Recognition: 2 theorem links
· Lean TheoremKeeping Score: Efficiency Improvements in Neural Likelihood Surrogate Training via Score-Augmented Loss Functions
Pith reviewed 2026-05-13 04:01 UTC · model grok-4.3
The pith
Augmenting loss functions with score gradients improves neural likelihood surrogates at lower cost than more simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By augmenting the binary cross-entropy loss with the exact score ∇_θ log p(x | θ) and adaptive weighting based on loss gradients, neural likelihood surrogates achieve improved quality for stochastic process models at drastically lower computational cost than generating additional training data.
What carries the argument
The score-augmented loss, which combines standard binary cross-entropy with terms using the exact gradient of the log-likelihood with respect to parameters θ.
Load-bearing premise
Exact score information, the gradient of the log-likelihood with respect to parameters, is available and computable for the models being studied.
What would settle it
A direct comparison showing that the augmented loss does not improve surrogate performance or downstream inference beyond what additional data provides would falsify the efficiency claim.
Figures

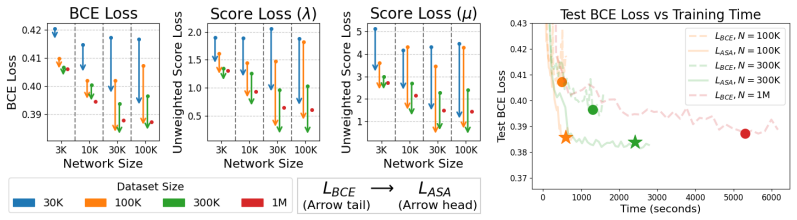






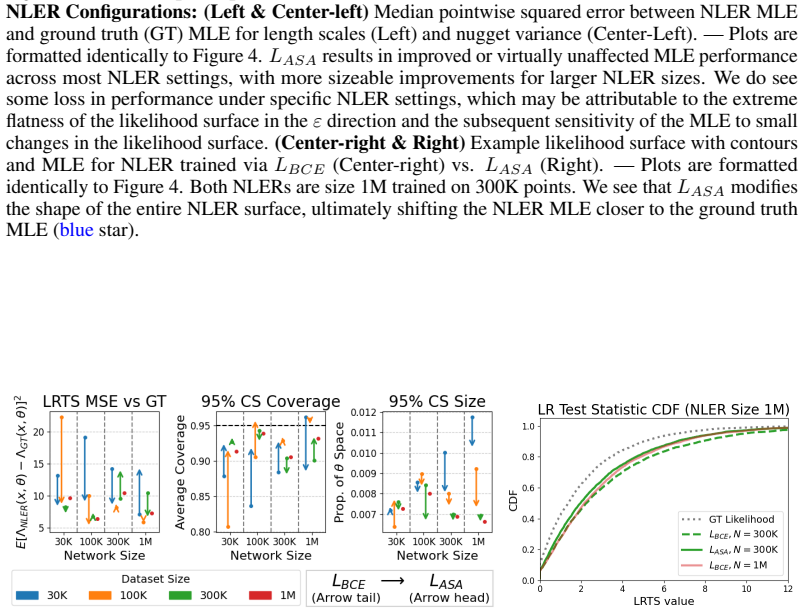





read the original abstract
For stochastic process models, parameter inference is often severely bottlenecked by computationally expensive likelihood functions. Simulation-based inference (SBI) bypasses this restriction by constructing amortized surrogate likelihoods, but most SBI methods assume a black-box data generating process. While these surrogates are exact in the limit of infinite training data, practical scenarios force a strict tradeoff between model quality and simulation cost. In this work, we loosen the black-box assumption of SBI to improve this tradeoff for structured stochastic process models. Specifically, for neural network likelihood surrogates trained via probabilistic classification, we propose to augment the standard binary cross-entropy loss with exact score information $\nabla_\theta \log p(x \mid \theta)$ and adaptive weighting based on loss gradients. We evaluate our approach on case studies involving network dynamics and spatial processes, demonstrating that our method improves surrogate quality at a drastically lower computational cost than generating more training data. Notably, in some cases, our approach achieves downstream inference performance equivalent to a 10x increase in training data with less than a 1.1x increase in training time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes augmenting the binary cross-entropy loss used to train neural likelihood surrogates in simulation-based inference with exact score information ∇_θ log p(x | θ) together with adaptive weighting derived from loss gradients. The approach is targeted at structured stochastic process models for which the score is computable, and is evaluated on case studies involving network dynamics and spatial processes. The central empirical claim is that the resulting surrogates achieve downstream inference performance equivalent to a 10× increase in training data while incurring less than a 1.1× increase in training time.
Significance. If the reported efficiency gains are robust, the work provides a practical way to improve the simulation-data versus compute tradeoff in SBI for models that admit exact score evaluation. This loosens the strict black-box assumption in a controlled manner and could reduce the simulation budgets required for accurate amortized inference in domains such as network dynamics and spatial statistics.
minor comments (3)
- [§3.2] §3.2: the precise form of the adaptive weighting term (how loss-gradient magnitudes are normalized and combined with the score term) is not stated explicitly enough for immediate reproduction; an equation or pseudocode block would help.
- [§4.1] §4.1 and Table 1: the time measurements should clarify whether score computation overhead is included in the reported 1.1× factor and whether the 10× data baseline uses the same network architecture and optimization schedule.
- The manuscript would benefit from a short discussion of the computational cost of obtaining the exact score for the two case-study models, even if this cost is assumed to be negligible relative to simulation.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work and for recommending minor revision. We are encouraged that the efficiency gains from score-augmented losses for neural likelihood surrogates in structured stochastic process models are viewed as potentially impactful for loosening the black-box assumption in SBI in a controlled way.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a score-augmented binary cross-entropy loss for training neural likelihood surrogates, using exact score information as an explicit additional input for structured models where it is available. All reported performance gains (including the 10x data equivalence claim) are empirical outcomes from controlled experiments on network dynamics and spatial processes, comparing the modified training procedure against standard baselines with matched simulation budgets. No step in the method or evaluation reduces by construction to a fitted parameter, self-citation chain, or renamed input; the black-box loosening is stated upfront and the results are qualified as holding in some cases. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Exact score ∇_θ log p(x | θ) can be computed for the target structured stochastic processes
- domain assumption Neural network classifiers trained on simulated data can serve as amortized likelihood surrogates
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe propose an adaptively weighted augmentation to the BCE loss that directly incorporates the SPM score function ∇θ logp(x|θ)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearLASA = LBCE + LScore with LScore = Σ αi,k [∇θk hγ − ∇θk log p]^2
Reference graph
Works this paper leans on
-
[1]
Mogens Bladt and Michael Sørensen. Statistical inference for discretely observed markov jump processes.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(3):395–410, 2005. doi: https://doi.org/10.1111/j.1467-9868.2005.00508.x. URL https: //rss.onlinelibrary.wiley.com/doi/abs/10.1111/j.1467-9868.2005.00508.x
-
[2]
Jan Boelts, Philipp Harth, Richard Gao, Daniel Udvary, Felipe Yáñez, Daniel Baum, Hans- Christian Hege, Marcel Oberlaender, and Jakob H. Macke. Simulation-based inference for efficient identification of generative models in computational connectomics.PLOS Computational Biology, 19(9):1–28, 09 2023. doi: 10.1371/journal.pcbi.1011406. URL https://doi.org/10...
-
[3]
Johann Brehmer, Gilles Louppe, Juan Pavez, and Kyle Cranmer. Mining gold from implicit models to improve likelihood-free inference.Proceedings of the National Academy of Sciences, 117(10):5242–5249, 2020. doi: 10.1073/pnas.1915980117. URL https://www.pnas.org/ doi/abs/10.1073/pnas.1915980117
-
[4]
GradNorm: Gra- dient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. GradNorm: Gra- dient normalization for adaptive loss balancing in deep multitask networks. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 794–803. PMLR, 10–15 Jul...
work page 2018
-
[5]
The frontier of simulation-based inference
Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference. Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020. doi: 10.1073/ pnas.1912789117. URLhttps://www.pnas.org/doi/abs/10.1073/pnas.1912789117
-
[6]
A.E. Gelfand, M. Fuentes, P. Guttorp, and P. Diggle.Handbook of Spatial Statistics. Chapman & Hall/CRC Handbooks of Modern Statistical Methods. Taylor & Francis, 2010. ISBN 9781420072877. URLhttp://books.google.com/books?id=EFbbcMFZ2mMC
work page 2010
-
[7]
Florian Gerber and Doug Nychka. Fast covariance parameter estimation of spatial gaussian process models using neural networks.Stat, 10, 04 2021. doi: 10.1002/sta4.382
-
[8]
Aishik Ghosh, Maximilian Griese, Ulrich Haisch, and Tae Hyoun Park. Neural simulation-based inference of the higgs trilinear self-coupling via off-shell higgs production.Eur. Phys. J. C Part. Fields, 86(4), April 2026
work page 2026
-
[9]
Likelihood-free MCMC with amortized approximate ratio estimators
Joeri Hermans, V olodimir Begy, and Gilles Louppe. Likelihood-free MCMC with amortized approximate ratio estimators. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 4239–4248. PMLR, 13–18 Jul 2020. URL https://proceedings. mlr.press...
work page 2020
-
[10]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Amanda Lenzi, Julie Bessac, Johann Rudi, and Michael L. Stein. Neural networks for parameter estimation in intractable models.Computational Statistics & Data Analysis, 185:107762,
-
[12]
doi: https://doi.org/10.1016/j.csda.2023.107762
ISSN 0167-9473. doi: https://doi.org/10.1016/j.csda.2023.107762. URL https://www. sciencedirect.com/science/article/pii/S0167947323000737
-
[13]
Curran Associates Inc., Red Hook, NY , USA, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala.PyTorch: an imperative style, high-performan...
work page 2019
-
[14]
Jordan Richards, Matthew Sainsbury-Dale, Andrew Zammit-Mangion, and Raphaël Huser. Neural bayes estimators for censored inference with peaks-over-threshold models.Journal of Machine Learning Research, 25(390):1–49, 2024. URL http://jmlr.org/papers/v25/ 23-1134.html. 10
work page 2024
-
[15]
Matthew Sainsbury-Dale, Andrew Zammit-Mangion, Jordan Richards, and Raphaël Huser. Neural bayes estimators for irregular spatial data using graph neural networks.Journal of Computational and Graphical Statistics, 34(3):1153–1168, 2025
work page 2025
-
[16]
Neural parameter estimation with incomplete data, 2026
Matthew Sainsbury-Dale, Andrew Zammit-Mangion, Noel Cressie, and Raphaël Huser. Neural parameter estimation with incomplete data, 2026. URL https://arxiv.org/abs/2501. 04330
work page 2026
-
[17]
Student-t Processes as Alternatives to Gaussian Processes
Amar Shah, Andrew Wilson, and Zoubin Ghahramani. Student-t Processes as Alternatives to Gaussian Processes. In Samuel Kaski and Jukka Corander, editors,Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, volume 33 of Proceedings of Machine Learning Research, pages 877–885, Reykjavik, Iceland, 22–25 Apr
-
[18]
URLhttps://proceedings.mlr.press/v33/shah14.html
PMLR. URLhttps://proceedings.mlr.press/v33/shah14.html
-
[19]
Deep calibration of market simulations using neural density es- timators and embedding networks
Namid R Stillman, Rory Baggott, Justin Lyon, Jianfei Zhang, Dingqui Zhu, Tao Chen, and Perukrishnen Vytelingum. Deep calibration of market simulations using neural density es- timators and embedding networks. InProceedings of the Fourth ACM International Con- ference on AI in Finance, ICAIF ’23, page 46–54, New York, NY , USA, 2023. Association for Comput...
-
[20]
Julia Walchessen, Amanda Lenzi, and Mikael Kuusela. Neural likelihood surfaces for spatial processes with computationally intensive or intractable likelihoods.Spatial Statistics, 62: 100848, 2024. ISSN 2211-6753. doi: https://doi.org/10.1016/j.spasta.2024.100848. URL https://www.sciencedirect.com/science/article/pii/S2211675324000393
-
[21]
Sis epidemic propagation on scale-free hypernet- work.Applied Sciences, 12(21), 2022
Kaijun Wang, Yunchao Gong, and Feng Hu. Sis epidemic propagation on scale-free hypernet- work.Applied Sciences, 12(21), 2022. ISSN 2076-3417. doi: 10.3390/app122110934. URL https://www.mdpi.com/2076-3417/12/21/10934
-
[22]
Andrew Zammit-Mangion, Matthew Sainsbury-Dale, and Raphaël Huser. Neural meth- ods for amortized inference.Annual Review of Statistics and Its Application, 12 (V olume 12, 2025):311–335, 2025. ISSN 2326-831X. doi: https://doi.org/10.1146/ annurev-statistics-112723-034123. URL https://www.annualreviews.org/content/ journals/10.1146/annurev-statistics-112723-034123
-
[23]
Neural posterior estimation with differentiable simulators, 2022
Justine Zeghal, François Lanusse, Alexandre Boucaud, Benjamin Remy, and Eric Aubourg. Neural posterior estimation with differentiable simulators, 2022. URL https://arxiv.org/ abs/2207.05636. 11 A Derivations for NLER training via binary classification A neural likelihood-to-evidence ratio estimator attempts to approximate p(x|θ) p(x) (or some simple trans...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.