Recognition: no theorem link
On the Importance of Multistability for Horizon Generalization in Reinforcement Learning
Pith reviewed 2026-05-13 06:17 UTC · model grok-4.3
The pith
Multistability in recurrent networks is necessary for policies to remain optimal across all temporal horizons in partially observable reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
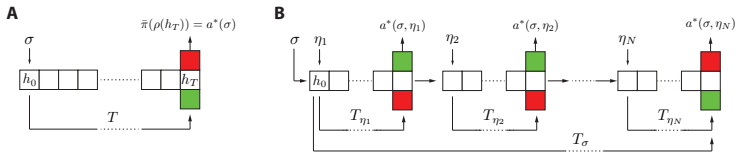
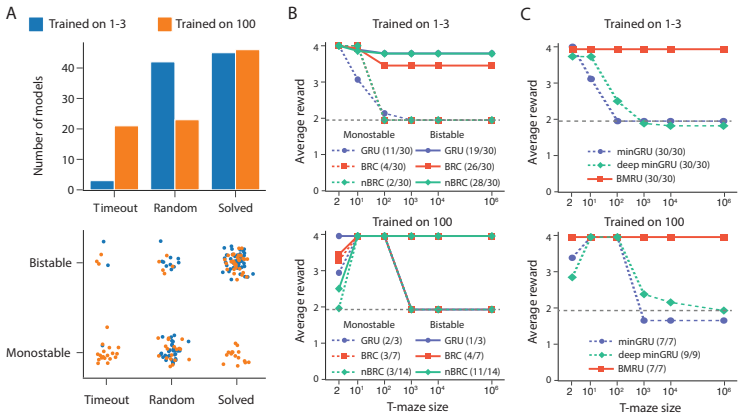
By formalizing temporal horizon generalization as the property that a policy remains optimal for all horizons, the authors derive a necessary and sufficient condition: multistability of the recurrent network is necessary in all cases and sufficient in simple tasks, while more complex tasks further require transient dynamics. Modern parallelizable architectures are monostable and consequently cannot achieve horizon generalization.
What carries the argument
Multistability of the RNN hidden-state dynamics, allowing multiple co-existing stable attractors that can represent distinct temporal contexts or memory states without collapsing.
Load-bearing premise
The formalization assumes that optimality on short horizons plus the multistability condition is sufficient to guarantee optimality at all longer horizons without additional training or task-specific adjustments, and that the tested tasks adequately represent the general POMDP case.
What would settle it
Train a monostable model such as a state space model to optimality on short horizons of a simple POMDP where the theory predicts multistability is required, then evaluate whether it retains optimal performance on much longer horizons; retained performance would falsify the necessity claim.
Figures




read the original abstract
In reinforcement learning (RL), agents acting in partially observable Markov decision processes (POMDPs) must rely on memory, typically encoded in a recurrent neural network (RNN), to integrate information from past observations. Long-horizon POMDPs, in which the relevant observation and the optimal action are separated by many time steps (called the horizon), are particularly challenging: training suffers from poor generalization, severe sample inefficiency, and prohibitive exploration costs. Ideally, an agent trained on short horizons would retain optimal behavior at arbitrarily longer ones, but no formal framework currently characterizes when this is achievable. To fill this gap, we formalized temporal horizon generalization, the property that a policy remains optimal for all horizons, derived a necessary and sufficient condition for it, and experimentally evaluated the ability of nonlinear and parallelizable RNN variants to achieve it. This paper presents the resulting theoretical framework, the empirical evaluation, and the dynamical interpretation linking RNN behavior to temporal horizon generalization. Our analyses reveal that multistability is necessary for temporal horizon generalization and, in simple tasks, sufficient; more complex tasks further require transient dynamics. In contrast, modern parallelizable architectures, namely state space models and gated linear RNNs, are monostable by construction and consequently fail to generalize across temporal horizons. We conclude that multistability and transient dynamics are two essential and complementary dynamical regimes for horizon generalization, and that no current parallelizable RNN exhibits both. Designing parallelizable architectures that combine these regimes thus emerges as a key direction for scalable long-horizon RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes temporal horizon generalization in POMDPs—the property that an RNN policy optimal on short horizons remains optimal for arbitrarily longer ones without retraining. It derives a necessary-and-sufficient condition for this property, concluding that multistability in the RNN state dynamics is necessary (and sufficient in simple tasks), while complex tasks additionally require transient dynamics. It further claims that modern parallelizable architectures (state-space models and gated linear RNNs) are monostable by construction and therefore cannot achieve horizon generalization.
Significance. If the derivation holds, the work supplies a dynamical-systems lens on a core obstacle in long-horizon POMDP RL: why memory-based agents trained on short horizons typically fail to scale. By isolating multistability and transient dynamics as complementary regimes and showing that current efficient RNNs lack both, the paper identifies a concrete architectural gap and a design target for future parallelizable models. This could inform both theory and practice in scalable RL.
major comments (3)
- [Theoretical derivation of the nec+suff condition (Section 3 / Theorem on temporal horizon generalization)] The sufficiency direction of the claimed necessary-and-sufficient condition (the step asserting that short-horizon optimality plus multistability automatically yields optimality at all longer horizons) is load-bearing yet rests on an invariance property under horizon extension that is not shown to hold for general POMDPs. In POMDPs where the optimal action depends on combinatorially growing or non-stationary history statistics, short-horizon optimality plus multistability need not preserve optimality without retraining or task-specific adjustments.
- [Experimental evaluation (Section 5)] The experimental distinction between 'simple' and 'complex' tasks is used to partition the sufficiency claim, yet the manuscript provides no explicit task definitions, horizon lengths, or quantitative metrics (e.g., return curves or generalization gaps) that would allow independent verification that the observed failures of SSMs and gated linear RNNs are due to monostability rather than task-specific choices.
- [Analysis of modern parallelizable architectures (Section 4)] The assertion that state-space models and gated linear RNNs are monostable by construction (and therefore cannot satisfy the derived condition) requires a concrete dynamical analysis or proof; without it, the contrast with multistable RNNs remains an unverified architectural claim rather than a demonstrated consequence of the formal condition.
minor comments (2)
- [Introduction / Formalization] Clarify early in the paper whether the formalization assumes finite or infinite horizons, stationary or non-stationary optimal policies, and the precise observability assumptions on the POMDP.
- [Preliminaries] Define 'multistability' and 'transient dynamics' with explicit dynamical-systems terminology (e.g., multiple attractors, eigenvalue conditions) before using them in the main claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. These have helped us strengthen the presentation of the theoretical results, experimental details, and architectural analysis. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Theoretical derivation of the nec+suff condition (Section 3 / Theorem on temporal horizon generalization)] The sufficiency direction of the claimed necessary-and-sufficient condition (the step asserting that short-horizon optimality plus multistability automatically yields optimality at all longer horizons) is load-bearing yet rests on an invariance property under horizon extension that is not shown to hold for general POMDPs. In POMDPs where the optimal action depends on combinatorially growing or non-stationary history statistics, short-horizon optimality plus multistability need not preserve optimality without retraining or task-specific adjustments.
Authors: We appreciate the referee highlighting the need to clarify the scope of sufficiency. The proof of the theorem in Section 3 shows that multistability induces an invariance: distinct attractors in the RNN state space encode history summaries that remain sufficient for optimality as the horizon is extended, because the optimal action depends only on the attractor reached rather than the full trajectory length. This holds for the POMDPs in which temporal horizon generalization is well-defined (i.e., where a short-horizon optimal policy exists that can be represented by the RNN). We acknowledge that for POMDPs with combinatorially exploding or non-stationary history statistics the invariance may require additional encoding capacity. We have revised Section 3 to state the assumptions explicitly, added a remark on the limitation for such cases, and included a brief counter-example sketch in the appendix showing when sufficiency would fail. revision: partial
-
Referee: [Experimental evaluation (Section 5)] The experimental distinction between 'simple' and 'complex' tasks is used to partition the sufficiency claim, yet the manuscript provides no explicit task definitions, horizon lengths, or quantitative metrics (e.g., return curves or generalization gaps) that would allow independent verification that the observed failures of SSMs and gated linear RNNs are due to monostability rather than task-specific choices.
Authors: We agree that the original submission lacked sufficient detail for independent verification. In the revised manuscript we have expanded Section 5 with: (i) precise definitions of the simple and complex tasks (including transition and observation functions), (ii) the exact short training horizons and the range of longer evaluation horizons, and (iii) quantitative results comprising return curves, generalization-gap plots, and ablation tables that isolate monostability as the cause of failure. These additions confirm that the performance drop of SSMs and gated linear RNNs occurs precisely when multistability is required. revision: yes
-
Referee: [Analysis of modern parallelizable architectures (Section 4)] The assertion that state-space models and gated linear RNNs are monostable by construction (and therefore cannot satisfy the derived condition) requires a concrete dynamical analysis or proof; without it, the contrast with multistable RNNs remains an unverified architectural claim rather than a demonstrated consequence of the formal condition.
Authors: We thank the referee for requesting a formal demonstration. Section 4 already sketches the argument that SSMs possess a unique fixed point under linear state transitions and that gated linear RNNs collapse to a single attractor due to their gating structure. To make this rigorous we have added a self-contained proof in the appendix (now referenced from Section 4) showing that both families admit exactly one stable equilibrium for any parameter setting, while standard nonlinear RNNs can be constructed with multiple attractors. This directly links the architectural form to the violation of the multistability condition in Theorem 1. revision: yes
Circularity Check
Derivation of necessary and sufficient condition for temporal horizon generalization is self-contained
full rationale
The paper formalizes temporal horizon generalization as the property that a policy remains optimal for all horizons and derives a necessary and sufficient condition based on multistability (with transient dynamics for complex tasks). No quoted equations or steps reduce the claimed result to its inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations are invoked to justify the core uniqueness or sufficiency claim. The derivation is presented as independent mathematical analysis, with experiments serving as validation rather than the source of the condition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimal policies in POMDPs require memory integration over time via recurrent dynamics.
Reference graph
Works this paper leans on
-
[1]
A survey analyzing generalization in deep reinforcement learning
Ezgi Korkmaz. A survey analyzing generalization in deep reinforcement learning. https://arxiv.org/pdf/2401.02349v2, 2024
-
[2]
Dibya Ghosh, Jad Rahme, Aviral Kumar, Amy Zhang, Ryan P Adams, and Sergey Levine. Why generalization in rl is difficult: Epistemic pomdps and implicit partial observability.Advances in neural information processing systems, 34:25502–25515, 2021
work page 2021
-
[3]
Horizon generalization in reinforcement learning
Vivek Myers, Catherine Ji, and Benjamin Eysenbach. Horizon generalization in reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[4]
Combining recurrent, convolutional, and continuous-time models with linear state space layers
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems, 34:572–585, 2021
work page 2021
-
[5]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. InInternational Conference on Learning Representations, 2022
work page 2022
-
[6]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. InFirst Conference on Language Modeling, August 2024
work page 2024
-
[7]
Parallelizing linear recurrent neural nets over sequence length
Eric Martin and Chris Cundy. Parallelizing linear recurrent neural nets over sequence length. In International Conference on Learning Representations, 2018
work page 2018
-
[8]
Zhen Qin, Songlin Yang, and Yiran Zhong. Hierarchically Gated Recurrent Neural Network for Sequence Modeling.Advances in Neural Information Processing Systems, 36:33202–33221, December 2023
work page 2023
-
[9]
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xLSTM: Extended Long Short-Term Memory.Advances in Neural Information Processing Systems, 37: 107547–107603, December 2024. doi: 10.52202/079017-3417
-
[10]
Were RNNs all we needed?arXiv preprint arXiv:2410.01201, 2024
Leo Feng, Frederick Tung, Hossein Hajimirsadeghi, Mohamed Osama, Yoshua Bengio, and Roland Memisevic. Were RNNs all we needed?arXiv preprint arXiv:2410.01201, 2024
-
[11]
Scalable matmul-free language modeling,
Rui-Jie Zhu, Yu Zhang, Steven Abreu, Ethan Sifferman, Tyler Sheaves, Yiqiao Wang, Dustin Richmond, Sumit Bam Shrestha, Peng Zhou, and Jason K. Eshraghian. Scalable MatMul-free language modeling, 2025. URLhttps://arxiv.org/abs/2406.02528. 10
-
[12]
Parallelizable memory recurrent units.arXiv preprint arXiv:2601.09495, 2026
Florent De Geeter, Gaspard Lambrechts, Damien Ernst, and Guillaume Drion. Parallelizable memory recurrent units.arXiv preprint arXiv:2601.09495, 2026
-
[13]
Long short-term memory.Neural Computation, 9 (8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9 (8):1735–1780, 1997
work page 1997
-
[14]
Learning phrase representations using RNN encoder- decoder for statistical machine translation
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder- decoder for statistical machine translation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724–1734, 2014
work page 2014
-
[15]
The unreasonable effectiveness of the forget gate
Jos Van Der Westhuizen and Joan Lasenby. The unreasonable effectiveness of the forget gate. arXiv preprint arXiv:1804.04849, 2018
work page Pith review arXiv 2018
-
[16]
A bio-inspired bistable recurrent cell allows for long-lasting memory.PLoS ONE, 16(6):e0252676, 2021
Nicolas Vecoven, Damien Ernst, and Guillaume Drion. A bio-inspired bistable recurrent cell allows for long-lasting memory.PLoS ONE, 16(6):e0252676, 2021
work page 2021
-
[17]
Guo-Bing Zhou, Jianxin Wu, Chen-Lin Zhang, and Zhi-Hua Zhou. Minimal gated unit for recurrent neural networks.International Journal of Automation and Computing, 13(3):226–234, 2016
work page 2016
-
[18]
Gaspard Lambrechts, Florent De Geeter, Nicolas Vecoven, Damien Ernst, and Guillaume Drion. Warming up recurrent neural networks to maximise reachable multistability greatly improves learning.Neural Networks, 166:645–669, 2023
work page 2023
- [19]
-
[20]
Bram Bakker. Reinforcement learning with long short-term memory.Advances in neural information processing systems, 14, 2001
work page 2001
-
[21]
Amy Zhang, Nicolas Ballas, and Joelle Pineau. A dissection of overfitting and generalization in continuous reinforcement learning.arXiv preprint arXiv:1806.07937, 2018
-
[22]
Quantifying generalization in reinforcement learning
Karl Cobbe, Oleg Klimov, Chris Hesse, Taehoon Kim, and John Schulman. Quantifying generalization in reinforcement learning. InInternational conference on machine learning, pages 1282–1289. PMLR, 2019
work page 2019
-
[23]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InInternational conference on machine learning, pages 2048–2056. PMLR, 2020
work page 2048
-
[24]
Robert Kirk, Amy Zhang, Edward Grefenstette, and Tim Rocktäschel. A survey of zero-shot generalisation in deep reinforcement learning.Journal of Artificial Intelligence Research, 76: 201–264, 2023
work page 2023
-
[25]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009
work page 2009
-
[26]
Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E Taylor, and Peter Stone. Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research, 21(181):1–50, 2020
work page 2020
-
[27]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
work page 2017
-
[28]
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
work page 1998
-
[29]
Deep recurrent q-learning for partially observable mdps
Matthew J Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. InAAAI fall symposia, volume 45, page 141, 2015. 11
work page 2015
-
[30]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
work page 2015
-
[32]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines.arXiv preprint arXiv:1410.5401, 2014
work page internal anchor Pith review arXiv 2014
-
[34]
Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska- Barwi´nska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, et al. Hybrid computing using a neural network with dynamic external memory.Nature, 538 (7626):471–476, 2016
work page 2016
-
[35]
Stabilizing transformers for reinforcement learning
Emilio Parisotto, Francis Song, Jack Rae, Razvan Pascanu, Caglar Gulcehre, Siddhant Jayaku- mar, Max Jaderberg, Raphael Lopez Kaufman, Aidan Clark, Seb Noury, et al. Stabilizing transformers for reinforcement learning. InInternational conference on machine learning, pages 7487–7498. PMLR, 2020
work page 2020
-
[36]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to Control: Learning Behaviors by Latent Imagination. InInternational Conference on Learning Represen- tations, September 2019
work page 2019
-
[37]
Mastering atari with discrete world models
Danijar Hafner, Timothy P Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations, 2020
work page 2020
-
[38]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
work page 2025
-
[39]
Luisa Zintgraf, Sebastian Schulze, Cong Lu, Leo Feng, Maximilian Igl, Kyriacos Shiarlis, Yarin Gal, Katja Hofmann, and Shimon Whiteson. Varibad: Variational bayes-adaptive deep rl via meta-learning.Journal of Machine Learning Research, 22(289):1–39, 2021
work page 2021
-
[40]
Stephen Boyd and Leon O. Chua. Fading memory and the problem of approximating nonlinear operators with Volterra series.IEEE Transactions on Circuits and Systems, 32(11):1150–1161, 1985
work page 1985
-
[41]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. On the difficulty of training recurrent neural networks. InInternational conference on machine learning, pages 1310–1318. PMLR, 2013
work page 2013
-
[42]
Gustave Bainier, Antoine Chaillet, Rodolphe Sepulchre, and Alessio Franci. State-space fading memory.arXiv preprint arXiv:2603.23814, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Peng Liu, Jun Wang, and Zhigang Zeng. An overview of the stability analysis of recurrent neural networks with multiple equilibria.IEEE Transactions on Neural Networks and Learning Systems, 34(3):1098–1111, 2023. doi: 10.1109/TNNLS.2021.3105519. Epub 2023 Feb 28
-
[44]
Asynchronous methods for deep reinforce- ment learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforce- ment learning. InInternational conference on machine learning, pages 1928–1937. PmLR, 2016
work page 1928
-
[45]
Shengyi Huang, Rousslan Fernand Julien Dossa, Chang Ye, Jeff Braga, Dipam Chakraborty, Kinal Mehta, and JoÃG, o GM AraÚjo. Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms.Journal of Machine Learning Research, 23(274):1–18, 2022. 12 A Related Work Since our work sits at the intersection of several active researc...
work page 2022
-
[46]
with recurrent encoders has since become one of the standard approaches to handling partial observability. Beyond standard RNNs, various approaches have been proposed to enhance the memory capacity accessible to the agent. Memory-augmented networks such as the neural turing machine [33] and the differentiable neural computer [34] decouple capacity from th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.