Recognition: no theorem link
UniCustom: Unified Visual Conditioning for Multi-Reference Image Generation
Pith reviewed 2026-05-13 05:51 UTC · model grok-4.3
The pith
Fusing semantic ViT features with appearance-rich VAE features early before VLM encoding allows the model to better associate multiple reference subjects with their specific visual details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniCustom proposes that early fusion of ViT semantic features and VAE appearance features before VLM encoding, implemented through a lightweight linear layer, produces hidden states that jointly represent each referred subject and its corresponding visual details. This unified conditioning is learned via a two-stage process of reconstruction-oriented pretraining to retain reference-specific appearance followed by supervised finetuning on single- and multi-reference tasks, together with slot-wise binding regularization to limit cross-reference entanglement.
What carries the argument
Early fusion of ViT and VAE features before VLM encoding via a lightweight linear layer, which creates unified hidden states that carry both semantics and appearance for each reference image.
If this is right
- Each reference image's identity and fine-grained appearance remain more consistently preserved across generated outputs.
- Text instructions that assign specific roles to different references are followed with higher accuracy.
- Attribute leakage and unintended mixing of details between references decrease in complex multi-subject scenes.
- Overall compositional fidelity improves because the model maintains clearer bindings between textual descriptions and visual references.
Where Pith is reading between the lines
- The same early-fusion pattern could be tested in video generation pipelines where temporal consistency across multiple reference subjects is required.
- Replacing the linear fusion layer with a small learned network might further strengthen detail preservation while keeping the overall training budget low.
- The slot-wise regularization term could be examined on datasets with larger numbers of simultaneous references to check whether binding quality scales.
Load-bearing premise
That early fusion of ViT and VAE features inside the VLM hidden states will simultaneously preserve semantic grounding and low-level appearance details without introducing new entanglement or training instability.
What would settle it
Training and evaluating the unified model on the two multi-reference generation benchmarks and observing no measurable gains in subject consistency, instruction following, or compositional fidelity over the decoupled ViT-plus-VAE baselines would falsify the claimed benefit of early fusion.
Figures




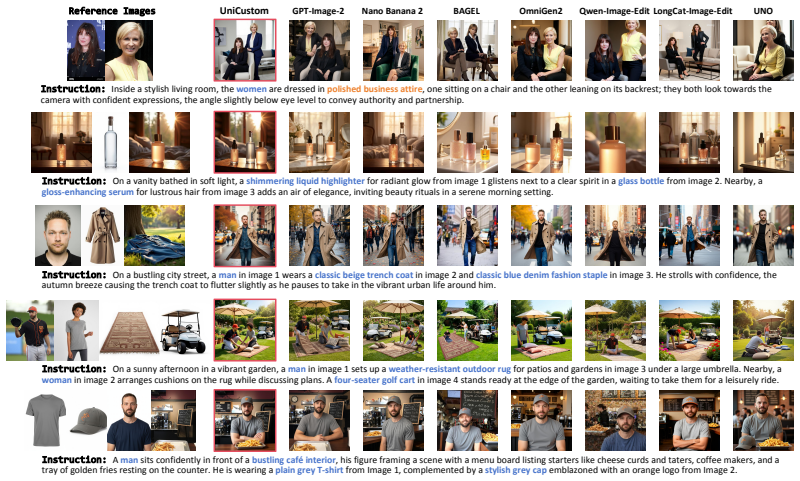








read the original abstract
Multi-reference image generation aims to synthesize images from textual instructions while faithfully preserving subject identities from multiple reference images. Existing VLM-enhanced diffusion models commonly rely on decoupled visual conditioning: semantic ViT features are processed by the VLM for instruction understanding, whereas appearance-rich VAE features are injected later into the diffusion backbone. Despite its intuitive design, this separation makes it difficult for the model to associate each semantically grounded subject with visual details from the correct reference image. As a result, the model may recognize which subject is being referred to, but fail to preserve its identity and fine-grained appearance, leading to attribute leakage and cross-reference confusion in complex multi-reference settings. To address this issue, we propose UniCustom, a unified visual conditioning framework that fuses ViT and VAE features before VLM encoding. This early fusion exposes the VLM to both semantic cues and appearance-rich details, enabling its hidden states to jointly encode the referred subject and corresponding visual appearance with only a lightweight linear fusion layer. To learn such unified representations, we adopt a two-stage training strategy: reconstruction-oriented pretraining that preserves reference-specific appearance details in the fused hidden states, followed by supervised finetuning on single- and multi-reference generation tasks. We further introduce a slot-wise binding regularization that encourages each image slot to preserve low-level details of its corresponding reference, thereby reducing cross-reference entanglement. Experiments on two multi-reference generation benchmarks demonstrate that UniCustom consistently improves subject consistency, instruction following, and compositional fidelity over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniCustom for multi-reference image generation, which fuses ViT semantic features and VAE appearance features early via a lightweight linear layer before VLM encoding. It employs a two-stage training procedure (reconstruction-oriented pretraining followed by supervised finetuning on single- and multi-reference tasks) plus slot-wise binding regularization to preserve low-level details and reduce cross-reference entanglement. The central claim, supported by experiments on two benchmarks, is that this unified conditioning yields consistent gains in subject consistency, instruction following, and compositional fidelity over strong baselines.
Significance. If the gains can be rigorously attributed to the early fusion mechanism rather than the auxiliary training recipe, the work would meaningfully advance VLM-enhanced diffusion models by addressing the semantic-appearance decoupling problem that leads to attribute leakage and confusion in multi-reference settings. The lightweight fusion and practical two-stage strategy are strengths that could be adopted more broadly if validated.
major comments (2)
- [Experiments] Experiments section: the comparisons to baselines do not describe whether those baselines were retrained with the identical two-stage procedure and slot-wise binding regularization; without such matched controls, the reported improvements in subject consistency and compositional fidelity cannot be confidently attributed to the early ViT-VAE fusion rather than the training and regularization components.
- [Method] Method section (description of unified conditioning): the claim that early fusion via the linear layer 'enables its hidden states to jointly encode the referred subject and corresponding visual appearance' lacks supporting analysis (e.g., feature visualization or entanglement metrics) showing that semantic grounding is preserved without introducing new training instability or detail loss, which is load-bearing for the weakest assumption identified in the approach.
minor comments (2)
- [Abstract] Abstract: the specific names of the two multi-reference generation benchmarks and the quantitative metrics (e.g., subject consistency scores) should be stated to allow immediate assessment of the strength of the claims.
- [Method] The notation for the linear fusion layer and the slot-wise regularization term should be formalized with equations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor where appropriate.
read point-by-point responses
-
Referee: Experiments section: the comparisons to baselines do not describe whether those baselines were retrained with the identical two-stage procedure and slot-wise binding regularization; without such matched controls, the reported improvements in subject consistency and compositional fidelity cannot be confidently attributed to the early ViT-VAE fusion rather than the training and regularization components.
Authors: We agree that matched controls would provide stronger evidence for attributing gains specifically to early fusion. The original experiments compared against published baseline implementations to reflect standard practice. The two-stage training and slot-wise regularization are integral to enabling effective unified conditioning in UniCustom. In the revision we will add a controlled ablation applying the same training recipe to at least one strong baseline (where architecture permits) and report the resulting metrics to better isolate the contribution of the fusion layer. revision: yes
-
Referee: Method section (description of unified conditioning): the claim that early fusion via the linear layer 'enables its hidden states to jointly encode the referred subject and corresponding visual appearance' lacks supporting analysis (e.g., feature visualization or entanglement metrics) showing that semantic grounding is preserved without introducing new training instability or detail loss, which is load-bearing for the weakest assumption identified in the approach.
Authors: We acknowledge that direct supporting analysis would strengthen the claim. While end-to-end benchmark gains provide indirect evidence that semantics and appearance are jointly encoded without catastrophic loss, we will add feature visualizations (e.g., t-SNE of fused vs. original ViT/VAE states) and simple quantitative checks (cosine similarity to reference features and training-loss stability curves) in the revised method section to demonstrate preservation of grounding and absence of new instability. revision: yes
Circularity Check
No circularity: empirical claims rest on independent benchmarks and standard training steps
full rationale
The paper introduces an architectural modification (early ViT+VAE fusion via linear layer) plus a two-stage training recipe and slot-wise regularization, then reports empirical gains on external multi-reference benchmarks. No equations, predictions, or first-principles derivations are presented that reduce the claimed improvements to quantities defined by the same fitted parameters or self-citations. The training procedure is described as standard reconstruction pretraining followed by supervised fine-tuning; the central result is an experimental comparison rather than a closed-form identity or self-referential fit. This is a self-contained design-and-evaluation paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- linear fusion layer weights
- slot-wise binding regularization strength
axioms (2)
- domain assumption Diffusion models can be conditioned on fused visual features without loss of semantic or appearance fidelity
- domain assumption Two-stage training (reconstruction then generation) converges to better multi-reference performance than joint training
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.