convolutional projection maps multivariate inertial signals (accelerometer and gyroscope) into the LLM latent space; the backbone is then adapted via LoRA while keeping the majority of parameters frozen. The central claims are that this yields rapid convergence, strong data efficiency, robust cross-dataset transfer (especially in low-data and few-shot regimes), and that the pretrained LLM weights supply useful long-range temporal modeling beyond what the convolutional frontend alone provides.
Significance. If the results hold after addressing the ablation gap, the work would be significant for efficient adaptation of foundation models to non-language modalities. It offers a practical, low-parameter route to leverage existing LLM pretraining for time-series tasks in pervasive computing, potentially lowering training costs and improving adaptability under domain shift. The explicit separation of local signal invariances (conv frontend) from long-range dependencies (LLM) is a clean conceptual contribution that could influence future cross-modal reuse of transformers.
major comments (2)
- [Experiments] Experiments section: the central claim that pretrained LLM weights supply useful long-range modeling (beyond architecture + LoRA) is not supported by any ablation that replaces the pretrained backbone with a randomly initialized transformer of identical depth/width while keeping the convolutional projection and LoRA identical. Without this comparison, it remains possible that performance gains arise from the conv frontend plus low-rank adaptation on any frozen transformer rather than from language pretraining transfer. This is load-bearing for the paper's framing of LLMs as reusable foundations.
- [Method and Experiments] §4 (Method) and Experiments: the structured convolutional projection is presented as the key modality bridge, yet no ablation varies its kernel sizes, channel counts, or stride choices while holding the LLM fixed. The free parameters listed in the axiom ledger (LoRA rank, conv kernel sizes) are therefore not isolated, weakening the claim that the projection reliably maps inertial signals into a space where pretrained knowledge transfers.
minor comments (2)
- [Abstract] Abstract: no quantitative metrics, dataset names, or error bars are reported despite the strong claims of 'rapid convergence' and 'strong data efficiency.' Adding one or two headline numbers would improve immediate readability.
- [Implementation details] The paper should explicitly state the exact LLM backbones tested (e.g., Llama-7B, GPT-2) and the precise LoRA configuration (rank, alpha, target modules) in a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that both major comments identify important gaps in the experimental validation of our central claims. We will revise the manuscript to include the requested ablations, which will strengthen the evidence that pretrained LLM weights contribute beyond architecture and LoRA alone, and that the convolutional projection is robustly designed.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that pretrained LLM weights supply useful long-range modeling (beyond architecture + LoRA) is not supported by any ablation that replaces the pretrained backbone with a randomly initialized transformer of identical depth/width while keeping the convolutional projection and LoRA identical. Without this comparison, it remains possible that performance gains arise from the conv frontend plus low-rank adaptation on any frozen transformer rather than from language pretraining transfer. This is load-bearing for the paper's framing of LLMs as reusable foundations.
Authors: We agree that this ablation is essential to isolate the contribution of language pretraining. In the revised manuscript we will add a direct comparison replacing the pretrained LLM backbone with a randomly initialized transformer of identical depth and width, while keeping the convolutional projection and LoRA configuration unchanged. This will clarify whether performance gains derive specifically from the pretrained weights rather than from the overall architecture plus adaptation. revision: yes
-
Referee: [Method and Experiments] §4 (Method) and Experiments: the structured convolutional projection is presented as the key modality bridge, yet no ablation varies its kernel sizes, channel counts, or stride choices while holding the LLM fixed. The free parameters listed in the axiom ledger (LoRA rank, conv kernel sizes) are therefore not isolated, weakening the claim that the projection reliably maps inertial signals into a space where pretrained knowledge transfers.
Authors: We concur that systematic variation of the convolutional projection hyperparameters is needed to validate its design choices. In the revision we will report ablations that vary kernel sizes, channel counts, and strides while holding the LLM backbone fixed. These results will demonstrate the sensitivity (or robustness) of the chosen projection and better support the claim that it serves as an effective modality bridge. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks and pretrained weights
full rationale
The paper advances an empirical architecture (structured conv projection + frozen LLM backbone + LoRA) whose performance claims are validated through experiments on standard HAR datasets rather than any closed mathematical derivation. No load-bearing step equates a fitted quantity to a prediction by construction, invokes a self-citation as an unverified uniqueness theorem, or renames an input as an output. The method reuses externally pretrained LLM weights and standard adaptation techniques; the central results (data efficiency, cross-dataset transfer) are measured against held-out benchmarks and therefore remain falsifiable outside the paper's own fitting procedure.
Axiom & Free-Parameter Ledger
free parameters (2)
- LoRA rank and scaling
- Convolutional projection kernel sizes and channels
axioms (2)
- domain assumption Pretrained transformer weights contain useful long-range temporal structure that can be reused for non-language sequences
- domain assumption A convolutional front-end can map raw multivariate sensor streams into the token embedding space of an LLM without destroying task-relevant information
Lean theorems connected to this paper
-
Foundation.AlexanderDualityalexander_duality_circle_linking unclearlong-range temporal dependencies are captured by the pretrained backbone
Reference graph
Works this paper leans on
-
[1]
A survey on using domain and contextual knowledge for human activity recognition in video streams,
L. Onofri, P. Soda, M. Pechenizkiy, and G. Iannello, “A survey on using domain and contextual knowledge for human activity recognition in video streams,” Expert Systems with Applications, vol. 63, pp. 97–111, 2016
work page 2016
-
[2]
Deep learning for sensor-based activity recognition: A survey,
J. Wang, Y . Chen, S. Hao, X. Peng, and L. Hu, “Deep learning for sensor-based activity recognition: A survey,” Pattern recognition letters, vol. 119, pp. 3–11, 2019
work page 2019
-
[3]
Real-time human activity recognition from accelerometer data using convolutional neural networks,
A. Ignatov, “Real-time human activity recognition from accelerometer data using convolutional neural networks,” Applied Soft Computing, vol. 62, 2018
work page 2018
-
[4]
F. J. Ord ´o˜nez and D. Roggen, “Deep convolutional and lstm recur- rent neural networks for multimodal wearable activity recognition,” in Sensors, 2016
work page 2016
-
[5]
Deep, convolutional, and recurrent models for human activity recognition using wearables,
N. Y . Hammerla, S. Halloran, and T. Pl ¨otz, “Deep, convolutional, and recurrent models for human activity recognition using wearables,” in IJCAI, 2016
work page 2016
-
[6]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
work page 1997
-
[7]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[8]
Transformer-based human activity recogni- tion,
I. e. a. Dirgov ´a Lupt´akov´a, “Transformer-based human activity recogni- tion,” Sensors, 2021
work page 2021
-
[9]
Y . Zhang, L. Wang, H. Chen, A. Tian, S. Zhou, and Y . Guo, “If- convtransformer: A framework for human activity recognition using imu fusion and convtransformer,” Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 6, no. 2, 2022
work page 2022
-
[10]
Transformer-based models to deal with heterogeneous environments in human activity recognition,
S. Ek, F. Portet, and P. Lalanda, “Transformer-based models to deal with heterogeneous environments in human activity recognition,” Personal and Ubiquitous Computing, 2023
work page 2023
-
[11]
Comparing self-supervised learning techniques for wearable human activity recognition,
S. Ek, R. Presotto, G. Civitarese, F. Portet, P. Lalanda, and C. Bettini, “Comparing self-supervised learning techniques for wearable human activity recognition,” arXiv preprint arXiv:2404.15331, 2024
-
[12]
Large language models for time series: A survey,
X. Zhang, R. R. Chowdhury, R. K. Gupta, and J. Shang, “Large language models for time series: A survey,” 2024. [Online]. Available: https://arxiv.org/abs/2402.01801
-
[13]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI Blog, 2019
work page 2019
-
[14]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar et al., “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Parameter-efficient transfer learning for NLP,
N. Houlsby, A. Giurgiu, S. Jastrzkebski, B. Morrone, Q. de Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” in International Conference on Machine Learning. PMLR, 2019, pp. 2790–2799
work page 2019
-
[17]
Prefix-tuning: Optimizing continuous prompts for generation,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers), 2021, pp. 4582–4597
work page 2021
-
[18]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 3045–3059
work page 2021
-
[19]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Combining public human activity recognition datasets to mitigate labeled data scarcity,
R. Presotto, S. Ek, G. Civitarese, F. Portet, P. Lalanda, and C. Bettini, “Combining public human activity recognition datasets to mitigate labeled data scarcity,” in 2023 IEEE International Conference on Smart Computing (SMARTCOMP), 2023, pp. 33–40
work page 2023
-
[21]
A. Stisen, H. Blunck, S. Bhattacharya, T. S. Prentow, M. B. Kjærgaard, A. Dey, T. Sonne, and M. M. Jensen, “Smart devices are different: Assessing and mitigatingmobile sensing heterogeneities for activity recognition,” in Proceedings of the 13th ACM conference on embedded networked sensor systems, 2015, pp. 127–140
work page 2015
-
[22]
A public domain dataset for human activity recognition using smartphones,
D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. L. Reyes-Ortiz, “A public domain dataset for human activity recognition using smartphones,” in 21st European Symposium on Artificial Neural Networks, ESANN 2013, Bruges, Belgium, April 24-26, 2013, 2013
work page 2013
-
[23]
On-body localization of wearable devices: An investigation of position-aware activity recognition,
T. Sztyler and H. Stuckenschmidt, “On-body localization of wearable devices: An investigation of position-aware activity recognition,” in 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), 2016, pp. 1–9
work page 2016
-
[24]
Real-time human activity recognition from accelerometer data using convolutional neural networks,
A. D. Ignatov, “Real-time human activity recognition from accelerometer data using convolutional neural networks,” Appl. Soft Comput., 2018
work page 2018
-
[25]
Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition,
F. J. Ord ´o˜nez and D. Roggen, “Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition,” Sensors, vol. 16, no. 1, p. 115, 2016
work page 2016
-
[26]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.