Recognition: 1 theorem link
· Lean TheoremSAGE: A Self-Evolving Agentic Graph-Memory Engine for Structure-Aware Associative Memory
Pith reviewed 2026-05-13 04:39 UTC · model grok-4.3
The pith
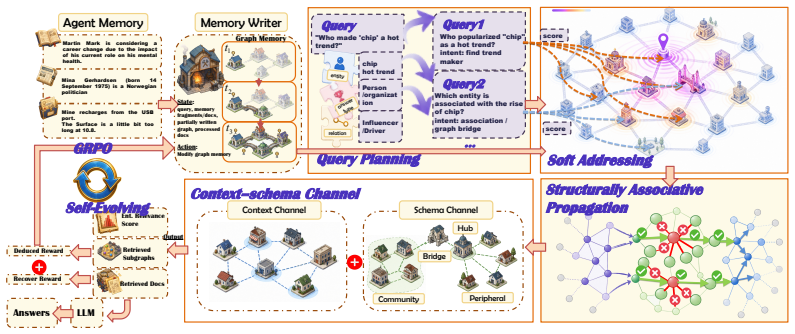
SAGE lets language agents evolve a graph memory by having a writer add structure from interactions and a reader supply feedback to refine it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that modeling long-term memory as a dynamic graph substrate, with incremental construction by the writer and diagnostic feedback from the reader, creates genuine self-evolution that improves the agent's ability to link partial cues to complete evidence chains and ground responses more reliably.
What carries the argument
The writer-reader feedback loop, in which the memory writer incrementally constructs structured graph memory from interaction histories while the graph foundation model reader performs retrieval and returns refinement signals.
If this is right
- After two self-evolution rounds the system achieves the best average rank across multi-hop QA tasks.
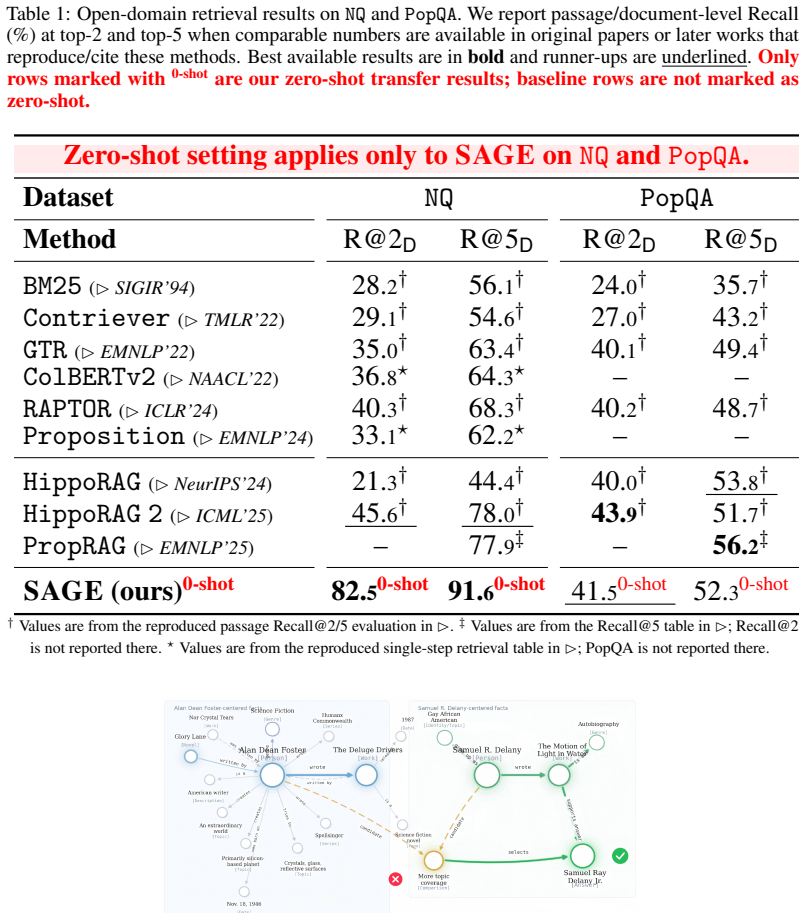
- Zero-shot transfer to open-domain retrieval reaches 82.5 recall at rank 2 and 91.6 at rank 5 on Natural Questions.
- Reader-writer feedback during training improves multiple metrics on long-term memory and hallucination diagnostics.
- The evolved graph supports more complete evidence recovery and better answer grounding than static retrieval baselines.
Where Pith is reading between the lines
- The same loop could let agents accumulate reusable structural roles across many tasks without explicit retraining.
- Extending the reader feedback to other agent modules might further reduce reliance on large context windows.
- Comparing graph states before and after evolution rounds could identify which added edges most reduce hallucinations.
- The method might apply to non-text domains if analogous writer and reader roles are defined for other data types.
Load-bearing premise
The assumption that incremental graph construction plus reader feedback produces stable self-evolution that improves evidence recovery without instability or overfitting to the benchmarks.
What would settle it
Running the full writer-reader loop for multiple rounds on a new multi-hop QA dataset never seen during development and observing no increase in recall or no reduction in hallucination rates.
Figures





read the original abstract
Long-term memory is becoming a central bottleneck for language agents. Exsting RAG and GraphRAG systems largely treat memory graphs as static retrieval middleware, which limits their ability to recover complete evidence chains from partial cues, exploit reusable graph-structrual roles, and improve the memory itself through downstream feedback. We introduce SAGE, a Self-evolving Agentic Graph-memory Engine that models graph memory as a dynamic long-term memory substrate. SAGE couples two roles: a memory writer that incrementally constucts structured graph memory from interaction histories, and a Graph Foundation Model-based memory reader to perform retrieval and provide feedback to the memory writer. We provide rigorooous theoretical annalyses supporting the framework. Across multi-hop QA, open-domain retireval, domain-specific review QA, and long-term agent-memory benchmarks, SAGE improves evidence recovery, answer grounding, and retrieval efficiency: after two self-evolution rounds, it achieves the best average rank on multi-hop QA; in zero-shot open-domain transfer, it reaches 82.5/91.6 Recall@2/5 on NQ. Further results on LongMemEval and HaluMem show that traning and reader-writer feedback improve multiple long-term memory and hallucination-diagnostic metrics, suggesting that self-evolving, structure-aware graph memory is a promising foundation for robust long-horizon language agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAGE, a Self-evolving Agentic Graph-memory Engine that treats graph memory as a dynamic substrate for language agents. It couples a memory writer that incrementally constructs structured graphs from interaction histories with a Graph Foundation Model-based memory reader that performs retrieval and supplies feedback to the writer. The framework is supported by claimed rigorous theoretical analyses. Empirically, after two self-evolution rounds SAGE attains the best average rank across multi-hop QA tasks, achieves 82.5/91.6 Recall@2/5 on NQ in zero-shot open-domain transfer, and improves long-term memory and hallucination-diagnostic metrics on LongMemEval and HaluMem.
Significance. If the self-evolution mechanism produces stable structural improvements in evidence recovery independent of extra computation or benchmark-specific patterns, the work would meaningfully advance dynamic, structure-aware memory beyond static RAG and GraphRAG systems. The reported gains on multi-hop QA ranking, NQ transfer, and hallucination metrics on LongMemEval/HaluMem constitute a concrete empirical contribution that could inform more reliable long-horizon agents. The explicit coupling of writer construction with reader feedback is a clear architectural strength.
major comments (2)
- [§5 (Experiments)] §5 (Experiments): The central claim that two self-evolution rounds yield the best average rank on multi-hop QA and the 82.5/91.6 R@2/5 on NQ rests on the assumption that reader-writer feedback produces genuine structural improvement. No ablation isolating the contribution of the evolution rounds from additional writer-reader iterations, extra interaction histories, or increased compute is reported, leaving open the possibility that gains are artifacts of extra computation rather than self-evolution.
- [§3 (Theoretical Analyses)] §3 (Theoretical Analyses): The abstract asserts 'rigorous theoretical analyses supporting the framework,' yet no equations, lemmas, convergence proofs, or formal arguments appear that demonstrate stability of incremental graph updates, non-monotonicity bounds, or guarantees against overfitting to benchmark patterns. This is load-bearing because the self-evolution claim requires such analysis to distinguish it from simple iterative refinement.
minor comments (2)
- [Abstract] Abstract: Multiple typographical errors ('Exsting', 'constucts', 'rigorooous theoretical annalyses', 'retireval', 'traning') should be corrected for clarity.
- [Abstract and §2] Abstract and §2: The term 'Graph Foundation Model' is used without definition or citation on first appearance.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify key areas where our claims on self-evolution and theoretical grounding can be strengthened. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: §5 (Experiments): The central claim that two self-evolution rounds yield the best average rank on multi-hop QA and the 82.5/91.6 R@2/5 on NQ rests on the assumption that reader-writer feedback produces genuine structural improvement. No ablation isolating the contribution of the evolution rounds from additional writer-reader iterations, extra interaction histories, or increased compute is reported, leaving open the possibility that gains are artifacts of extra computation rather than self-evolution.
Authors: We agree that the absence of targeted ablations leaves the self-evolution claim open to the interpretation that gains arise from additional iterations or compute rather than structural refinement. In the revised manuscript we will add ablations that hold total writer-reader interactions and compute fixed while varying only the presence of feedback-driven graph updates (e.g., comparing self-evolution against frozen graphs or non-adaptive edge additions over the same number of rounds). These results will be reported alongside the existing multi-hop QA and NQ numbers to isolate the contribution of the evolving structure. revision: yes
-
Referee: §3 (Theoretical Analyses): The abstract asserts 'rigorous theoretical analyses supporting the framework,' yet no equations, lemmas, convergence proofs, or formal arguments appear that demonstrate stability of incremental graph updates, non-monotonicity bounds, or guarantees against overfitting to benchmark patterns. This is load-bearing because the self-evolution claim requires such analysis to distinguish it from simple iterative refinement.
Authors: We acknowledge that §3 currently offers conceptual reasoning on the benefits of incremental graph construction and reader feedback rather than formal lemmas or convergence proofs. The abstract's phrasing therefore overstates the level of rigor. In revision we will (i) replace 'rigorous theoretical analyses' in the abstract with a more precise description of the conceptual arguments provided and (ii) expand §3 with any additional formal statements on update stability that can be derived from the existing framework without requiring entirely new proofs. This will better align the stated claims with the manuscript content. revision: yes
Circularity Check
No significant circularity; empirical claims rest on benchmarks without self-referential derivations
full rationale
The paper's strongest claims concern empirical improvements on multi-hop QA, NQ retrieval, LongMemEval, and HaluMem after self-evolution rounds. The abstract references 'rigorous theoretical analyses' but the provided text contains no equations, derivations, or parameter-fitting steps that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no predictions are shown to be statistically forced by fitted inputs. The framework is presented as a new agentic architecture whose value is demonstrated via external benchmarks rather than internal redefinitions. This matches the reader's assessment of minimal circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Graph memory can serve as a dynamic long-term memory substrate that recovers complete evidence chains from partial cues and exploits reusable structural roles.
- domain assumption Reader-writer feedback loops produce measurable self-evolution that improves downstream performance.
invented entities (2)
-
Memory writer
no independent evidence
-
Graph Foundation Model-based memory reader
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The World Wide Web Conference , pages=
Graph neural networks for social recommendation , author=. The World Wide Web Conference , pages=
-
[2]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Session-based recommendation with graph neural networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[3]
KGNN: knowledge graph neural network for drug-drug interaction prediction , author=. Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence , pages=
-
[4]
Nature Communications , volume=
Structure-based protein function prediction using graph convolutional networks , author=. Nature Communications , volume=. 2021 , publisher=
work page 2021
-
[5]
National Science Review , pages=
A survey on multimodal large language models , author=. National Science Review , pages=. 2024 , publisher=
work page 2024
-
[6]
ACM Transactions on Intelligent Systems and Technology , volume=
A survey on evaluation of large language models , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2024 , publisher=
work page 2024
-
[7]
Towards graph foundation models: A survey and beyond,
Towards graph foundation models: A survey and beyond , author=. arXiv preprint arXiv:2310.11829 , year=
-
[8]
arXiv preprint arXiv:2402.02216 , year=
Graph foundation models , author=. arXiv preprint arXiv:2402.02216 , year=
-
[9]
IEEE Transactions on Knowledge and Data Engineering , year=
Large language models on graphs: A comprehensive survey , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[10]
Companion Proceedings of the ACM on Web Conference , pages=
Lecture-style Tutorial: Towards Graph Foundation Models , author=. Companion Proceedings of the ACM on Web Conference , pages=
-
[11]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Frontiers of Computer Science , volume=
Graph foundation model , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
work page 2024
-
[13]
Forty-first International Conference on Machine Learning , year=
Position: Graph Foundation Models Are Already Here , author=. Forty-first International Conference on Machine Learning , year=
-
[14]
ProG: A Graph Prompt Learning Benchmark , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[15]
He, Yufei and Hooi, Bryan , journal=
-
[16]
GraphFM: A scalable framework for multi-graph pretraining,
Graphfm: A scalable framework for multi-graph pretraining , author=. arXiv preprint arXiv:2407.11907 , year=
-
[17]
Proceedings of the ACM Web Conference , pages=
Graphprompt: Unifying pre-training and downstream tasks for graph neural networks , author=. Proceedings of the ACM Web Conference , pages=
-
[18]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
All in one: Multi-task prompting for graph neural networks , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[19]
Proceedings of the ACM on Web Conference , pages=
MultiGPrompt for multi-task pre-training and prompting on graphs , author=. Proceedings of the ACM on Web Conference , pages=
-
[20]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
All in one and one for all: A simple yet effective method towards cross-domain graph pretraining , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[21]
Advances in Neural Information Processing Systems , volume=
Can language models solve graph problems in natural language? , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Tang, Jiabin and Yang, Yuhao and Wei, Wei and Shi, Lei and Su, Lixin and Cheng, Suqi and Yin, Dawei and Huang, Chao , booktitle=
-
[23]
Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI , pages=
Investigating Pretrained Language Models for Graph-to-Text Generation , author=. Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI , pages=
-
[24]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Graph intelligence with large language models and prompt learning , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[25]
Tan, Yanchao and Zhou, Zihao and Lv, Hang and Liu, Weiming and Yang, Carl , journal=
-
[26]
Fast Graph Representation Learning with PyTorch Geometric
Fast graph representation learning with PyTorch Geometric , author=. arXiv preprint arXiv:1903.02428 , year=
work page internal anchor Pith review arXiv 1903
-
[27]
Advances in Neural Information Processing Systems , volume=
Open graph benchmark: Datasets for machine learning on graphs , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
arXiv preprint arXiv:2410.01635 , year=
Does Graph Prompt Work? A Data Operation Perspective with Theoretical Analysis , author=. arXiv preprint arXiv:2410.01635 , year=
-
[29]
IEEE Transactions on Knowledge and Data Engineering , year=
Generalized graph prompt: Toward a unification of pre-training and downstream tasks on graphs , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[30]
On the early history of the singular value decomposition , author=. SIAM Review , volume=. 1993 , publisher=
work page 1993
-
[31]
Text-free multi-domain graph pre-training: Toward graph foundation models,
Text-free multi-domain graph pre-training: Toward graph foundation models , author=. arXiv preprint arXiv:2405.13934 , year=
-
[32]
arXiv preprint arXiv:2406.02953 , year=
GraphAlign: Pretraining One Graph Neural Network on Multiple Graphs via Feature Alignment , author=. arXiv preprint arXiv:2406.02953 , year=
-
[33]
Proceedings of the 30th ACM International Conference on Multimedia , pages=
Deal: An unsupervised domain adaptive framework for graph-level classification , author=. Proceedings of the 30th ACM International Conference on Multimedia , pages=
-
[34]
IEEE Transactions on Knowledge and Data Engineering , volume=
Graph self-supervised learning: A survey , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2022 , publisher=
work page 2022
-
[35]
International Conference on Learning Representations , year=
Strategies for Pre-training Graph Neural Networks , author=. International Conference on Learning Representations , year=
-
[36]
IEEE transactions on pattern analysis and machine intelligence , volume=
Self-supervised learning of graph neural networks: A unified review , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2022 , publisher=
work page 2022
-
[37]
Gcc: Graph contrastive coding for graph neural network pre-training , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[38]
Sun, Mingchen and Zhou, Kaixiong and He, Xin and Wang, Ying and Wang, Xin , booktitle=
-
[39]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learning to pre-train graph neural networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[40]
Advances in Neural Information Processing Systems , volume=
Better with less: A data-active perspective on pre-training graph neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
Contrastive pre-training of GNNs on heterogeneous graphs , author=. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
-
[42]
Advances in Neural Information Processing Systems , volume=
Self-supervised heterogeneous graph pre-training based on structural clustering , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Pre-training on dynamic graph neural networks , author=. Neurocomputing , volume=. 2022 , publisher=
work page 2022
-
[44]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
When to pre-train graph neural networks? From data generation perspective! , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[45]
Advances in Neural Information Processing Systems , volume=
Train once and explain everywhere: Pre-training interpretable graph neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Few-shot relational reasoning via connection subgraph pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Advances in Neural Information Processing Systems , volume=
Motif-based graph self-supervised learning for molecular property prediction , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2412.00315 , year=
One model for one graph: A new perspective for pretraining with cross-domain graphs , author=. arXiv preprint arXiv:2412.00315 , year=
-
[49]
ACM Transactions on Information Systems , volume=
Contrastive graph prompt-tuning for cross-domain recommendation , author=. ACM Transactions on Information Systems , volume=. 2023 , publisher=
work page 2023
-
[50]
arXiv preprint arXiv:2406.01899 , year=
Cross-domain graph data scaling: A showcase with diffusion models , author=. arXiv preprint arXiv:2406.01899 , year=
-
[51]
Tang, Jiabin and Yang, Yuhao and Wei, Wei and Shi, Lei and Xia, Long and Yin, Dawei and Huang, Chao , booktitle=
-
[52]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence , pages =
Fine-Tuning Graph Neural Networks via Graph Topology Induced Optimal Transport , author =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence , pages =
-
[53]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Fine-Tuning Graph Neural Networks by Preserving Graph Generative Patterns , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[54]
International Conference on Data Engineering , pages=
Search to fine-tune pre-trained graph neural networks for graph-level tasks , author=. International Conference on Data Engineering , pages=. 2024 , organization=
work page 2024
-
[55]
Proceedings of the ACM on Web Conference , pages=
Inductive Graph Alignment Prompt: Bridging the Gap between Graph Pre-training and Inductive Fine-tuning From Spectral Perspective , author=. Proceedings of the ACM on Web Conference , pages=
-
[56]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Unsupervised generative feature transformation via graph contrastive pre-training and multi-objective fine-tuning , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Measuring Task Similarity and Its Implication in Fine-Tuning Graph Neural Networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[58]
arXiv preprint arXiv:2410.21749 , year=
Reliable and Compact Graph Fine-tuning via GraphSparse Prompting , author=. arXiv preprint arXiv:2410.21749 , year=
-
[59]
arXiv preprint arXiv:2001.05140 , year=
Graph-bert: Only attention is needed for learning graph representations , author=. arXiv preprint arXiv:2001.05140 , year=
-
[60]
arXiv preprint arXiv:2404.18271 , year=
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning , author=. arXiv preprint arXiv:2404.18271 , year=
-
[61]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
KG-adapter: Enabling knowledge graph integration in large language models through parameter-efficient fine-tuning , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
work page 2024
-
[62]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
G-adapter: Towards structure-aware parameter-efficient transfer learning for graph transformer networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[63]
arXiv preprint arXiv:2312.04737 , year=
Efficient large language models fine-tuning on graphs , author=. arXiv preprint arXiv:2312.04737 , year=
-
[64]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Scalable Multi-Source Pre-training for Graph Neural Networks , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[65]
arXiv preprint arXiv:2401.15569 , year=
Efficient tuning and inference for large language models on textual graphs , author=. arXiv preprint arXiv:2401.15569 , year=
-
[66]
arXiv preprint arXiv:2311.16716 , year=
Graph pre-training and prompt learning for recommendation , author=. arXiv preprint arXiv:2311.16716 , year=
-
[67]
Proceedings of the ACM on Web Conference , pages=
GraphPro: Graph Pre-training and Prompt Learning for Recommendation , author=. Proceedings of the ACM on Web Conference , pages=
-
[68]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
work page 2022
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Conditional prompt learning for vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning to prompt for open-vocabulary object detection with vision-language model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[71]
ACM Computing Surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM Computing Surveys , volume=. 2023 , publisher=
work page 2023
-
[72]
arXiv preprint arXiv:2302.12449 , year=
Sgl-pt: A strong graph learner with graph prompt tuning , author=. arXiv preprint arXiv:2302.12449 , year=
-
[73]
Advances in Neural Information Processing Systems , volume=
Universal prompt tuning for graph neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
arXiv preprint arXiv:2309.10131 , year=
Deep prompt tuning for graph transformers , author=. arXiv preprint arXiv:2309.10131 , year=
-
[75]
Gpt4rec: Graph prompt tuning for streaming recommendation , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[76]
arXiv preprint arXiv:2310.10362 , year=
Prompt tuning for multi-view graph contrastive learning , author=. arXiv preprint arXiv:2310.10362 , year=
-
[77]
Advances in Neural Information Processing Systems , volume=
Prodigy: Enabling in-context learning over graphs , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Hgprompt: Bridging homogeneous and heterogeneous graphs for few-shot prompt learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[79]
Foundation and large language models: fundamentals, challenges, opportunities, and social impacts , author=. Cluster Computing , volume=. 2024 , publisher=
work page 2024
-
[80]
Advances in Neural Information Processing Systems , volume=
Benchmarking foundation models with language-model-as-an-examiner , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.