Recognition: unknown
SOAR: Scale Optimization for Accurate Reconstruction in NVFP4 Quantization
Pith reviewed 2026-05-13 05:51 UTC · model grok-4.3
The pith
SOAR achieves higher accuracy in NVFP4 quantization of large language models by optimizing scales with closed-form solutions and discrete search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deriving closed-form solutions for jointly optimizing global and per-block scales from minimizing reconstruction error, and by decoupling the high-precision quantization scale from its dequantization counterpart to enable discrete search, SOAR delivers superior accuracy in NVFP4-quantized LLMs compared to existing baselines while maintaining identical memory usage and hardware compatibility.
What carries the argument
Closed-form Joint Scale Optimization (CJSO) that provides analytical scale values from error minimization, combined with Decoupled Scale Search (DSS) that finds better scales under dequantization constraints.
Load-bearing premise
The closed-form scale solutions derived from error minimization continue to work well after quantization to the hardware's restricted dequantization format, and the discrete search step does not overfit to the calibration dataset.
What would settle it
Evaluating the method on an LLM not seen during development and measuring no accuracy improvement over standard NVFP4 baselines, or observing that optimal scales from search deviate little from the closed-form predictions.
Figures

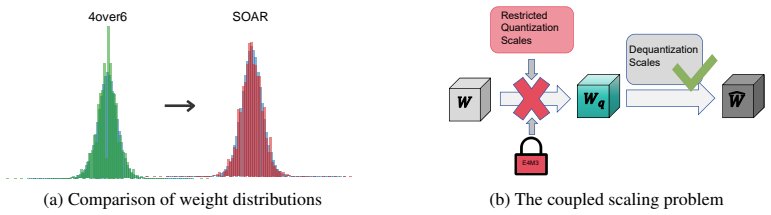

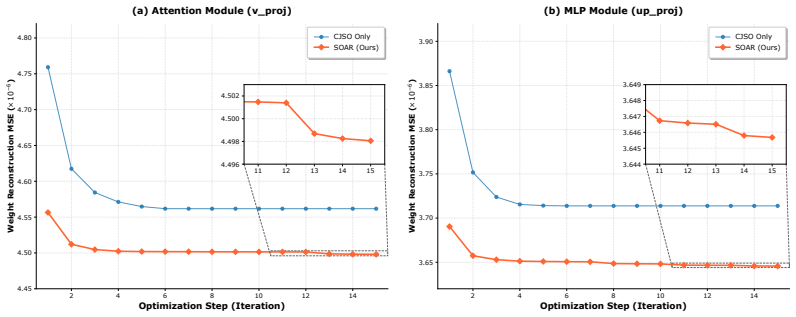
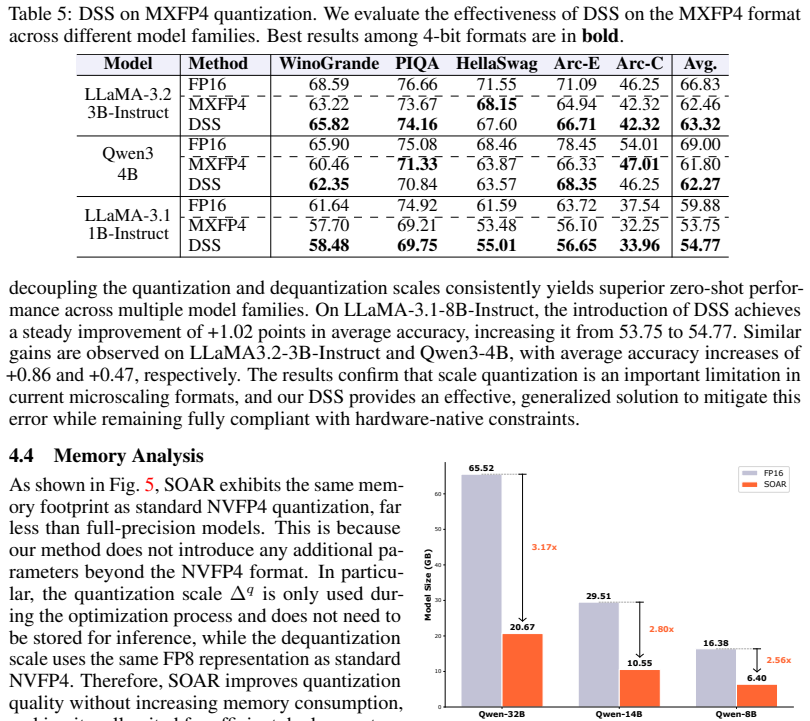
read the original abstract
NVFP4 has recently emerged as an efficient 4-bit microscaling format for large language models (LLMs), offering superior numerical fidelity with native hardware support. However, existing methods often yield suboptimal performance due to inflexible scale selection and the coupled treatment of quantization and dequantization scales. To address these issues, we propose Scale Optimization for Accurate Reconstruction (SOAR), a novel post-training quantization framework that improves the accuracy of NVFP4 quantization. At its core, SOAR features Closed-form Joint Scale Optimization (CJSO), which jointly optimizes global and block-wise scales via analytical solutions derived from reconstruction error minimization. Furthermore, it incorporates Decoupled Scale Search (DSS). DSS decouples the high-precision quantization scale from its constrained dequantization counterpart, and performs discrete search to mitigate precision loss from scale quantization. Extensive experiments across multiple LLMs show that our method consistently outperforms existing NVFP4 quantization baselines, achieving superior accuracy under the same memory footprint with no additional hardware overhead. The code and models will be available at https://github.com/steven-bao1/SOAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SOAR, a post-training quantization framework for the NVFP4 microscaling format applied to large language models. The core contributions are Closed-form Joint Scale Optimization (CJSO), which computes analytical solutions for joint global and block-wise scales by minimizing reconstruction error, and Decoupled Scale Search (DSS), which decouples the quantization scale from the constrained dequantization scale and uses discrete search to minimize precision loss. The authors report that extensive experiments on multiple LLMs show consistent outperformance over existing NVFP4 baselines in accuracy while maintaining the same memory footprint and without additional hardware overhead.
Significance. If the results are robust, this work offers a meaningful advance in efficient quantization of LLMs by providing closed-form optimizations and a decoupling strategy that preserves hardware compatibility. The analytical nature of CJSO and the search-based mitigation in DSS could reduce reliance on heuristic scale selection, potentially benefiting deployment of models in resource-constrained environments. The no-extra-overhead claim is particularly significant for practical adoption.
major comments (3)
- [Abstract and §3] Abstract and §3 (CJSO): The claim that analytical solutions derived from reconstruction error minimization remain optimal once scales are snapped to NVFP4's constrained dequantization grid is load-bearing but unsupported by any derivation, sensitivity analysis, or post-quantization optimality proof. The continuous optimum may shift under the discrete constraint, directly affecting whether the reported accuracy gains are attributable to CJSO.
- [§4] §4 (DSS): DSS performs discrete search over the calibration set to decouple scales. No experiments or analysis demonstrate that this search generalizes beyond the calibration distribution rather than overfitting to specific tokens; a held-out validation or distribution-shift test is required to support the claim that precision loss is mitigated without compromising downstream performance.
- [Experiments] Experiments section: The headline claim of consistent outperformance requires ablations that isolate CJSO from DSS contributions, plus direct quantitative comparisons (e.g., perplexity or zero-shot accuracy deltas) against the exact NVFP4 baselines cited. Without these, it is unclear whether gains exceed what simpler scale heuristics could achieve.
minor comments (1)
- [§2–3] Notation in §2–3: The distinction between the high-precision quantization scale and the constrained dequantization scale should be introduced with explicit equations before the optimization derivations to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have carefully considered each comment and provide point-by-point responses below. We believe these revisions will strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (CJSO): The claim that analytical solutions derived from reconstruction error minimization remain optimal once scales are snapped to NVFP4's constrained dequantization grid is load-bearing but unsupported by any derivation, sensitivity analysis, or post-quantization optimality proof. The continuous optimum may shift under the discrete constraint, directly affecting whether the reported accuracy gains are attributable to CJSO.
Authors: We thank the referee for highlighting this important point. In Section 3, we derive the closed-form solutions for the joint global and block-wise scales by minimizing the reconstruction error in the continuous domain. While the final scales are snapped to the NVFP4 grid, our experiments demonstrate that the optimized scales lead to superior accuracy compared to baselines. To rigorously address the potential shift, we will add a sensitivity analysis and discussion on the impact of discretization in the revised version, including comparisons before and after snapping. revision: yes
-
Referee: [§4] §4 (DSS): DSS performs discrete search over the calibration set to decouple scales. No experiments or analysis demonstrate that this search generalizes beyond the calibration distribution rather than overfitting to specific tokens; a held-out validation or distribution-shift test is required to support the claim that precision loss is mitigated without compromising downstream performance.
Authors: We agree that validating generalization is crucial. The calibration set is used following standard PTQ practices, and our results on multiple LLMs and tasks suggest robustness. In the revision, we will include additional experiments using held-out validation data and tests under distribution shifts to confirm that DSS does not overfit and maintains performance. revision: yes
-
Referee: [Experiments] Experiments section: The headline claim of consistent outperformance requires ablations that isolate CJSO from DSS contributions, plus direct quantitative comparisons (e.g., perplexity or zero-shot accuracy deltas) against the exact NVFP4 baselines cited. Without these, it is unclear whether gains exceed what simpler scale heuristics could achieve.
Authors: We appreciate the suggestion for clearer ablations. The current experiments compare SOAR against NVFP4 baselines, but to better isolate the contributions, we will add ablations showing the effect of CJSO alone and DSS alone. Additionally, we will include explicit quantitative deltas in perplexity and zero-shot accuracy against the baselines in the revised experiments section. revision: yes
Circularity Check
No significant circularity; derivations are self-contained analytical and search-based steps
full rationale
The paper presents CJSO as closed-form analytical solutions obtained by minimizing reconstruction error (standard first-principles derivation, not a fit renamed as prediction) and DSS as an explicit discrete search over the quantized-scale constraint. Neither step reduces the final accuracy metric to its own inputs by construction, nor relies on load-bearing self-citations or ansatzes smuggled from prior work. The central claims rest on empirical validation across LLMs rather than tautological equivalence between inputs and outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reconstruction error on a calibration set is a faithful proxy for downstream task accuracy after quantization.
Reference graph
Works this paper leans on
-
[1]
Arai, Y. and Ichikawa, Y. Quantization Error Propagation : Revisiting Layer - Wise Post - Training Quantization . In NeurIPS, 2025
work page 2025
-
[2]
Quik: Towards end-to-end 4-bit inference on generative large language models
Ashkboos, S., Markov, I., Frantar, E., Zhong, T., Wang, X., Ren, J., Hoefler, T., and Alistarh, D. Quik: Towards end-to-end 4-bit inference on generative large language models. In EMNLP, 2024 a
work page 2024
-
[3]
L., Li, B., Cameron, P., Jaggi, M., Alistarh, D., Hoefler, T., and Hensman, J
Ashkboos, S., Mohtashami, A., Croci, M. L., Li, B., Cameron, P., Jaggi, M., Alistarh, D., Hoefler, T., and Hensman, J. QuaRot : Outlier - Free 4- Bit Inference in Rotated LLMs . In NeurIPS, 2024 b
work page 2024
-
[4]
Piqa: Reasoning about physical commonsense in natural language
Bisk, Y., Zellers, R., Gao, J., Choi, Y., et al. Piqa: Reasoning about physical commonsense in natural language. In AAAI, 2020
work page 2020
- [5]
-
[6]
Unveiling the potential of quantization with mxfp4: Strategies for quantization error reduction
Chhugani, J., Jeong, G., Su, B.-Y., Pan, Y., Yang, H., Ankit, A., Yu, J., Deng, S., Chen, Y., Satish, N., and Kim, C. Unveiling the potential of quantization with mxfp4: Strategies for quantization error reduction. arXiv preprint arXiv:2603.08713, 2026
-
[7]
FP 4 all the way: Fully quantized training of large language models
Chmiel, B., Fishman, M., Banner, R., and Soudry, D. FP 4 all the way: Fully quantized training of large language models. In NeurIPS, 2025
work page 2025
-
[8]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
Cook, J., Guo, J., Xiao, G., Lin, Y., and Han, S. Four over six: More accurate nvfp4 quantization with adaptive block scaling. arXiv preprint arXiv:2512.02010, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Dettmers, T., Lewis, M., Belkada, Y., and Zettlemoyer, L. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. In NeurIPS, 2022
work page 2022
-
[12]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
L., Kurtic, E., and Alistarh, D
Egiazarian, V., Panferov, A., Kuznedelev, D., Pandit, S., Marques, A., Kurtz, M., Ashkboos, S., Hoefler, T., Castro, R. L., Kurtic, E., and Alistarh, D. Bridging the gap between promise and performance for microscaling fp4 quantization. In ICLR, 2026
work page 2026
-
[14]
GPTQ : Accurate Post - Training Quantization for Generative Pre -trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. GPTQ : Accurate Post - Training Quantization for Generative Pre -trained Transformers . In ICLR, 2023
work page 2023
-
[15]
Measuring massive multitask language understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. In ICLR, 2021
work page 2021
-
[16]
Hu, X., Cheng, Y., Yang, D., Xu, Z., Yuan, Z., Yu, J., Xu, C., Jiang, Z., and Zhou, S. Ostquant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting. In ICLR, 2025
work page 2025
-
[17]
SliM - LLM : Salience - Driven Mixed - Precision Quantization for Large Language Models
Huang, W., Qin, H., Liu, Y., Li, Y., Liu, Q., Liu, X., Benini, L., Magno, M., Zhang, S., and Qi, X. SliM - LLM : Salience - Driven Mixed - Precision Quantization for Large Language Models . In ICML, 2025
work page 2025
-
[18]
BOA : Attention -aware Post -training Quantization without Backpropagation
Kim, J., Kim, H.-y., Cho, E., Lee, C., Kim, J., and Jeon, Y. BOA : Attention -aware Post -training Quantization without Backpropagation . In ICML, 2025
work page 2025
-
[19]
Kim, S., Hooper, C., Gholami, A., Dong, Z., Li, X., Shen, S., Mahoney, M. W., and Keutzer, K. SqueezeLLM : Dense -and- Sparse Quantization . In ICML, 2024
work page 2024
-
[20]
Batquant: Outlier-resilient mxfp4 quantization via learnable block-wise optimization
Li, J.-F., Zhang, M., Xia, X., Bao, H., Bai, H., Dong, Z., and Yu, X. Batquant: Outlier-resilient mxfp4 quantization via learnable block-wise optimization. arXiv preprint arXiv:2603.16590, 2026
-
[21]
GPTAQ : Efficient Finetuning - Free Quantization for Asymmetric Calibration
Li, Y., Yin, R., Lee, D., Xiao, S., and Panda, P. GPTAQ : Efficient Finetuning - Free Quantization for Asymmetric Calibration . In ICML, 2025 a
work page 2025
-
[22]
Arb-llm: Alternating refined binarizations for large language models
Li, Z., Yan, X., Zhang, T., Qin, H., Xie, D., Tian, J., Kong, L., Zhang, Y., Yang, X., et al. Arb-llm: Alternating refined binarizations for large language models. In ICLR, 2025 b
work page 2025
-
[23]
Paroquant: Pairwise rotation quantization for efficient reasoning LLM inference
Liang, Y., Chen, H., Han, S., and Liu, Z. Paroquant: Pairwise rotation quantization for efficient reasoning LLM inference. In ICLR, 2026
work page 2026
-
[24]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms
Lin, H., Xu, H., Wu, Y., Cui, J., Zhang, Y., Mou, L., Song, L., Sun, Z., and Wei, Y. Duquant: Distributing outliers via dual transformation makes stronger quantized llms. In NeurIPS, 2024 a
work page 2024
-
[25]
AWQ : Activation -aware Weight Quantization for LLM Compression and Acceleration
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.-M., Wang, W.-C., Xiao, G., Dang, X., Gan, C., and Han, S. AWQ : Activation -aware Weight Quantization for LLM Compression and Acceleration . In MLSys, 2024 b
work page 2024
-
[26]
Affinequant: Affine transformation quantization for large language models
Ma, Y., Li, H., Zheng, X., Ling, F., Xiao, X., Wang, R., Wen, S., Chao, F., and Ji, R. Affinequant: Affine transformation quantization for large language models. In ICLR, 2024
work page 2024
-
[27]
Arcquant: Boosting nvfp4 quantization with augmented residual channels for llms
Meng, H., Luo, Y., Zhao, Y., Liu, W., Zhang, P., and Ma, X. Arcquant: Boosting nvfp4 quantization with augmented residual channels for llms. arXiv preprint arXiv:2601.07475, 2026
-
[28]
Pointer sentinel mixture models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. In ICLR, 2017
work page 2017
-
[29]
Nvidia blackwell architecture technical brief
NVIDIA . Nvidia blackwell architecture technical brief. https://resources.nvidia.com/en-us-blackwell-architecture, 2024
work page 2024
-
[30]
arXiv preprint arXiv:2509.25149 , year=
Nvidia, Abecassis, F., Agrusa, A., Ahn, D., Alben, J., Alborghetti, S., Andersch, M., Arayandi, S., Bjorlin, A., Blakeman, A., Briones, E., et al. Pretraining large language models with nvfp4. arXiv preprint arXiv:2509.25149, 2025
-
[31]
Pytorch: An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., and et al. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019
work page 2019
-
[32]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 2020
work page 2020
-
[33]
arXiv preprint arXiv:2310.10537 , year=
Rouhani, B. D., Zhao, R., More, A., Hall, M., Khodamoradi, A., Deng, S., Choudhary, D., Cornea, M., Dellinger, E., Denolf, K., et al. Microscaling data formats for deep learning. arXiv preprint arXiv:2310.10537, 2023
-
[34]
Skim: Any-bit quantization pushing the limits of post-training quantization
Runsheng, B., Bo, L., and Qiang, L. Skim: Any-bit quantization pushing the limits of post-training quantization. In ICML, 2025
work page 2025
-
[35]
Winogrande: An adversarial winograd schema challenge at scale
Sakaguchi, K., Le Bras, R., Bhagavatula, C., and Choi, Y. Winogrande: An adversarial winograd schema challenge at scale. In AAAI, 2020
work page 2020
-
[36]
Resq: Mixed-precision quantization of large language models with low-rank residuals
Saxena, U., Sharify, S., Roy, K., and Wang, X. Resq: Mixed-precision quantization of large language models with low-rank residuals. In ICML, 2025
work page 2025
-
[37]
Dartquant: Efficient rotational distribution calibration for LLM quantization
Shao, Y., Chen, Y., Wang, P., Yu, J., Lin, J., Yao, Y., Wei, Z., and Cheng, J. Dartquant: Efficient rotational distribution calibration for LLM quantization. In NeurIPS, 2025 a
work page 2025
-
[38]
Block rotation is all you need for mxfp4 quantization
Shao, Y., Wang, P., Chen, Y., Xu, C., Wei, Z., and Cheng, J. Block rotation is all you need for mxfp4 quantization. arXiv preprint arXiv:2511.04214, 2025 b
-
[39]
Flatquant: Flatness matters for llm quantization
Sun, Y., Liu, R., Bai, H., Bao, H., Zhao, K., Li, Y., Hu, J., Yu, X., Hou, L., Yuan, C., et al. Flatquant: Flatness matters for llm quantization. In ICML, 2025
work page 2025
-
[40]
L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Scao, T. L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. Transformers: State-of-the-art natural language processing. In EMNLP, 2020
work page 2020
-
[41]
SmoothQuant : Accurate and Efficient Post - Training Quantization for Large Language Models
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., and Han, S. SmoothQuant : Accurate and Efficient Post - Training Quantization for Large Language Models . In ICML, 2023
work page 2023
-
[42]
Pt ^2 -llm: Post-training ternarization for large language models
Yan, X., Bao, C., Li, Z., Zhang, T., Yang, K., Qin, H., Xie, R., Sun, X., and Zhang, Y. Pt ^2 -llm: Post-training ternarization for large language models. In ICLR, 2026 a
work page 2026
-
[43]
D2quant: Accurate low-bit post-training weight quantization for llms
Yan, X., Bao, C., Li, Z., Zhang, T., Zhang, S., Xie, R., Sun, X., and Zhang, Y. D2quant: Accurate low-bit post-training weight quantization for llms. arXiv preprint arXiv:2602.02546, 2026 b
-
[44]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
LLM - FP 4: 4-bit floating-point quantized transformers
yang Liu, S., Liu, Z., Huang, X., Dong, P., and Cheng, K.-T. LLM - FP 4: 4-bit floating-point quantized transformers. In EMNLP, 2023
work page 2023
-
[46]
Hellaswag: Can a machine really finish your sentence? In ACL, 2019
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence? In ACL, 2019
work page 2019
-
[47]
Zhang, M., Li, J.-F., Sun, Z., Bai, H., Zhen, H.-L., Dong, Z., and Yu, X. Benchmarking post-training quantization of large language models under microscaling floating point formats. arXiv preprint arXiv:2601.09555, 2026
-
[48]
Atom: Low-bit quantization for efficient and accurate llm serving
Zhao, Y., Lin, C.-Y., Zhu, K., Ye, Z., Chen, L., Zheng, S., Ceze, L., Krishnamurthy, A., Chen, T., and Kasikci, B. Atom: Low-bit quantization for efficient and accurate llm serving. In MLSys, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.