Recognition: no theorem link
MM-OptBench: A Solver-Grounded Benchmark for Multimodal Optimization Modeling
Pith reviewed 2026-05-13 05:46 UTC · model grok-4.3
The pith
Multimodal models must generate both optimization formulations and solver code from text plus visual inputs, yet top performers solve only about half the cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
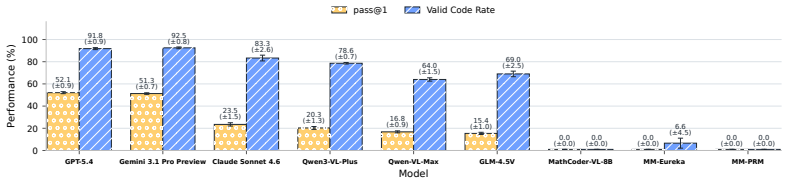
We introduce a solver-grounded framework that generates structured optimization instances, verifies each instance with an exact solver, and derives both the visible multimodal inputs and hidden reference solutions from the same verified source; instantiating this framework yields MM-OptBench with 780 instances spanning six families and three difficulty tiers, on which the strongest evaluated models achieve 52.1 percent and 51.3 percent pass@1 while math-specialized models solve zero instances.
What carries the argument
The solver-grounded instance generation and verification framework that produces both the model-facing multimodal inputs and the hidden reference files from the same verified optimization source.
Load-bearing premise
The 780 solver-verified instances together with the selected visual artifacts are representative of the range and difficulty of multimodal optimization tasks that arise in operational practice.
What would settle it
A single multimodal model that produces correct, solver-executable code for more than 60 percent of the hard instances in MM-OptBench would indicate that the reported performance ceiling has been exceeded.
Figures















read the original abstract
Optimization modeling translates real decision-making problems into mathematical optimization models and solver-executable implementations. Although language models are increasingly used to generate optimization formulations and solver code, existing benchmarks are almost entirely text-only. This omits many optimization-modeling tasks that arise in operational practice, where requirements are described in text but instance information is conveyed through visual artifacts such as tables, graphs, maps, schedules, and dashboards. We introduce multimodal optimization modeling, a benchmark setting in which models must construct both a mathematical formulation and executable solver code from a text-and-visual problem specification. To evaluate this setting, we develop a solver-grounded framework that generates structured optimization instances, verifies each with an exact solver, and builds both the model-facing inputs and hidden reference files from the same verified source. We instantiate the framework as MM-OptBench, a benchmark of 780 solver-verified instances spanning 6 optimization families, 26 subcategories, and 3 structural difficulty levels. We evaluate 9 multimodal large language models (MLLMs), including 6 frontier general-purpose models and 3 math-specialized models, with aggregate, family-level, difficulty-level, and failure-mode analyses. The results show that the task remains far from solved: the best two models reach 52.1% and 51.3% pass@1, while on average across the six general-purpose MLLMs, pass@1 is 43.4% on easy instances and 15.9% on hard instances. All three math-specialized MLLMs solve 0/780 instances. Failure attribution shows that errors arise both when extracting instance data from text and visuals and when turning extracted data into solver-correct formulations and code. MM-OptBench provides a testbed for solver-grounded, decision-oriented multimodal intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces multimodal optimization modeling as a benchmark task requiring MLLMs to produce both mathematical formulations and executable solver code from combined text-and-visual problem specifications. It presents a solver-grounded generation framework that creates verified optimization instances, derives inputs and hidden references from them, and instantiates this as MM-OptBench (780 instances across 6 families, 26 subcategories, and 3 difficulty levels). Evaluation of 9 MLLMs shows top general-purpose models at 52.1% and 51.3% pass@1, average 43.4% on easy vs. 15.9% on hard instances, and 0/780 for math-specialized models, with failure-mode analysis attributing errors to data extraction and formulation steps.
Significance. If the instances are faithfully constructed and representative, the benchmark fills a clear gap in text-only optimization modeling evaluations by incorporating visual artifacts common in practice. The solver-verified construction and pass@1 protocol with failure attribution provide a reproducible, decision-oriented testbed that could usefully guide MLLM development for operational tasks. The reported performance gaps (especially the complete failure of math-specialized models) are a concrete, falsifiable signal of current limitations.
major comments (3)
- [§3] §3 (Framework description): The generation pipeline for visual artifacts (tables, graphs, maps, etc.) from the verified instances is described at a high level but lacks sufficient detail on rendering choices, data embedding, and verification that the visuals are unambiguous and solver-consistent; this directly affects whether the 780 instances can be trusted as a reliable testbed for multimodal extraction.
- [§4.2] §4.2 (Instance statistics and difficulty split): The criteria and thresholds used to assign the three structural difficulty levels are not specified, so the reported easy/hard performance differential (43.4% vs 15.9%) cannot be independently assessed or replicated.
- [§5.1] §5.1 (Evaluation protocol): The exact definition of pass@1 (including whether partial credit, multiple attempts, or post-processing of generated code is allowed) and the solver used for verification are not stated, undermining the headline aggregate numbers and the claim that math-specialized models solve 0/780.
minor comments (3)
- [§1] The abstract and §1 claim the benchmark spans 'real-world' tasks, but the paper does not quantify how the chosen families and visual styles map to operational practice; a short discussion or citation to domain sources would strengthen this.
- [Table 1] Table 1 (or equivalent instance summary table) should include per-family counts and example visual types to allow readers to judge coverage.
- [§5.3] Failure-mode examples in §5.3 are useful but would benefit from one or two concrete input-output pairs showing a correct vs. incorrect extraction step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that several sections require additional clarification to ensure reproducibility and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Framework description): The generation pipeline for visual artifacts (tables, graphs, maps, etc.) from the verified instances is described at a high level but lacks sufficient detail on rendering choices, data embedding, and verification that the visuals are unambiguous and solver-consistent; this directly affects whether the 780 instances can be trusted as a reliable testbed for multimodal extraction.
Authors: We acknowledge that §3 provides only a high-level overview of the visual artifact generation. In the revised manuscript we will expand this section with concrete details on rendering parameters (e.g., table styles, graph layouts, map projections), data-embedding procedures, and the automated checks that confirm each visual is unambiguous and produces the same solver input as the hidden reference. We will also include pseudocode and representative examples for each artifact type. revision: yes
-
Referee: [§4.2] §4.2 (Instance statistics and difficulty split): The criteria and thresholds used to assign the three structural difficulty levels are not specified, so the reported easy/hard performance differential (43.4% vs 15.9%) cannot be independently assessed or replicated.
Authors: We agree that the difficulty assignment rules must be stated explicitly. The revision will add a dedicated subsection describing the structural metrics (number of decision variables, constraints, and visual elements) together with the exact thresholds used to label instances as easy, medium, or hard. This will enable independent replication of the split and direct assessment of the performance gap. revision: yes
-
Referee: [§5.1] §5.1 (Evaluation protocol): The exact definition of pass@1 (including whether partial credit, multiple attempts, or post-processing of generated code is allowed) and the solver used for verification are not stated, undermining the headline aggregate numbers and the claim that math-specialized models solve 0/780.
Authors: We will clarify the evaluation protocol in the revised §5.1. Pass@1 is defined as the fraction of instances for which the first generated response produces code that, when executed by the solver on the provided instance data, returns the exact optimal objective value; no partial credit, no multiple attempts, and no post-processing are permitted. We will also name the solver (Gurobi 10.0) and version used for all verification runs. These additions directly support the reported aggregate figures and the zero-success result for math-specialized models. revision: yes
Circularity Check
No significant circularity
full rationale
The paper constructs and evaluates MM-OptBench, a benchmark of 780 solver-verified multimodal optimization instances, without any mathematical derivations, fitted parameters, or predictions. The solver-grounded generation framework produces inputs and references from the same verified source, which is standard benchmark methodology rather than a self-referential reduction. Performance numbers (e.g., 52.1% pass@1 for best models) are direct empirical outcomes of running MLLMs on the benchmark, not outputs forced by the construction itself. No self-citations, uniqueness theorems, or ansatzes appear as load-bearing steps. The work is self-contained empirical research.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InEuropean conference on computer vision
A diagram is worth a dozen images. InEuropean conference on computer vision. Springer, 235–251. Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. 2017. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. InProceedings of the IEEE Conference on Computer V...
-
[2]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
COMET:“cone of experience” enhanced large multimodal model for mathematical problem generation.Science China Information Sciences67, 12 (2024), 220108. 11 Wentao Liu, Qianjun Pan, Yi Zhang, Zhuo Liu, Ji Wu, Jie Zhou, Aimin Zhou, Qin Chen, Bo Jiang, and Liang He. 2025. Cmm-math: A chinese multimodal math dataset to evaluate and enhance the mathematics reas...
work page Pith review arXiv 2024
-
[3]
study diagram and textbook reasoning, while ChartQA (Masry et al., 2022), ChartBench (Xu et al., 2023), DocVQA (Mathew et al., 2021), TableBench (Wu et al., 2025b), GRAB (Roberts et al., 2025), and SCIVER (Wang et al., 2025b) evaluate charts, documents, tables, graphs, and multimodal scientific evidence. These settings are especially relevant because opti...
work page 2022
-
[4]
Benchmark guideline specification.The process begins with a family-level design spec- ification that fixes the target difficulty regime, admissible scale, structural motifs, visual carrier, and readability constraints
-
[5]
Instance configuration sampling.The generator samples the discrete structure of a can- didate instance, such as graph topology, spatial layout, temporal horizon, routing regime, resource pattern, or logical sparsity pattern
-
[6]
Parameter instantiation.Numerical and categorical parameters are then assigned to the sampled structure, including costs, capacities, demands, processing times, coordinates, compatibility relations, or logical coefficients
-
[7]
Structural validation.Before solving, the candidate is checked for family-specific validity and nontriviality, such as connectivity, feasible coverage, admissible density, dimensional consistency, or meaningful resource conflict. This is the stage where LLM-assisted review is used to help experts surface possible semantic or structural inconsistencies; an...
-
[8]
Solver-grounded verification.Structurally valid candidates are translated into a reference optimization model or exact solving procedure. A candidate is retained only if the solver 25 certifies an optimal solution and records a benchmark-consistent objective value together with any family-specific solution object
-
[9]
Semantic artifact construction.For each verified candidate, the canonical specification, model-facing task text, mathematical formulation, reference solver, verified solution, and metadata are derived from the same verified instance data
-
[10]
Visual rendering and consistency check.Visual inputs are rendered from the same parameter source used by the reference model. Rendering checks verify label readability, correct annotation, cross-modal consistency, and absence of solution leakage
-
[11]
Quality evaluation and rejection–regeneration.Final checks assess difficulty alignment, structural diversity, solver consistency, artifact completeness, and multimodal consistency. Candidates that fail any check are rejected and regenerated until the target number of valid instances is collected. This shared protocol is what makes MM-OptBench scalable wit...
-
[12]
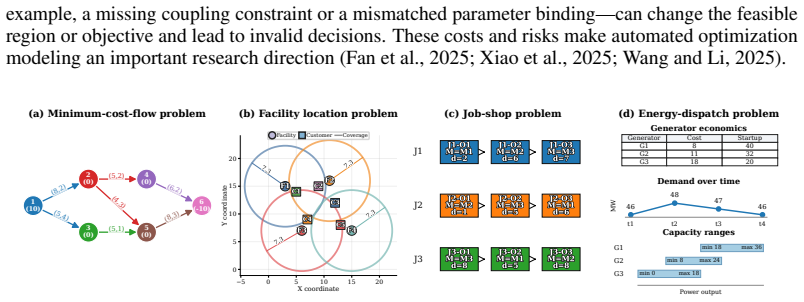
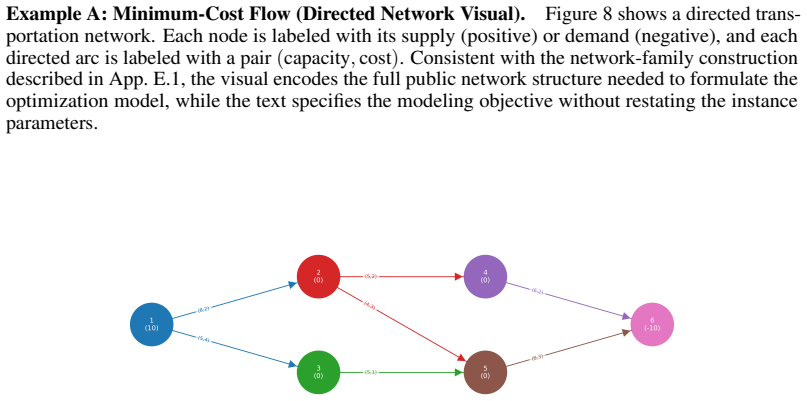
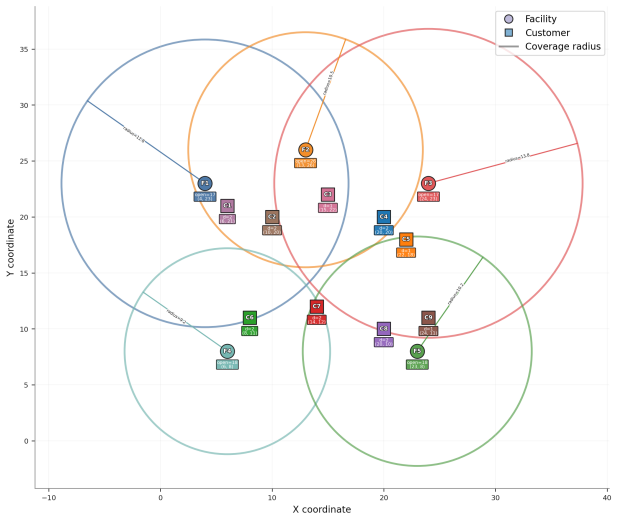
Objective: minimize total facility opening cost plus demand-weighted assignment cost
Provide solver-executable code implementing the model. Objective: minimize total facility opening cost plus demand-weighted assignment cost. Ground-truth notes.The corresponding math_model.md defines this example as a single-period uncapacitated facility-location problem with coverage-based assignment feasibility. The sets are F={F1, F2, F3, F4} for candi...
-
[13]
Objective: Minimize the makespan
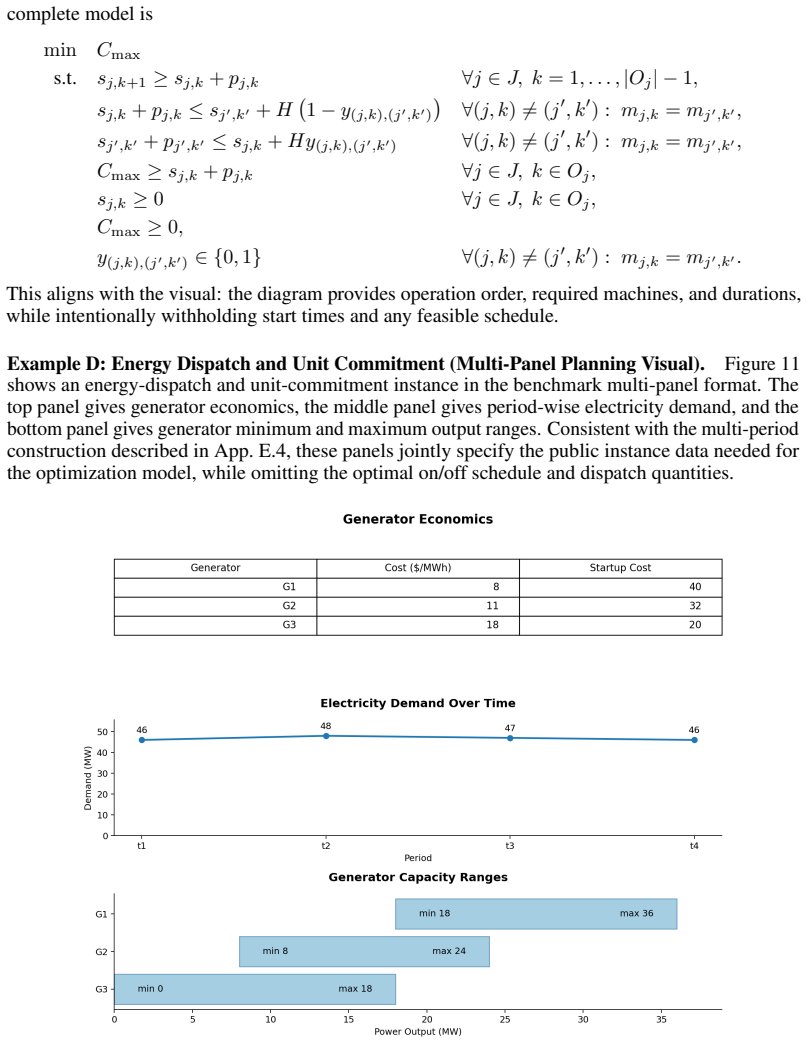
Provide solver-executable code implementing the model. Objective: Minimize the makespan. Ground-truth notes.The corresponding math_model.md defines a classical job-shop scheduling model with J={J1, J2, J3} , M={M1, M2, M3} , and ordered operation sets Oj. The instance- specific operations are J1 :O1(M1,2)→O2(M2,6)→O3(M3,7), J2 :O1(M2,1)→O2(M3,5)→O3(M1,6),...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.