Recognition: 2 theorem links
· Lean TheoremGeometric Asymptotics of Score Mixing and Guidance in Diffusion Models
Pith reviewed 2026-05-13 03:57 UTC · model grok-4.3
The pith
Mixed-score guidance in diffusion models reduces asymptotically to dynamics on a geometric potential of squared distances to data supports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Exploiting a Laplace-Varadhan principle under a similarity-time rescaling, the small-time generation dynamics driven by the mixed score s = λ ∇log u1 + (1-λ) ∇log u2 is governed by the explicit geometric potential Φ_λ = λ d1² + (1-λ) d2², which depends only on the supports of the initial measures and on the mixing parameter. This gives a rigorous reduction from a singular, non-autonomous score-driven dynamics to autonomous Clarke-type subgradient inclusions. In the empirical setting of finite Dirac mixtures, the limiting potential is piecewise quadratic with a Voronoi-type structure, yielding convergence of all autonomous limiting trajectories to critical points and a conditional convergence
What carries the argument
The geometric potential Φ_λ = λ d₁² + (1-λ) d₂², which encodes the limiting small-time behavior of the mixed-score flow and permits its reduction to an autonomous subgradient inclusion.
If this is right
- The mixed-score dynamics reduces to an autonomous Clarke subgradient inclusion driven by Φ_λ.
- In the finite-Dirac case all limiting trajectories converge to critical points of the piecewise-quadratic potential.
- The original generation flow converges to local minimizers of Φ_λ at rate O(√t) whenever the minimizer is smooth and stable.
- The same geometric description covers both the mixture-of-experts regime 0 ≤ λ ≤ 1 and the classifier-free guidance regime λ > 1.
Where Pith is reading between the lines
- Choosing λ to sculpt the landscape of Φ_λ offers a direct way to steer sampling toward or away from particular supports without retraining scores.
- The Voronoi structure of the empirical case suggests that guidance with more than two measures would induce a multi-class Voronoi partition whose geometry controls the flow.
- Because the reduction is local in time, early-stopping or hybrid integrators that switch to the geometric flow after a short burn-in period become feasible.
Load-bearing premise
The two measures are heat evolutions of compactly supported probability measures, so the Laplace-Varadhan principle applies directly to the rescaled process.
What would settle it
Numerical trajectories generated by the mixed score for small times that deviate systematically from the gradient flow of Φ_λ, or an analytic counter-example in which the supports are compact yet the limiting dynamics is not captured by that potential.
Figures
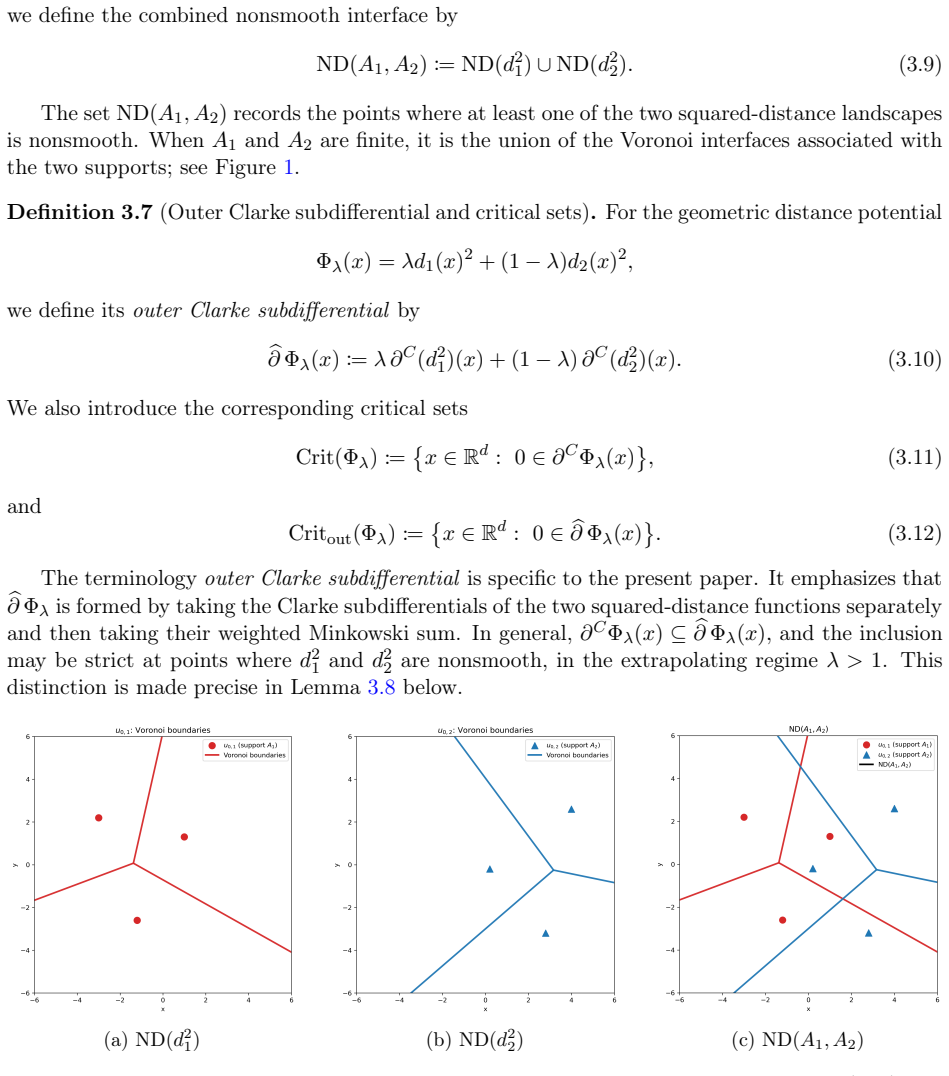

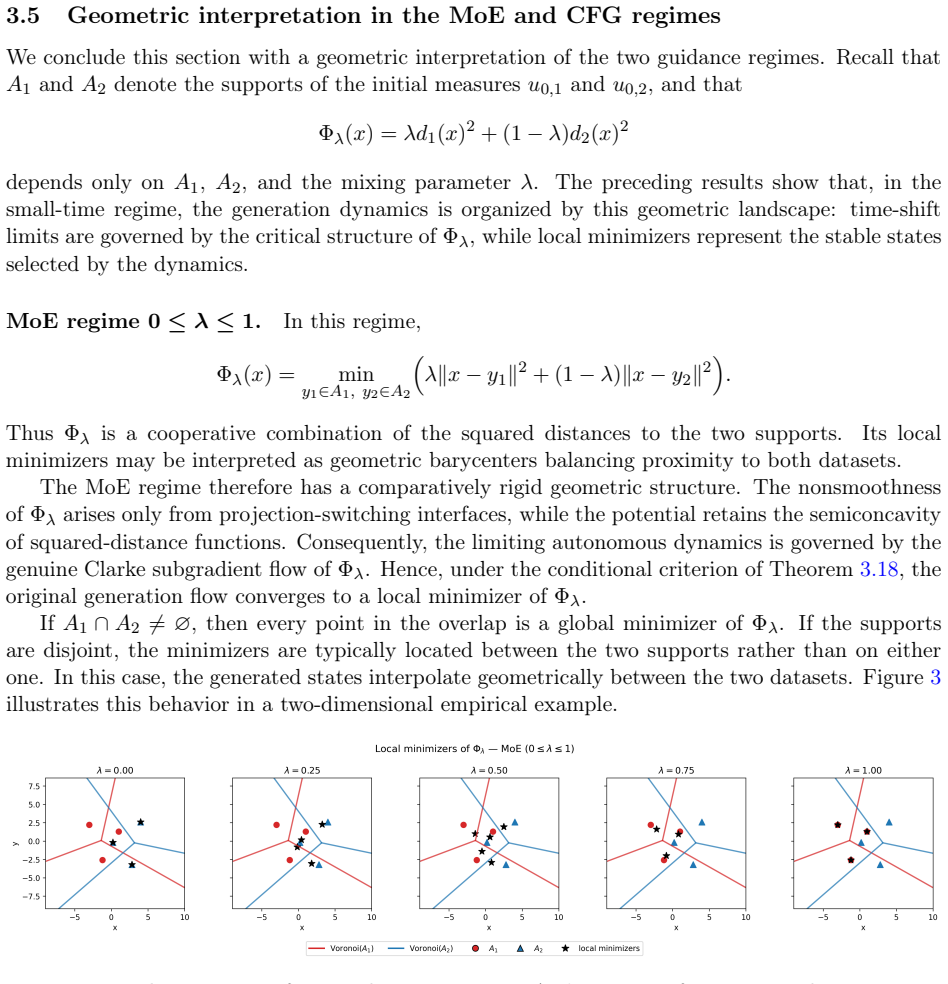


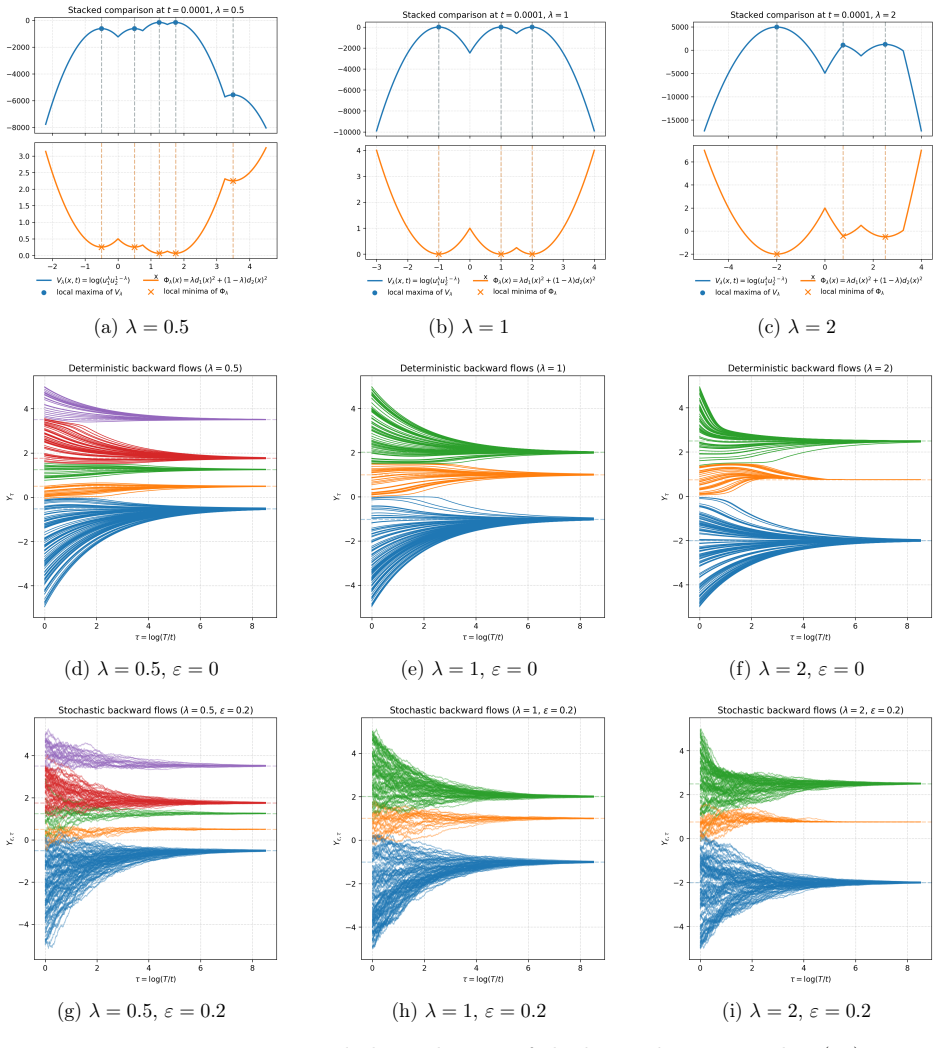



read the original abstract
Diffusion models are routinely guided in practice by combining multiple score fields, yet the mathematical structure of score mixing is still poorly understood. We study the small-time generation dynamics driven by mixed scores $$ s=\lambda\,\nabla\log u_1+(1-\lambda)\,\nabla\log u_2,\qquad \lambda\ge 0, $$ in the heat-flow framework, where $u_1,u_2$ are heat evolutions of two compactly supported probability measures. This single formulation covers both the mixture-of-experts regime $(0\leq \lambda\leq 1)$ and the classifier-free guidance regime $(\lambda>1)$. Exploiting a Laplace-Varadhan principle under a similarity-time rescaling, we show that the small-time generation dynamics is governed by the explicit geometric potential $$ \Phi_\lambda=\lambda d_1^2+(1-\lambda)d_2^2, $$ which depends only on the supports of the initial measures and on the mixing parameter. This gives a rigorous reduction from a singular, non-autonomous score-driven dynamics to autonomous Clarke-type subgradient inclusions. In the empirical setting of finite Dirac mixtures, the limiting potential is piecewise quadratic with a Voronoi-type structure; this rigidity yields convergence of all autonomous limiting trajectories to critical points and a conditional convergence criterion for the original generation flow toward local minimizers of the potential, with rate $\mathcal O(\sqrt t)$ in the smooth stable case.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes small-time generation dynamics in diffusion models driven by mixed scores s = λ ∇log u₁ + (1-λ) ∇log u₂ (λ ≥ 0), where u₁ and u₂ are heat evolutions of compactly supported probability measures. This covers both mixture-of-experts (0 ≤ λ ≤ 1) and classifier-free guidance (λ > 1). Exploiting a Laplace-Varadhan principle under similarity-time rescaling, the authors show that the dynamics reduce to an autonomous Clarke subgradient flow on the explicit geometric potential Φ_λ = λ d₁² + (1-λ) d₂², which depends only on the supports of the initial measures. For finite Dirac mixtures the limiting potential is piecewise quadratic with Voronoi structure; this yields convergence of all limiting trajectories to critical points and a conditional convergence criterion for the original flow toward local minimizers, with rate O(√t) in the smooth stable case.
Significance. If the central reduction holds, the work supplies a rigorous geometric foundation for score mixing and guidance, two techniques central to practical diffusion models. The explicit, support-dependent potential Φ_λ together with the reduction from a singular non-autonomous SDE to an autonomous subgradient inclusion is a clear strength; the compact-support hypothesis is used effectively to obtain coercivity and compact sublevel sets without extra tail conditions. The piecewise-quadratic Voronoi analysis for Dirac mixtures and the explicit convergence rate in the stable case are concrete, falsifiable contributions that could guide both theoretical analysis and empirical design of guided samplers.
major comments (2)
- [Abstract and §3] Abstract and §3 (Laplace-Varadhan reduction): the claim of a rigorous passage from the non-autonomous score-driven SDE to the limiting Clarke inclusion is load-bearing, yet the manuscript provides no explicit error estimates or quantitative rate for the rescaled large-deviation approximation in the singular regime (λ > 1). Without these bounds it is difficult to confirm the precise scope of the compact-support assumption.
- [§4] §4 (Dirac-mixture case): the stated O(√t) convergence rate to local minimizers is given only for the smooth stable case; the manuscript should clarify whether this rate survives when the limiting potential Φ_λ has non-differentiable Voronoi edges, as these are the generic points for finite mixtures.
minor comments (3)
- [Abstract] The distance functions d₁ and d₂ (distances to the supports) are used throughout but never defined explicitly in the abstract or early sections; a short sentence recalling d_i(x) = inf_{y ∈ supp(μ_i)} |x - y| would improve readability.
- [§2] The term “similarity-time rescaling” is introduced without the precise change-of-variable formula; adding the explicit time substitution (e.g., τ = -log t or equivalent) in the first paragraph of §2 would help readers track the large-deviation scaling.
- [§3] Notation for the Clarke subdifferential ∂^C Φ_λ is used in the limiting inclusion but never contrasted with the classical gradient; a one-sentence reminder that the inclusion reduces to the gradient flow wherever Φ_λ is differentiable would clarify the statement.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment, and recommendation for minor revision. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Laplace-Varadhan reduction): the claim of a rigorous passage from the non-autonomous score-driven SDE to the limiting Clarke inclusion is load-bearing, yet the manuscript provides no explicit error estimates or quantitative rate for the rescaled large-deviation approximation in the singular regime (λ > 1). Without these bounds it is difficult to confirm the precise scope of the compact-support assumption.
Authors: The Laplace-Varadhan principle under similarity-time rescaling yields a rigorous asymptotic reduction of the rescaled process to the autonomous Clarke subgradient inclusion as the time parameter tends to zero. The compact-support hypothesis is used precisely to guarantee the large-deviation principle and the coercivity of Φ_λ, without requiring extra tail conditions. Explicit quantitative error bounds for the approximation in the singular regime λ > 1 are not needed to establish the limiting geometric structure or the convergence statements for Dirac mixtures. We will add a clarifying paragraph in Section 3 on the sense of convergence (viscosity solutions) and note that rate estimates constitute an open direction. revision: partial
-
Referee: [§4] §4 (Dirac-mixture case): the stated O(√t) convergence rate to local minimizers is given only for the smooth stable case; the manuscript should clarify whether this rate survives when the limiting potential Φ_λ has non-differentiable Voronoi edges, as these are the generic points for finite mixtures.
Authors: The O(√t) rate is derived only when the trajectory approaches a point at which Φ_λ is locally C² with positive-definite Hessian (the smooth stable case). At generic non-differentiable Voronoi edges the subgradient inclusion still forces convergence to critical points, but the rate typically slows (e.g., O(t^{1/3}) near codimension-1 edges). We will revise Section 4 to restrict the stated rate explicitly to the smooth stable case and add a short remark on the non-smooth regime. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives the governing potential Φ_λ via direct application of the standard Laplace-Varadhan large-deviation principle to a similarity-time rescaling of the heat kernels generated by compactly supported initial measures. This produces an explicit expression Φ_λ = λ d₁² + (1-λ) d₂² constructed solely from the distance functions to the supports, without parameter fitting, self-referential definitions, or load-bearing self-citations. The reduction from the non-autonomous score-driven SDE to the autonomous Clarke subgradient inclusion follows from the asymptotic analysis and the coercivity ensured by compact support; all steps remain independent of the target result and rely on externally verifiable principles rather than circular inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption u1 and u2 are heat evolutions of compactly supported probability measures
- standard math Laplace-Varadhan principle applies under the similarity-time rescaling
invented entities (1)
-
geometric potential Φ_λ = λ d1² + (1-λ) d2²
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearExploiting a Laplace-Varadhan principle under a similarity-time rescaling, we show that the small-time generation dynamics is governed by the explicit geometric potential Φ_λ=λ d1²+(1-λ)d2²
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearthe limiting potential is piecewise quadratic with a Voronoi-type structure
Reference graph
Works this paper leans on
-
[1]
B. D. O. Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982
work page 1982
-
[2]
H.Attouchand J.Bolte. On theconvergenceofthe proximal algorithm fornonsmooth functions involving analytic features.Mathematical Programming, 116(1–2):5–16, 2009
work page 2009
-
[3]
J.-P. Aubin and H. Frankowska.Set-Valued Analysis. Systems & Control: Foundations & Applications. Birkhäuser Boston, 1990
work page 1990
-
[4]
Systems & Control: Foundations & Applications
Martino Bardi and Italo Capuzzo-Dolcetta.Optimal Control and Viscosity Solutions of Hamilton-Jacobi-Bellman Equations. Systems & Control: Foundations & Applications. Birkhäuser Boston, Boston, MA, 1997
work page 1997
-
[5]
M. Benaïm and M. W. Hirsch. Asymptotic pseudotrajectories and chain recurrent flows, with applications.Journal of Dynamics and Differential Equations, 8(1):141–176, 1996
work page 1996
- [6]
-
[7]
C. M. Bender and S. A. Orszag.Advanced Mathematical Methods for Scientists and Engineers I: Asymptotic Methods and Perturbation Theory. Springer, 2013
work page 2013
- [8]
-
[9]
C. M. Bishop.Neural Networks for Pattern Recognition. Oxford University Press, 1995
work page 1995
-
[10]
S. Chen, S. Chewi, J. Li, Y. Li, A. Salim, and A. R. Zhang. Sampling is as easy as learning the score: Theory for diffusion models with minimal data assumptions. InInternational Conference on Learning Representations, 2023
work page 2023
-
[11]
M. Chidambaram, K. Gatmiry, S. Chen, H. Lee, and J. Lu. What does guidance do? a fine- grained analysis in a simple setting. InAdvances in Neural Information Processing Systems, volume 37, pages 84968–85005, 2024
work page 2024
-
[12]
F. H. Clarke.Optimization and Nonsmooth Analysis. Wiley, 1989. 60
work page 1989
-
[13]
G. Conforti, A. Durmus, and M. Gentiloni Silveri. KL convergence guarantees for score diffusion models under minimal data assumptions.SIAM Journal on Mathematics of Data Science, 7(1):86–109, 2025
work page 2025
-
[14]
J. Cortés. Discontinuous dynamical systems: A tutorial on solutions, nonsmooth analysis, and stability.IEEE Control Systems Magazine, 28(3):36–73, 2008
work page 2008
-
[15]
Crandall, Hitoshi Ishii, and Pierre-Louis Lions
Michael G. Crandall, Hitoshi Ishii, and Pierre-Louis Lions. User’s guide to viscosity solutions of second order partial differential equations.Bulletin of the American Mathematical Society, 27(1):1–67, 1992
work page 1992
-
[16]
A. Dembo and O. Zeitouni.Large Deviations Techniques and Applications, volume 38 ofAp- plications of Mathematics. Springer, New York, 2 edition, 1998
work page 1998
-
[17]
P. Dhariwal and A. Q. Nichol. Diffusion models beat GANs on image synthesis. InAdvances in Neural Information Processing Systems, volume 34, pages 8780–8794, 2021
work page 2021
-
[18]
K. Fukunaga and L. D. Hostetler. The estimation of the gradient of a density function, with applications in pattern recognition.IEEE Transactions on Information Theory, 21(1):32–40, 1975
work page 1975
-
[19]
V. A. Galaktionov and J. L. Vázquez. Asymptotic behaviour of nonlinear parabolic equa- tions with critical exponents: A dynamical systems approach.Journal of Functional Analysis, 100(2):435–462, 1991
work page 1991
-
[20]
V. A. Galaktionov and J. L. Vázquez.A Stability Technique for Evolution Partial Differential Equations: A Dynamical Systems Approach, volume 56 ofProgress in Nonlinear Differential Equations and Their Applications. Birkhäuser, 2004
work page 2004
-
[21]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems, volume 27, 2014
work page 2014
-
[22]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
- [23]
-
[24]
Estimationofnon-normalizedstatisticalmodelsbyscorematching
A.HyvärinenandP.Dayan. Estimationofnon-normalizedstatisticalmodelsbyscorematching. Journal of Machine Learning Research, 6(4):695–709, 2005
work page 2005
-
[25]
I.KaratzasandS.E.Shreve.Brownian Motion and Stochastic Calculus, volume113ofGraduate Texts in Mathematics. Springer, 2 edition, 1991
work page 1991
- [26]
-
[27]
D. P. Kingma and Y. LeCun. Regularized estimation of image statistics by score matching. In Advances in Neural Information Processing Systems, volume 23, 2010
work page 2010
-
[28]
D. P. Kingma and M. Welling. Auto-encoding variational Bayes. InInternational Conference on Learning Representations, 2014. 61
work page 2014
-
[29]
B. Klartag and O. Ordentlich. The strong data processing inequality under the heat flow.IEEE Transactions on Information Theory, 2025
work page 2025
-
[30]
H. Lee, J. Lu, and Y. Tan. Convergence for score-based generative modeling with polynomial complexity. InAdvances in Neural Information Processing Systems, volume 35, pages 22870– 22882, 2022
work page 2022
-
[31]
P. Li and S.-T. Yau. On the parabolic kernel of the Schrödinger operator.Acta Mathematica, 156:153–201, 1986
work page 1986
-
[32]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. M. Stuart, and A. Anand- kumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021
work page 2021
-
[33]
Z. Li, K. Liu, L. Liverani, and E. Zuazua. Universal approximation of dynamical systems by semiautonomous neural ODEs and applications.SIAM Journal on Numerical Analysis, 64(1):193–223, 2026
work page 2026
-
[34]
Z. Li, K. Liu, Y. Song, H. Yue, and E. Zuazua. Deep neural ODE operator networks for PDEs. Mathematical Models and Methods in Applied Sciences, 2026
work page 2026
-
[35]
A PDE Perspective on Generative Diffusion Models
K. Liu and E. Zuazua. A PDE perspective on generative diffusion models, 2025. Preprint at https://arxiv.org/abs/2511.05940
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
S. Łojasiewicz. Ensembles semi-analytiques, 1965. Lecture notes, Institut des Hautes Études Scientifiques
work page 1965
-
[37]
C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems, volume 35, pages 5775–5787, 2022
work page 2022
-
[38]
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intel- ligence, 3(3):218–229, 2021
work page 2021
-
[39]
L. Markus. Asymptotically autonomous differential systems. InContributions to the Theory of Nonlinear Oscillations, Vol. III, volume 36 ofAnnals of Mathematics Studies, pages 17–29. Princeton University Press, Princeton, NJ, 1956
work page 1956
-
[40]
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas. Communication- efficient learning of deep networks from decentralized data. InProceedings of the 20th Interna- tional Conference on Artificial Intelligence and Statistics, 2017
work page 2017
-
[41]
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
work page 2023
-
[42]
P. Rahimi and S. Marcel. ScoreMix: Improving face recognition via score composition in diffusion generators, 2025. Preprint athttps://arxiv.org/abs/2506.10226
- [43]
-
[44]
H. Robbins and S. Monro. A stochastic approximation method.Annals of Mathematical Statistics, 22(3):400–407, 1951
work page 1951
-
[45]
R. T. Rockafellar and R. J.-B. Wets.Variational Analysis, volume 317 ofGrundlehren der Mathematischen Wissenschaften. Springer, 1998
work page 1998
-
[46]
O. Ronneberger, P. Fischer, and T. Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, volume 9351 ofLecture Notes in Computer Science, pages 234–241. Springer, 2015
work page 2015
- [47]
-
[48]
L. Simon. Asymptotics for a class of nonlinear evolution equations, with applications to geo- metric problems.Annals of Mathematics, 118(3):525–571, 1983
work page 1983
-
[49]
Y. Song and S. Ermon. Generative modeling by estimating gradients of the data distribution. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[50]
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021
work page 2021
-
[51]
C. Villani.Hypocoercivity. American Mathematical Society, 2009
work page 2009
-
[52]
P. Vincent. A connection between score matching and denoising autoencoders.Neural Com- putation, 23(7):1661–1674, 2011
work page 2011
-
[53]
X. Wang, N. Dufour, N. Andreou, M.-P. Cani, V. Fernández Abrevaya, D. Picard, and V. Kalo- geiton. Analysisofclassifier-freeguidanceweightschedulers.Transactions on Machine Learning Research, 2024
work page 2024
- [54]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.