Recognition: no theorem link
ReproBreak: A Dataset of Reproducible Web Locator Breaks
Pith reviewed 2026-05-13 04:02 UTC · model grok-4.3
The pith
A dataset of 449 reproducible web locator breaks is now available for GUI testing research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
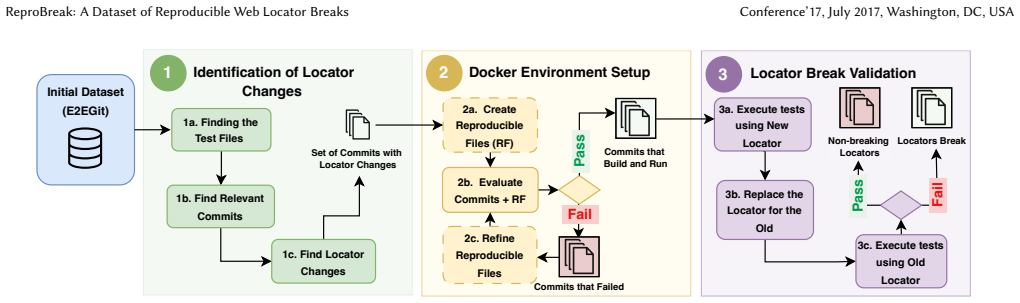
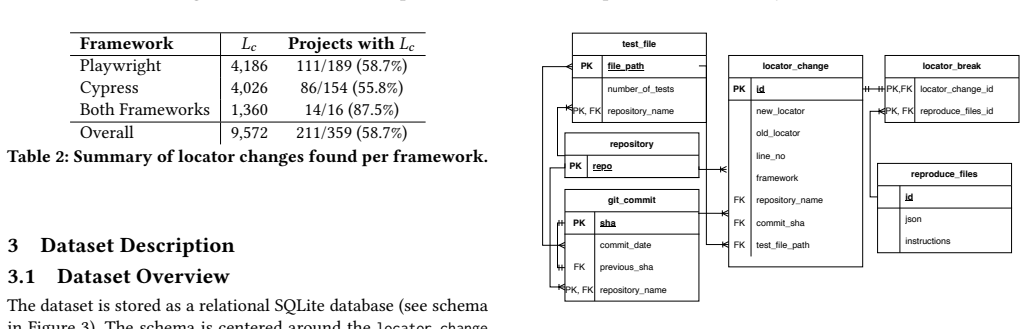
We present ReproBreak, a dataset of reproducible locator breaks in web application GUI tests. We analyzed 359 open-source repositories to identify commits that contain locator changes. To confirm whether these changes are indeed locator breaks, we reproduced them in the top 4 projects with the largest number of locator changes and found 449 locator breaks, which are provided in the dataset along with scripts for automated reproduction.
What carries the argument
The ReproBreak dataset of 449 validated locator breaks, each accompanied by reproduction scripts that automate the process of triggering the break in the original test environment.
If this is right
- Researchers can benchmark new locator repair techniques against the 449 real examples.
- The dataset supports quantitative studies of what structural changes most often cause locator fragility.
- Automated scripts enable repeatable experiments on test robustness across different frameworks.
- It provides a foundation for measuring how UI evolution affects long-term test maintenance effort.
Where Pith is reading between the lines
- The public release may allow the community to extend the dataset with breaks from additional projects or frameworks.
- Similar commit-mining and reproduction methods could be applied to study fragility in mobile or desktop GUI testing.
- The dataset makes it possible to compare the performance of manual locators against emerging AI-generated ones.
Load-bearing premise
That locator changes identified in commits from the analyzed repositories are genuine breaks caused by structural changes in the application rather than other reasons such as refactoring or feature updates.
What would settle it
Running the provided reproduction scripts on the top four projects and finding that far fewer than 449 cases produce actual locator breaks where the element cannot be found while the underlying functionality still works.
Figures


read the original abstract
Automated GUI testing frameworks such as Cypress and Playwright rely on locators to find and interact with web elements. A locator break occurs when a structural change in the application under test causes a locator to no longer find its target element, resulting in test breakages even when the underlying functionality remains unchanged. Despite its impact on test maintenance, no dataset exists to evaluate locator fragility in Cypress and Playwright at scale. In this paper, we present ReproBreak, a dataset of reproducible locator breaks in web application GUI tests. We analyzed 359 open-source repositories to identify commits that contain locator changes. To confirm whether these changes are indeed locator breaks, we reproduced them in the top 4 projects with the largest number of locator changes and found 449 locator breaks, which are provided in the dataset along with scripts for automated reproduction. We believe ReproBreak serves as a valuable artifact to support research on locator fragility, repair techniques, and test robustness. The video is available at: https://youtu.be/mZByS_TnCvE. The dataset is at https://github.com/rub-sq/ReproBreak.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ReproBreak, a dataset of 449 reproducible locator breaks in web GUI tests for frameworks such as Cypress and Playwright. The authors analyzed 359 open-source repositories to identify commits containing locator changes, reproduced the changes in the top four projects by change volume to confirm the 449 cases, and released the dataset together with automated reproduction scripts. The work positions the artifact as a resource for research on locator fragility, repair techniques, and test robustness.
Significance. If the 449 cases are shown to be genuine structural-change-induced breaks, ReproBreak would fill a documented gap by supplying the first large-scale, publicly reproducible collection of locator failures from real repositories. The provision of reproduction scripts is a clear strength that supports independent verification and follow-on experiments. The top-4 reproduction step supplies concrete confirmation for the included entries, but the overall significance is reduced by the absence of explicit filtering details and the limited scope of reproduction.
major comments (2)
- [Abstract] Abstract: The claim that the 449 reproduced cases constitute 'locator breaks' (defined as cases where a structural change causes a locator to fail while functionality remains unchanged) rests on commits that contain locator changes. No explicit exclusion criteria or classification procedure is described to separate structural-change breaks from locator edits performed for refactoring, feature addition, or other non-structural reasons. This distinction is load-bearing for the dataset's validity.
- [Abstract] Abstract and §4 (reproduction procedure): Reproduction is performed only on the top four projects by locator-change volume. The manuscript does not report how many locator-change commits existed in the remaining 355 repositories, whether any were sampled, or why the top-4 subset is sufficient to represent the broader collection. This selection choice directly affects claims about the dataset's scale and representativeness.
minor comments (2)
- The abstract states that scripts for automated reproduction are provided; the repository README should include a one-command reproduction example and a clear statement of the exact Cypress/Playwright versions used in the validation runs.
- Table or figure captions that list the 449 cases should explicitly note the commit hashes and the before/after locator strings so readers can verify the reproduction without additional manual inspection.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, with clear indications of where the manuscript will be revised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the 449 reproduced cases constitute 'locator breaks' (defined as cases where a structural change causes a locator to fail while functionality remains unchanged) rests on commits that contain locator changes. No explicit exclusion criteria or classification procedure is described to separate structural-change breaks from locator edits performed for refactoring, feature addition, or other non-structural reasons. This distinction is load-bearing for the dataset's validity.
Authors: We agree that an explicit description of the classification procedure is necessary to support the dataset's validity. In our reproduction process, we examined commit diffs and executed the tests before and after each change to confirm that the locator failure was caused by a structural modification to the web element (e.g., attribute or hierarchy changes from UI updates) while the underlying functionality remained unchanged. Commits involving pure refactoring, feature additions, or non-structural locator updates were excluded during this verification. We will revise the abstract and Section 4 to document these exclusion criteria and the step-by-step classification procedure in detail. revision: yes
-
Referee: [Abstract] Abstract and §4 (reproduction procedure): Reproduction is performed only on the top four projects by locator-change volume. The manuscript does not report how many locator-change commits existed in the remaining 355 repositories, whether any were sampled, or why the top-4 subset is sufficient to represent the broader collection. This selection choice directly affects claims about the dataset's scale and representativeness.
Authors: The top-four selection was made for practical reasons: these projects contained the largest volume of locator changes, enabling us to produce a substantial set of 449 fully verified and reproducible cases within feasible manual verification effort. Full reproduction across all 359 repositories was not practical. No sampling was performed on the remaining repositories, as the objective was a high-quality, reproducible collection rather than a random or statistically representative sample of all locator changes. We will revise the abstract and Section 4 to report the total number of locator-change commits identified across the full set of 359 repositories and to explicitly state the rationale for focusing reproduction on the top four. revision: yes
Circularity Check
No significant circularity in empirical dataset construction
full rationale
The paper presents an empirical data collection effort: scanning 359 repositories for commits containing locator changes, then reproducing a subset from the top-4 projects to yield 449 entries with reproduction scripts. No equations, fitted parameters, predictions, or self-citation chains appear in the provided text. The process relies on public repository data and independent reproduction steps rather than any derivation that reduces to its own inputs by construction. This is a standard non-circular artifact paper whose validity rests on external verifiability of the scripts and commits, not internal self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Laurent Christophe, Reinout Stevens, Coen De Roover, and Wolfgang De Meuter
-
[2]
InInternational Conference on Software Maintenance and Evolution (ICSME ’14)
Prevalence and Maintenance of Automated Functional Tests for Web Applications. InInternational Conference on Software Maintenance and Evolution (ICSME ’14). IEEE CS, USA, 141–150. doi:10.1109/ICSME.2014.36
-
[3]
Cypress.io. 2026. Cypress: Modern Web Testing Framework. https://www.cypress. io/. Accessed: 2026-05-06
work page 2026
-
[4]
Marco De Luca, Anna Rita Fasolino, and Porfirio Tramontana. 2024. Investigating the robustness of locators in template-based Web application testing using a GUI change classification model.JSS210 (April 2024), 16 pages. doi:10.1016/j.jss.2023. 111932
-
[5]
Sergio Di Meglio and Luigi Libero Lucio Starace. 2024. Towards Predicting Fragility in End-to-End Web Tests. InProceedings of the 28th International Confer- ence on Evaluation and Assessment in Software Engineering(Salerno, Italy)(EASE ’24). ACM, New York, NY, USA, 387–392. doi:10.1145/3661167.3661179
-
[6]
Sergio Di Meglio, Luigi Libero Lucio Starace, Valeria Pontillo, Ruben Opdebeeck, Coen De Roover, and Sergio Di Martino. 2026. Investigating the adoption and maintenance of web GUI testing: Insights from GitHub repositories.IST189 (2026), 107928. doi:10.1016/j.infsof.2025.107928
-
[7]
del Alamo, Maurizio Leotta, and Filippo Ricca
Boni García, Jose M. del Alamo, Maurizio Leotta, and Filippo Ricca. 2024. Explor- ing Browser Automation: A Comparative Study of Selenium, Cypress, Puppeteer, and Playwright. InQUATIC. Springer Nature Switzerland, Cham, 142–149
work page 2024
-
[8]
Google. 2026. Puppeteer: Headless Chrome Node.js API. https://pptr.dev/. Ac- cessed: 2026-05-06
work page 2026
-
[9]
Mouna Hammoudi, Gregg Rothermel, and Paolo Tonella. 2016. Why do Record/Re- play Tests of Web Applications Break?. InIEEE International Conference on Soft- ware Testing, Verification and Validation (ICST). 180–190. doi:10.1109/ICST.2016.16
-
[10]
Hiroyuki Kirinuki, Shinsuke Matsumoto, Yoshiki Higo, and Shinji Kusumoto
-
[11]
In2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER)
Web Element Identification by Combining NLP and Heuristic Search for Web Testing. InIEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). 1055–1065. doi:10.1109/SANER53432.2022.00123
-
[12]
Hiroyuki Kirinuki, Haruto Tanno, and Katsuyuki Natsukawa. 2019. COLOR: Correct Locator Recommender for Broken Test Scripts using Various Clues in Web Application. InIEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). 310–320. doi:10.1109/SANER.2019.8667976
-
[13]
Maurizio Leotta, Filippo Ricca, Alessandro Marchetto, and Dario Olianas. 2024. An empirical study to compare three web test automation approaches: NLP-based, programmable, and capture&replay.Journal of Software: Evolution and Process 36, 5 (2024), e2606. doi:10.1002/smr.2606
-
[14]
Maurizio Leotta, Filippo Ricca, and Paolo Tonella. 2021. Sidereal: Statistical adap- tive generation of robust locators for web testing.Software Testing, Verification and Reliability31, 3 (2021), e1767. doi:10.1002/stvr.1767
-
[15]
Maurizio Leotta, Andrea Stocco, Filippo Ricca, and Paolo Tonella. 2015. Using Multi-Locators to Increase the Robustness of Web Test Cases. InIEEE 8th Inter- national Conference on Software Testing, Verification and Validation (ICST). 1–10. doi:10.1109/ICST.2015.7102611
-
[16]
Maurizio Leotta, Andrea Stocco, Filippo Ricca, and Paolo Tonella. 2016. Robula+: an algorithm for generating robust XPath locators for web testing.Journal of Software: Evolution and Process28, 3 (2016), 177–204. doi:10.1002/smr.1771
-
[17]
Sergio Di Meglio, Luigi Libero Lucio Starace, Valeria Pontillo, Ruben Opdebeeck, Coen De Roover, and Sergio Di Martino. 2025. E2EGit: A Dataset of End-to-End Web Tests in Open Source Projects. InIEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). 836–840. doi:10.1109/MSR66628.2025.00121
-
[18]
Microsoft. 2026. Playwright: Fast and reliable end-to-end testing for modern web apps. https://playwright.dev/. Accessed: 2026-05-06
work page 2026
-
[19]
Michel Nass, Emil Alégroth, Robert Feldt, Maurizio Leotta, and Filippo Ricca
-
[20]
ACM TOSEM32, 3, Article 75 (April 2023), 30 pages
Similarity-based Web Element Localization for Robust Test Automation. ACM TOSEM32, 3, Article 75 (April 2023), 30 pages. doi:10.1145/3571855
-
[21]
Michel Nass, Emil Alégroth, and Robert Feldt. 2021. Why many challenges with GUI test automation (will) remain.IST138 (2021), 106625. doi:10.1016/j.infsof. 2021.106625
-
[22]
Michel Nass, Emil Alégroth, Robert Feldt, and Riccardo Coppola. 2023. Robust web element identification for evolving applications by considering visual overlaps. InIEEE Conference on Software Testing, Verification and Validation (ICST). 258–268. doi:10.1109/ICST57152.2023.00032
-
[23]
Filippo Ricca, Maurizio Leotta, and Andrea Stocco. 2019. Three Open Problems in the Context of E2E Web Testing and a Vision: NEONATE. Advances in Computers, Vol. 113. Elsevier, 89–133. doi:10.1016/bs.adcom.2018.10.005
-
[24]
Selenium Project. 2026. Selenium: Browser Automation Framework. https: //www.selenium.dev/. Accessed: 2026-05-06
work page 2026
- [25]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.