Recognition: 1 theorem link
· Lean TheoremOmniRefine: Alignment-Aware Cooperative Compression for Efficient Omnimodal Large Language Models
Pith reviewed 2026-05-13 04:46 UTC · model grok-4.3
The pith
OmniRefine refines audio-video chunk boundaries for alignment then jointly compresses tokens to cut inference cost while holding performance near full levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
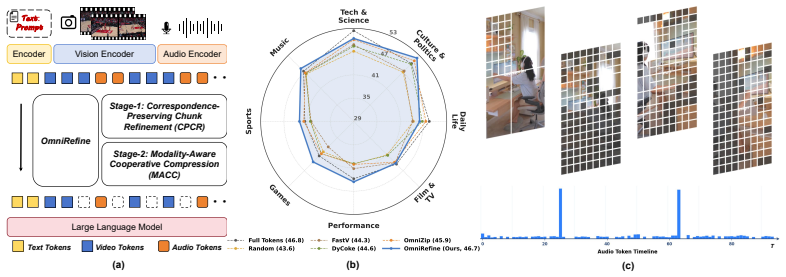
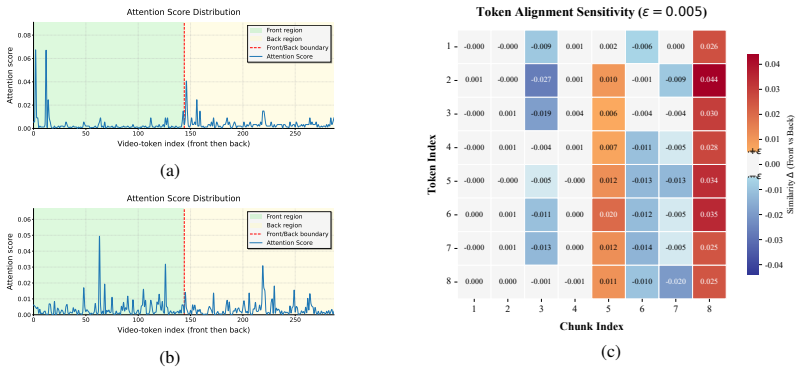
OmniRefine is a training-free two-stage framework for audio-visual token compression in Omni-LLMs. Correspondence-Preserving Chunk Refinement first converts native chunk boundaries into cross-modally aligned compression units by measuring frame-audio similarity and applying dynamic programming. Modality-Aware Cooperative Compression then jointly reduces redundancy in video and audio tokens inside each refined unit while keeping critical evidence intact.
What carries the argument
Correspondence-Preserving Chunk Refinement followed by Modality-Aware Cooperative Compression, which together produce aligned units that keep complementary audio-video information available during joint token reduction.
If this is right
- The method delivers a better efficiency-performance trade-off than baselines that use fixed or native compression units.
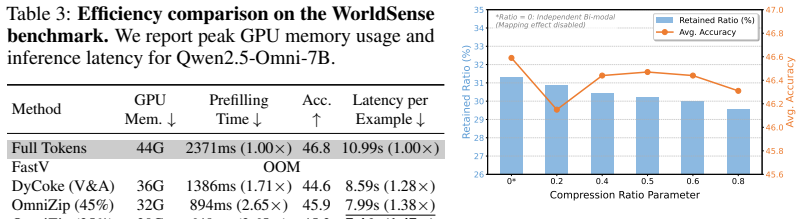
- Performance stays stable even when token retention drops to 44 percent.
- On WorldSense the approach reaches 46.7 percent accuracy at 44 percent retention, nearly matching the full-token baseline.
- Longer video streams and denser audio sequences become feasible at lower inference cost.
Where Pith is reading between the lines
- The same boundary-refinement idea could extend to other paired modalities such as text and images where misalignment also hurts compression.
- Lower token counts may enable real-time omnimodal applications on devices with limited memory or power.
- Preserving alignment during compression reduces the chance that downstream reasoning steps lose synchronization between sound and visuals.
Load-bearing premise
Refining native chunk boundaries with frame-audio similarity and dynamic programming will create compression units that keep the complementary cross-modal information required for audio-video reasoning intact.
What would settle it
A controlled test at 44 percent token retention on WorldSense showing that accuracy with the refined aligned units falls more than a few points below the accuracy obtained with native unrefined chunks at the same retention rate.
Figures


read the original abstract
Omnimodal large language models (Omni-LLMs) show strong capability in audio-video understanding, but their practical deployment remains limited by high inference cost of long video streams and dense audio sequences. Despite recent progress, existing compression methods for Omni-LLMs typically rely on fixed or native compression units, which can disrupt cross-modal correspondence and the complementary information required for audio-video reasoning, making it difficult to improve inference efficiency while stably preserving performance. To address this, we propose OmniRefine, a training-free two-stage framework for efficient audio-visual token compression in Omni-LLMs. First, Correspondence-Preserving Chunk Refinement refines native chunk boundaries into cross-modally aligned compression units through frame-audio similarity and dynamic programming. Second, Modality-Aware Cooperative Compression jointly compresses video and audio tokens within each refined unit to reduce redundancy while preserving critical evidence. Extensive experiments show that OmniRefine achieves a better efficiency-performance trade-off than strong baselines and maintains stable performance under lower compression ratios. On WorldSense, it still reaches 46.7% accuracy at a 44% token retention ratio, nearly matching the full-token baseline. The code and interface will be released to facilitate further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniRefine, a training-free two-stage framework for token compression in omnimodal LLMs. Stage 1 (Correspondence-Preserving Chunk Refinement) uses frame-audio similarity and dynamic programming to adjust native chunk boundaries for better cross-modal alignment. Stage 2 (Modality-Aware Cooperative Compression) then jointly compresses video and audio tokens within each refined unit to reduce redundancy. The central empirical claim is that this yields a superior efficiency-performance trade-off versus baselines, with stable results under aggressive compression (e.g., 46.7% accuracy on WorldSense at 44% token retention, nearly matching the full-token baseline).
Significance. If the results hold after proper isolation of components, the work would be moderately significant for practical deployment of omnimodal models, as it targets a real deployment bottleneck (cross-modal misalignment during compression) with a training-free method. The emphasis on preserving complementary audio-video evidence and the promise of code release are positive for reproducibility.
major comments (2)
- §4 (Experiments) and §4.2 (Ablation Studies): No ablation isolates the contribution of Correspondence-Preserving Chunk Refinement. The WorldSense result (46.7% at 44% retention) is reported only for the full pipeline; there is no direct comparison against modality-aware cooperative compression applied to native (unrefined) chunks. This leaves the load-bearing assumption—that frame-audio similarity + DP produces units preserving complementary cross-modal information—untested, so the performance gain cannot be confidently attributed to the alignment step rather than the second stage alone.
- §4.1 (Experimental Setup): The manuscript supplies the headline WorldSense number but provides insufficient detail on exact baseline implementations, the precise definition and computation of frame-audio similarity, the dynamic programming objective function and constraints, number of runs, and any statistical tests for the reported superiority. This weakens the ability to evaluate the efficiency-performance trade-off claims.
minor comments (2)
- §3.1: The dynamic programming recurrence for boundary refinement would benefit from an explicit small-scale example or pseudocode to clarify how similarity scores translate into the final chunk boundaries.
- Figure 3 / Table 2: Axis labels and legend entries for compression ratios and accuracy could be made more consistent across panels to improve readability of the efficiency curves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: §4 (Experiments) and §4.2 (Ablation Studies): No ablation isolates the contribution of Correspondence-Preserving Chunk Refinement. The WorldSense result (46.7% at 44% retention) is reported only for the full pipeline; there is no direct comparison against modality-aware cooperative compression applied to native (unrefined) chunks. This leaves the load-bearing assumption—that frame-audio similarity + DP produces units preserving complementary cross-modal information—untested, so the performance gain cannot be confidently attributed to the alignment step rather than the second stage alone.
Authors: We agree that an explicit ablation isolating the Correspondence-Preserving Chunk Refinement stage is needed to strengthen attribution of gains. The current results show the full pipeline's performance, but we will add a new ablation in the revised §4.2 comparing Modality-Aware Cooperative Compression applied to native chunks versus the refined chunks on WorldSense (and other benchmarks). This will directly test whether the alignment-aware refinement preserves complementary cross-modal information beyond what the second stage achieves alone. We expect the refined units to yield higher accuracy at the same retention ratio, consistent with the paper's motivation that native chunks can disrupt audio-video correspondence. revision: yes
-
Referee: §4.1 (Experimental Setup): The manuscript supplies the headline WorldSense number but provides insufficient detail on exact baseline implementations, the precise definition and computation of frame-audio similarity, the dynamic programming objective function and constraints, number of runs, and any statistical tests for the reported superiority. This weakens the ability to evaluate the efficiency-performance trade-off claims.
Authors: We agree more implementation details are required for reproducibility. In the revised §4.1 we will add: exact baseline reimplementations (using the same Omni-LLM backbone and matching the original papers' token selection logic at equivalent ratios); frame-audio similarity defined as average cosine similarity between video frame embeddings and corresponding audio segment embeddings extracted from the model's encoders; the DP objective as maximizing the cumulative alignment score (sum of per-chunk similarities) subject to constraints of minimum one frame and one audio segment per refined chunk plus upper bounds on chunk duration to control compute; all results averaged over 3 random seeds with standard deviation reported; and paired t-tests confirming statistical significance (p < 0.05) versus baselines on WorldSense. These additions will allow readers to fully evaluate the trade-off claims. revision: yes
Circularity Check
No circularity in algorithmic derivation or claims
full rationale
The paper describes a training-free two-stage algorithmic procedure (Correspondence-Preserving Chunk Refinement via frame-audio similarity and dynamic programming, followed by Modality-Aware Cooperative Compression) evaluated directly on external benchmarks such as WorldSense. No equations, fitted parameters presented as predictions, self-definitional quantities, or load-bearing self-citations appear in the provided text that would reduce the reported performance retention (e.g., 46.7% at 44% retention) to an input by construction. The central claims rest on empirical results from independent datasets rather than any internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Inclusion AI, Biao Gong, Cheng Zou, Chuanyang Zheng, Chunluan Zhou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong Wang, et al. Ming-omni: A unified multimodal model for perception and generation.arXiv preprint arXiv:2506.09344, 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[5]
Xueyi Chen, Keda Tao, Kele Shao, and Huan Wang. Streamingtom: Streaming token compres- sion for efficient video understanding.arXiv preprint arXiv:2510.18269, 2025
-
[6]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[7]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[10]
Yuchen Deng, Xiuyang Wu, Hai-Tao Zheng, Jie Wang, Feidiao Yang, and Yuxing Han. Beyond boundary frames: Audio-visual semantic guidance for context-aware video interpolation.arXiv preprint arXiv:2512.03590, 2025
-
[11]
Yuchen Deng, Xiuyang Wu, Hai-Tao Zheng, Suiyang Zhang, Yi He, and Yuxing Han. Avatarsync: Rethinking talking-head animation through autoregressive perspective.arXiv e-prints, pages arXiv–2509, 2025
work page 2025
-
[12]
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, et al. Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models.arXiv preprint arXiv:2602.04804, 2026
work page internal anchor Pith review arXiv 2026
-
[13]
Vita: Towards open-source interactive omni multimodal llm
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Yuhang Dai, Meng Zhao, Yi-Fan Zhang, Shaoqi Dong, Yangze Li, Xiong Wang, et al. Vita: Towards open-source interactive omni multimodal llm.arXiv preprint arXiv:2408.05211, 2024
-
[14]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[15]
Tianyu Fu, Tengxuan Liu, Qinghao Han, Guohao Dai, Shengen Yan, Huazhong Yang, Xuefei Ning, and Yu Wang. Framefusion: Combining similarity and importance for video token reduction on large vision language models.arXiv preprint arXiv:2501.01986, 2024. 10
-
[16]
Yuying Ge, Yixiao Ge, Chen Li, Teng Wang, Junfu Pu, Yizhuo Li, Lu Qiu, Jin Ma, Lisheng Duan, Xinyu Zuo, et al. Arc-hunyuan-video-7b: Structured video comprehension of real-world shorts.arXiv preprint arXiv:2507.20939, 2025
-
[17]
Chao Gong, Depeng Wang, Zhipeng Wei, Ya Guo, Huijia Zhu, and Jingjing Chen. Echoing- pixels: Cross-modal adaptive token reduction for efficient audio-visual llms.arXiv preprint arXiv:2512.10324, 2025
-
[18]
arXiv preprint arXiv:2502.04326 (2025)
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluat- ing real-world omnimodal understanding for multimodal llms.arXiv preprint arXiv:2502.04326, 2025
-
[19]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19959–19973, 2025
work page 2025
-
[20]
Multi-granular spatio-temporal token merging for training-free acceleration of video llms
Jeongseok Hyun, Sukjun Hwang, Su Ho Han, Taeoh Kim, Inwoong Lee, Dongyoon Wee, Joon- Young Lee, Seon Joo Kim, and Minho Shim. Multi-granular spatio-temporal token merging for training-free acceleration of video llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23990–24000, 2025
work page 2025
-
[21]
Zhonghua Jiang, Kui Chen, Kunxi Li, Keting Yin, Yiyun Zhou, Zhaode Wang, Chengfei Lv, and Shengyu Zhang. Acckv: Towards efficient audio-video llms inference via adaptive-focusing and cross-calibration kv cache optimization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 5494–5502, 2026
work page 2026
-
[22]
Chaeyoung Jung, Youngjoon Jang, Seungwoo Lee, and Joon Son Chung. Fastav: Efficient token pruning for audio-visual large language model inference.arXiv preprint arXiv:2601.13143, 2026
-
[23]
Taehan Lee and Hyukjun Lee. Token pruning in audio transformers: Optimizing performance and decoding patch importance.arXiv preprint arXiv:2504.01690, 2025
-
[24]
Bingzhou Li and Tao Huang. Dash: Dynamic audio-driven semantic chunking for efficient omnimodal token compression.arXiv preprint arXiv:2603.15685, 2026
-
[25]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[27]
Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025
work page 2025
-
[28]
Baichuan-omni technical report.arXiv preprint arXiv:2410.08565, 2024
Yadong Li, Haoze Sun, Mingan Lin, Tianpeng Li, Guosheng Dong, Tao Zhang, Bowen Ding, Wei Song, Zhenglin Cheng, Yuqi Huo, et al. Baichuan-omni technical report.arXiv preprint arXiv:2410.08565, 2024
-
[29]
Accelerating transducers through adjacent token merging.arXiv preprint arXiv:2306.16009, 2023
Yuang Li, Yu Wu, Jinyu Li, and Shujie Liu. Accelerating transducers through adjacent token merging.arXiv preprint arXiv:2306.16009, 2023
-
[30]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 5971–5984, 2024
work page 2024
-
[31]
Speechprune: Context-aware token pruning for speech information retrieval
Yueqian Lin, Yuzhe Fu, Jingyang Zhang, Yudong Liu, Jianyi Zhang, Jingwei Sun, Hai Helen Li, and Yiran Chen. Speechprune: Context-aware token pruning for speech information retrieval. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025. 11
work page 2025
-
[32]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[33]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024
work page 2024
-
[34]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision.Advances in Neural Information Processing Systems, 37:68658–68685, 2024
work page 2024
-
[36]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
work page 2025
-
[37]
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models.arXiv preprint arXiv:2505.21334, 2025
-
[38]
arXiv preprint arXiv:2507.20198 , year=
Kele Shao, Keda Tao, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. When tokens talk too much: A survey of multimodal long- context token compression across images, videos, and audios.arXiv preprint arXiv:2507.20198, 2025
-
[39]
arXiv preprint arXiv:2503.11187 (2025)
Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Pengzhang Liu, Sicheng Zhao, and Guiguang Ding. Fastvid: Dynamic density pruning for fast video large language models. arXiv preprint arXiv:2503.11187, 2025
-
[40]
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
-
[41]
Audio-visual llm for video understanding
Fangxun Shu, Lei Zhang, Hao Jiang, and Cihang Xie. Audio-visual llm for video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4246– 4255, 2025
work page 2025
-
[42]
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, and Chao Zhang. video-salmonn: Speech-enhanced audio-visual large language models.arXiv preprint arXiv:2406.15704, 2024
-
[43]
Xudong Tan, Peng Ye, Chongjun Tu, Jianjian Cao, Yaoxin Yang, Lin Zhang, Dongzhan Zhou, and Tao Chen. Tokencarve: Information-preserving visual token compression in multimodal large language models.arXiv preprint arXiv:2503.10501, 2025
-
[44]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18992–19001, 2025
work page 2025
-
[45]
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Huan Wang, et al. Omnizip: Audio- guided dynamic token compression for fast omnimodal large language models.arXiv preprint arXiv:2511.14582, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Wenwen Tong, Hewei Guo, Dongchuan Ran, Jiangnan Chen, Jiefan Lu, Kaibin Wang, Keqiang Li, Xiaoxu Zhu, Jiakui Li, Kehan Li, et al. Interactiveomni: A unified omni-modal model for audio-visual multi-turn dialogue.arXiv preprint arXiv:2510.13747, 2025
-
[48]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 12
work page 2017
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Zhifei Xie and Changqiao Wu. Mini-omni2: Towards open-source gpt-4o with vision, speech and duplex capabilities.arXiv preprint arXiv:2410.11190, 2024
-
[51]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247, 2024
work page internal anchor Pith review arXiv 2024
-
[52]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025. URLhttps://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, et al. Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19803–19813, 2025
work page 2025
-
[55]
Humanomniv2: From understanding to omni-modal reasoning with context, 2025
Qize Yang, Shimin Yao, Weixuan Chen, Shenghao Fu, Detao Bai, Jiaxing Zhao, Boyuan Sun, Bowen Yin, Xihan Wei, and Jingren Zhou. Humanomniv2: From understanding to omni-modal reasoning with context.arXiv preprint arXiv:2506.21277, 2025
-
[56]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
work page 2025
-
[57]
Audio-centric video understanding benchmark without text shortcut
Yudong Yang, Jimin Zhuang, Guangzhi Sun, Changli Tang, Yixuan Li, Peihan Li, Yifan Jiang, Wei Li, Zejun Ma, and Chao Zhang. Audio-centric video understanding benchmark without text shortcut. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6580–6598, 2025
work page 2025
-
[58]
Hanrong Ye, Chao-Han Huck Yang, Arushi Goel, Wei Huang, Ligeng Zhu, Yuanhang Su, Sean Lin, An-Chieh Cheng, Zhen Wan, Jinchuan Tian, et al. Omnivinci: Enhancing architecture and data for omni-modal understanding llm.arXiv preprint arXiv:2510.15870, 2025
-
[59]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22128–22136, 2025
work page 2025
-
[60]
Peiqi Yin, Jiangyun Zhu, Han Gao, Chenguang Zheng, Yongxiang Huang, Taichang Zhou, Ruirui Yang, Weizhi Liu, Weiqing Chen, Canlin Guo, et al. vllm-omni: Fully disaggregated serving for any-to-any multimodal models.arXiv preprint arXiv:2602.02204, 2026
-
[61]
Lmms-eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 881–916, 2025
work page 2025
-
[62]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 13 A Hyperparameter Settings To supplement the configuration details provided in the main text, Table 5 summarizes the compre- hensive hyperparameter settings utilized in the Omni...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.