Recognition: no theorem link
UHR-Micro: Diagnosing and Mitigating the Resolution Illusion in Earth Observation VLMs
Pith reviewed 2026-05-13 06:28 UTC · model grok-4.3
The pith
VLMs show a resolution illusion on UHR Earth observation imagery where higher resolution does not improve micro-target perception; UHR-Micro benchmark and MAP-Agent address this via evidence-centered active inspection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
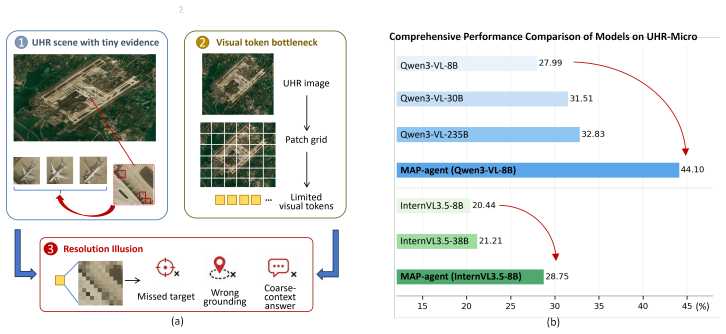
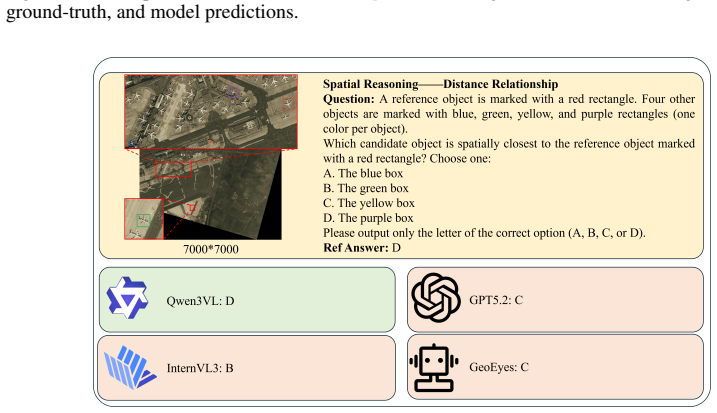
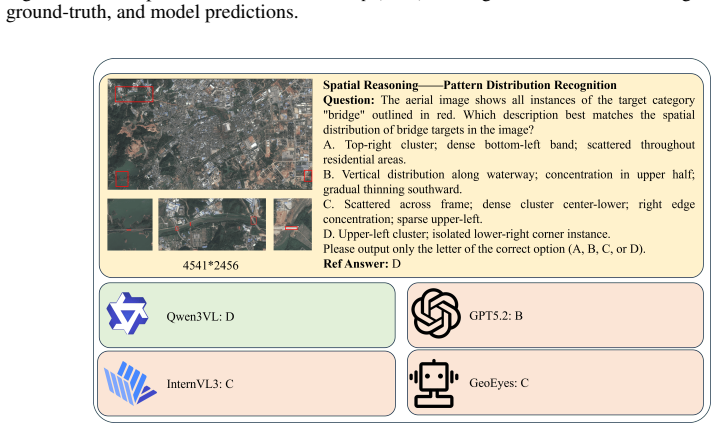
Experiments with representative high-resolution VLMs show substantial failures in spatial grounding and evidence parsing, despite access to high-resolution inputs. Further analysis suggests that these failures are not fully resolved by increasing model capacity, but are closely tied to insufficient guidance in locating and using task-relevant micro-evidence.
Load-bearing premise
That the observed failures stem primarily from lack of guidance in locating micro-evidence and that MAP-Agent's decomposition and active inspection will locate and use that evidence without introducing new errors or excessive computational cost.
Figures

















read the original abstract
Vision-Language Models (VLMs) increasingly operate on ultra-high-resolution (UHR) Earth observation imagery, yet they remain vulnerable to a severe scale mismatch between large-scale scene context and micro-scale targets. We refer to this empirical gap as a "resolution illusion": higher input resolution provides the appearance of richer visual detail, but does not necessarily yield reliable perception of spatially small, task-relevant evidence. To benchmark this challenge, we introduce UHR-Micro, a benchmark comprising 11,253 instructions grounded in 1,212 UHR images, designed to evaluate VLMs at the spatial limits of native Earth observation imagery. UHR-Micro spans diverse micro-target scales, context requirements, task families, and visual conditions, and provides diagnostic annotations that support controlled evaluation and fine-grained error attribution. Experiments with representative high-resolution VLMs show substantial failures in spatial grounding and evidence parsing, despite access to high-resolution inputs. Further analysis suggests that these failures are not fully resolved by increasing model capacity, but are closely tied to insufficient guidance in locating and using task-relevant micro-evidence. Motivated by this finding, we propose Micro-evidence Active Perception (MAP), a reference agent that decomposes queries into evidence-seeking steps, actively inspects candidate regions, and grounds its answers in localized observations. MAP-Agent improves micro-level perception by making high-resolution reasoning evidence-centered rather than image-centered. Together, UHR-Micro and MAP-Agent provide a diagnostic platform for evaluating, understanding, and advancing high-resolution reasoning in Earth observation VLMs. Datasets and source code were released at https://github.com/MiliLab/UHR-Micro.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the UHR-Micro benchmark consisting of 11,253 instructions grounded in 1,212 ultra-high-resolution Earth observation images to diagnose a 'resolution illusion' in VLMs: higher native resolution inputs do not reliably enable perception of spatially small, task-relevant micro-evidence. Experiments on representative high-resolution VLMs demonstrate substantial failures in spatial grounding and evidence parsing. Analysis indicates these failures are not resolved by model capacity scaling alone but stem from insufficient guidance in locating micro-evidence. The authors propose the MAP-Agent, which decomposes queries into evidence-seeking steps, performs active region inspection, and grounds answers in localized observations, claiming improved micro-level perception.
Significance. If the empirical claims hold after detailed validation, the work supplies a needed diagnostic benchmark and agent framework for high-resolution reasoning in Earth observation VLMs, a domain where micro-scale targets are common. The open release of the dataset and code supports reproducibility and further research on evidence-centered perception.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the claim that failures 'are not fully resolved by increasing model capacity' rests on unspecified analysis; no model variants, capacity scaling protocol, exact metrics (e.g., grounding accuracy, evidence recall), error bars, or data splits are reported, making it impossible to evaluate whether the central claim is supported.
- [MAP-Agent / Results] MAP-Agent description and results: the mitigation benefit is presented as evidence that insufficient guidance is the primary cause, yet no quantitative breakdown of agent error modes (missed candidates, spurious observations, localization errors) versus baseline failures is provided; this leaves the load-bearing assumption that decomposition plus active inspection succeeds without new artifacts untested.
minor comments (2)
- [Introduction] The term 'resolution illusion' is introduced without a formal definition or illustrative example that distinguishes it from standard scale-variance issues in vision models.
- [Benchmark construction] Benchmark statistics (11,253 instructions, 1,212 images) are given but no table or section details the distribution across micro-target scales, task families, or visual conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate the requested clarifications and analyses into the revised version to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claim that failures 'are not fully resolved by increasing model capacity' rests on unspecified analysis; no model variants, capacity scaling protocol, exact metrics (e.g., grounding accuracy, evidence recall), error bars, or data splits are reported, making it impossible to evaluate whether the central claim is supported.
Authors: We agree that the analysis supporting the claim requires additional detail for full evaluability. In the revised manuscript, we will expand the Experiments section to explicitly describe the model variants tested (different parameter scales within representative VLM families), the capacity scaling protocol, the precise metrics including grounding accuracy and evidence recall, error bars computed over multiple runs, and the data splits used. This will provide transparent quantitative evidence that micro-evidence perception failures persist across scales. revision: yes
-
Referee: [MAP-Agent / Results] MAP-Agent description and results: the mitigation benefit is presented as evidence that insufficient guidance is the primary cause, yet no quantitative breakdown of agent error modes (missed candidates, spurious observations, localization errors) versus baseline failures is provided; this leaves the load-bearing assumption that decomposition plus active inspection succeeds without new artifacts untested.
Authors: We acknowledge that a quantitative error-mode breakdown is needed to confirm that MAP-Agent improvements arise from better guidance rather than new failure modes. In the revision, we will add a dedicated analysis in the Results section reporting the frequency of each error type (missed candidates, spurious observations, localization errors) for MAP-Agent versus baselines, enabling direct comparison and verification that active inspection enhances micro-level perception without introducing substantial new artifacts. revision: yes
Circularity Check
No circularity: empirical benchmark and agent proposal are self-contained
full rationale
The paper introduces the UHR-Micro benchmark with 11,253 instructions on 1,212 images and evaluates representative VLMs, showing failures in spatial grounding. It then proposes MAP-Agent to decompose queries and actively inspect regions, motivated by the empirical observation that failures tie to insufficient guidance rather than capacity alone. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All claims rest on direct experimental results and diagnostic annotations, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can ingest and reason over native ultra-high-resolution imagery without downsampling artifacts dominating performance
invented entities (2)
-
resolution illusion
no independent evidence
-
MAP-Agent
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Xiao An, Jiaxing Sun, Zihan Gui, and Wei He. Choice: benchmarking the remote sensing capabilities of large vision-language models.Advances in Neural Information Processing Systems, 38, 2026
work page 2026
-
[3]
Anthropic. Claude 3.7 sonnet, 2025. URL https://www.anthropic.com/news/ claude-3-7-sonnet
work page 2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
work page 2024
-
[6]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
A benchmark for ultra-high-resolution remote sensing mllms.arXiv preprint arXiv:2512.17319, 2025
Yunkai Dang, Meiyi Zhu, Donghao Wang, Yizhuo Zhang, Jiacheng Yang, Qi Fan, Yuekun Yang, Wenbin Li, Feng Miao, and Yang Gao. A benchmark for ultra-high-resolution remote sensing mllms.arXiv preprint arXiv:2512.17319, 2025
-
[9]
Geobench-vlm: Benchmarking vision- language models for geospatial tasks
Muhammad Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Kartik Kuckreja, Fahad Shahbaz Khan, Paolo Fraccaro, Alexandre Lacoste, and Salman Khan. Geobench-vlm: Benchmarking vision- language models for geospatial tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7132–7142, 2025
work page 2025
-
[10]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fa- had Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 27831–27840, 2024
work page 2024
-
[12]
xview: Objects in context in overhead imagery,
Darius Lam, Richard Kuzma, Kevin McGee, Samuel Dooley, Michael Laielli, Matthew Klaric, Yaroslav Bulatov, and Brendan McCord. xview: Objects in context in overhead imagery.arXiv preprint arXiv:1802.07856, 2018
-
[13]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
work page 2023
-
[15]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[16]
Ruixun Liu, Bowen Fu, Jiayi Song, Kaiyu Li, Wanchen Li, Lanxuan Xue, Hui Qiao, Weizhan Zhang, Deyu Meng, and Xiangyong Cao. Zoomearth: Active perception for ultra-high-resolution geospatial vision-language tasks.arXiv preprint arXiv:2511.12267, 2025
-
[17]
Rotated multi-scale interaction network for referring remote sensing image segmentation
Sihan Liu, Yiwei Ma, Xiaoqing Zhang, Haowei Wang, Jiayi Ji, Xiaoshuai Sun, and Rongrong Ji. Rotated multi-scale interaction network for referring remote sensing image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26658–26668, 2024
work page 2024
-
[18]
Yi Liu, Jing Zhang, Di Wang, Xiaoyu Tian, Haonan Guo, and Bo Du. Seeing clearly without training: Mitigating hallucinations in multimodal llms for remote sensing.arXiv preprint arXiv:2603.02754, 2026
-
[19]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[20]
Sylvain Lobry, Diego Marcos, Jesse Murray, and Devis Tuia. Rsvqa: Visual question answering for remote sensing data.IEEE Transactions on Geoscience and Remote Sensing, 58(12):8555–8566, 2020
work page 2020
-
[21]
Xiaoqiang Lu, Binqiang Wang, Xiangtao Zheng, and Xuelong Li. Exploring models and data for remote sensing image caption generation.IEEE Transactions on Geoscience and Remote Sensing, 56(4):2183– 2195, 2017
work page 2017
-
[22]
Aref Miri Rekavandi, Shima Rashidi, Farid Boussaid, Stephen Hoefs, Emre Akbas, and Mohammed Bennamoun. Transformers in small object detection: A benchmark and survey of state-of-the-art.ACM Computing Surveys, 58(3):1–33, 2025
work page 2025
-
[23]
Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model
Dilxat Muhtar, Zhenshi Li, Feng Gu, Xueliang Zhang, and Pengfeng Xiao. Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model. InEuropean Conference on Computer Vision, pages 440–457. Springer, 2024
work page 2024
-
[24]
UniGeoSeg: Towards Unified Open-World Segmentation for Geospatial Scenes
Shuo Ni, Di Wang, He Chen, Haonan Guo, Ning Zhang, and Jing Zhang. Unigeoseg: Towards unified open-world segmentation for geospatial scenes.arXiv preprint arXiv:2511.23332, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[26]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. 2025:28085–28128, 2025
work page 2025
-
[27]
Geopixel: Pixel grounding large multimodal model in remote sensing
Akashah Shabbir, Mohammed Zumri, Mohammed Bennamoun, Fahad Shahbaz Khan, and Salman Khan. Geopixel: Pixel grounding large multimodal model in remote sensing. InInternational Conference on Machine Learning, pages 54095–54111. PMLR, 2025
work page 2025
-
[28]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Xian Sun, Peijin Wang, Zhiyuan Yan, Feng Xu, Ruiping Wang, Wenhui Diao, Jin Chen, Jihao Li, Yingchao Feng, Tao Xu, et al. Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery.ISPRS Journal of Photogrammetry and Remote Sensing, 184:116–130, 2022
work page 2022
-
[30]
Visual grounding in remote sensing images
Yuxi Sun, Shanshan Feng, Xutao Li, Yunming Ye, Jian Kang, and Xu Huang. Visual grounding in remote sensing images. InProceedings of the 30th ACM International conference on Multimedia, pages 404–412, 2022
work page 2022
-
[31]
Fengxiang Wang, Mingshuo Chen, Xuming He, Yi-Fan Zhang, Yueying Li, Feng Liu, Zijie Guo, Zhenghao Hu, Jiong Wang, Jingyi Xu, et al. Omniearth-bench: Towards holistic evaluation of earth’s six spheres and cross-spheres interactions with multimodal observational earth data, 2025. 11
work page 2025
-
[32]
Fengxiang Wang, Hongzhen Wang, Zonghao Guo, Di Wang, Yulin Wang, Mingshuo Chen, Qiang Ma, Long Lan, Wenjing Yang, Jing Zhang, et al. Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14325–14336, 2025
work page 2025
-
[33]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Di Wang, Haotian Wang, Zonghao Guo, Zefan Wang, Shan Boqi, Long Lan, Yulin Wang, et al. Geollava-8k: scaling remote-sensing multimodal large language models to 8k resolution.Advances in Neural Information Processing Systems, 38:159185–159218, 2026
work page 2026
-
[34]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Yajie Yang, Yifan Zhang, Long Lan, Xue Yang, Hongda Sun, Yulin Wang, Di Wang, et al. Geoeyes: On-demand visual focusing for evidence-grounded understanding of ultra-high-resolution remote sensing imagery.arXiv preprint arXiv:2602.14201, 2026
-
[35]
Tiny object detection in aerial images
Jinwang Wang, Wen Yang, Haowen Guo, Ruixiang Zhang, and Gui-Song Xia. Tiny object detection in aerial images. In2020 25th international conference on pattern recognition (ICPR), pages 3791–3798. IEEE, 2021
work page 2021
-
[36]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Dota: A large-scale dataset for object detection in aerial images
Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Belongie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liangpei Zhang. Dota: A large-scale dataset for object detection in aerial images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3974–3983, 2018
work page 2018
-
[39]
Dongjie Yang, Xianjun Gao, Yuanwei Yang, Kangliang Guo, Kuikui Han, and Lei Xu. Advances and future prospects in building extraction from high-resolution remote sensing images.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 18:6994–7016, 2025
work page 2025
-
[40]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
work page 2016
-
[41]
Yang Zhan, Zhitong Xiong, and Yuan Yuan. Rsvg: Exploring data and models for visual grounding on remote sensing data.IEEE transactions on geoscience and remote sensing, 61:1–13, 2023
work page 2023
-
[42]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625–5644, 2024
work page 2024
-
[43]
YiFan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans? 2025:89655–89701, 2025
work page 2025
-
[44]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International journal of computer vision, 130(9):2337–2348, 2022. 12 Appendix Appendix Contents Appendix A. Dataset Construction Details. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.