Recognition: no theorem link
AB-Sparse: Sparse Attention with Adaptive Block Size for Accurate and Efficient Long-Context Inference
Pith reviewed 2026-05-13 04:38 UTC · model grok-4.3
The pith
Attention heads vary in block-size sensitivity, so assigning different sizes per head raises sparse-attention accuracy up to 5.43 percent with unchanged throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
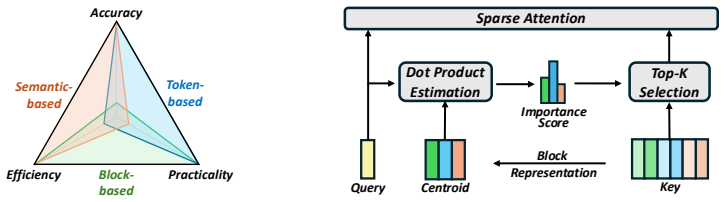
AB-Sparse is a training-free framework that allocates adaptive block sizes across attention heads according to their measured sensitivity to granularity. It pairs this allocation with lossless block-centroid quantization to offset the memory increase and supplies custom GPU kernels that execute variable block sizes efficiently. On long-context inference benchmarks the resulting system improves accuracy by as much as 5.43 percent over existing fixed-block sparse attention methods while incurring no throughput penalty.
What carries the argument
Per-head adaptive block-size allocation driven by a training-free sensitivity metric, together with block-centroid quantization and variable-block-size GPU kernels.
Load-bearing premise
Differences in attention-head sensitivity to block granularity are stable enough that a training-free measurement rule can identify useful allocations that hold across different inputs and tasks.
What would settle it
If a new long-context benchmark or model shows that the adaptive allocation yields less than one percent accuracy gain or reduces accuracy compared with the best fixed block size, the premise that per-head differences are reliably exploitable would be falsified.
Figures







read the original abstract
As large language models scale to longer contexts, loading the growing KV cache during attention computation becomes a critical bottleneck. Previous work has shown that attention computation is dominated by a small subset of tokens. This motivates block sparse attention methods that partition the KV cache into fixed-size blocks and selectively compute attention over those blocks exhibiting high importance. However, these methods assign a uniform block size across all attention heads, implicitly assuming homogeneous behavior throughout the model. Our analysis reveals that this assumption is flawed: attention heads exhibit widely varying sensitivity to block granularity, and uniformity leads to suboptimal accuracy. We present AB-Sparse, a training-free algorithm-system co-designed framework that improves accuracy while preserving throughput. AB-Sparse introduces lightweight adaptive block size allocation across attention heads to improve accuracy. To compensate for the additional memory overhead, it further employs lossless block centroid quantization. In addition, custom GPU kernels are developed to support efficient execution with variable block sizes. Evaluation results demonstrate that AB-Sparse achieves an accuracy improvement of up to 5.43% over existing block sparse attention baselines without throughput overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AB-Sparse, a training-free algorithm-system co-design for block-sparse attention in long-context LLMs. It claims that attention heads exhibit varying sensitivity to block granularity (making uniform block sizes suboptimal), introduces per-head adaptive block-size allocation, lossless block-centroid quantization to offset memory costs, and custom GPU kernels for variable block sizes. The central empirical claim is an accuracy improvement of up to 5.43% over existing block-sparse baselines with no throughput overhead.
Significance. If the adaptive allocation rule generalizes, the approach could meaningfully improve the accuracy-throughput tradeoff in sparse attention methods by relaxing the homogeneity assumption. The training-free property and explicit system co-design (quantization plus kernels) are practical strengths that could aid deployment. However, the assessed significance is tempered by the absence of quantitative stability metrics or cross-task validation for the sensitivity-based rule.
major comments (2)
- [Abstract, §3] Abstract and §3 (analysis of head sensitivity): the manuscript states that 'analysis revealed varying head sensitivity' and that uniformity is suboptimal, but provides no description of the measurement method, sensitivity metric, data used, or quantitative stability across inputs. This is load-bearing for the adaptive allocation rule and the claim that it delivers consistent gains without per-deployment retuning.
- [§4] §4 (evaluation): the reported 5.43% accuracy gain is presented without details on exact baselines, number of runs, statistical significance testing, or cross-task/model validation. This directly affects assessment of the central claim, especially given the skeptic concern that optimal block sizes may shift with task (e.g., retrieval vs. summarization) or model scale.
minor comments (1)
- [Abstract, §3.2] The abstract and method description could more explicitly state the precise definition of 'block centroid quantization' and how losslessness is verified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the sensitivity analysis and evaluation details require expansion for clarity and reproducibility. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (analysis of head sensitivity): the manuscript states that 'analysis revealed varying head sensitivity' and that uniformity is suboptimal, but provides no description of the measurement method, sensitivity metric, data used, or quantitative stability across inputs. This is load-bearing for the adaptive allocation rule and the claim that it delivers consistent gains without per-deployment retuning.
Authors: We acknowledge that §3 currently lacks sufficient detail on the head sensitivity analysis. The analysis measures per-head accuracy sensitivity by comparing performance under uniform block sizes versus per-head adaptive sizes, using accuracy drop as the metric on long-context benchmarks. We will revise §3 to fully describe the sensitivity metric, the specific data and inputs used for the analysis, and add quantitative stability results (e.g., variance across multiple sequences) to show the allocation rule generalizes without retuning. revision: yes
-
Referee: [§4] §4 (evaluation): the reported 5.43% accuracy gain is presented without details on exact baselines, number of runs, statistical significance testing, or cross-task/model validation. This directly affects assessment of the central claim, especially given the skeptic concern that optimal block sizes may shift with task (e.g., retrieval vs. summarization) or model scale.
Authors: We agree that §4 requires additional experimental details. We will expand the section to specify the exact baselines and their configurations, report results over multiple runs with standard deviations and statistical significance tests, and include further cross-task validation on retrieval and summarization tasks along with results on additional model scales to address generalizability concerns. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper performs an empirical analysis of per-head sensitivity to block granularity, then introduces a training-free adaptive allocation rule plus supporting quantization and kernels. The reported accuracy gains (up to 5.43%) are measured outcomes on external benchmarks rather than quantities defined by the allocation rule itself. No equations reduce the final result to its inputs by construction, no load-bearing self-citations close the chain, and the central claim rests on independently verifiable system-level improvements rather than renaming or fitting. The approach is therefore non-circular under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Attention computation is dominated by a small subset of tokens
- domain assumption Attention heads exhibit widely varying sensitivity to block granularity
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[2]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Curiousllm: Elevating multi-document question answering with llm-enhanced knowledge graph reasoning
Zukang Yang, Zixuan Zhu, and Jennifer Zhu. Curiousllm: Elevating multi-document question answering with llm-enhanced knowledge graph reasoning. InProceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 3: Industry Track), pages 274–286, 2025
work page 2025
-
[5]
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, et al. Repoagent: An llm-powered open-source framework for repository-level code documentation generation.arXiv preprint arXiv:2402.16667, 2024
-
[6]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[7]
Meta. Llama-3.1-8b-instruct. https://huggingface.co/meta-llama/Llama-3. 1-8B-Instruct, 2024
work page 2024
-
[8]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
work page 2023
-
[10]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 155–172, 2024
work page 2024
-
[11]
Guangda Liu, Chengwei Li, Jieru Zhao, Chenqi Zhang, and Minyi Guo. Clusterkv: Manipulating llm kv cache in semantic space for recallable compression.arXiv preprint arXiv:2412.03213, 2024
-
[12]
RetroInfer: A Vector Storage Engine for Scalable Long-Context LLM Inference
Yaoqi Chen, Jinkai Zhang, Baotong Lu, Qianxi Zhang, Chengruidong Zhang, Jingjia Luo, Di Liu, Huiqiang Jiang, Qi Chen, Jing Liu, et al. Retroinfer: A vector-storage approach for scalable long-context llm inference.arXiv preprint arXiv:2505.02922, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[14]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37:62557–62583, 2024
work page 2024
-
[15]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. Flashinfer: Efficient and customizable attention engine for llm inference serving.Proceedings of Machine Learning and Systems, 7, 2025
work page 2025
-
[16]
arXiv preprint arXiv:2406.10774 , year=
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774, 2024
-
[17]
Renze Chen, Zhuofeng Wang, Beiquan Cao, Tong Wu, Size Zheng, Xiuhong Li, Xuechao Wei, Shengen Yan, Meng Li, and Yun Liang. Arkvale: Efficient generative llm inference with recallable key-value eviction.Advances in Neural Information Processing Systems, 37:113134– 113155, 2024
work page 2024
-
[18]
Duoattention: Efficient long-context LLM inference with retrieval and streaming heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819, 2024
-
[19]
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mecha- nistically explains long-context factuality.arXiv preprint arXiv:2404.15574, 2024
-
[20]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference...
work page 2017
-
[21]
GQA: training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. GQA: training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, 2023
work page 2023
-
[22]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems, 37:52481–52515, 2024
work page 2024
-
[23]
Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, et al. Retrievalattention: Accelerating long- context llm inference via vector retrieval.arXiv preprint arXiv:2409.10516, 2024
-
[24]
Mag- icpig: Lsh sampling for efficient llm generation.arXiv preprint arXiv:2410.16179,
Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, et al. Magicpig: Lsh sampling for efficient llm generation.arXiv preprint arXiv:2410.16179, 2024
-
[25]
Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, et al. Moba: Mixture of block attention for long-context llms. arXiv preprint arXiv:2502.13189, 2025
-
[26]
Qwen3-8b.https://huggingface.co/Qwen/Qwen3-8B, 2025
Qwen. Qwen3-8b.https://huggingface.co/Qwen/Qwen3-8B, 2025
work page 2025
- [27]
-
[28]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Qwen3-32b.https://huggingface.co/Qwen/Qwen3-32B, 2025
Qwen. Qwen3-32b.https://huggingface.co/Qwen/Qwen3-32B, 2025
work page 2025
-
[30]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
work page 2024
-
[31]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[32]
Guangda Liu, Chengwei Li, Zhenyu Ning, Jing Lin, Yiwu Yao, Danning Ke, Minyi Guo, and Jieru Zhao. Freekv: Boosting kv cache retrieval for efficient llm inference.arXiv preprint arXiv:2505.13109, 2025
-
[33]
PRKV:page restruct KV cache for high accuracy and efficiency LLM generation, 2026
Fang Wu, Congming Gao, Weixi Zhu, and Jiwu Shu. PRKV:page restruct KV cache for high accuracy and efficiency LLM generation, 2026
work page 2026
-
[34]
Art of Problem Solving. Aime problems and solutions. https://artofproblemsolving. com/wiki/index.php/AIME_Problems_and_Solutions, 2024
work page 2024
-
[35]
Art of Problem Solving. Amc problems and solutions. https://artofproblemsolving. com/wiki/index.php?title=AMC_Problems_and_Solutions, 2023
work page 2023
-
[36]
Let’s verify step by step, 2023
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023
work page 2023
-
[37]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.