Recognition: no theorem link
Fuzzy k-anonymity in complex networks
Pith reviewed 2026-05-13 04:18 UTC · model grok-4.3
The pith
Modest uncertainty in attacker knowledge of a network's edges turns most unique nodes anonymous under k-anonymity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
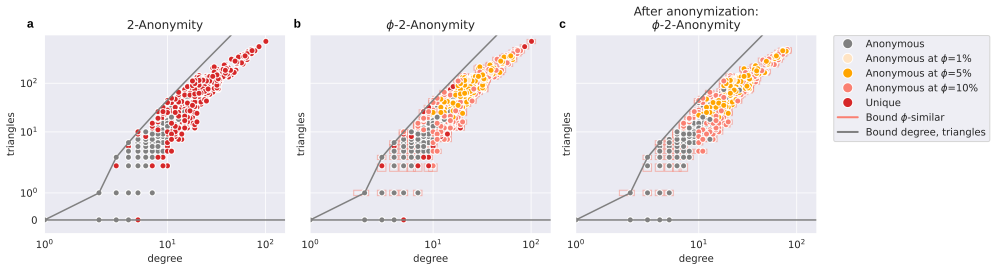
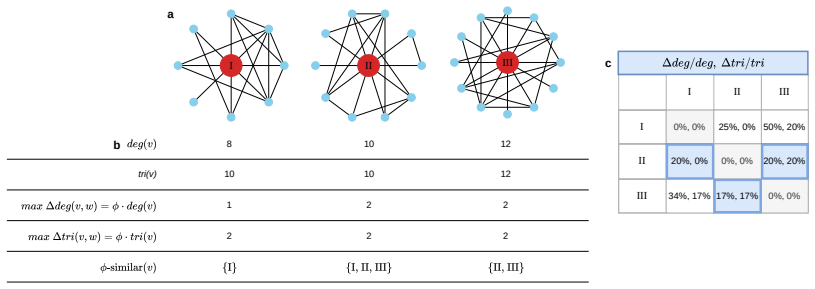
φ-k-anonymity relaxes the requirement that an attacker’s knowledge must match the published graph exactly; instead, φ represents a uniform percentage of possible edge differences, so that a node is φ-k-anonymous when at least k nodes remain indistinguishable even after allowing for that level of uncertainty.
What carries the argument
φ-k-anonymity, the mechanism that counts a node as anonymous if at least k other nodes are consistent with the attacker’s view after tolerating φ percent edge uncertainty.
If this is right
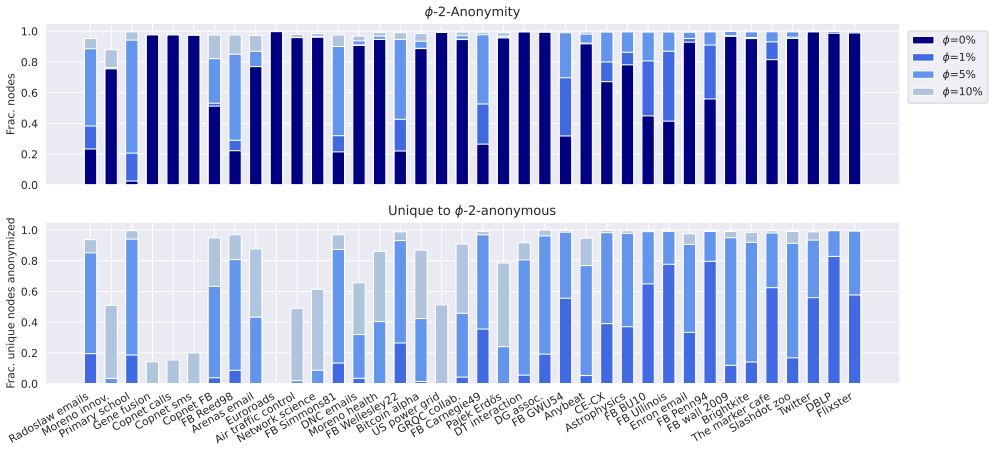
- High anonymity becomes attainable with very small edge modifications once uncertainty is taken into account.
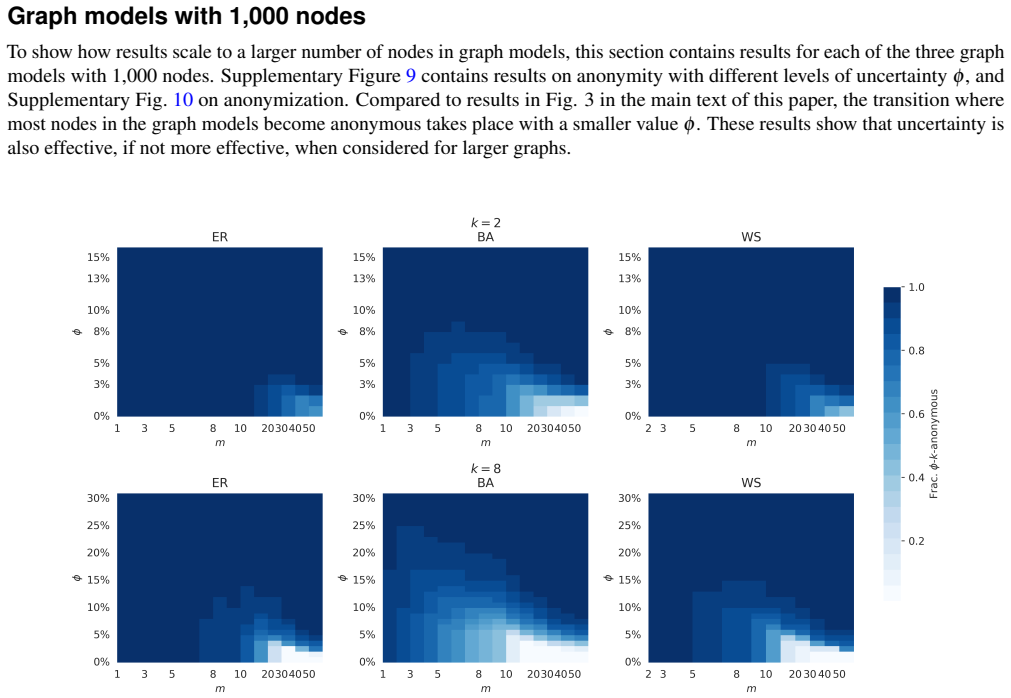
- Dense graphs that resist exact k-anonymity can still be anonymized effectively.
- Structural properties and performance on standard network tasks remain nearly unchanged.
Where Pith is reading between the lines
- Privacy methods for networks may need to treat attacker knowledge as probabilistic rather than perfect.
- The same uncertainty idea could be tested on other privacy definitions such as differential privacy on graphs.
- Releasing networks with modest uncertainty assumptions may reduce the need for heavy anonymization while still meeting practical privacy goals.
Load-bearing premise
Uncertainty in an attacker’s knowledge of network structure can be captured by one uniform percentage parameter without modeling how that uncertainty actually arises or what specific strategies the attacker uses.
What would settle it
Measure the actual uncertainty an attacker has about the edges of a released network and test whether the observed re-identification rate matches the rate predicted by the φ model at the same numerical value.
Figures









read the original abstract
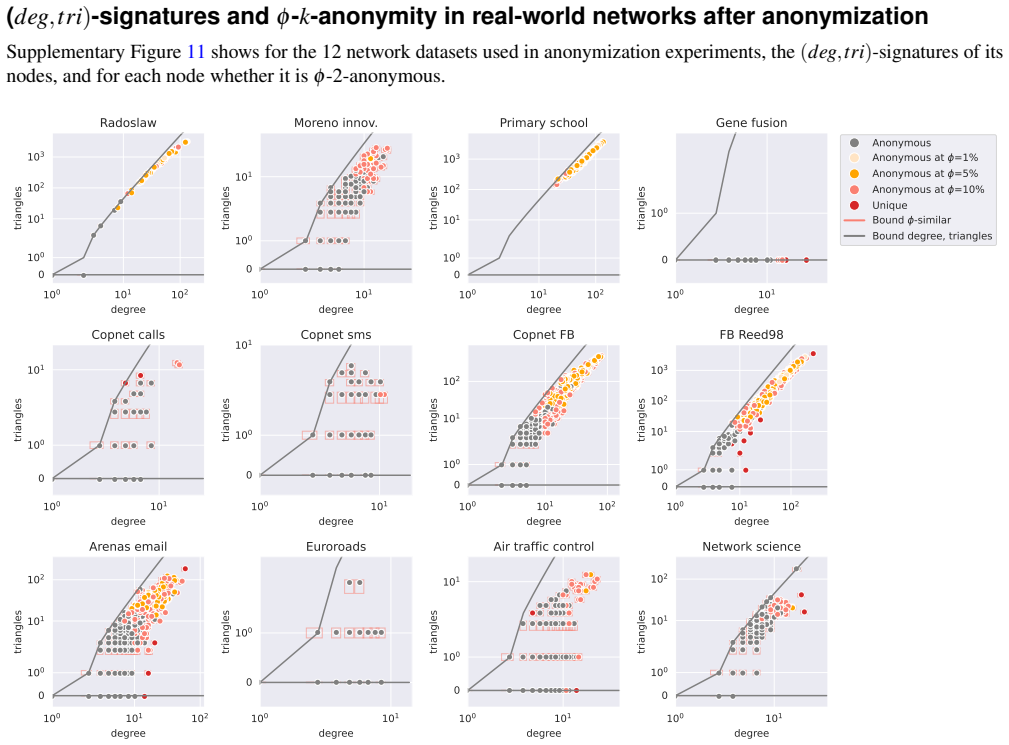
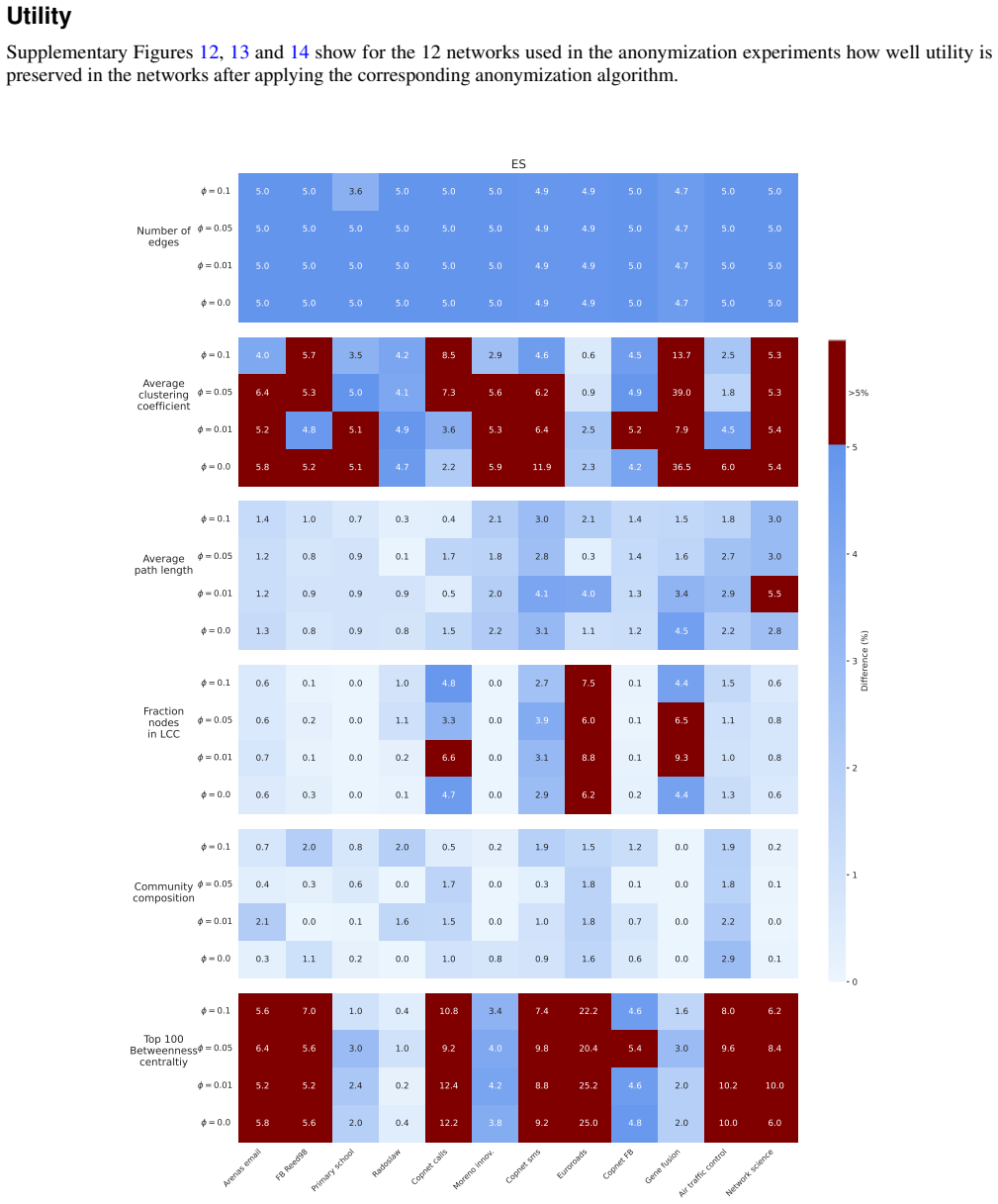
With the introduction of large-scale network data, including population-scale social networks, techniques for privacy-aware sharing of network data become increasingly important. While existing $k$-anonymity approaches can model different attacker scenarios, they typically assume that attacker knowledge exactly matches the published network structure. We argue that exact knowledge is often unrealistic and introduce $\phi$-$k$-anonymity, a fuzzy variant of $k$-anonymity in which parameter $\phi$ captures the level of uncertainty in attacker knowledge. Across a benchmark of $39$ real-world networks, a realistic level of uncertainty ($\phi=5\%$) renders, on average, $64\%$ of previously unique nodes anonymous. To further enhance anonymity, we apply anonymization algorithms under a $5\%$ edge modification budget. While full anonymization is often unattainable under exact $k$-anonymity, with low uncertainty ($\phi=10\%$) our newly proposed Greedy algorithm anonymizes over $99\%$ of the nodes. Uncertainty also enables effective anonymization in otherwise difficult to anonymize dense synthetic graphs. Additionally, data utility in terms of structural properties and performance on network analysis tasks is well preserved, with most metrics changing less than $5\%$. Overall, our findings suggest that modest uncertainty assumptions yield high levels of anonymity and utility, motivating further research on uncertainty-aware privacy guarantees for network data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces φ-k-anonymity, a fuzzy extension of k-anonymity for complex networks in which a single parameter φ models the level of uncertainty in an attacker's knowledge of the published graph structure. On a benchmark of 39 real-world networks, the authors report that φ=5% renders 64% of previously unique nodes anonymous on average; they further propose a Greedy anonymization algorithm that, under a 5% edge-modification budget and φ=10%, anonymizes >99% of nodes while keeping most structural and task-based utility metrics within a 5% change. The work also examines synthetic dense graphs and argues that modest uncertainty assumptions enable effective anonymization where exact k-anonymity fails.
Significance. If the uniform-uncertainty model is realistic, the empirical results would indicate that incorporating even small amounts of attacker uncertainty can yield substantial privacy gains in network data release with negligible utility loss, offering a practical middle ground between exact k-anonymity (often unattainable) and no privacy protection. The scale of the evaluation (39 networks plus synthetics) and the concrete percentages strengthen the practical relevance for privacy-aware sharing of social and complex network data.
major comments (3)
- [§3] §3 (Definition of φ-k-anonymity): the anonymity-set size is computed by applying a uniform φ-percentage uncertainty to every possible edge or non-edge; no derivation or experiment shows how the reported 64% figure changes when uncertainty is instead drawn from a degree-dependent or community-structured distribution. Because the headline percentages are direct functions of this uniformity assumption, the central empirical claim is sensitive to it.
- [§5] §5 (Greedy algorithm and experimental setup): the 5% edge-modification budget and the φ=10% setting are fixed globally; the manuscript does not report an ablation on how the >99% anonymization rate degrades when the budget is allocated non-uniformly or when φ is realized as local rather than global uncertainty. This directly affects the claim that the algorithm “anonymizes over 99% of the nodes.”
- [§4, §6] §4 and §6 (Utility evaluation): while average metric changes are stated to be <5%, the paper does not quantify the correlation between nodes that gain anonymity and nodes whose local properties (degree, clustering) are altered by the modifications; if the two sets overlap substantially, the utility preservation claim for the anonymized subgraph is weakened.
minor comments (3)
- [Abstract, §1] The abstract and introduction use “realistic level of uncertainty (φ=5%)” without citing external evidence or attacker models that justify this specific value; a short literature pointer or sensitivity table would help.
- [§3] Notation for the fuzzy neighborhood and the exact definition of the anonymity set size should be placed in a single displayed equation block rather than scattered across prose paragraphs.
- [§6] Figure captions for the utility plots should explicitly state the number of networks averaged and whether error bars represent standard deviation or inter-quartile range.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Definition of φ-k-anonymity): the anonymity-set size is computed by applying a uniform φ-percentage uncertainty to every possible edge or non-edge; no derivation or experiment shows how the reported 64% figure changes when uncertainty is instead drawn from a degree-dependent or community-structured distribution. Because the headline percentages are direct functions of this uniformity assumption, the central empirical claim is sensitive to it.
Authors: We acknowledge that the reported anonymity percentages, including the 64% average, are obtained under the uniform φ uncertainty model. This assumption provides a clean, parameterizable baseline that does not presuppose additional attacker knowledge of degree or community structure. While non-uniform distributions could indeed produce different anonymity rates, the current work focuses on establishing results for the uniform case, which is a standard starting point in fuzzy privacy models. In the revision we will explicitly qualify the empirical claims as holding under uniform uncertainty and add a short discussion paragraph in §3 on the potential sensitivity to alternative distributions, together with directions for future work. revision: partial
-
Referee: [§5] §5 (Greedy algorithm and experimental setup): the 5% edge-modification budget and the φ=10% setting are fixed globally; the manuscript does not report an ablation on how the >99% anonymization rate degrades when the budget is allocated non-uniformly or when φ is realized as local rather than global uncertainty. This directly affects the claim that the algorithm “anonymizes over 99% of the nodes.”
Authors: The 5% global budget and φ=10% values are chosen as representative modest constraints to demonstrate that the Greedy algorithm can achieve high anonymization where exact k-anonymity cannot. The >99% figure is therefore tied to these global settings. We agree that an ablation on non-uniform budget allocation or locally varying φ would strengthen the robustness claim. In the revised manuscript we will add a sensitivity discussion and, where computationally practical, limited additional experiments or tables showing how the anonymization rate varies under modest deviations from the global parameters. revision: partial
-
Referee: [§4, §6] §4 and §6 (Utility evaluation): while average metric changes are stated to be <5%, the paper does not quantify the correlation between nodes that gain anonymity and nodes whose local properties (degree, clustering) are altered by the modifications; if the two sets overlap substantially, the utility preservation claim for the anonymized subgraph is weakened.
Authors: The referee correctly notes that our utility results are reported as averages across the whole graph. We have not yet computed the overlap or correlation between the set of nodes that become anonymous and the set whose local metrics (degree, clustering coefficient, etc.) are changed by the edge modifications. This additional analysis would clarify whether utility is preserved specifically for the newly anonymized nodes. We will perform this quantification in the revision—computing overlap statistics and conditional metric changes—and include the results in §4 and §6. revision: yes
Circularity Check
No circularity; empirical anonymity metrics computed on external networks
full rationale
The paper defines φ-k-anonymity by extending standard k-anonymity with a uniform uncertainty parameter φ and then reports computed percentages (e.g., 64% of unique nodes anonymized at φ=5%) obtained by applying that definition to 39 independent real-world networks plus synthetic graphs. These headline numbers are direct evaluation outputs, not quantities that reduce by construction to fitted parameters, self-referential definitions, or self-citation chains. No equations or steps in the provided text equate a reported result to its own input; the uniformity assumption on φ is an explicit modeling choice whose consequences are measured externally rather than presupposed.
Axiom & Free-Parameter Ledger
free parameters (2)
- φ (uncertainty level)
- edge modification budget (5%)
axioms (2)
- domain assumption Attacker knowledge of network structure is uncertain and this uncertainty can be modeled uniformly by a single scalar φ representing percentage deviation.
- domain assumption Structural properties and network analysis task performance are adequate proxies for data utility after anonymization.
Reference graph
Works this paper leans on
-
[1]
Li, Y ., Fan, J., Wang, Y . & Tan, K.-L. Influence maximization on social graphs: A survey.IEEE Transactions on Knowl. Data Eng.30, 1852–1872 (2018)
work page 2018
-
[2]
Azizi, A., Montalvo, C., Espinoza, B., Kang, Y . & Castillo-Chavez, C. Epidemics on networks: Reducing disease transmission using health emergency declarations and peer communication.Infect. Dis. Model.5, 12–22 (2020)
work page 2020
-
[3]
Kazmina, Y ., Heemskerk, E. M., Bokányi, E. & Takes, F. W. Socio-economic segregation in a population-scale social network.Soc. Networks78, 279–291 (2024). 4.Bojanowski, M. & Corten, R. Measuring segregation in social networks.Soc. Networks39, 14–32 (2014)
work page 2024
-
[4]
Bokányi, E., Heemskerk, E. M. & Takes, F. W. The anatomy of a population-scale social network.Sci. Reports13, 9209 (2023)
work page 2023
-
[5]
Panayiotou, G.et al.Anatomy of a swedish population-scale network: G. panayiotou et al.Sci. Reports15, 30300 (2025)
work page 2025
-
[6]
Cremers, J.et al.Unveiling the social fabric through a temporal, nation-scale social network and its characteristics.Sci. Reports15, 18383 (2025)
work page 2025
- [7]
-
[8]
Romanini, D., Lehmann, S. & Kivelä, M. Privacy and uniqueness of neighborhoods in social networks.Sci. Reports11, 20104 (2021)
work page 2021
-
[9]
de Jong, R. G., van der Loo, M. P. J. & Takes, F. W. The effect of distant connections on node anonymity in complex networks.Sci. Reports14, 1156 (2024). 11.Duncan, G. T. & Lambert, D. Disclosure-Limited Data Dissemination.J. Am. Stat. Assoc.81, 10–18 (1986). 11/20 12.Lambert, D. Measures of disclosure risk and harm.J. Off. Stat.9, 313–331 (1993)
work page 2024
-
[10]
Jiang, H.et al.Applications of differential privacy in social network analysis: A survey.IEEE Transactions on Knowl. Data Eng.35, 108–127 (2021)
work page 2021
-
[11]
Liu, K. & Terzi, E. Towards identity anonymization on graphs. InProceedings of the ACM SIGMOD International Conference on Management of Data, 93–106 (2008)
work page 2008
-
[12]
de Jong, R. G., van der Loo, M. P. J. & Takes, F. W. Algorithms for efficiently computing structural anonymity in complex networks.ACM J. Exp. Algorithmics28(2023)
work page 2023
- [13]
-
[14]
de Jong, R. G., van der Loo, M. P. J. & Takes, F. W. The anonymization problem in social networks. InProceedings of the Workshop on Modelling and Mining Networks (WAW)(To appear)
-
[15]
Bonello, S., de Jong, R. G., Bäck, T. H. W. & Takes, F. W. Utility-aware social network anonymization using genetic algorithms. InProceedings of the Genetic and Evolutionary Computation Conference Companion (GECCO), 775–778 (2025)
work page 2025
-
[16]
Arsene, E. D., de Jong, R. G., Takes, F. W. & Latour, A. L. D. A simulated annealing approach to social network anonymization. InProceedings of Complex Networks & Their Applications XIV, 205–216 (2026)
work page 2026
-
[17]
de Jong, R. G., van der Loo, M. P. & Takes, F. W. A systematic comparison of measures for k-anonymity in networks. arXiv preprint arXiv:2407.02290(2024)
-
[18]
de Vries, M. M., de Jong, R. G., van der Loo, M. P. J., de Wolf, P.-P. & Takes, F. W. The risk of identity disclosure through network structure: Anecdotal evidence from a hackathon. Working Document, United Nations Economic Commission for Europe (2023)
work page 2023
-
[19]
Blumenthal, D. B. & Gamper, J. On the exact computation of the graph edit distance.Pattern Recognit. Lett.134, 46–57 (2020). 23.Erd ˝os, P. & Rényi, A. On the evolution of random graphs.Publ. Math. Inst. Hungarian Acad. Sci.5, 17–60 (1960). 24.Barabási, A. L. & Albert, R. Emergence of scaling in random networks.Science286, 509–512 (1999). 25.Watts, D. J. ...
work page 2020
-
[20]
Konect: the Koblenz network collection
Kunegis, J. Konect: the Koblenz network collection. InProceedings of the 22nd International Conference on World Wide Web, 1343–1350 (2013)
work page 2013
-
[21]
Stehlé, J.et al.High-resolution measurements of face-to-face contact patterns in a primary school.PLoS ONE6, e23176 (2011)
work page 2011
-
[22]
Sapiezynski, P., Stopczynski, A., Lassen, D. D. & Jørgensen, S. L. The copenhagen networks study interaction data. figshare. https://doi.org/10.6084/m9.figshare.7267433.v1 (last accessed 2025) (2019)
-
[23]
Rossi, R. A. & Ahmed, N. K. The network data repository with interactive graph analytics and visualization. InProceedings of the AAAI Conference on Artificial Intelligence, 4292–4293 (2015)
work page 2015
-
[24]
Leskovec, J. & Krevl, A. Snap datasets: Stanford large network dataset collection. http://snap.stanford.edu/data (last accessed 2025) (2014)
work page 2025
-
[25]
Zitnik, M., Sosiˇc, R., Maheshwari, S. & Leskovec, J. Biosnap datasets: Stanford. biomedical network dataset collection. http://snap.stanford.edu/biodata (last accessed 2025) (2018). 32.Fire, M. Data 4 good lab. https://data4goodlab.github.io/MichaelFire/#section3 (last accessed 2025) (2020)
work page 2025
-
[26]
Traag, V . A., Waltman, L. & Van Eck, N. J. From louvain to leiden: guaranteeing well-connected communities.Sci. Reports9, 1–12 (2019). 34.Lancichinetti, A. & Fortunato, S. Consensus clustering in complex networks.Sci. Reports2, 336 (2012)
work page 2019
-
[27]
Csardi, G. & Nepusz, T. The igraph software package for complex network research.InterJournal Complex Syst.1695 (2006)
work page 2006
-
[28]
Hagberg, A., Swart, P. & Schult, D. Exploring network structure, dynamics, and function using networkx. Tech. Rep., Los Alamos National Lab (LANL) (2008). 12/20 Supplementary information Measures and distances In the literature on k-anonymity for networks, various measures for anonymity have been introduced that reflect different attacker scenarios. Suppl...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.