Recognition: 2 theorem links
· Lean TheoremCorrecting Selection Bias in Sparse User Feedback for Large Language Model Quality Estimation: A Multi-Agent Hierarchical Bayesian Approach
Pith reviewed 2026-05-13 05:49 UTC · model grok-4.3
The pith
Mild priors on feedback selection recover true LLM quality within 4-13 percentage points despite severe bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Hierarchical-Informed Bayesian model, equipped with a mild prior on the feedback channel's positive rate and negative-to-positive ratio, produces aggregate quality estimates within 4-13 percentage points of the true Q* = 0.6249 on UltraFeedback data, even as simulated bias ratios vary from 1:1 to 30:1, and its 95% credible intervals cover the true value in all 50 random-seed replicates tested at maximum cluster size 10.
What carries the argument
The Bias Modeling Agent's two-stage hierarchical Beta-Binomial model under NUTS sampling, which infers per-topic selection rates s_c and qualities q_c with partial pooling, combined with reweighting by empirical topic prevalences in the Synthesis Agent.
If this is right
- The approach outperforms naive averaging and inverse propensity weighting baselines under simulated biases.
- Credible intervals provide reliable uncertainty quantification for the corrected quality.
- Drift signals from the model support online recalibration as topic prevalences or biases change.
- Partial pooling allows borrowing strength across topics even with sparse feedback per cluster.
Where Pith is reading between the lines
- Similar hierarchical priors on selection mechanisms could address bias in other user-generated data streams like reviews or surveys.
- If the bias channel prior is dashboard-readable, the method could be deployed with minimal additional data collection in live LLM systems.
- Extending the clustering to dynamic online updates might improve adaptability to shifting user bases.
Load-bearing premise
The per-cluster data can be fit equally well by a range of quality and selection combinations, so an external prior on the bias channel is needed to pick out the correct one.
What would settle it
Running the model on the UltraFeedback dataset with the described simulated biases and checking whether the credible intervals cover the known Q* in fewer than 45 of 50 replicates, or whether the point estimate error exceeds 13 percentage points at 30:1 bias ratio.
Figures



read the original abstract
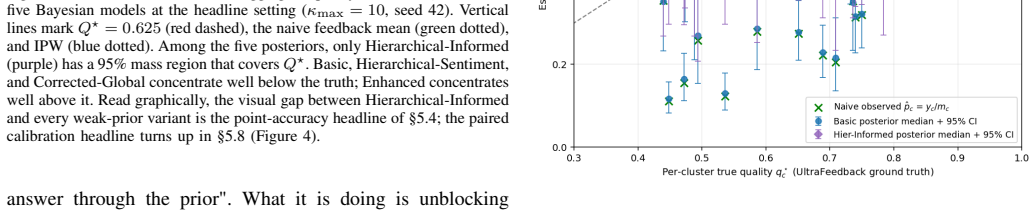
[Abridged] Production LLM deployments receive feedback from a non-random fraction of users: thumbs sit mostly in the tails of the satisfaction distribution, and a naive average over them can land 40-50 percentage points away from true system quality. We treat this as a topic- and sentiment- stratified selection-bias problem and propose a three-agent hierarchical Bayesian pipeline that does not require ground-truth labels on individual interactions. A Topic Clustering Agent partitions the stream via UMAP + HDBSCAN over text embeddings; a Bias Modeling Agent fits a two-stage hierarchical Beta-Binomial under NUTS, inferring per-topic selection rates $s_c$ and quality $q_c$ with partial pooling; a Synthesis Agent reweights $q_c$ by true topic prevalence $\hat\pi_c = n_c/N$ to report a bias-corrected aggregate posterior $\bar Q = \sum_c \hat\pi_c q_c$ with credible interval, plus drift signals for online recalibration. Validation uses UltraFeedback (N=10,232 retained interactions, $C=18$ clusters, $Q^\star=0.6249$) with simulated topic- and sentiment-dependent selection biases. We compare five Bayesian variants against Naive and IPW baselines. A mild prior on the feedback channel (typical positive-feedback rate and negative-to-positive ratio, both readable from any production dashboard without labels) keeps Hierarchical-Informed within 4-13 pp of $Q^\star$ as the bias ratio sweeps from 1:1 to 30:1, with 95% credible intervals covering $Q^\star$ in 50/50 random-seed replicates at $\kappa_{\max}=10$. Without channel-side priors, every weak-prior variant misses $Q^\star$ by 22-33 pp: the per-cluster sufficient statistics admit a one-parameter family of equally good fits, and the prior on the bias channel (not on latent quality) is what breaks the degeneracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address selection bias in user feedback for LLM quality estimation using a three-agent hierarchical Bayesian pipeline. A Topic Clustering Agent partitions interactions via UMAP + HDBSCAN on embeddings; a Bias Modeling Agent fits a hierarchical Beta-Binomial model under NUTS to infer per-cluster selection rates s_c and qualities q_c; a Synthesis Agent reweights by topic prevalence to obtain bias-corrected aggregate quality Q-bar with credible intervals. On UltraFeedback (N=10,232, C=18 clusters, true Q^*=0.6249) with simulated biases, the informed variant stays within 4-13 pp of Q* for bias ratios up to 30:1, with good CI coverage, while weak priors fail by 22-33 pp.
Significance. Should the mild dashboard-derived priors prove robust in real deployments with unknown selection mechanisms, the approach would provide a practical, label-free method for debiasing LLM feedback and monitoring drift. The explicit acknowledgment of under-identification without the channel prior and the use of partial pooling are notable strengths. The simulation-based validation demonstrates the necessity of the prior but leaves open questions about generalization.
major comments (3)
- [Abstract] The central result that Hierarchical-Informed stays within 4-13 pp of Q* depends on the mild prior on the feedback channel (positive-feedback rate and negative-to-positive ratio). Since the validation simulates the bias whose parameters inform the prior, the manuscript should include a sensitivity analysis to prior misspecification to support claims of applicability in real settings where the true bias is unknown.
- [Validation on UltraFeedback] The per-cluster degeneracy is noted (per-cluster sufficient statistics admit a one-parameter family of equally good fits), but no explicit equation or derivation shows this family for the observed feedback counts. Providing the likelihood function or a simple example with two clusters would clarify how the bias-channel prior resolves the identification issue.
- [Bias Modeling Agent] Details on convergence diagnostics for the NUTS sampler (e.g., R-hat, effective sample size) and sensitivity to clustering hyperparameters (HDBSCAN min_cluster_size, etc.) are missing, which are load-bearing for trusting the credible intervals and cluster stability.
minor comments (2)
- The notation hat{pi}_c = n_c/N for topic prevalence could be introduced earlier with a symbol table for clarity.
- [Abstract] The value of kappa_max=10 should be defined in the main text, as it appears only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation and strengthen the claims regarding robustness. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] The central result that Hierarchical-Informed stays within 4-13 pp of Q* depends on the mild prior on the feedback channel (positive-feedback rate and negative-to-positive ratio). Since the validation simulates the bias whose parameters inform the prior, the manuscript should include a sensitivity analysis to prior misspecification to support claims of applicability in real settings where the true bias is unknown.
Authors: We agree that the current validation ties the prior to the simulated bias mechanism, which limits claims about robustness under misspecification. In the revised manuscript we will add a dedicated sensitivity analysis section that perturbs the dashboard-derived prior hyperparameters (means and variances of the positive-feedback rate and negative-to-positive ratio) over plausible ranges and reports the resulting deviation of the posterior mean and credible-interval coverage from Q*. This will be presented both for the UltraFeedback simulation and, where feasible, on a second held-out dataset. revision: yes
-
Referee: [Validation on UltraFeedback] The per-cluster degeneracy is noted (per-cluster sufficient statistics admit a one-parameter family of equally good fits), but no explicit equation or derivation shows this family for the observed feedback counts. Providing the likelihood function or a simple example with two clusters would clarify how the bias-channel prior resolves the identification issue.
Authors: We accept that the current text only states the existence of the degeneracy without derivation. The revised version will include the explicit per-cluster likelihood (Beta-Binomial with selection probability s_c and quality q_c, where the observed positive count y_c depends on the product s_c * q_c under the assumed feedback channel) and a short two-cluster toy example that shows the one-parameter family of (s_c, q_c) pairs yielding identical likelihoods. We will then demonstrate how the mild prior on the channel parameters (positive rate and ratio) breaks the degeneracy and yields unique posterior modes. revision: yes
-
Referee: [Bias Modeling Agent] Details on convergence diagnostics for the NUTS sampler (e.g., R-hat, effective sample size) and sensitivity to clustering hyperparameters (HDBSCAN min_cluster_size, etc.) are missing, which are load-bearing for trusting the credible intervals and cluster stability.
Authors: We agree that these diagnostics are essential for reproducibility and trust in the credible intervals. In the revision we will report standard NUTS diagnostics (R-hat < 1.01, bulk and tail ESS > 1000, no divergent transitions) for the main UltraFeedback run and will add a supplementary sensitivity table varying HDBSCAN min_cluster_size and min_samples over a small grid, showing the resulting variation in the number of clusters, aggregate Q-bar, and CI coverage. If any hyperparameter choice materially affects conclusions we will note it explicitly. revision: yes
Circularity Check
No significant circularity; hierarchical model uses external priors and independent simulation validation
full rationale
The paper's derivation applies standard hierarchical Beta-Binomial inference (via NUTS) to observed feedback counts after UMAP+HDBSCAN clustering, with a mild external prior on channel parameters drawn from production dashboards. The aggregate Q-bar is computed as a weighted sum of posterior q_c under known topic prevalences. Validation against known Q* on simulated biases, plus comparisons to Naive and IPW baselines, provides independent grounding. No equation reduces the reported accuracy or credible-interval coverage to a fitted input by construction, no self-citation is load-bearing for the central claim, and the acknowledged degeneracy without the prior is resolved by an external source rather than tautologically. The pipeline is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-topic selection rates s_c
- per-cluster quality q_c
axioms (2)
- standard math Beta-Binomial likelihood for binary feedback under selection bias
- domain assumption UMAP + HDBSCAN clustering on embeddings captures topic- and sentiment-dependent selection strata
invented entities (3)
-
Topic Clustering Agent
no independent evidence
-
Bias Modeling Agent
no independent evidence
-
Synthesis Agent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a two-stage hierarchical Beta-Binomial model under the No-U-Turn Sampler (NUTS); per-topic feedback-selection probabilities and per-topic positive-feedback probabilities are inferred under partial pooling
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a mild prior on the feedback channel (typical positive-feedback rate and negative-to-positive ratio, both readable from any production dashboard without labels)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bias-corrected multi-agent user feedback analysis system for LLM performance optimization,
S. Gupta and A. Morandi, “Bias-corrected multi-agent user feedback analysis system for LLM performance optimization,” Technical Disclo- sure Commons, Defensive Publication Series #8803, 2025
work page 2025
-
[2]
Post-stratification: A modeler’s perspective,
R. J. A. Little, “Post-stratification: A modeler’s perspective,”Journal of the American Statistical Association, vol. 88, no. 423, pp. 1001–1012, 1993
work page 1993
-
[3]
Poststratification and weighting adjust- ments,
A. Gelman and J. B. Carlin, “Poststratification and weighting adjust- ments,” inSurvey Nonresponse, R. M. Groves, D. A. Dillman, J. L. Eltinge, and R. J. A. Little, Eds. Wiley, 2002
work page 2002
-
[4]
Sample selection bias as a specification error,
J. J. Heckman, “Sample selection bias as a specification error,”Econo- metrica, vol. 47, no. 1, pp. 153–161, 1979
work page 1979
-
[5]
A generalization of sampling without replacement from a finite universe,
D. G. Horvitz and D. J. Thompson, “A generalization of sampling without replacement from a finite universe,”Journal of the American Statistical Association, vol. 47, no. 260, pp. 663–685, 1952. 13
work page 1952
-
[6]
D. Holt and T. M. F. Smith, “Post stratification,”Journal of the Royal Statistical Society. Series A, vol. 142, no. 1, pp. 33–46, 1979
work page 1979
-
[7]
Poststratification into many categories using hierarchical logistic regression,
A. Gelman and T. C. Little, “Poststratification into many categories using hierarchical logistic regression,”Survey Methodology, vol. 23, pp. 127– 135, 1997
work page 1997
-
[8]
Bayesian multilevel estima- tion with poststratification: State-level estimates from national polls,
D. K. Park, A. Gelman, and J. Bafumi, “Bayesian multilevel estima- tion with poststratification: State-level estimates from national polls,” Political Analysis, vol. 12, no. 4, pp. 375–385, 2004
work page 2004
-
[9]
UMAP: Uniform manifold approximation and projection for dimension reduction,
L. McInnes, J. Healy, and J. Melville, “UMAP: Uniform manifold approximation and projection for dimension reduction,” 2018
work page 2018
-
[10]
Density-based cluster- ing based on hierarchical density estimates,
R. J. G. B. Campello, D. Moulavi, and J. Sander, “Density-based cluster- ing based on hierarchical density estimates,” inPacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD). Springer, 2013, pp. 160–172
work page 2013
-
[11]
hdbscan: Hierarchical density based clustering,
L. McInnes, J. Healy, and S. Astels, “hdbscan: Hierarchical density based clustering,”Journal of Open Source Software, vol. 2, no. 11, p. 205, 2017
work page 2017
-
[12]
Top2Vec: Distributed representations of topics,
D. Angelov, “Top2Vec: Distributed representations of topics,” 2020
work page 2020
-
[13]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure,
M. Grootendorst, “BERTopic: Neural topic modeling with a class-based TF-IDF procedure,” 2022
work page 2022
-
[14]
Holistic evaluation of language models,
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumaret al., “Holistic evaluation of language models,”Transactions on Machine Learning Research, 2023
work page 2023
-
[15]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[16]
Recommendations as treatments: Debiasing learning and evaluation,
T. Schnabel, A. Swaminathan, A. Singh, N. Chandak, and T. Joachims, “Recommendations as treatments: Debiasing learning and evaluation,” inInternational Conference on Machine Learning (ICML), 2016
work page 2016
-
[17]
Collaborative prediction and ranking with non-random missing data,
B. M. Marlin and R. S. Zemel, “Collaborative prediction and ranking with non-random missing data,” inACM Conference on Recommender Systems (RecSys), 2009
work page 2009
-
[18]
Causal inference for recom- mendation,
D. Liang, L. Charlin, and D. M. Blei, “Causal inference for recom- mendation,” inUAI Workshop on Causation: Foundation to Application, 2016
work page 2016
- [19]
-
[20]
Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,
P. J. Rousseeuw, “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,”Journal of Computational and Applied Mathematics, vol. 20, pp. 53–65, 1987
work page 1987
-
[21]
D. L. Davies and D. W. Bouldin, “A cluster separation measure,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PAMI- 1, no. 2, pp. 224–227, 1979
work page 1979
-
[22]
The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo,
M. D. Hoffman and A. Gelman, “The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo,”Journal of Machine Learning Research, vol. 15, no. 47, pp. 1593–1623, 2014
work page 2014
-
[23]
Inference from iterative simulation using multiple sequences,
A. Gelman and D. B. Rubin, “Inference from iterative simulation using multiple sequences,”Statistical Science, vol. 7, no. 4, pp. 457–472, 1992
work page 1992
-
[24]
Posterior predictive assessment of model fitness via realized discrepancies,
A. Gelman, X.-L. Meng, and H. Stern, “Posterior predictive assessment of model fitness via realized discrepancies,”Statistica Sinica, vol. 6, no. 4, pp. 733–807, 1996
work page 1996
-
[25]
UltraFeedback: Boosting language models with scaled AI feedback,
G. Cui, L. Yuan, N. Ding, G. Yao, B. He, W. Zhu, Y . Ni, G. Xie, R. Xie, Y . Lin, Z. Liu, and M. Sun, “UltraFeedback: Boosting language models with scaled AI feedback,” 2023
work page 2023
-
[26]
Practical Bayesian model eval- uation using leave-one-out cross-validation and W AIC,
A. Vehtari, A. Gelman, and J. Gabry, “Practical Bayesian model eval- uation using leave-one-out cross-validation and W AIC,”Statistics and Computing, vol. 27, no. 5, pp. 1413–1432, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.