Recognition: 2 theorem links
· Lean TheoremSI-Diff: A Framework for Learning Search and High-Precision Insertion with a Force-Domain Diffusion Policy
Pith reviewed 2026-05-13 04:06 UTC · model grok-4.3
The pith
A single force-domain diffusion policy can handle both robotic search and high-precision insertion by using mode conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A force-domain diffusion policy with an added mode-conditioning mechanism can learn the mapping from tactile and velocity observations to actions that cover both search and insertion. The policy is trained on successful trajectories generated by a new search teacher that produces diverse demonstrations. Once trained, the single model executes both behaviors without switching weights, producing higher tolerance to initial pose errors than prior separate-model baselines.
What carries the argument
The mode-conditioning mechanism that lets one diffusion policy capture distinct action patterns for search versus insertion while sharing the same network weights.
If this is right
- The policy tolerates x-y misalignments up to 5 mm where earlier methods were limited to 2 mm.
- The same weights transfer zero-shot to peg shapes not seen during training.
- No model or weight switching is needed when moving from search to insertion.
- Training relies on force-domain observations paired with end-effector velocity to produce the required actions.
Where Pith is reading between the lines
- The unification could simplify controller architectures in assembly cells by removing the need to detect phase transitions externally.
- The teacher-policy approach might generalize to other dual-phase contact tasks if similar diverse demonstrations can be generated.
- If the mode signal can be inferred from observations alone, the system could run without an explicit mode input at test time.
Load-bearing premise
Mode conditioning can cleanly separate the two behaviors inside one diffusion model without degrading performance on either task.
What would settle it
Running the trained policy on insertion trials after successful search and measuring insertion success rates that fall below those of a dedicated insertion-only baseline would show the conditioning failed to preserve both capabilities.
Figures




read the original abstract
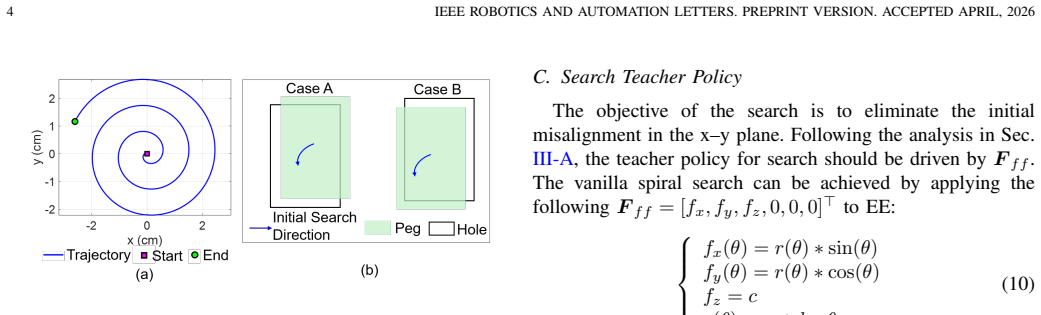
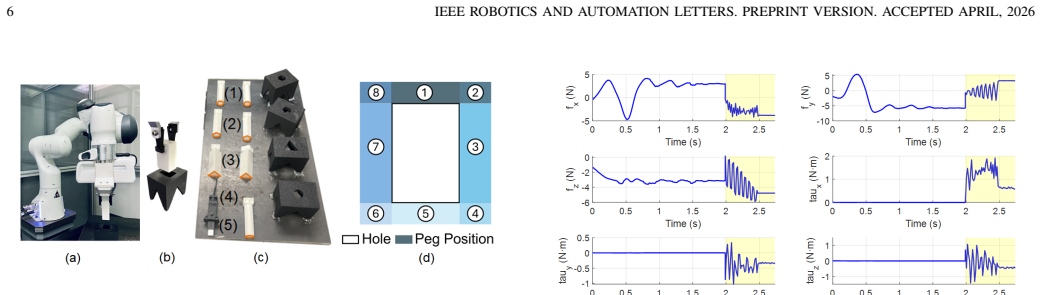
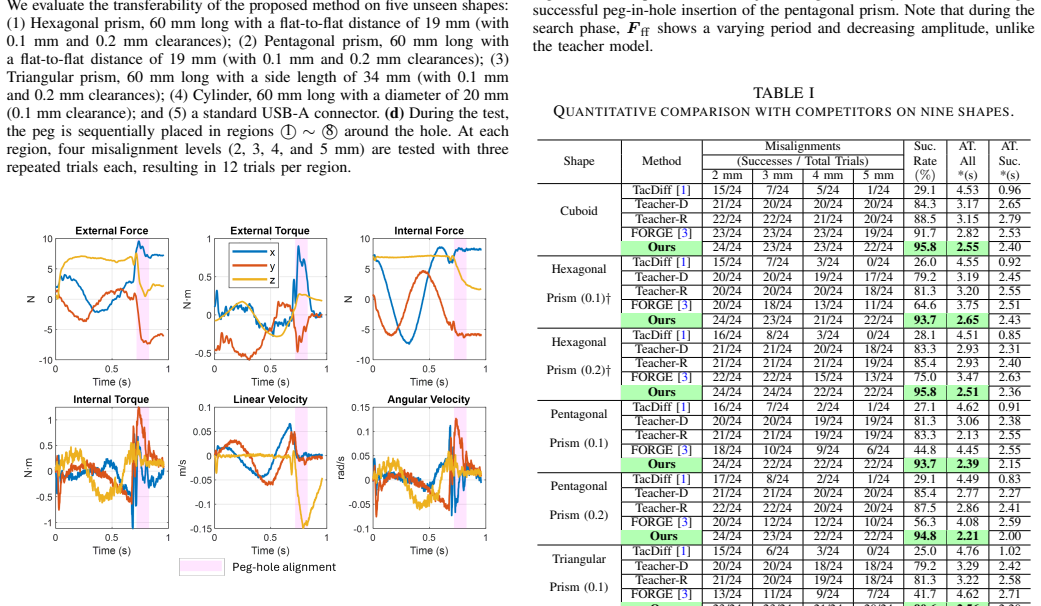
Contact-rich assembly is fundamental in robotics but poses significant challenges due to uncertainties in relative poses, such as misalignments and small clearances in peg-in-hole tasks. Existing approaches typically address search and high-precision insertion separately, because these tasks involve distinct action patterns. However, supporting both tasks within a single model, without switching models or weights, is desirable for intelligent assembly systems. In this work, we propose SI-Diff, a framework that learns both search and high-precision insertion through a force-domain diffusion policy. To this end, we introduce a new mode-conditioning mechanism that enables the policy to capture distinct action behaviors under a single framework. Moreover, we develop a new search teacher policy that can generate diverse trajectories. By training on successful and efficient demonstrations provided by the teacher policy, the model learns the mapping from tactile and end-effector velocity observations to effective action behaviors. We conduct thorough experiments to show that SI-Diff extends the tolerance to x-y misalignments from 2 mm to 5 mm compared to the state-of-the-art baseline, TacDiffusion, while also demonstrating strong zero-shot transferability to unseen shapes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SI-Diff, a single force-domain diffusion policy augmented with a mode-conditioning mechanism to jointly learn search (for large x-y misalignments) and high-precision insertion (for sub-mm clearances) in peg-in-hole assembly tasks. It introduces a new search teacher policy to generate diverse, high-quality demonstrations and trains the diffusion model on tactile and end-effector velocity observations. Experiments claim that SI-Diff increases x-y misalignment tolerance from 2 mm to 5 mm relative to the TacDiffusion baseline while enabling strong zero-shot transfer to unseen shapes.
Significance. If the central empirical claims hold after isolating the contributions of mode-conditioning and the teacher policy, the work would be significant for contact-rich robotics: it demonstrates that a single diffusion policy can capture two qualitatively different action regimes without explicit model switching, which could simplify deployment of intelligent assembly systems. The force-domain formulation and teacher-generated data are concrete strengths that address real uncertainties in relative pose.
major comments (2)
- [Experiments] Experiments section: The manuscript reports performance gains only for the complete SI-Diff system versus TacDiffusion. No ablation is presented that removes the mode-conditioning input while retaining the identical teacher policy, observation space, diffusion architecture, and training procedure. Because the abstract and method attribute the 2 mm → 5 mm tolerance extension and zero-shot shape transfer to the combination of mode-conditioning and the teacher, the absence of this controlled comparison leaves open the possibility that the gains derive primarily from the teacher demonstrations rather than from the shared-policy architecture.
- [Method] Method section, mode-conditioning description: The paper states that the mode vector enables the policy to capture distinct search and insertion behaviors, yet provides no quantitative verification (e.g., action-distribution statistics or latent-space analysis) that the conditioning actually separates the two regimes inside the shared diffusion model. Without such evidence, the claim that a single set of weights successfully handles both coarse search and fine insertion without performance trade-off remains unverified.
minor comments (2)
- The abstract and experimental narrative refer to 'thorough experiments' but omit reporting of run-to-run variance, number of trials per condition, or statistical significance tests for the tolerance thresholds; adding these would strengthen reproducibility.
- [Method] Notation for the force-domain observation and the exact form of the mode vector (concatenation, embedding, or cross-attention) is introduced without a clear equation or diagram, complicating direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will incorporate to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The manuscript reports performance gains only for the complete SI-Diff system versus TacDiffusion. No ablation is presented that removes the mode-conditioning input while retaining the identical teacher policy, observation space, diffusion architecture, and training procedure. Because the abstract and method attribute the 2 mm → 5 mm tolerance extension and zero-shot shape transfer to the combination of mode-conditioning and the teacher, the absence of this controlled comparison leaves open the possibility that the gains derive primarily from the teacher demonstrations rather than from the shared-policy architecture.
Authors: We acknowledge that a controlled ablation isolating mode-conditioning is necessary to substantiate the contribution of the shared-policy architecture. In the revised manuscript we will add this experiment: we will train and evaluate an otherwise identical diffusion policy (same teacher-generated demonstrations, observation space of tactile and end-effector velocity, architecture, and training procedure) but without the mode-conditioning input. Direct comparison of this ablated model against full SI-Diff on the x-y tolerance and zero-shot transfer metrics will clarify whether the reported gains require the conditioning mechanism or arise primarily from the teacher data. revision: yes
-
Referee: [Method] Method section, mode-conditioning description: The paper states that the mode vector enables the policy to capture distinct search and insertion behaviors, yet provides no quantitative verification (e.g., action-distribution statistics or latent-space analysis) that the conditioning actually separates the two regimes inside the shared diffusion model. Without such evidence, the claim that a single set of weights successfully handles both coarse search and fine insertion without performance trade-off remains unverified.
Authors: We agree that quantitative verification of regime separation would strengthen the methodological claims. In the revision we will add an analysis subsection that reports (1) comparative statistics on action distributions (velocity magnitude, direction, and force profiles) generated under search versus insertion mode conditioning and (2) low-dimensional visualizations (e.g., PCA or t-SNE) of the diffusion model's internal features conditioned on each mode. These results will demonstrate that the single set of weights learns distinct behaviors without observable performance trade-offs. revision: yes
Circularity Check
No circularity: empirical imitation learning with held-out evaluation
full rationale
The paper describes an empirical framework for training a diffusion policy on teacher-generated demonstrations for peg-in-hole search and insertion. All performance claims (2 mm to 5 mm tolerance, zero-shot shape transfer) are measured on separate test cases rather than derived from model equations. No mathematical derivation chain exists that reduces to fitted inputs, self-citations, or renamed ansatzes; the mode-conditioning and teacher policy are architectural choices whose effects are validated experimentally, not presupposed by definition.
Axiom & Free-Parameter Ledger
free parameters (2)
- mode-conditioning vector
- diffusion noise schedule and step count
axioms (2)
- domain assumption Force and end-effector velocity observations are sufficient to distinguish and execute both search and insertion phases.
- domain assumption Successful trajectories generated by the teacher policy form an adequate training distribution for the diffusion model.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose SI-Diff, a framework that learns both search and high-precision insertion through a force-domain diffusion policy... new mode-conditioning mechanism... new search teacher policy that can generate diverse trajectories.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearSI-Diff extends the tolerance to x-y misalignments from 2 mm to 5 mm... zero-shot transferability to unseen shapes.
Reference graph
Works this paper leans on
-
[1]
Tacdiffusion: Force-domain diffusion policy for precise tactile manipulation,
Y . Wu, Z. Chen, F. Wu, L. Chen, L. Zhang, Z. Bing, A. Swikir, S. Haddadin, and A. Knoll, “Tacdiffusion: Force-domain diffusion policy for precise tactile manipulation,” inInternational Conference on Robotics and Automation (ICRA), 2025
work page 2025
-
[2]
1 khz behavior tree for self-adaptable tactile insertion,
Y . Wu, F. Wu, L. Chen, K. Chen, S. Schneider, L. Johannsmeier, Z. Bing, F. J. Abu-Dakka, A. Knoll, and S. Haddadin, “1 khz behavior tree for self-adaptable tactile insertion,” inIEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 16 002–16 008
work page 2024
-
[3]
Forge: Force-guided exploration for robust contact-rich manipulation under uncertainty,
M. Noseworthy, B. Tang, B. Wen, A. Handa, C. Kessens, N. Roy, D. Fox, F. Ramos, Y . Narang, and I. Akinola, “Forge: Force-guided exploration for robust contact-rich manipulation under uncertainty,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[4]
Deep reinforcement learning for high precision assembly tasks,
T. Inoue, G. De Magistris, A. Munawar, T. Yokoya, and R. Tachibana, “Deep reinforcement learning for high precision assembly tasks,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 819–825
work page 2017
-
[5]
K. Nottensteiner, A. Sachtler, and A. Albu-Sch ¨affer, “Towards au- tonomous robotic assembly: Using combined visual and tactile sensing for adaptive task execution,”Journal of Intelligent & Robotic Systems, vol. 101, no. 3, p. 49, 2021
work page 2021
-
[6]
Perception-control coupled visual servoing for textureless objects using keypoint-based ekf,
A. Tao, J. Yang, S. Oparnica, and W. Xue, “Perception-control coupled visual servoing for textureless objects using keypoint-based ekf,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2026
work page 2026
-
[7]
Compliant peg-in-hole assembly using partial spiral force trajectory with tilted peg posture,
H. Park, J. Park, D.-H. Lee, J.-H. Park, and J.-H. Bae, “Compliant peg-in-hole assembly using partial spiral force trajectory with tilted peg posture,”IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4447– 4454, 2020. LIUet al.: SI-DIFF: A FRAMEWORK FOR LEARNING SEARCH AND HIGH-PRECISION INSERTION WITH A FORCE-DOMAIN DIFFUSION POLICY 9
work page 2020
-
[8]
Pomdp- guided active force-based search for robotic insertion,
C. Wang, H. Luo, K. Zhang, H. Chen, J. Pan, and W. Zhang, “Pomdp- guided active force-based search for robotic insertion,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 10 668–10 675
work page 2023
-
[9]
X. Zhang, S. Jin, C. Wang, X. Zhu, and M. Tomizuka, “Learning insertion primitives with discrete-continuous hybrid action space for robotic assembly tasks,” inInternational Conference on Robotics and Automation (ICRA), 2022, pp. 9881–9887
work page 2022
-
[10]
Autonomous vision-based uav landing with collision avoidance using deep learning,
T. Liao, A. Haridevan, Y . Liu, and J. Shan, “Autonomous vision-based uav landing with collision avoidance using deep learning,” inScience and Information Conference. Springer, 2022, pp. 79–87
work page 2022
-
[11]
Particle filtering on lie group for mobile robot localization with range-bearing measurements,
S. Zhang, J. Shan, and Y . Liu, “Particle filtering on lie group for mobile robot localization with range-bearing measurements,”IEEE Control Systems Letters, vol. 7, pp. 3753–3758, 2023
work page 2023
-
[12]
Application of ghost- deblurgan to fiducial marker detection,
Y . Liu, A. Haridevan, H. Schofield, and J. Shan, “Application of ghost- deblurgan to fiducial marker detection,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 6827– 6832
work page 2022
-
[13]
Approximate inference particle filtering for mobile robot slam,
S. Zhang, J. Shan, and Y . Liu, “Approximate inference particle filtering for mobile robot slam,”IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 7967–7978, 2025
work page 2025
-
[14]
Intensity image-based lidar fiducial marker system,
Y . Liu, H. Schofield, and J. Shan, “Intensity image-based lidar fiducial marker system,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6542–6549, 2022
work page 2022
-
[15]
Improvements to thin-sheet 3d lidar fiducial tag localization,
Y . Liu, J. Shan, and H. Schofield, “Improvements to thin-sheet 3d lidar fiducial tag localization,”IEEE Access, vol. 12, pp. 124 907–124 914, 2024
work page 2024
-
[16]
R. Li and H. Qiao, “A survey of methods and strategies for high- precision robotic grasping and assembly tasks—some new trends,” IEEE/ASME Transactions on Mechatronics, vol. 24, no. 6, pp. 2718– 2732, 2019
work page 2019
-
[17]
Y . Ren, G. Wu, R. Li, Z. Yang, Y . Liu, X. Chen, T. Cao, and B. Liu, “Uni- gaussian: Driving scene reconstruction from multiple camera models via unified gaussian representations,” inProceedings of the International Conference on 3D Vision (3DV), 2026, poster
work page 2026
-
[18]
Y . Liu, J. Shan, A. Haridevan, and S. Zhang, “L-pr: Exploiting li- dar fiducial marker for unordered low-overlap multiview point cloud registration,”IEEE Transactions on Instrumentation and Measurement, vol. 74, pp. 1–14, 2025
work page 2025
-
[19]
Y . Liu, K. Zhu, G. Wu, Y . Ren, B. Liu, Y . Liu, and J. Shan, “Mv- deepsdf: Implicit modeling with multi-sweep point clouds for 3d vehicle reconstruction in autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8306–8316
work page 2023
-
[20]
Hippo: Harnessing image-to-3d priors for model-free zero-shot 6d pose estimation,
Y . Liu, Z. Jiang, B. Xu, G. Wu, Y . Ren, T. Cao, B. Liu, R. H. Yang, A. Rasouli, and J. Shan, “Hippo: Harnessing image-to-3d priors for model-free zero-shot 6d pose estimation,”IEEE Robotics and Automa- tion Letters, vol. 10, no. 8, pp. 8284–8291, 2025
work page 2025
-
[21]
Learning effective nerfs and sdfs representations with 3d gans for object gen- eration,
Z. Yang, Y . Liu, G. Wu, T. Cao, Y . Ren, Y . Liu, and B. Liu, “Learning effective nerfs and sdfs representations with 3d gans for object gen- eration,” inNeurIPS Workshop on Symmetry and Geometry in Neural Representations, 2024
work page 2024
-
[22]
Exploratory motion guided tactile learning for shape-consistent robotic insertion,
G. Yan, J. He, S. Funabashi, A. Schmitz, and S. Sugano, “Exploratory motion guided tactile learning for shape-consistent robotic insertion,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 4487–4494
work page 2024
-
[23]
Fast robust peg-in-hole insertion with continuous visual servoing,
R. Haugaard, J. Langaa, C. Sloth, and A. Buch, “Fast robust peg-in-hole insertion with continuous visual servoing,” inin Conference on Robot Learning. PMLR, 2021, pp. 1696–1705
work page 2021
-
[24]
Vision-driven compliant manipulation for reliable; high-precision assembly tasks,
J. Liang, A. Boularias, A. Dollar, K. Bekriset al., “Vision-driven compliant manipulation for reliable; high-precision assembly tasks,” in in Robotics: Science and Systems
-
[25]
Robust, locally guided peg-in-hole using impedance-controlled robots,
K. Nottensteiner, F. Stulp, and A. Albu-Sch ¨affer, “Robust, locally guided peg-in-hole using impedance-controlled robots,” inIEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 5771–5777
work page 2020
-
[26]
Active extrinsic contact sensing: Applica- tion to general peg-in-hole insertion,
S. Kim and A. Rodriguez, “Active extrinsic contact sensing: Applica- tion to general peg-in-hole insertion,” inInternational Conference on Robotics and Automation (ICRA), 2022, pp. 10 241–10 247
work page 2022
-
[27]
Human-like adaptation of force and impedance in stable and unstable interactions,
C. Yang, G. Ganesh, S. Haddadin, S. Parusel, A. Albu-Schaeffer, and E. Burdet, “Human-like adaptation of force and impedance in stable and unstable interactions,”IEEE transactions on robotics, vol. 27, no. 5, pp. 918–930, 2011
work page 2011
-
[28]
Imitating human behaviour with diffusion models,
T. Pearce, T. Rashid, A. Kanervisto, D. Bignell, M. Sun, R. Georgescu, S. V . Macua, S. Z. Tan, I. Momennejad, K. Hofmannet al., “Imitating human behaviour with diffusion models,” inInternational Conference on Learning Representations, 2023
work page 2023
-
[29]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[30]
Y . Liu, Z. Yang, G. Wu, Y . Ren, K. Lin, B. Liu, Y . Liu, and J. Shan, “Vqa-diff: Exploiting vqa and diffusion for zero-shot image-to-3d ve- hicle asset generation in autonomous driving,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 323–340
work page 2024
-
[31]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
work page 2019
-
[32]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[33]
Balanced contrastive learning for long-tailed visual recognition,
J. Zhu, Z. Wang, J. Chen, Y .-P. P. Chen, and Y .-G. Jiang, “Balanced contrastive learning for long-tailed visual recognition,” inIEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 6908– 6917
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.