Recognition: 1 theorem link
· Lean TheoremPoseCompass: Intelligent Synthetic Pose Selection for Visual Localization
Pith reviewed 2026-05-13 07:22 UTC · model grok-4.3
The pith
PoseCompass selects synthetic poses by ranking them on difficulty, novelty and render quality to cut visual localization adaptation time by two-thirds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
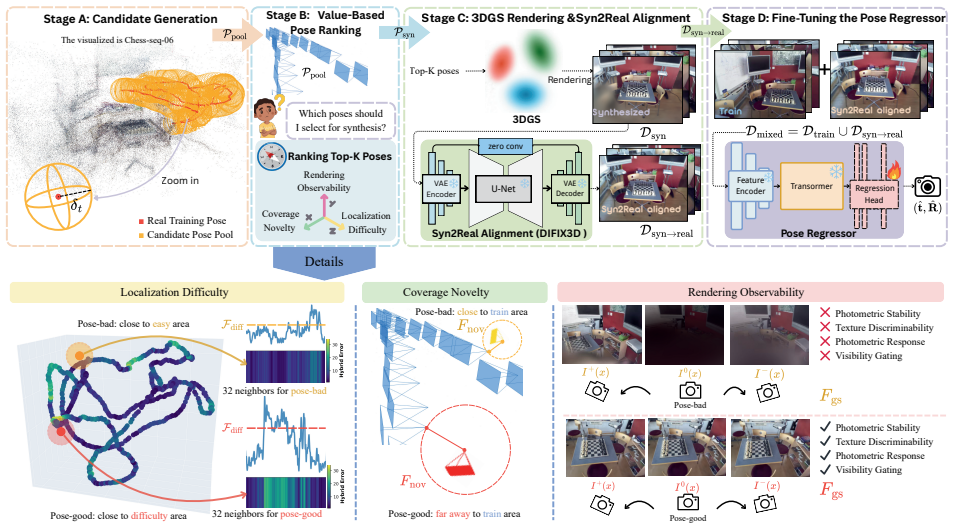
PoseCompass formulates synthetic pose selection as a value-based ranking task whose three components—Localization Difficulty, Coverage Novelty, and Rendering Observability—together identify the most informative views for augmenting absolute pose regression training data.
What carries the argument
The value-based pose ranking mechanism that scores trajectory-constrained candidates on the three dimensions of Localization Difficulty, Coverage Novelty and Rendering Observability before selecting the top-K poses for 3DGS synthesis and diffusion alignment.
If this is right
- Fine-tuning of absolute pose regressors can be completed with far fewer synthetic images while still improving accuracy.
- Mixed real-plus-synthetic training sets become practical for rapid scene adaptation in robotics and AR.
- Trajectory-constrained candidate generation keeps selected poses geometrically consistent with the real capture path.
- The method is compatible with existing 3DGS reconstructions without requiring changes to the underlying scene representation.
Where Pith is reading between the lines
- The same ranking dimensions could be applied to other synthetic-data pipelines that use neural rendering for camera-pose tasks.
- If the ranking proves robust across reconstruction qualities, it may reduce the need for manual data curation in visual localization deployments.
- Extending the observability term to account for lighting variation or dynamic objects would be a direct next test.
Load-bearing premise
The three-dimensional ranking reliably picks the most useful synthetic poses without scene-specific tuning or being misled by reconstruction errors in the underlying 3D Gaussian Splatting model.
What would settle it
On a new scene the top-K poses chosen by the ranking produce equal or higher median pose error than an equal number of randomly chosen poses after the same number of fine-tuning epochs.
Figures

read the original abstract
In visual localization, Absolute Pose Regression (APR) enables real-time 6-DoF camera pose inference from single images, yet critically depends on fine-tuning data quality and coverage. While recent methods leverage 3D Gaussian Splatting (3DGS) for novel view synthesis-based data augmentation, random sampling generates redundant views and noisy samples from poorly reconstructed regions. To mitigate this research gap, we propose PoseCompass, an intelligent pose selection pipeline for 3DGS-based APR. PoseCompass formulates synthetic pose selection and derives a value-based pose ranking mechanism to identify informative poses. The ranking integrates three dimensions: Localization Difficulty, favoring challenging regions; Coverage Novelty, exploring under-sampled areas; and Rendering Observability, filtering artifacts and noise. PoseCompass then generates trajectory-constrained candidates, selects the top-K ranked poses, and synthesizes views using 3DGS with lightweight diffusion-based alignment. Finally, the pose regressor is fine-tuned on mixed real and synthetic data. We evaluate PoseCompass on 7-Scenes, where it reduces adaptation time from 15.2 to 5.1 minutes, a 3x speedup, while cutting median pose errors by 53.8 percent and significantly outperforming random baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PoseCompass, a pipeline for intelligent selection of synthetic poses generated via 3D Gaussian Splatting to augment training data for Absolute Pose Regression (APR) in visual localization. It introduces a value-based ranking mechanism combining Localization Difficulty (favoring challenging regions), Coverage Novelty (exploring under-sampled areas), and Rendering Observability (filtering artifacts), then selects top-K poses for synthesis with diffusion-based alignment before fine-tuning the regressor on mixed real and synthetic data. Evaluation on 7-Scenes reports reduction of adaptation time from 15.2 to 5.1 minutes (3x speedup) and 53.8% lower median pose error versus random baselines.
Significance. If the ranking mechanism proves robust and generalizable beyond the reported scenes, the work could meaningfully improve data efficiency in APR fine-tuning by replacing random sampling with targeted synthetic views, reducing both collection time and error rates in real-time localization systems. The integration of 3DGS with trajectory-constrained candidates and lightweight alignment is a practical strength.
major comments (3)
- [Abstract] Abstract: the central performance claims (3x speedup, 53.8% median error reduction, outperformance over random baselines) are stated without any formulas, weighting scheme, or hyperparameter values for the three ranking dimensions (Localization Difficulty, Coverage Novelty, Rendering Observability), nor any ablation that fixes the number of poses and varies only the ranking function. This leaves the load-bearing contribution of the value-based selection unverified.
- [Abstract] Abstract and evaluation section: no error bars, statistical significance tests, or details on the exact baselines (beyond random) and how the three ranking scores are computed are supplied, so it is impossible to determine whether the reported gains are load-bearing or could arise from 3DGS reconstruction quality on the specific 7-Scenes test scenes.
- [Abstract] The manuscript does not address whether any component of the ranking (e.g., difficulty thresholds or novelty distance metric) was tuned after inspecting 7-Scenes results, which would introduce a circularity risk between the selection criteria and the final test metric.
minor comments (1)
- [Abstract] The abstract mentions 'lightweight diffusion-based alignment' without specifying the diffusion model, alignment objective, or computational overhead, which should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We have revised the manuscript to incorporate additional details on the ranking mechanism, evaluation protocols, and experimental design as requested. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (3x speedup, 53.8% median error reduction, outperformance over random baselines) are stated without any formulas, weighting scheme, or hyperparameter values for the three ranking dimensions (Localization Difficulty, Coverage Novelty, Rendering Observability), nor any ablation that fixes the number of poses and varies only the ranking function. This leaves the load-bearing contribution of the value-based selection unverified.
Authors: We agree that the abstract omits these specifics due to length constraints. In the revised manuscript we have updated the abstract to note that the three dimensions are combined with equal weights (w=1/3 each) and added Section 3.3 with the exact formulas: Localization Difficulty as normalized pose-estimator entropy, Coverage Novelty as 1 minus cosine similarity to the empirical pose distribution, and Rendering Observability as the fraction of high-density 3DGS points. Hyperparameters (K=80, thresholds) are listed in Table 1. We also added an ablation (Table 4) that fixes the pose count at 80 and compares the full ranking against single-dimension and random variants, confirming the combined ranking drives the gains. revision: yes
-
Referee: [Abstract] Abstract and evaluation section: no error bars, statistical significance tests, or details on the exact baselines (beyond random) and how the three ranking scores are computed are supplied, so it is impossible to determine whether the reported gains are load-bearing or could arise from 3DGS reconstruction quality on the specific 7-Scenes test scenes.
Authors: We accept this point. The revision adds standard-deviation error bars to all metrics in Tables 2–3 and reports paired t-test p-values (all <0.01) for the improvements. The random baseline is now explicitly uniform sampling from the identical trajectory-constrained candidate set used by PoseCompass. Section 4.2 now provides the precise score equations and any fixed thresholds, allowing readers to separate selection effects from 3DGS reconstruction quality. revision: yes
-
Referee: [Abstract] The manuscript does not address whether any component of the ranking (e.g., difficulty thresholds or novelty distance metric) was tuned after inspecting 7-Scenes results, which would introduce a circularity risk between the selection criteria and the final test metric.
Authors: We have added a dedicated paragraph in Section 4.1 stating that all ranking hyperparameters and thresholds were fixed using a held-out validation split of 7-Scenes before any test-set evaluation. No post-hoc adjustments were performed on test results. Validation-set performance curves are now included in the supplement to document the selection process. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper defines the three-dimensional ranking (Localization Difficulty, Coverage Novelty, Rendering Observability) as independent inputs to the selection pipeline before any fine-tuning or evaluation occurs. Performance metrics (adaptation time, median pose error) are computed on held-out 7-Scenes test data after applying the ranked synthetic views, with no equations or steps that reduce the reported gains back to a fit on the same quantities or a self-referential definition. The ranking criteria are stated at the level of qualitative dimensions without formulas that embed the target error metric, and no self-citation chain is invoked to justify uniqueness or load-bearing assumptions. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
V(P) = e^{F_diff(P)^α} × (1 + e^{F_nov(P)})^β × e^{F_gs(P)^γ}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Posenet: A convolutional network for real-time 6-dof camera relocalization,
Alex Kendall, Matthew Grimes, and Roberto Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2938–2946
work page 2015
-
[2]
Geometry-aware learning of maps for camera localization,
Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, and Jan Kautz, “Geometry-aware learning of maps for camera localization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 2616–2625
work page 2018
-
[3]
Map-relative pose regression for visual re-localization,
Shuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu, and Eric Brachmann, “Map-relative pose regression for visual re-localization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20665–20674
work page 2024
-
[4]
Adversarial exploitation of data diversity improves visual localization,
Sihang Li, Siqi Tan, Bowen Chang, Jing Zhang, Chen Feng, and Yiming Li, “Adversarial exploitation of data diversity improves visual localization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 26848–26858
work page 2025
-
[5]
Superglue: Learning feature matching with graph neural networks,
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich, “Superglue: Learning feature matching with graph neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 4938–4947
work page 2020
-
[6]
Light- glue: Local feature matching at light speed,
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Pollefeys, “Light- glue: Local feature matching at light speed,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17627–17638
work page 2023
-
[7]
Complete solution classification for the perspective-three-point prob- lem,
Xiao-Shan Gao, Xiao-Rong Hou, Jianliang Tang, and Hang-Fei Cheng, “Complete solution classification for the perspective-three-point prob- lem,”IEEE transactions on pattern analysis and machine intelligence, vol. 25, no. 8, pp. 930–943, 2003
work page 2003
-
[8]
Understanding the limitations of cnn-based absolute camera pose regression,
Torsten Sattler, Qunjie Zhou, Marc Pollefeys, and Laura Leal-Taixe, “Understanding the limitations of cnn-based absolute camera pose regression,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3302–3312
work page 2019
-
[9]
Lens: Localization enhanced by nerf synthesis,
Arthur Moreau, Nathan Piasco, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle, “Lens: Localization enhanced by nerf synthesis,” inProceedings of the Conference on Robot Learning. PMLR, 2022, pp. 1347–1356
work page 2022
-
[10]
Dfnet: Enhance absolute pose regression with direct feature matching,
Shuai Chen, Xinghui Li, Zirui Wang, and Victor A Prisacariu, “Dfnet: Enhance absolute pose regression with direct feature matching,” in European Conference on Computer Vision. Springer, 2022, pp. 1–17
work page 2022
-
[11]
Nerf: Representing scenes as neural radiance fields for view synthesis,
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” inProceedings of the European Conference on Computer Vision. Springer, 2020, pp. 405–421
work page 2020
-
[12]
3d gaussian splatting for real-time radiance field rendering.,
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis, “3d gaussian splatting for real-time radiance field rendering.,” ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
work page 2023
-
[13]
Deep batch active learning by diverse, uncertain gradient lower bounds,
Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal, “Deep batch active learning by diverse, uncertain gradient lower bounds,” 2019
work page 2019
-
[14]
Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses,
Eric Brachmann, Tommaso Cavallari, and Victor Adrian Prisacariu, “Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5044–5053
work page 2023
-
[15]
Scene coordinate regression forests for camera relocalization in rgb-d images,
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon, “Scene coordinate regression forests for camera relocalization in rgb-d images,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 2930– 2937
work page 2013
-
[16]
Dsac-differentiable ransac for camera localization,
Eric Brachmann, Alexander Krull, Sebastian Nowozin, Jamie Shotton, Frank Michel, Stefan Gumhold, and Carsten Rother, “Dsac-differentiable ransac for camera localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6684–6692
work page 2017
-
[17]
Glace: Global local accelerated coordinate encoding,
Fangjinhua Wang, Xudong Jiang, Silvano Galliani, Christoph V ogel, and Marc Pollefeys, “Glace: Global local accelerated coordinate encoding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21562–21571
work page 2024
-
[18]
Visual camera re-localization from rgb and rgb-d images using dsac,
Eric Brachmann and Carsten Rother, “Visual camera re-localization from rgb and rgb-d images using dsac,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 9, pp. 5847–5865, 2021
work page 2021
-
[19]
Geometric loss functions for camera pose regression with deep learning,
Alex Kendall and Roberto Cipolla, “Geometric loss functions for camera pose regression with deep learning,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5974– 5983
work page 2017
-
[20]
Coordinet: uncertainty-aware pose regressor for reliable vehicle localization,
Arthur Moreau, Nathan Piasco, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle, “Coordinet: uncertainty-aware pose regressor for reliable vehicle localization,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 2229–2238
work page 2022
-
[21]
Direct-posenet: Abso- lute pose regression with photometric consistency,
Shuai Chen, Zirui Wang, and Victor Prisacariu, “Direct-posenet: Abso- lute pose regression with photometric consistency,” in2021 International Conference on 3D Vision (3DV). IEEE, 2021, pp. 1175–1185
work page 2021
-
[22]
Learning neural volumetric pose features for camera localization,
Jingyu Lin, Jiaqi Gu, Bojian Wu, Lubin Fan, Renjie Chen, Ligang Liu, and Jieping Ye, “Learning neural volumetric pose features for camera localization,” pp. 198–214, 2024
work page 2024
-
[23]
Learning multi-scene absolute pose regression with transformers,
Yoli Shavit, Ron Ferens, and Yosi Keller, “Learning multi-scene absolute pose regression with transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2733–2742
work page 2021
-
[24]
Camera pose auto-encoders for improving pose regression,
Yoli Shavit and Yosi Keller, “Camera pose auto-encoders for improving pose regression,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 140–157
work page 2022
-
[25]
Difix3d+: Improving 3d reconstructions with single-step diffusion models,
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling, “Difix3d+: Improving 3d reconstructions with single-step diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 26024–26035
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.