Recognition: 2 theorem links
· Lean TheoremPreScam: A Benchmark for Predicting Scam Progression from Early Conversations
Pith reviewed 2026-05-13 05:11 UTC · model grok-4.3
The pith
A benchmark from real scam reports shows language models spot some cues but fail to track how manipulation escalates over turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
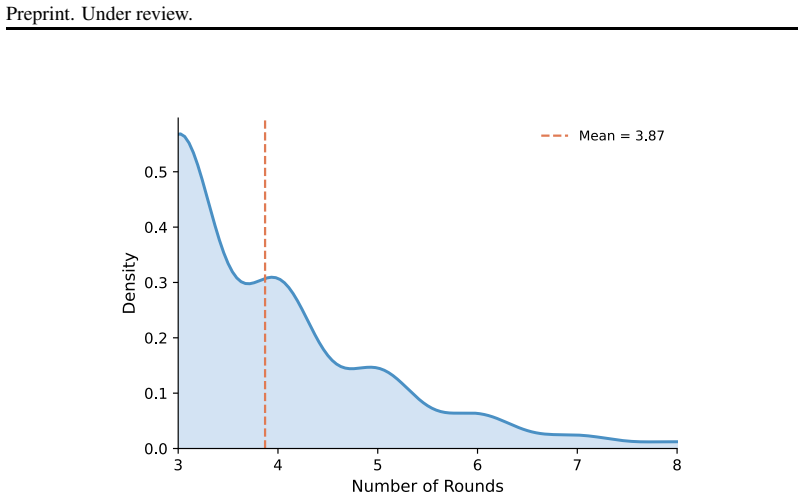
PreScam supplies 11,573 structured conversational scam instances derived from 177,989 raw reports. When models are tested on real-time termination prediction and scammer next-action prediction, supervised encoders substantially outperform zero-shot LLMs on the first task while next-action prediction stays only moderately successful even for strong LLMs, revealing a gap between handling fluent text and modeling progressive manipulation.
What carries the argument
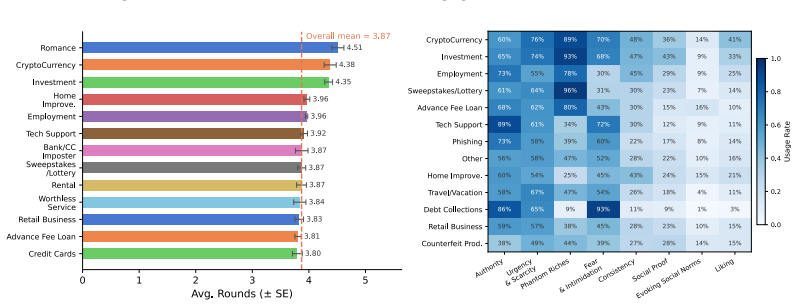
The scam kill chain, a hierarchical structure that divides each conversation into lifecycle stages and supplies turn-level annotations of scammer psychological actions and victim responses.
If this is right
- Improved termination prediction could enable chat platforms to issue early warnings before victims reach the final loss stage.
- Moderate action-prediction performance indicates that explicit stage labels help supervised models capture escalation patterns that zero-shot LLMs miss.
- The gap between fluency and progression tracking suggests future training regimes must incorporate explicit lifecycle supervision rather than raw text alone.
- Benchmark results can guide the design of specialized detectors that intervene at intermediate manipulation stages rather than only at the end.
Where Pith is reading between the lines
- If progression models improve, messaging services could embed real-time risk meters that flag conversations before money or personal data changes hands.
- The same kill-chain approach could be adapted to study other gradual online deceptions such as grooming or coordinated misinformation campaigns.
- Pairing the benchmark with victim-response prediction might expose which reply patterns accelerate or slow escalation, opening a path to protective coaching tools.
Load-bearing premise
User-submitted scam reports, after filtering and structuring, supply accurate ground-truth labels for how real scams progress and what tactics they employ.
What would settle it
Running the same models on a fresh collection of verified scam transcripts obtained from law-enforcement records or controlled victim recordings would show whether the benchmark's progression labels match actual events.
Figures



read the original abstract
Conversational scams, such as romance and investment scams, are emerging as a major form of online fraud. Unlike one-shot scam lures such as fake lottery or unpaid toll messages, they unfold through multi-turn conversations in which scammers gradually manipulate victims using evolving psychological techniques. However, existing research mainly focuses on static scam detection or synthetic scams, leaving open whether language models can understand how real-world scams progress over time. We introduce PreScam, a benchmark for modeling scam progression from early conversations. Built from user-submitted scam reports, PreScam filters and structures 177,989 raw reports into 11,573 conversational scam instances spanning 20 scam categories. Each instance is hierarchically structured according to the scam lifecycle defined by the proposed scam kill chain, and further annotated at the turn level with scammer psychological actions and victim responses. We benchmark models on two tasks: real-time termination prediction, which estimates whether a conversation is approaching the termination stage, and scammer action prediction, which forecasts the scammer's subsequent actions. Results show a clear gap between surface-level fluency and progression modeling: supervised encoders substantially outperform zero-shot LLMs on real-time termination prediction, while next-action prediction remains only moderately successful even for strong LLMs. Taken together, these results show that current models can capture some scam-related cues, yet still struggle to track how risk escalates and how manipulation unfolds across turns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PreScam, a benchmark for modeling scam progression from early conversations. It filters and structures 177,989 user-submitted scam reports into 11,573 instances across 20 categories using a proposed scam kill chain, with turn-level annotations for psychological actions and victim responses. Models are benchmarked on real-time termination prediction and scammer next-action prediction, revealing that supervised encoders outperform zero-shot LLMs on the former while the latter remains challenging even for strong LLMs.
Significance. If the constructed labels prove reliable, this benchmark usefully demonstrates limitations in current language models for tracking conversational manipulation and risk escalation beyond surface-level fluency. The creation of a large-scale structured dataset from real user reports rather than synthetic data is a clear strength that could support future proactive fraud detection research.
major comments (3)
- [§3.2] §3.2: The reduction from 177,989 raw reports to 11,573 instances lacks any analysis of selection effects, characteristics of discarded reports, or potential biases introduced by the filtering and structuring process. This is load-bearing for the central claim that observed performance gaps reflect genuine modeling limitations rather than artifacts of the data construction.
- [§3.3] §3.3: No inter-annotator agreement scores or validation against verified scam transcripts are reported for the turn-level psychological action and victim response annotations. This directly undermines confidence in the ground-truth fidelity required to interpret the gap between supervised encoders and zero-shot LLMs on termination prediction.
- [§4.1] §4.1: The experimental setup provides insufficient detail on model architectures, data splits, hyperparameter choices, and statistical significance tests for the reported performance differences. Without these, the claim of a 'clear gap' between surface-level fluency and progression modeling cannot be rigorously evaluated.
minor comments (2)
- [Abstract] The abstract would be strengthened by including one or two key quantitative metrics (e.g., F1 scores) alongside the qualitative description of the performance gap.
- [Figure 1] Figure 1 (scam kill chain diagram) could benefit from an accompanying example conversation snippet to illustrate how the hierarchy maps to actual turns.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the rigor and transparency of our work. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [§3.2] The reduction from 177,989 raw reports to 11,573 instances lacks any analysis of selection effects, characteristics of discarded reports, or potential biases introduced by the filtering and structuring process. This is load-bearing for the central claim that observed performance gaps reflect genuine modeling limitations rather than artifacts of the data construction.
Authors: We agree that a detailed analysis of the filtering pipeline is essential to rule out artifacts. In the revised manuscript, we will add a dedicated subsection (or appendix) that reports: (i) aggregate statistics on discarded reports (length, category distribution, and primary exclusion reasons such as insufficient turns or non-scam content), (ii) a side-by-side comparison of retained versus discarded samples on key metadata features, and (iii) an explicit discussion of self-selection bias inherent to user-submitted reports and how the scam-kill-chain structuring may affect category balance. These additions will directly support the claim that performance differences arise from modeling challenges rather than data-construction artifacts. revision: yes
-
Referee: [§3.3] No inter-annotator agreement scores or validation against verified scam transcripts are reported for the turn-level psychological action and victim response annotations. This directly undermines confidence in the ground-truth fidelity required to interpret the gap between supervised encoders and zero-shot LLMs on termination prediction.
Authors: We acknowledge that reporting inter-annotator agreement is necessary for establishing annotation reliability. The annotations followed a detailed codebook aligned with the scam kill chain; in revision we will compute and report Fleiss’ kappa (or equivalent) on a held-out sample of turns for both psychological-action and victim-response labels. For external validation, we note that the source material consists of real user-submitted reports rather than laboratory transcripts, limiting direct access to independently verified ground truth. We will nevertheless add a manual audit of a random subset against documented scam-progression patterns from public sources and literature, together with a clear limitations paragraph on the self-reported nature of the data. These steps will materially increase confidence in the labels used for the termination-prediction task. revision: partial
-
Referee: [§4.1] The experimental setup provides insufficient detail on model architectures, data splits, hyperparameter choices, and statistical significance tests for the reported performance differences. Without these, the claim of a 'clear gap' between surface-level fluency and progression modeling cannot be rigorously evaluated.
Authors: We concur that additional experimental detail is required for reproducibility and for rigorous assessment of the reported gaps. In the revised §4.1 we will specify: exact model architectures and checkpoints, train/validation/test split ratios and stratification strategy, hyperparameter search ranges and selection criteria, training hyperparameters (batch size, learning rate, epochs), and statistical significance tests (bootstrap confidence intervals or paired tests) for all performance differences. We will also release the full experimental configuration files. These expansions will allow readers to evaluate the surface-fluency versus progression-modeling distinction with full transparency. revision: yes
Circularity Check
Empirical benchmark construction with no self-referential derivations
full rationale
The paper introduces PreScam as a dataset and benchmark derived from filtering and annotating 177,989 external user-submitted scam reports into 11,573 instances, structured by a proposed scam kill chain and turn-level labels. The two tasks (real-time termination prediction and scammer action prediction) are standard supervised evaluation on this constructed data. No equations, fitted parameters, or first-principles claims reduce to inputs by construction; results compare model performance without self-definition or self-citation load-bearing. This is a normal non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conversational scams follow a definable lifecycle (scam kill chain) that can be used to hierarchically structure instances and annotations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Scam Kill Chain, a representation that maps the temporal phases of a scam conversation to actions driven by psychological techniques... three primary phases: Initial Contact, Engagement, and Termination.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
real-time termination prediction... Area Under the Risk Curve (AUC)... Alert Time (AT@FPRα)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
"multi-round dialogue": The report contains direct chat logs or conversation transcripts with back-and-forth messages between the victim and scammer
-
[2]
"multi-round description": The report describes a sequence of multiple interactions over time, showing a process with multiple exchanges. Single-round means: The report only describes a one-time event or a single interaction without follow-up exchanges. Report: """ {description} """ Analyze and respond in this exact format: RESULT: [YES or NO] Only output...
-
[3]
initial_contact: A concise summary (1-2 sentences) of how the scammer first reached or lured the victim
-
[4]
Each round MUST have at least one PT
engagement: A list of interaction rounds where the scammer uses psychological techniques. Each round MUST have at least one PT. For each round, extract: - scammer_action: A concise summary (1-2 sentences) of what the scammer did or said in this round. - scammer_action_verbatim: The VERBATIM text from the report that corresponds to the scammer's action. Co...
-
[5]
outcome: A concise summary (1-2 sentences) of the final result, such as the victim realizing it is a scam, losing money, or the scammer disappearing. psychological techniques (PTs) {pt_definitions} Critical Rules - For scammer_action and victim_action: use concise, factual summaries in 1-2 sentences. - For scammer_action_verbatim and victim_action_verbati...
-
[6]
PT accuracy: Is each PT correctly assigned? Remove incorrect PTs and add missing ones
-
[7]
PT completeness: Every engagement round MUST have at least one PT. If a round has no valid PT after review, merge it into an adjacent round or move it to initial_contact or outcome
-
[8]
Round granularity: Should any rounds be split or merged?
-
[9]
Role separation: Is any victim behavior described in scammer_action, or vice versa?
-
[10]
Chronological order: Are the rounds in the correct time sequence?
-
[11]
Coverage: Are there persuasion actions from the report that were 20 Preprint. Under review. missed entirely?
-
[12]
initial_contact and outcome: Are they correct summaries? Should any content move between these fields and the engagement rounds?
-
[13]
Verbatim accuracy: Does each verbatim field contain EXACT text from the original report? Output Return the corrected JSON object only (same format as before). If no changes are needed, return the same JSON. G Additional Scam Kill Chain Examples H Evaluation Details H.1 Real-time Termination Prediction Details For real-time termination prediction, each eva...
-
[14]
First, identify each distinct scammer action or tactic described in the generated narrative
-
[15]
For each distinct action you identified, decide whether it is semantically covered by ANY of the ground truth actions. Respond ONLY with a JSON object: { "actions_found": <int>, "actions_matched": <int>, "precision": <float 0-1> } 24 Preprint. Under review. PT Extraction Judge.To compute PT HitRate, we ask the judge to extract which PTs are present in the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.