Recognition: 2 theorem links
· Lean TheoremSocial Welfare under Heterogeneous Time Preferences
Pith reviewed 2026-05-13 04:06 UTC · model grok-4.3
The pith
In MDPs with principals who discount the future at different rates, socially optimal strategies use finite counting memory and admit polynomial-time synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under heterogeneous time preferences, optimal strategies for utilitarian social welfare are no longer positional, even when all principals receive identical rewards. Nevertheless, optimal strategies remain structurally simple: they can be realized as pure finite-memory counting strategies, require only polynomial memory in the system size, and can be synthesized in polynomial time. Deciding threshold questions for optimal positional strategies is NP-hard.
What carries the argument
pure finite-memory counting strategies that track the relative phases of the distinct discount factors
If this is right
- Optimal strategies remain realizable with memory bounded by a polynomial in the number of states.
- An algorithm exists that synthesizes an optimal strategy in time polynomial in the size of the MDP.
- Even when every principal receives the same reward function, positional strategies are generally suboptimal.
- Any decision procedure restricted to positional strategies cannot decide welfare thresholds in polynomial time.
Where Pith is reading between the lines
- Limited-memory counters may suffice for practical multi-stakeholder planning tools in climate or resource problems.
- The same counting structure could be tested in non-additive welfare definitions such as weighted sums or min-max fairness.
- Synthesis routines based on these counters could be embedded in existing MDP solvers to handle heterogeneous discount inputs without exponential blow-up.
Load-bearing premise
The underlying model consists of finite-state finite-action MDPs and social welfare is exactly the arithmetic sum of the individually discounted utilities.
What would settle it
An explicit MDP family with heterogeneous discounts in which every strategy achieving the optimal welfare value requires memory size super-polynomial in the number of states.
Figures

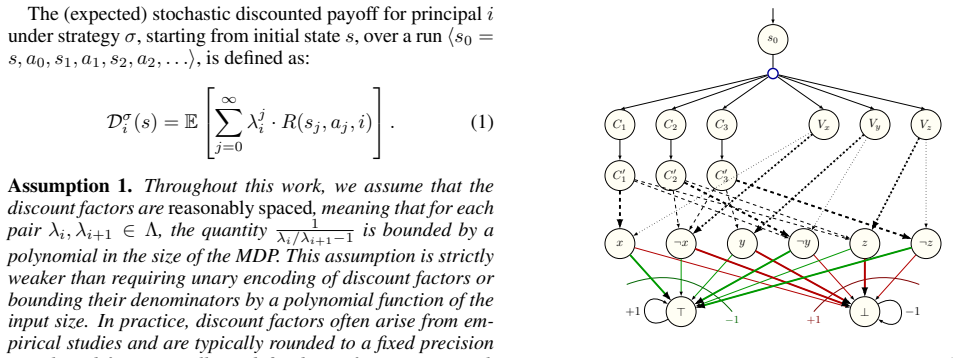
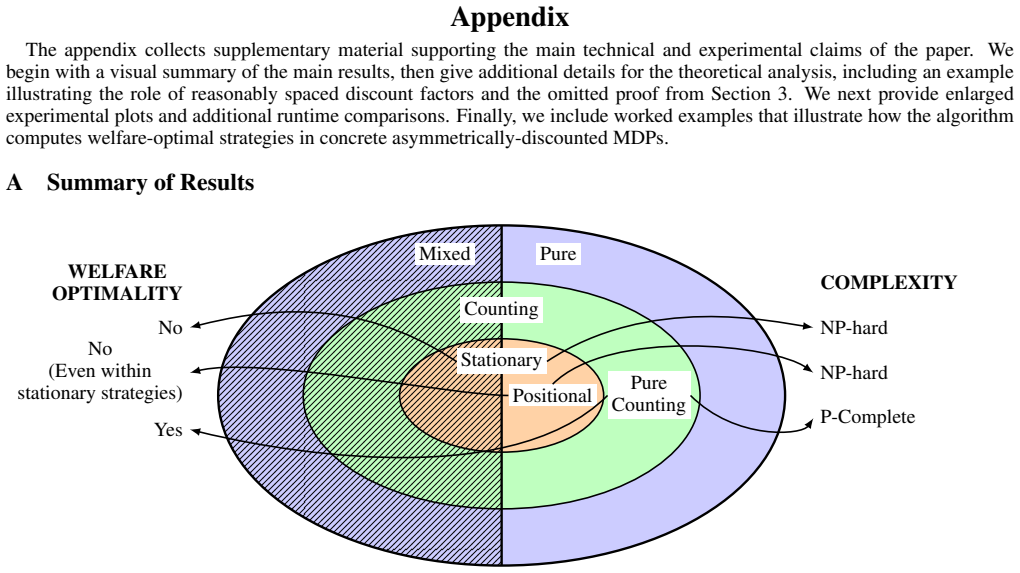





read the original abstract
In several socioeconomic-critical decision-making settings, such as fair resource allocation, climate policy, or AI alignment, multiple principals interact within a common arena. While it is well established that these principals may have differing preferences, decision-making under heterogeneous time preferences remains relatively unexplored. In particular, principals may weigh future outcomes differently and may derive distinct utilities from the same decisions. Motivated by such scenarios, we introduce the notion of heterogeneous time preferences in MDPs, where multiple principals possess distinct reward functions and apply different discount factors to future rewards. To compute meaningful decisions in such settings, an AI agent must rely on a notion of optimality that accounts for the preferences of all principals. We adopt a utilitarian notion of social welfare, defined as the sum of utilities accrued to all principals, and study the synthesis of agent strategies that maximise this welfare. Under heterogeneous time preferences, we show that optimal strategies are no longer positional, even when all principals receive identical rewards. Nevertheless, optimal strategies remain structurally simple: they can be realized as pure finite-memory counting strategies, require only polynomial memory in the system size, and can be synthesized in polynomial time. On the other hand, we show that deciding threshold questions for optimal positional strategies is NP-hard, exposing a poor trade-off: insisting on positional simplicity neither makes synthesis tractable nor preserves social welfare.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines Markov Decision Processes (MDPs) with multiple principals possessing heterogeneous time preferences, i.e., distinct reward functions and discount factors. It adopts a utilitarian social welfare objective defined as the arithmetic sum of the individually discounted utilities and studies the synthesis of strategies maximizing this welfare. The central claims are that optimal strategies are no longer positional (even when all principals receive identical rewards), yet they admit a simple structure as pure finite-memory counting strategies requiring only polynomial memory in the system size and synthesizable in polynomial time; additionally, deciding welfare thresholds for positional strategies is NP-hard.
Significance. If the results hold, this work meaningfully extends classical MDP theory to multi-principal settings with differing time preferences, which arise in applications such as fair resource allocation, climate policy, and AI alignment. The structural result that finite-memory counting strategies suffice with polynomial bounds, combined with an efficient synthesis algorithm, offers a practical algorithmic pathway while the NP-hardness result for positional strategies clarifies the necessity of memory augmentation. The approach is consistent with standard product constructions for multi-discount objectives and provides both theoretical insight and computational tractability.
minor comments (3)
- An explicit small example (e.g., a two-state MDP with two principals having different discounts) illustrating a case where no positional strategy is optimal but a counting strategy succeeds would make the non-positionality claim more concrete and accessible.
- The related-work section would benefit from a more detailed comparison to existing results on multi-objective MDPs, Pareto optimality under multiple discounts, and finite-memory strategies in stochastic games.
- Clarify in the main text (rather than only in the appendix) the precise bound on the counter size in the finite-memory construction to make the polynomial-memory claim immediately verifiable from the high-level argument.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The recognition of the practical and theoretical value in extending classical MDP results to heterogeneous time preferences is appreciated. Since the report lists no specific major comments, we have no point-by-point rebuttals to provide at this stage.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines heterogeneous time preferences and utilitarian social welfare (sum of discounted utilities) as new modeling primitives on finite MDPs, then proves that optimal strategies are finite-memory counting strategies via product constructions and standard MDP analysis. The polynomial memory bound and synthesis algorithm follow directly from the finite-state assumption and additive objective without reducing to any fitted parameter, self-definition, or self-citation chain. The NP-hardness result for positional strategies is shown by reduction from an external problem and does not rely on prior results by the same authors. All load-bearing steps are externally verifiable from the stated model and classical MDP theory.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The underlying MDP has finite states and actions
- domain assumption Social welfare is the arithmetic sum of each principal's individually discounted total reward
Reference graph
Works this paper leans on
-
[1]
Dynamic Noncooperative Game Theory
[Bas ¸ar and Olsder, 1999] Tamer Bas ¸ar and Geert Jan Olsder. Dynamic Noncooperative Game Theory. Classics in Ap- plied Mathematics. SIAM, 2 edition,
work page 1999
-
[2]
[Baird and Leemon, 1993] Iii Baird and C Leemon. Advan- tage updating. Technical report,
work page 1993
- [3]
-
[4]
[Chatterjeeet al., 2013 ] Krishnendu Chatterjee, V ojt ˇech Forejt, and Dominik Wojtczak
Springer Berlin Heidelberg. [Chatterjeeet al., 2013 ] Krishnendu Chatterjee, V ojt ˇech Forejt, and Dominik Wojtczak. Multi-objective dis- counted reward verification in graphs and mdps. In Ken McMillan, Aart Middeldorp, and Andrei V oronkov, editors,Logic for Programming, Artificial Intelligence, and Reasoning, pages 228–242, Berlin, Heidelberg,
work page 2013
-
[5]
[Chen and Takahashi, 2012] Bo Chen and Satoru Takahashi
Springer Berlin Heidelberg. [Chen and Takahashi, 2012] Bo Chen and Satoru Takahashi. A folk theorem for repeated games with unequal dis- counting.Games and Economic Behavior, 76(2):571–581,
work page 2012
-
[6]
[Dasgupta and Ghosh, 2022] Ani Dasgupta and Sambuddha Ghosh. Self-accessibility and repeated games with asymmetric discounting.Journal of Economic Theory, 200:105312,
work page 2022
-
[7]
Competitive Markov decision processes
[Filar and Vrieze, 1997] Jerzy A Filar and Koos Vrieze. Competitive Markov decision processes. Springer Science & Business Media,
work page 1997
-
[8]
[Ganet al., 2023 ] Jiarui Gan, Annika Hennes, Rupak Ma- jumdar, Debmalya Mandal, and Goran Radanovic. Markov decision processes with time-varying geometric discounting.Proceedings of the AAAI Conference on Arti- ficial Intelligence, 37(10):11980–11988, Jun
work page 2023
-
[9]
[Gu´eronet al., 2011 ] Yves Gu ´eron, Thibaut Lamadon, and Caroline D Thomas. On the folk theorem with one- dimensional payoffs and different discount factors.Games and Economic Behavior, 73(1):287–295,
work page 2011
-
[10]
Graduate texts in computer science
[Immerman, 1999] Neil Immerman.Descriptive complexity. Graduate texts in computer science. Springer,
work page 1999
-
[11]
Karp.Reducibility among Combi- natorial Problems
[Karp, 1972] Richard M. Karp.Reducibility among Combi- natorial Problems
work page 1972
-
[12]
Repeated games with differential time preferences.Econo- metrica, 67(2):393–412,
[Lehrer and Pauzner, 1999] Ehud Lehrer and Ady Pauzner. Repeated games with differential time preferences.Econo- metrica, 67(2):393–412,
work page 1999
-
[13]
Consistent aggregation of ob- jectives with diverse time preferences requires non- markovian rewards
[Pitis, 2023] Silviu Pitis. Consistent aggregation of ob- jectives with diverse time preferences requires non- markovian rewards. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 2877–2893. Curran Associates, Inc.,
work page 2023
-
[14]
[Puterman, 1994] M. L. Puterman.Markov Decision Pro- cesses: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., New York, NY , USA,
work page 1994
-
[15]
[Shapley, 1953] L. S. Shapley. Stochastic games.Proc. Nat. Acad. Sci. U.S.A., 39:1095–1100,
work page 1953
-
[16]
[Sutton and Barto, 2018] R. S. Sutton and A. G. Barto.Rein- forcement Learning: An Introduction. MIT Press, second edition,
work page 2018
-
[17]
[Tasdighi Kalatet al., 2024 ] Shadi Tasdighi Kalat, Sriram Sankaranarayanan, and Ashutosh Trivedi. What is your discount factor? InInternational Conference on Quan- titative Evaluation of Systems and Formal Modeling and Analysis of Timed Systems, pages 322–336. Springer,
work page 2024
-
[18]
[Tasdighi Kalatet al., 2026 ] Shadi Tasdighi Kalat, Sriram Sankaranarayanan, and Ashutosh Trivedi. Active discount factor elicitation via reward modification.International Journal on Software Tools for Technology Transfer,
work page 2026
-
[19]
1.Long-term strategy (Algorithm 1).The long-term strategy computed by Algorithm 1 is: π∞ ={s 0 7→b, s 1 7→d, s 2 7→f, s 3 7→g, s 4 7→h, s 5 7→k}. 2.Long-term values.The value functions underπ ∞ from the initial states 0 are: V0(s0) = 1072.2294andV 1(s0) = 1.00001. Hence, the baseline component of social welfare is already very close to the optimum. 3.Devi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.