Recognition: 2 theorem links
· Lean TheoremA Line--Search--Based Stochastic Gradient Method for 3D Computed Tomography
Pith reviewed 2026-05-13 04:09 UTC · model grok-4.3
The pith
A line-search stochastic gradient method with full-projection mini-batches accelerates 3D CT reconstruction without training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
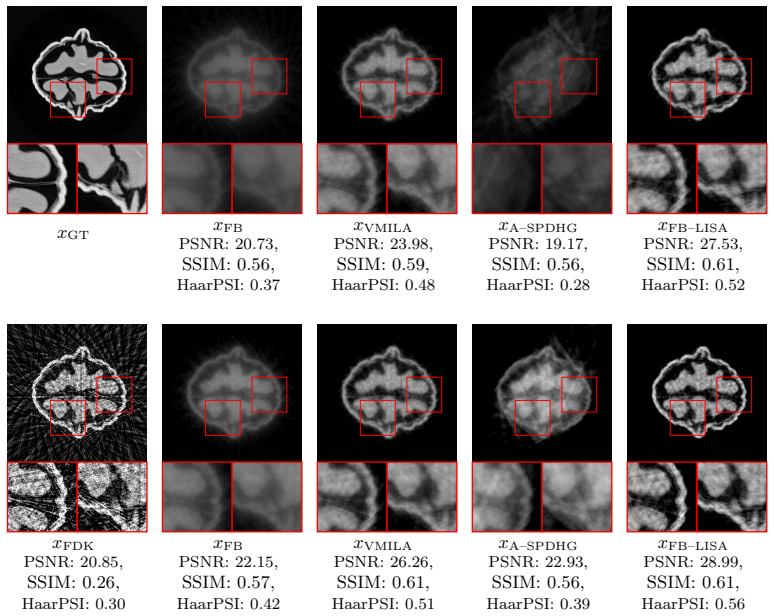
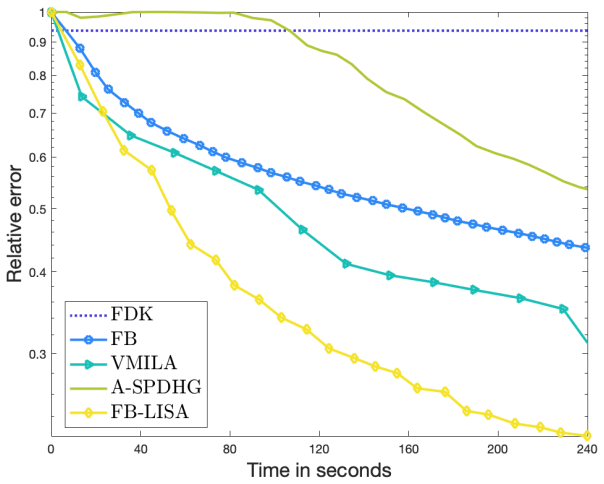
FB-LISA applies forward-backward splitting to a line-search-based stochastic gradient method so that mini-batches of full 2D projections can be used on the large-scale 3D CT operator; the resulting scheme yields substantial speed-ups in early iterations while preserving the physical structure of the acquisition process and requiring no training data or learned priors.
What carries the argument
FB-LISA, the forward-backward line-search stochastic gradient algorithm that samples mini-batches consisting of entire 2D projections to address the high-dimensional 3D CT inverse problem.
Load-bearing premise
The forward-backward generalization of the line-search stochastic gradient method keeps reliable convergence and reconstruction quality when applied to the high-dimensional 3D CT operator with full-projection mini-batches.
What would settle it
A test on a standard 3D CT benchmark dataset in which FB-LISA either diverges, fails to reach acceptable error in a reasonable number of iterations, or yields image quality metrics markedly worse than a deterministic line-search method would disprove the central claim.
Figures
read the original abstract
We introduce FB-LISA, a forward-backward (FB) generalization of a recently proposed line-search-based stochastic gradient algorithm to address the imaging problem of volumetric reconstruction in Computed Tomography, a substantially high demanding problem, which involves orders of magnitude of data, a high computational burden for forward and backprojection, and memory requirements that push current GPU architectures to their limits. Our formulation employs stochastic mini-batches composed of full 2D projections, preserving the physical structure of the acquisition process while enabling significant speed-ups during early iterations. The resulting method demonstrates how concepts traditionally associated with deep learning can be repurposed to accelerate large-scale inverse problems, without relying on training data or learned priors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FB-LISA, a forward-backward generalization of a line-search-based stochastic gradient algorithm for volumetric reconstruction in 3D Computed Tomography. The formulation employs stochastic mini-batches of full 2D projections to preserve the physical structure of the acquisition process while enabling speed-ups in early iterations, and it repurposes concepts from deep learning to accelerate large-scale inverse problems without training data or learned priors.
Significance. If the claimed convergence behavior and reconstruction quality hold, the work would be significant for practical acceleration of high-dimensional CT problems on limited hardware. It offers a structure-preserving stochastic approach that bridges optimization ideas from machine learning with classical inverse problems, potentially reducing computational and memory demands without requiring external training data.
minor comments (2)
- [Abstract] The abstract asserts speed-ups and structure preservation but would benefit from a brief quantitative statement (e.g., iteration count or wall-clock reduction) to ground the central claim, even if full results appear later in the manuscript.
- [Methods] Notation for the stochastic mini-batch selection (full 2D projections) should be introduced with a clear equation or diagram in the methods section to make the preservation of acquisition physics explicit.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on FB-LISA and for recommending minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper introduces FB-LISA as a forward-backward generalization of a recently proposed line-search stochastic gradient method for 3D CT reconstruction, using stochastic mini-batches of full 2D projections to preserve acquisition physics and accelerate early iterations without training data. No equations, fitted parameters, or explicit predictions are shown in the abstract or description that reduce by construction to inputs. The formulation is presented as a direct methodological extension that repurposes deep learning concepts for inverse problems, with the central claim remaining independent and self-contained rather than tautological or forced by self-citation chains. No self-definitional steps, fitted-input predictions, or load-bearing uniqueness theorems appear.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J(x) = ½(x + x⁻¹) − 1 is the unique calibrated reciprocal cost) unclearFB–LISA ... proximal operator ... line-search inequality ... f_Nk(¯x(k)) ≤ ... + (1/(2α_k))∥¯x(k)−x(k)∥² ... Theorem 1 (almost-sure stationarity of limit points)
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction (8-tick period and D=3 forced) unclearmini-batch size increase ... N_t = min(n_max, max(⌈C/(ε̂_k + ⌈n/N_{t-1}⌉)⌉, N_0)) ... 8-tick or φ-ladder absent
Reference graph
Works this paper leans on
-
[1]
A. H. Andersen and A. C. Kak. Simultaneous algebraic reconstruction technique (sart): a superior implementation of the art algorithm.Ultrasonic imaging, 6(1):81–94, 1984
work page 1984
-
[2]
J. Barzilai and J. M. Borwein. Two-point step size gradient methods.IMA Journal of Numerical Analysis, 8:141–148, 1988
work page 1988
-
[3]
Beck.First-order methods in optimization
A. Beck.First-order methods in optimization. SIAM, 2017
work page 2017
-
[4]
S. Bonettini, I. Loris, F. Porta, and M. Prato. Variable metric inexact line-search-based methods for nonsmooth optimization.SIAM Journal on Optimization, 26(2):891–921, 2016
work page 2016
- [5]
-
[6]
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers.Foundations and Trends in Machine learning, 3(1):1–22, 2011
work page 2011
-
[7]
R. Cavicchioli, J. C. Hu, E. Loli Piccolomini, E. Morotti, and L. Zanni. Gpu accel- eration of a model-based iterative method for digital breast tomosynthesis.Scientific reports, 10(1):43, 2020
work page 2020
-
[8]
A. Chambolle, C. Delplancke, M. J. Ehrhardt, C.-B. Sch¨ onlieb, and J. Tang. Stochastic primal–dual hybrid gradient algorithm with adaptive step sizes.Journal of Mathemat- ical Imaging and Vision, 66:294–313, 2024. 14
work page 2024
-
[9]
A. Chambolle, M. J. Ehrhardt, P. Richt´ arik, and C.-B. Sch¨ onlieb. Stochastic primal- dual hybrid gradient algorithm with arbitrary sampling and imaging applications. SIAM Journal on Optimization, 28:2783–2808, 2018
work page 2018
-
[10]
A. Chambolle and T. Pock. A first-order primal-dual algorithm for convex problems with applications to imaging.Journal of Mathematical Imaging and Vision, 40(1):120– 145, 2011
work page 2011
-
[11]
P. L. Combettes and V. R. Wajs. Signal recovery by proximal forward-backward split- ting.Multiscale Modeling & Simulation, 4(4):1168–1200, 2005
work page 2005
-
[12]
L. Condat. A primal–dual splitting method for convex optimization involving lips- chitzian, proximable and linear composite terms.Journal of optimization theory and applications, 158(2):460–479, 2013
work page 2013
- [13]
-
[14]
M. J. Ehrhardt, ˇZ. Kereta, J. Liang, and J. Tang. A guide to stochastic optimisation for large-scale inverse problems.Inverse Problems, 41(5), 2025
work page 2025
-
[15]
M. J. Ehrhardt, P. J. Markiewicz, and C.-B. Sch¨ onlieb. Faster pet reconstruction with non-smooth priors by randomization and preconditioning.Physics in Medicine & Biology, 64:225019, 2019
work page 2019
-
[16]
H. Erdogan and J. A. Fessler. Ordered subsets algorithms for transmission tomography. Phys. Med. Biol., 44(11):2835, 1999
work page 1999
-
[17]
L. A. Feldkamp, L. C. Davis, and J. W. Kress. Practical cone-beam algorithm.Journal of the Optical Society of America A, 1(6):612–619, 1984
work page 1984
-
[18]
G. Franchini, F. Porta, V. Ruggiero, and I. Trombini. A line search based proximal stochastic gradient algorithm with dynamical variance reduction.Journal of Scientific Computing, 94:23, 2023
work page 2023
-
[19]
G. Franchini, F. Porta, V. Ruggiero, I. Trombini, and L. Zanni. A stochastic gradient method with variance control and variable learning rate for deep learning.Journal of Computational and Applied Mathematics, 451:116083, 2024
work page 2024
-
[20]
G. Frassoldati, G. Zanghirati, and L. Zanni. New adaptive stepsize selections in gra- dient methods.J. Ind. Manag. Optim., 4(2):299–312, 2008
work page 2008
-
[21]
G. T. Herman and L. B. Meyer. Algebraic reconstruction techniques can be made computationally efficient (positron emission tomography application).IEEE Trans. Med. Imag., 12(3):600–609, 1993
work page 1993
-
[22]
A. C. Kak and M. Slaney.Principles of computerized tomographic imaging. SIAM, 2001. 15
work page 2001
-
[23]
D. Kim, S. Ramani, and J. A. Fessler. Combining ordered subsets and momentum for accelerated x-ray ct image reconstruction.IEEE Trans. Med. Imag., 34(1):167–178, 2015
work page 2015
-
[24]
M. Lazzaretti, Z. Kereta, C. Estatico, and L. Calatroni. Stochastic gradient descent for linear inverse problems in variable exponent lebesgue spaces. InInternational Con- ference on Scale Space and Variational Methods in Computer Vision, pages 457–470. Springer, 2023
work page 2023
-
[25]
A. Meaney. Cone-beam computed tomography dataset of a walnut (1.1.0) [data set]. Zenodo, 2022
work page 2022
-
[26]
E. Papoutsellis, M. A. G. Duff, J. S. Jørgensen, S. Porter, C. Delplancke, G. Fardell, E. Pasca, and K. Thielemans. A modular approach to stochastic optimisation for inverse problems using the core imaging library.arXiv preprint arXiv:2603.21230, 2026
-
[27]
Polyak.Introduction to Optimization
B. Polyak.Introduction to Optimization. Optimization Software, New York, 1987
work page 1987
-
[28]
R. Reisenhofer, S. Bosse, G. Kutyniok, and T. Wiegand. A Haar Wavelet-Based Percep- tual Similarity Index for Image Quality Assessment.Signal Process. Image, 61:33–43, 2018
work page 2018
-
[29]
J. Tang, K. Egiazarian, and M. Davies. The limitation and practical acceleration of stochastic gradient algorithms in inverse problems. In IEEE, editor,ICASSP 2019- 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7680–7684, 2019
work page 2019
-
[30]
J. Tang, K. Egiazarian, M. Golbabaee, and M. Davies. The practicality of stochas- tic optimization in imaging inverse problems.IEEE Transactions on Computational Imaging, 6:1471–1485, 2020
work page 2020
-
[31]
W. Van Aarle, W. J. Palenstijn, J. Cant, E. Janssens, F. Bleichrodt, A. Dabravolski, J. De Beenhouwer, K. J. Batenburg, and J. Sijbers. Fast and flexible X-ray tomography using the ASTRA toolbox.Optics express, 24(22):25129–25147, 2016
work page 2016
-
[32]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 16
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.