Recognition: no theorem link
Learning Ego-Centric BEV Representations from a Perspective-Privileged View: Cross-View Supervision for Online HD Map Construction
Pith reviewed 2026-05-13 06:35 UTC · model grok-4.3
The pith
Cross-view supervision transfers overhead structural knowledge to camera BEV encoders for better long-range HD maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-View Supervision (CVS) distills globally consistent structural knowledge from an ego-aligned overhead teacher into camera-based BEV encoders by aligning representations in a shared BEV feature space. This enhances structural coherence for HD map construction while leaving the inference architecture unchanged and requiring no overhead input at test time.
What carries the argument
Cross-View Supervision (CVS), a distillation process that aligns camera-derived BEV features with those from a perspective-privileged overhead teacher to transfer geometric priors.
If this is right
- CVS produces a 3.9 mAP increase in the standard 60 by 30 meter region.
- CVS produces a 9.9 mAP increase in the extended 100 by 50 meter region, a 44 percent relative gain at long range.
- The method keeps exactly the same camera-only inference path and speed as the baseline.
- Gains appear consistently when training with ego-aligned aerial imagery from the AID4AD extension.
Where Pith is reading between the lines
- The same alignment principle could be tested on other BEV tasks such as 3D detection if overhead data exists only at training time.
- Gains concentrated at long range suggest the method may help extend reliable perception distance in driving systems.
- If the alignment works across different overhead sources, it could reduce reliance on perfect sensor synchronization in multi-view datasets.
Load-bearing premise
That matching features from the overhead and camera views in the same top-down coordinate space successfully moves reliable map structure knowledge into the camera model.
What would settle it
An ablation on the same nuScenes data where the alignment loss produces no mAP gain or produces lower accuracy than the baseline when the overhead teacher is replaced by a non-matching view.
Figures
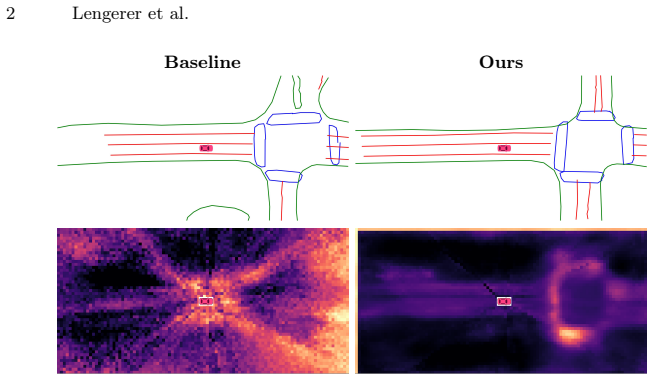
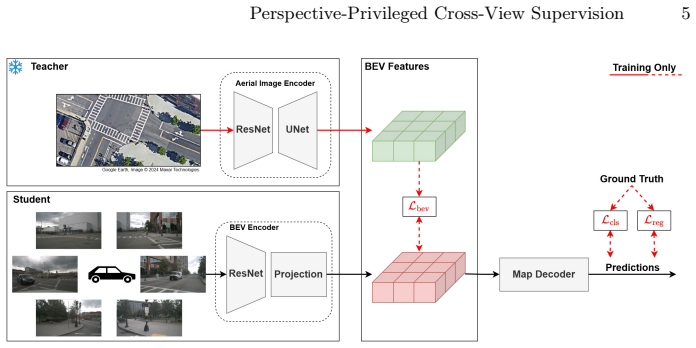






read the original abstract
Bird's-eye-view (BEV) representations derived from multi-camera input have become a central interface for online high-definition (HD) map construction. However, most approaches rely solely on ego-centric supervision, requiring large-scale scene structure to be inferred from incomplete observations, occlusions, and diminishing information density at long range, where perspective effects and spatial sparsity hinder consistent structural reasoning. We introduce Cross-View Supervision (CVS), a representation learning paradigm that transfers geometric and topological priors from an ego-aligned overhead perspective into camera-based BEV encoders. Rather than adding auxiliary semantic losses, CVS aligns representations in a shared BEV feature space and distills globally consistent structural knowledge from a perspective-privileged teacher into the ego-centric backbone. This supervision enhances structural coherence without modifying the inference architecture or requiring overhead input at test time. Experiments on nuScenes using ego-aligned aerial imagery from the AID4AD cross-view extension demonstrate consistent improvements over StreamMapNet while maintaining identical camera-only inference. CVS yields +3.9\,mAP in the standard $60\times30\,\mathrm{m}$ region and +9.9\,mAP in the extended $100\times50\,\mathrm{m}$ setting, corresponding to a 44\% relative gain at long range. These results highlight perspective-privileged structural supervision as a promising training principle for improving BEV representation learning in HD map construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cross-View Supervision (CVS), a training paradigm that aligns camera-derived BEV features with those from an ego-aligned overhead (perspective-privileged) teacher in a shared BEV space. This is intended to transfer geometric and topological priors to improve ego-centric BEV representations for online HD map construction without auxiliary semantic losses or overhead input at inference. On nuScenes with AID4AD aerial data, CVS reports +3.9 mAP in the 60×30 m region and +9.9 mAP in the 100×50 m region over StreamMapNet (44% relative gain at long range) while preserving identical camera-only inference.
Significance. If the alignment mechanism demonstrably transfers globally consistent structural knowledge (long-range lane continuity and topology) rather than local cues or generic regularization, the result would be significant for camera-only HD mapping, as it addresses diminishing information density at range via privileged-view supervision during training only. The reported long-range gains and unchanged inference footprint make the paradigm worth further exploration if the transfer claim can be substantiated.
major comments (3)
- Abstract: the central claim that representation alignment in shared BEV space 'distills globally consistent structural knowledge' (long-range topology) is load-bearing for the +9.9 mAP long-range result, yet the manuscript provides no explicit loss formulation, alignment objective, or mechanism to enforce higher-order geometric invariants beyond standard feature matching; this leaves open whether gains arise from structural transfer or from feature sharpening/regularization.
- Abstract and Experiments: the reported mAP gains lack controls or ablations isolating CVS from confounding factors such as hyperparameter retuning, data selection in the AID4AD extension, or changes in training schedule; without these, the attribution of the 44% relative long-range improvement specifically to perspective-privileged supervision cannot be verified.
- Methods (alignment description): the assumption that shared-BEV-space alignment transfers globally consistent topology from the aerial teacher is not supported by auxiliary losses or topological metrics; standard feature-level distillation does not automatically preserve lane continuity or higher-order structure, weakening the interpretation of the long-range gains.
minor comments (1)
- Abstract: the notation for the two evaluation regions (60×30 m and 100×50 m) should be clarified with explicit definitions of the coordinate frames and how the extended region is sampled.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating revisions to the manuscript where they strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: Abstract: the central claim that representation alignment in shared BEV space 'distills globally consistent structural knowledge' (long-range topology) is load-bearing for the +9.9 mAP long-range result, yet the manuscript provides no explicit loss formulation, alignment objective, or mechanism to enforce higher-order geometric invariants beyond standard feature matching; this leaves open whether gains arise from structural transfer or from feature sharpening/regularization.
Authors: We appreciate the referee highlighting the need for explicit formulation. In the revised manuscript, Section 3.2 now includes the precise CVS objective: L_CVS = ||F_BEV^student - F_BEV^teacher||_2^2 (with optional cosine term), applied after projecting both views into the shared ego-aligned BEV grid. The teacher is a BEV encoder trained directly on aerial imagery, so its features encode complete scene geometry unavailable to the student. An added ablation replacing the aerial teacher with a randomly initialized network yields no long-range gains, indicating the improvement is not generic regularization. We also include qualitative BEV feature visualizations showing preserved lane continuity at range. revision: yes
-
Referee: Abstract and Experiments: the reported mAP gains lack controls or ablations isolating CVS from confounding factors such as hyperparameter retuning, data selection in the AID4AD extension, or changes in training schedule; without these, the attribution of the 44% relative long-range improvement specifically to perspective-privileged supervision cannot be verified.
Authors: We agree that stronger isolation is required. The revised Experiments section adds three controls: (i) StreamMapNet retrained from scratch using identical hyperparameters, optimizer schedule, and epoch count as the CVS model but without the teacher; (ii) all methods evaluated on the exact same AID4AD aerial data splits; (iii) a data-subset ablation confirming the long-range gain persists when restricting to the original nuScenes training scenes. These show the +9.9 mAP remains attributable to CVS rather than schedule or data differences. revision: yes
-
Referee: Methods (alignment description): the assumption that shared-BEV-space alignment transfers globally consistent topology from the aerial teacher is not supported by auxiliary losses or topological metrics; standard feature-level distillation does not automatically preserve lane continuity or higher-order structure, weakening the interpretation of the long-range gains.
Authors: We acknowledge that pure feature alignment does not explicitly regularize topology. The revised Methods clarifies that the transfer occurs because the teacher’s features are derived from a globally consistent overhead view; the student learns to reproduce these priors in regions where camera evidence is sparse. To strengthen the claim, we have added a topological metric (lane connectivity accuracy and continuity score at >50 m) in the Experiments, which improves under CVS. While we do not introduce new auxiliary losses, the empirical gains on this metric support the structural-transfer interpretation. revision: partial
Circularity Check
No circularity: derivation is self-contained on external benchmarks
full rationale
The paper defines CVS as a teacher-student feature alignment in a shared BEV space that transfers priors from an ego-aligned overhead view during training only. Reported mAP gains are measured directly on nuScenes with the AID4AD extension; no equations reduce the claimed improvements to fitted parameters renamed as predictions, no self-citations are invoked as uniqueness theorems, and no ansatz or known result is smuggled via prior work by the same authors. The central claim remains externally falsifiable and does not collapse to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature alignment in a shared BEV space transfers geometric and topological priors effectively from overhead to ego-centric views
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2206.05400 (2022)
Bao, Z., Hossain, S., Lang, H., Lin, X.: High-definition map generation technologies for autonomous driving. arXiv preprint arXiv:2206.05400 (2022)
-
[2]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
work page 2020
-
[3]
Chen, J., Wu, Y., Tan, J., Ma, H., Furukawa, Y.: MapTracker: Tracking with strided memory fusion for consistent vector hd mapping. In: ECCV (2024)
work page 2024
-
[4]
IEEE Transactions on Pattern Analysis and Ma- chine Intelligence46(12), 10164–10183 (2024)
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence46(12), 10164–10183 (2024)
work page 2024
-
[5]
Choi,S.,Kim,J.,Shin,H.,Choi,J.W.:Mask2Map:Vectorizedhdmapconstruction using bird’s eye view segmentation masks. In: ECCV (2024)
work page 2024
-
[6]
IEEE Open Journal of Intelligent Transportation Systems4, 527–550 (2023)
Elghazaly, G., Frank, R., Harvey, S., Safko, S.: High-Definition Maps: Comprehen- sive survey, challenges, and future perspectives. IEEE Open Journal of Intelligent Transportation Systems4, 527–550 (2023)
work page 2023
-
[7]
Federal Agency for Cartography and Geodesy (BKG): Digitale orthophotos bo- denauflösung 20 cm (dop20).https://gdz.bkg.bund.de/index.php/default/ digitale- orthophotos- bodenauflosung- 20- cm- dop20.html(2023), accessed: November 2025
work page 2023
-
[8]
In: 2021 IEEE Intelligent Vehicles Symposium (IV)
Gómez–Huélamo, C., Bergasa, L.M., Gutiérrez, R., Arango, J.F., Díaz, A.: Smart- MOT: Exploiting the fusion of hdmaps and multi-object tracking for real-time scene understanding in intelligent vehicles applications. In: 2021 IEEE Intelligent Vehicles Symposium (IV). pp. 710–715 (2021)
work page 2021
-
[9]
In: Proceedings of the European Conference on Computer Vision (ECCV) (2024)
Hao, X., Li, R., Zhang, H., Li, D., Yin, R., Jung, S., Park, S.I., Yoo, B., Zhao, H., Zhang, J.: MapDistill: Boosting efficient camera-based hd map construction via camera-lidar fusion model distillation. In: Proceedings of the European Conference on Computer Vision (ECCV) (2024)
work page 2024
-
[10]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Hao, Z., Guo, J., Han, K., Tang, Y., Hu, H., Wang, Y., Xu, C.: One-for-All: Bridge the gap between heterogeneous architectures in knowledge distillation. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 79570–79582. Curran As- sociates, Inc. (2023)
work page 2023
-
[11]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
work page 2016
-
[12]
arXiv preprint arXiv:2203.17054 (2022)
Huang,J.,Huang,G.:BEVDet4D:Exploittemporalcuesinmulti-camera3dobject detection. arXiv preprint arXiv:2203.17054 (2022)
-
[13]
Institut Géographique National (IGN): Bd ortho – aerial imagery of metropolitan france.https://geoservices.ign.fr/bdortho(2023), accessed: November 2025
work page 2023
-
[14]
Johansen, H.: ResUNet++: An advanced architecture for medical image segmentation
Jha, D., Smedsrud, P.H., Riegler, M.A., Johansen, D., Lange, T.D., Halvorsen, P., D. Johansen, H.: ResUNet++: An advanced architecture for medical image segmentation. In: 2019 IEEE International Symposium on Multimedia (ISM). pp. 225–230 (2019)
work page 2019
-
[15]
In: 2019 IEEE Intelligent Vehicles Symposium (IV)
Jian, Z., Zhang, S., Chen, S., Lv, X., Zheng, N.: High-definition map combined local motion planning and obstacle avoidance for autonomous driving. In: 2019 IEEE Intelligent Vehicles Symposium (IV). pp. 2180–2186 (2019) 16 Lengerer et al
work page 2019
-
[16]
In: Chaudhuri, K., Salakhutdinov, R
Kornblith, S., Norouzi, M., Lee, H., Hinton, G.: Similarity of neural network rep- resentations revisited. In: Chaudhuri, K., Salakhutdinov, R. (eds.) Proceedings of the 36th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 97, pp. 3519–3529. PMLR (09–15 Jun 2019)
work page 2019
-
[17]
In: Proceedings of the Euro- pean Conference on Computer Vision (ECCV) (2024)
Le, D.T., Shi, H., Cai, J., Rezatofighi, H.: Diffusion model for robust multi-sensor fusion in 3d object detection and bev segmentation. In: Proceedings of the Euro- pean Conference on Computer Vision (ECCV) (2024)
work page 2024
-
[18]
arXiv preprint arXiv:2508.02140 (2025)
Lengerer,D.,Pechinger,M.,Bogenberger,K.,Markgraf,C.:AID4AD:Aerialimage data for automated driving perception. arXiv preprint arXiv:2508.02140 (2025)
-
[19]
IEEE Transactions on Intelligent Vehicles9(1), 2489–2498 (2024)
Li, J., Lu, M., Liu, J., Guo, Y., Du, Y., Du, L., Zhang, S.: BEV-LGKD: A uni- fied lidar-guided knowledge distillation framework for multi-view bev 3d object detection. IEEE Transactions on Intelligent Vehicles9(1), 2489–2498 (2024)
work page 2024
-
[20]
In: 2022 International Conference on Robotics and Automation (ICRA)
Li, Q., Wang, Y., Wang, Y., Zhao, H.: HDMapNet: An online hd map construc- tion and evaluation framework. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 4628–4634 (2022)
work page 2022
-
[21]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Li, Z., Peng, H., Yu, T., Li, S., Pang, J., Lin, D.: BEVFormer: Learning bird’s-eye- view representation from multi-camera images via spatiotemporal transformers. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 1–18 (2022)
work page 2022
-
[22]
In: International Conference on Learning Representations (ICLR) (2023)
Liao, B., Chen, S., Wang, X., Cheng, T., Zhang, Q., Liu, W., Huang, C.: MapTR: Structured modeling and learning for online vectorized hd map construction. In: International Conference on Learning Representations (ICLR) (2023)
work page 2023
-
[23]
International Journal of Computer Vision pp
Liao, B., Chen, S., Zhang, Y., Jiang, B., Zhang, Q., Liu, W., Huang, C., Wang, X.: Maptrv2: An end-to-end framework for online vectorized hd map construction. International Journal of Computer Vision pp. 1–23 (2024)
work page 2024
-
[24]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object de- tection. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 2980–2988 (2017)
work page 2017
-
[25]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, X., Wang, S., Li, W., Yang, R., Chen, J., Zhu, J.: MGMap: Mask-guided learning for online vectorized hd map construction. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14812–14821 (June 2024)
work page 2024
-
[26]
In: Proceedings of the 40th International Conference on Machine Learning (ICML) (2023)
Liu, Y., Yuan, T., Wang, Y., Wang, Y., Zhao, H.: VectorMapNet: End-to-end vectorized hd map learning. In: Proceedings of the 40th International Conference on Machine Learning (ICML) (2023)
work page 2023
-
[27]
In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Monninger, T., Zhang, Z., Mo, Z., Anwar, M.Z., Staab, S., Ding, S.: MapDiffusion: Generative diffusion for vectorized online hd map construction and uncertainty estimation in autonomous driving. In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 4099–4106 (2025)
work page 2025
-
[28]
In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R
Morcos, A., Raghu, M., Bengio, S.: Insights on representational similarity in neural networks with canonical correlation. In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 31. Curran Associates, Inc. (2018)
work page 2018
-
[29]
co.uk/products/os-mastermap-imagery-layer(2023), accessed: November 2025
Ordnance Survey: Os mastermap imagery layer.https://www.ordnancesurvey. co.uk/products/os-mastermap-imagery-layer(2023), accessed: November 2025
work page 2023
-
[30]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Philion, J., Fidler, S.: Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 194–210 (2020)
work page 2020
-
[31]
Poggenhans, F., Pauls, J.H., Janosovits, J., Orf, S., Naumann, M., Kuhnt, F., Mayr, M.: Lanelet2: A high-definition map framework for the future of automated driving.In:ProceedingsoftheIEEEIntelligentTransportationSystemsConference (ITSC) (2018) Perspective-Privileged Cross-View Supervision 17
work page 2018
-
[32]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Qiao, L., Ding, W., Qiu, X., Zhang, C.: End-to-end vectorized hd-map construction with piecewise bezier curve. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13218–13228 (June 2023)
work page 2023
-
[33]
In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R
Raghu, M., Gilmer, J., Yosinski, J., Sohl-Dickstein, J.: SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017)
work page 2017
-
[34]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Roddick, T., Cipolla, R.: Predicting semantic map representations from images us- ing pyramid occupancy networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
work page 2020
-
[35]
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- calimagesegmentation.In:ProceedingsoftheInternationalConferenceonMedical Image Computing and Computer-Assisted Intervention (MICCAI). pp. 234–241. Springer (2015)
work page 2015
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
Wang, S., Liu, Y., Wang, T., Li, Y., Zhang, X.: Exploring object-centric tempo- ral modeling for efficient multi-view 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
work page 2023
-
[37]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Wang, S., Jia, F., Mao, W., Liu, Y., Zhao, Y., Chen, Z., Wang, T., Zhang, C., Zhang, X., Zhao, F.: Stream query denoising for vectorized HD map construction. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 203–220. Springer (2024)
work page 2024
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wang, Z., Li, D., Luo, C., Xie, C., Yang, X.: DistillBEV: Boosting multi-camera 3d object detection with cross-modal knowledge distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 8637–8646 (October 2023)
work page 2023
-
[39]
Wilson, B., Qi, W., Agarwal, T., Lambert, J., Singh, J., Khandelwal, S., Pan, B., Kumar, R., Hartnett, A., Pontes, J.K., Ramanan, D., Carr, P., Hays, J.: Argo- verse 2: Next generation datasets for self-driving perception and forecasting. In: Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Be...
work page 2021
-
[40]
IEEE Intelligent Transportation Systems Magazine13(1), 91–106 (2021)
Wong, K., Gu, Y., Kamijo, S.: Mapping for autonomous driving: Opportunities and challenges. IEEE Intelligent Transportation Systems Magazine13(1), 91–106 (2021)
work page 2021
-
[41]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Ye, X., Yaman, B., Cheng, S., Tao, F., Mallik, A., Ren, L.: Bevdiffuser: Plug-and- play diffusion model for bev denoising with ground-truth guidance. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 1495– 1504 (June 2025)
work page 2025
-
[42]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2024)
Yuan, T., Liu, Y., Wang, Y., Wang, Y., Zhao, H.: StreamMapNet: Streaming mapping network for vectorized online hd map construction. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (2024)
work page 2024
-
[43]
Zou, J., Tian, K., Zhu, Z., Ye, Y., Wang, X.: DiffBEV: Conditional diffusion model for bird’s eye view perception. Proceedings of the AAAI Conference on Artificial Intelligence38(7), 7846–7854 (Mar 2024) 18 Lengerer et al. Appendix Thisdocumentprovidesadditionaldetails,analyses,andvisualizationsthatcom- plement the main paper. A Sensitivity to the BEV los...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.