Recognition: 2 theorem links
· Lean TheoremResilient Vision-Tabular Multimodal Learning under Modality Missingness
Pith reviewed 2026-05-13 06:30 UTC · model grok-4.3
The pith
A transformer framework fuses vision and tabular medical data under pervasive modality missingness without imputation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
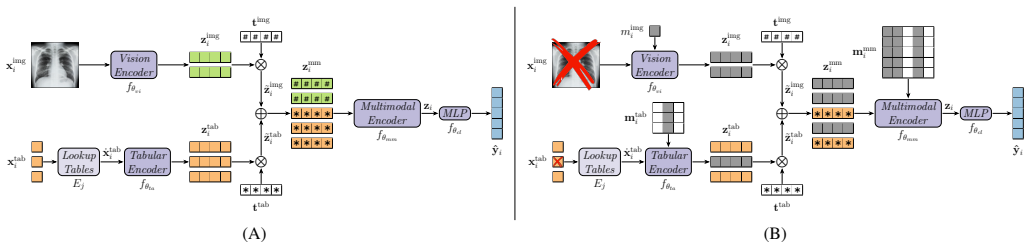
The paper claims that by weighting unimodal representations with learnable modality tokens and performing intermediate fusion through masked self-attention that ignores missing tokens, combined with stochastic removal of available modalities in training, the model achieves resilient joint learning. This results in smoother performance degradation and superior accuracy in multilabel classification of 14 findings on the MIMIC-CXR and MIMIC-IV datasets under systematic increases in missingness during both training and inference.
What carries the argument
The masked self-attention mechanism within the multimodal fusion encoder, which excludes missing modality tokens from information aggregation and backpropagation, augmented by learnable modality tokens and a modality-dropout regularization strategy.
If this is right
- The approach supports training and inference across the full spectrum from complete multimodal to single-modality inputs without model switching.
- Attention masking and intermediate fusion with joint fine-tuning prove essential for maintaining performance under missing data.
- Performance degrades more gradually with increasing missingness compared to representative baselines.
- Modality dropout encourages exploitation of complementary information from partial inputs.
Where Pith is reading between the lines
- This design may generalize to other pairs of modalities beyond vision and tabular data in clinical settings.
- Clinics could deploy such models directly on existing incomplete records without additional preprocessing steps for missing values.
- Testing on datasets with real-world missingness patterns rather than synthetic ones would further validate the robustness.
- Extending the masking to handle partially missing features within a modality could broaden applicability.
Load-bearing premise
The masked self-attention and modality dropout will enable the model to extract and combine useful signals from whichever modalities remain available without needing complete data or separate unimodal models.
What would settle it
Observing that the proposed model's accuracy falls below a simple unimodal baseline when one entire modality is missing at test time on the same dataset would falsify the resilience advantage.
Figures



read the original abstract
Multimodal deep learning has shown strong potential in medical applications by integrating heterogeneous data sources such as medical images and structured clinical variables. However, most existing approaches implicitly assume complete modality availability, an assumption that rarely holds in real-world clinical settings where entire modalities and individual features are frequently missing. In this work, we propose a multimodal transformer framework for joint vision-tabular learning explicitly designed to operate under pervasive modality missingness, without relying on imputation or heuristic model switching. The architecture integrates three components: a vision, a tabular, and a multimodal fusion encoder. Unimodal representations are weighted through learnable modality tokens and fused via intermediate fusion with masked self-attention, which excludes missing tokens and modalities from information aggregation and gradient propagation. To further enhance resilience, we introduce a modality-dropout regularization strategy that stochastically removes available modalities during training, encouraging the model to exploit complementary information under partial data availability. We evaluate our approach on the MIMIC-CXR dataset paired with structured clinical data from MIMIC-IV for multilabel classification of 14 diagnostic findings with incomplete annotations. Two parallel systematic stress-test protocols progressively increase training and inference missingness in each modality separately, spanning fully multimodal to fully unimodal scenarios. Across all missingness regimes, the proposed method consistently outperforms representative baselines, showing smoother performance degradation and improved robustness. Ablation studies further demonstrate that attention-level masking and intermediate fusion with joint fine-tuning are key to resilient multimodal inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multimodal transformer for vision-tabular learning under modality missingness, using learnable modality tokens to weight unimodal encoders, intermediate fusion via masked self-attention that excludes missing tokens from aggregation and gradients, and modality-dropout regularization during training. It is evaluated on MIMIC-CXR images paired with MIMIC-IV tabular data for 14-label multilabel classification, employing two systematic stress-test protocols that progressively increase missingness separately in each modality from fully multimodal to fully unimodal settings. The central claim is consistent outperformance over baselines with smoother degradation curves, supported by ablations highlighting the role of masking and joint fine-tuning.
Significance. If the empirical results hold with full verification, the work would meaningfully advance robust multimodal medical AI by providing a unified architecture that exploits partial complementary information without imputation or model switching. The systematic stress-test protocols and explicit ablations on fusion components are strengths that allow direct assessment of resilience claims.
major comments (2)
- [Experiments] Experiments section: The abstract asserts 'consistent outperformance' and 'smoother performance degradation' across regimes, but the provided text lacks specific quantitative results (e.g., AUC/F1 values at each missingness percentage), baseline implementations, run-to-run variance, or statistical significance tests. These details are load-bearing for the central robustness claim and must be supplied with tables or figures.
- [Method] Method, modality-dropout paragraph: The regularization is described as stochastically removing available modalities, yet it is unclear how the dropout probability is selected or scheduled relative to the training missingness distribution; without this, it is difficult to rule out that gains arise from implicit adaptation to the evaluation protocol rather than true complementary exploitation.
minor comments (2)
- [Abstract] Abstract: The description of the two stress-test protocols could explicitly state the range of missingness fractions tested (e.g., 0-100% in 20% steps) and whether missingness is applied at the sample or feature level.
- [Method] Notation: The distinction between 'modality tokens' and standard class tokens should be clarified in the architecture diagram or equations to avoid reader confusion.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We appreciate the positive assessment of the significance of our work and the constructive suggestions for improvement. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract asserts 'consistent outperformance' and 'smoother performance degradation' across regimes, but the provided text lacks specific quantitative results (e.g., AUC/F1 values at each missingness percentage), baseline implementations, run-to-run variance, or statistical significance tests. These details are load-bearing for the central robustness claim and must be supplied with tables or figures.
Authors: We fully agree that the Experiments section requires more detailed quantitative support for our claims of consistent outperformance and smoother degradation. In the revised manuscript, we will add tables presenting the AUC and F1 scores for the proposed method and all baselines at incremental missingness levels for both vision and tabular modalities. Additionally, we will report standard deviations across multiple runs and include statistical significance testing to validate the improvements. Details on baseline implementations, including any adaptations for missingness, will be provided in the main text or supplementary material. These additions will make the robustness claims verifiable and strengthen the paper. revision: yes
-
Referee: [Method] Method, modality-dropout paragraph: The regularization is described as stochastically removing available modalities, yet it is unclear how the dropout probability is selected or scheduled relative to the training missingness distribution; without this, it is difficult to rule out that gains arise from implicit adaptation to the evaluation protocol rather than true complementary exploitation.
Authors: We acknowledge that the description of the modality-dropout regularization lacks specifics on probability selection and scheduling. In the revision, we will expand this paragraph to explain that the dropout probability is determined via cross-validation on a held-out validation set, chosen to maximize average performance across a range of simulated missingness levels rather than matching the test distribution exactly. We will also include an ablation study showing performance for different dropout rates to demonstrate that the benefits stem from encouraging the model to learn complementary features. This will address concerns about potential adaptation to the evaluation protocol. revision: yes
Circularity Check
No significant circularity; architecture and evaluation defined independently
full rationale
The paper defines its multimodal transformer with learnable modality tokens, intermediate fusion via masked self-attention (explicitly excluding missing tokens from aggregation and gradients), and modality-dropout regularization as explicit design choices. These components are introduced without equations that reduce claimed robustness or outperformance to quantities fitted on the evaluation missingness patterns. The two stress-test protocols on MIMIC-CXR/MIMIC-IV are described as separate progressive sweeps, and no self-citation chain or ansatz is invoked to force the central result. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable modality tokens
axioms (1)
- domain assumption Transformer self-attention can be masked to exclude missing tokens without breaking gradient flow or representation quality
invented entities (1)
-
modality tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearmasked self-attention, which excludes missing tokens and modalities from information aggregation and gradient propagation... modality-dropout regularization strategy that stochastically removes available modalities during training
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearintermediate fusion with masked self-attention... Jcost not mentioned; no recognition cost, phi-ladder, or 8-tick structure
Reference graph
Works this paper leans on
-
[1]
A systematic review of intermediate fusion in multimodal deep learning for biomedical applications,
V . Guarrasi, F. Aksu, C. M. Caruso, F. Di Feola, A. Ro- fena, F. Ruffini, and P. Soda, “A systematic review of intermediate fusion in multimodal deep learning for biomedical applications,”Image and Vision Computing, p. 105509, 2025
work page 2025
-
[2]
Multimodal artificial intelligence in medical diagnostics,
B. Jandoubi and M. A. Akhloufi, “Multimodal artificial intelligence in medical diagnostics,”Information, vol. 16, no. 7, p. 591, 2025
work page 2025
-
[3]
Multi- modal machine learning: A survey and taxonomy,
T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multi- modal machine learning: A survey and taxonomy,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018
work page 2018
-
[4]
D. Schouten, G. Nicoletti, B. Dille, C. Chia, P. Vendittelli, M. Schuurmans, G. Litjens, and N. Khalili, “Navigating the landscape of multimodal AI in medicine: a scoping review on technical challenges and clinical applications,” Medical Image Analysis, p. 103621, 2025
work page 2025
-
[5]
Deep multimodal learning with missing modality: A survey,
R. Wu, H. Wang, H.-T. Chen, and G. Carneiro, “Deep multimodal learning with missing modality: A survey,” arXiv preprint arXiv:2409.07825, 2024
-
[6]
Training strategies to handle missing modalities for audio-visual expression recognition,
S. Parthasarathy and S. Sundaram, “Training strategies to handle missing modalities for audio-visual expression recognition,” inCompanion Publication of the 2020 Inter- national Conference on Multimodal Interaction, 2020, pp. 400–404
work page 2020
-
[7]
T. Zhou, S. Canu, P. Vera, and S. Ruan, “Latent correla- tion representation learning for brain tumor segmentation with missing MRI modalities,”IEEE Transactions on Im- age Processing, vol. 30, pp. 4263–4274, 2021
work page 2021
-
[8]
COM: Contrastive Masked- attention model for incomplete multimodal learning,
S. Qian and C. Wang, “COM: Contrastive Masked- attention model for incomplete multimodal learning,” Neural Networks, vol. 162, pp. 443–455, 2023
work page 2023
-
[9]
Knowledge distillation from multi-modal to mono-modal segmentation networks,
M. Hu, M. Maillard, Y . Zhang, T. Ciceri, G. La Bar- bera, I. Bloch, and P. Gori, “Knowledge distillation from multi-modal to mono-modal segmentation networks,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2020, pp. 772–781
work page 2020
-
[10]
TIP: Tabular-Image Pre-training for Multimodal Classification with Incomplete Data,
S. Du, S. Zheng, Y . Wang, W. Bai, D. P. O’Regan, and C. Qin, “TIP: Tabular-Image Pre-training for Multimodal Classification with Incomplete Data,” inComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XV. Springer-Verlag, 2024, p. 478–496. [Online]. Available: https://doi.org/10.1007/978-3-...
-
[11]
Tabular insights, visual impacts: transferring expertise from tables to images,
J.-P. Jiang, H.-J. Ye, L. Wang, Y . Yang, Y . Jiang, and D.- C. Zhan, “Tabular insights, visual impacts: transferring expertise from tables to images,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
work page 2024
-
[12]
A. Khaled, M. Sabir, R. Qureshi, C. M. Caruso, V . Guar- rasi, S. Xiang, and S. K. Zhou, “Leveraging mimic datasets for better digital health: A review on open prob- lems, progress highlights, and future promises,”arXiv preprint arXiv:2506.12808, 2025
-
[13]
A. E. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-y. Deng, R. G. Mark, and S. Horng, “MIMIC-CXR, a de-identified publicly avail- able database of chest radiographs with free-text reports,” Scientific data, vol. 6, no. 1, p. 317, 2019
work page 2019
-
[14]
MIMIC-IV , a freely accessible electronic health record dataset,
A. E. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Shammout, S. Horng, T. J. Pollard, S. Hao, B. Moody, B. Gowet al., “MIMIC-IV , a freely accessible electronic health record dataset,”Scientific data, vol. 10, no. 1, p. 1, 2023
work page 2023
-
[15]
On the stratification of multi-label data,
K. Sechidis, G. Tsoumakas, and I. Vlahavas, “On the stratification of multi-label data,” inJoint European con- ference on machine learning and knowledge discovery in databases. Springer, 2011, pp. 145–158
work page 2011
-
[16]
Prediction of in- tensive care unit length of stay in the MIMIC-IV dataset,
L. Hempel, S. Sadeghi, and T. Kirsten, “Prediction of in- tensive care unit length of stay in the MIMIC-IV dataset,” Applied Sciences, vol. 13, no. 12, p. 6930, 2023. 14 Appendix A. Dataset Preparation Details We use a multimodal dataset obtained by pairing chest X-Rays from the MIMIC-CXR repository with structured clinical infor- mation from MIMIC-IV . T...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.