Recognition: 2 theorem links
· Lean TheoremH3D-MarNet: Wavelet-Guided Dual-Path Learning for Metal Artifact Suppression and CT Modality Transformation for Radiotherapy Workflows
Pith reviewed 2026-05-13 06:19 UTC · model grok-4.3
The pith
H3D-MarNet uses wavelet preprocessing and a hybrid CNN-transformer to suppress metal artifacts in CT while converting kVCT to MVCT for radiotherapy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
H3D-MarNet performs artifact-aware kVCT-to-MVCT transformation by first using a wavelet-based preprocessing module for frequency-aware denoising that preserves anatomy, then passing the result through Domain-TransNet, a hybrid volumetric architecture whose CNN encoder extracts fine local features, transformer encoder models long-range dependencies, attention fusion combines them, and a multi-stage attention-guided decoder with deep supervision reconstructs the final MVCT volume.
What carries the argument
Domain-TransNet hybrid architecture, which pairs a CNN encoder for local anatomical detail with a transformer encoder for volumetric dependencies and fuses them via attention-based mechanism before deep-supervised decoding.
Load-bearing premise
The wavelet preprocessing combined with the hybrid CNN-transformer network will generalize to unseen clinical cases without creating new distortions or losing critical anatomical detail.
What would settle it
A test on an independent clinical dataset containing varied metal implant types where PSNR falls below 25 dB or visible new distortions appear in reconstructed MVCT volumes would falsify the claim of reliable suppression and transformation.
Figures





read the original abstract
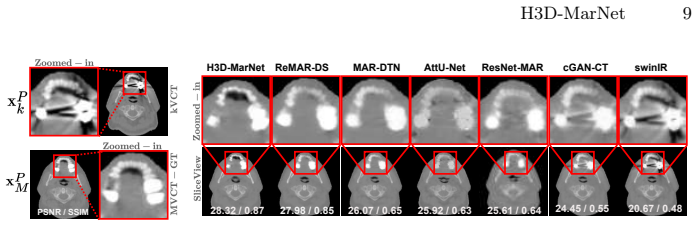
Metal artifacts in computed tomography (CT) severely degrade image quality, compromising diagnostic accuracy and radiotherapy planning, especially in cancer patients with high-density implants. We propose H3D-MarNet, a two-stage framework for artifact-aware CT domain transformation from kilo-voltage CT (kVCT) to mega-voltage CT (MVCT). In the first stage, a wavelet-based preprocessing module suppresses metal-induced artifacts through frequency-aware denoising while preserving anatomical structures. In second stage, Domain-TransNet performs kVCT-to-MVCT domain transformation using a hybrid volumetric learning architecture. Domain-TransNet integrates a CNN-based encoder to capture fine-grained local anatomical details and a transformer-based encoder to model long-range volumetric dependencies. The complementary representations are fused through an attention-based feature fusion mechanism to ensure spatial and contextual coherence across slices. A multi-stage, attention-guided decoder, supported by deep supervision, progressively reconstructs artifact-suppressed MVCT volumes. Extensive experiments demonstrate that H3D-MarNet achieves 28.14 dB PSNR and 0.717 SSIM on artifact-affected slices from full dataset, indicating effective metal artifact suppression and anatomical preservation, highlighting its potential for reliable CT modality transformation in clinical radiotherapy workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces H3D-MarNet, a two-stage framework for metal artifact suppression in kilo-voltage CT (kVCT) and domain transformation to mega-voltage CT (MVCT) for radiotherapy. The first stage applies wavelet-based preprocessing for frequency-aware denoising while preserving anatomy. The second stage uses Domain-TransNet, a hybrid volumetric architecture combining a CNN encoder for local details, a transformer encoder for long-range dependencies, attention-based feature fusion, and a multi-stage attention-guided decoder with deep supervision. The central empirical claim is that the method achieves 28.14 dB PSNR and 0.717 SSIM on artifact-affected slices from the full dataset.
Significance. If the reported metrics can be reproduced with proper controls, the hybrid wavelet-CNN-transformer design could offer a practical advance for CT-based radiotherapy planning in patients with high-density implants, by jointly addressing artifact removal and modality adaptation in a volumetric setting. The explicit separation of frequency-aware preprocessing from the domain transformation stage is a clear architectural choice that merits evaluation.
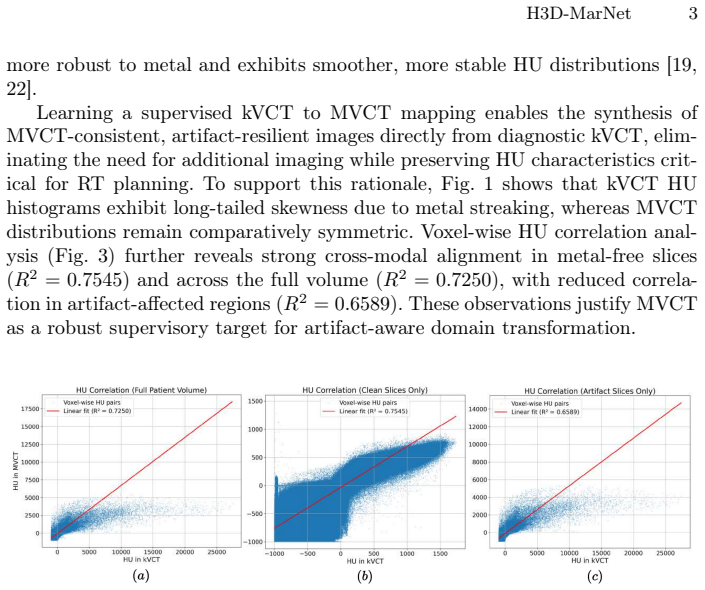
major comments (2)
- [Abstract] Abstract: The headline quantitative results (28.14 dB PSNR, 0.717 SSIM on artifact-affected slices from the 'full dataset') are presented without any disclosure of dataset size (number of patients or volumes), train/test split strategy, whether artifacts are synthetic or real, baseline comparisons, or the procedure used to obtain and spatially align MVCT ground truth with kVCT. These details are load-bearing for interpreting the metrics as evidence of effective suppression and reliable transformation.
- [Experiments] Experiments section: No ablation studies, cross-validation details, or statistical testing are described to isolate the contribution of the wavelet preprocessing, the transformer branch, or the attention fusion mechanism relative to simpler CNN-only or non-wavelet baselines. Without these, the performance numbers cannot be used to support the claim that the dual-path architecture is necessary or superior.
minor comments (2)
- [Abstract] The abstract uses the phrase 'full dataset' without a forward reference to the data section; this should be clarified for readers.
- [Method] Notation for the wavelet preprocessing module and the attention fusion block could be made more explicit (e.g., by defining input/output tensors) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements for greater transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative results (28.14 dB PSNR, 0.717 SSIM on artifact-affected slices from the 'full dataset') are presented without any disclosure of dataset size (number of patients or volumes), train/test split strategy, whether artifacts are synthetic or real, baseline comparisons, or the procedure used to obtain and spatially align MVCT ground truth with kVCT. These details are load-bearing for interpreting the metrics as evidence of effective suppression and reliable transformation.
Authors: We agree that the abstract lacks critical contextual details needed to interpret the reported metrics. In the revised manuscript, we will expand the abstract to specify the dataset composition (number of patients and volumes), the train/test split strategy, confirmation that the metal artifacts are real (from clinical kVCT acquisitions with high-density implants), the baseline methods compared, and a concise description of the MVCT ground-truth acquisition and spatial alignment procedure with kVCT. These elements are described in the Experiments section but will now be summarized in the abstract as well. revision: yes
-
Referee: [Experiments] Experiments section: No ablation studies, cross-validation details, or statistical testing are described to isolate the contribution of the wavelet preprocessing, the transformer branch, or the attention fusion mechanism relative to simpler CNN-only or non-wavelet baselines. Without these, the performance numbers cannot be used to support the claim that the dual-path architecture is necessary or superior.
Authors: We concur that explicit ablations and statistical validation are necessary to substantiate the architectural choices. In the revised manuscript, we will add ablation experiments that systematically remove or replace the wavelet preprocessing stage, the transformer encoder branch, and the attention-based fusion module, comparing each variant against a CNN-only baseline. We will also report cross-validation details (e.g., patient-wise splits) and statistical tests (paired t-tests or Wilcoxon signed-rank tests with p-values) to demonstrate that the observed gains are significant and attributable to the hybrid design. revision: yes
Circularity Check
No circularity: empirical metrics reported as experimental outputs, not derived by construction
full rationale
The paper proposes a two-stage neural network (wavelet preprocessing + hybrid CNN-transformer Domain-TransNet) and reports PSNR/SSIM values as direct results of training and evaluation on the described dataset. No equations, uniqueness theorems, or fitted parameters are invoked to derive the performance numbers; they are presented as measured outcomes. No self-citations are used to justify core architectural choices or to close a derivation loop. The central claim therefore remains an independent empirical statement rather than a tautology.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
wavelet-based preprocessing module suppresses metal-induced artifacts through frequency-aware denoising... hybrid volumetric learning architecture... CNN-based encoder... transformer-based encoder... attention-based feature fusion
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
28.14 dB PSNR and 0.717 SSIM on artifact-affected slices
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
RadioGraphics 24, 1679–1691 (2004)
Barrett, J.F., Keat, N.: Artifacts in ct: Recognition and avoidance. RadioGraphics 24, 1679–1691 (2004). https://doi.org/10.1148/rg.246045065
-
[2]
Albumentations:fastandflexible image augmentations.Information11, 125 (2020)
Buslaev, A., Iglovikov, V.I., Khvedchenya, E., Parinov, A., Druzhinin, M., Kalinin, A.A.: Albumentations: Fast and flexible image augmentations. Information11(2), 125 (Feb 2020). https://doi.org/10.3390/info11020125
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
Physics in Medicine and Biology62(2017)
Giantsoudi, D., et al.: Metal artifacts in computed tomography for radiation ther- apy planning: Dosimetric effects and impact of metal artifact reduction. Physics in Medicine and Biology62(2017). https://doi.org/10.1088/1361-6560/aa5a22, please verify the exact publication details, such as issue number and page range, for accuracy
-
[5]
https://doi.org/10.1109/ACCESS.2016.2608621
Gjesteby, L.,DeMan, B., Jin,Y.,Paganetti,H.,Verburg,J.,Giantsoudi,D.,Wang, G.: Metal artifact reduction in ct: Where are we after four decades? IEEE Access 4, 5826–5849 (2016). https://doi.org/10.1109/ACCESS.2016.2608621
- [6]
-
[7]
arXiv preprint arXiv:2209.08575 , year=
Guo, M., Lu, C., Hou, Q., Liu, Z., Cheng, M.M., Hu, S.M.: Segnext: Rethink- ing convolutional attention design for semantic segmentation. arXiv preprint arXiv:2209.08575 (2022)
-
[8]
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks (2018)
work page 2018
-
[9]
CVPR (2017) 14 R.Mubashara et al
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. CVPR (2017) 14 R.Mubashara et al
work page 2017
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, L., Dai, B., Wu, W., Loy, C.C.: Focal frequency loss for image reconstruc- tion and synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13919–13929 (2021)
work page 2021
-
[11]
In: European conference on computer vision
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: European conference on computer vision. pp. 694–711. Springer (2016)
work page 2016
-
[12]
Scientific Reports12(1), 20823 (2022)
Kim, H., Yoo, S.K., Kim, D.W., Lee, H., Hong, C.S., Han, M.C., Kim, J.S.: Metal artifact reduction in kv ct images throughout two-step sequential deep convolu- tional neural networks by combining multi-modal imaging (martian). Scientific Reports12(1), 20823 (2022)
work page 2022
-
[13]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., Shi, W.: Photo-realistic single image super- resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4681–4690 (2017)
work page 2017
-
[14]
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., Shi, W.: Photo-realistic single image super- resolution using a generative adversarial network. In: Proc. IEEE Conf. Comput. Vis. Pattern Recognit. pp. 4681–4690 (2017)
work page 2017
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1833–1844 (2021)
work page 2021
-
[16]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Lin, W.A., Liao, H., Peng, C., Sun, X., Zhang, J., Luo, J., Chellappa, R., Zhou, S.K.: Dudonet: Dual domain network for ct metal artifact reduction. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10504–10513 (2019). https://doi.org/10.1109/CVPR.2019.01076
-
[17]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10012–10022 (2021)
work page 2021
-
[18]
Scientific reports6(1), 37608 (2016)
Liugang, G., Hongfei, S., Xinye, N., Mingming, F., Zheng, C., Tao, L.: Metal ar- tifact reduction through mvcbct and kvct in radiotherapy. Scientific reports6(1), 37608 (2016)
work page 2016
-
[19]
Journal of Medical Imaging and Radiation Sciences46(3), 291–297 (2015)
Maerz, M., Johnson, S., Cox, J.D.: Megavoltage computed tomography imaging: a review of current technology and applications in radiation therapy. Journal of Medical Imaging and Radiation Sciences46(3), 291–297 (2015)
work page 2015
-
[20]
Medical Physics37(10), 5482–5493 (2010)
Meyer, E., Raupach, R., Lell, M., Schmidt, B., Kachelriess, M.: Normalized metal artifact reduction (NMAR) in computed tomography. Medical Physics37(10), 5482–5493 (2010). https://doi.org/10.1118/1.3484090
-
[21]
Medical Physics 39(4), 1904–1916 (Apr 2012)
Meyer, E., Raupach, R., Lell, M., Schmidt, B., Kachelrieß, M.: Frequency split metal artifact reduction (FSMAR) in computed tomography. Medical Physics 39(4), 1904–1916 (Apr 2012). https://doi.org/10.1118/1.3691902
-
[22]
Medical Physics40(8), 081917 (2013)
Michielsen, K., Xia, T., Boone, J.M.: A novel metal artifact reduction algorithm in ct imaging for the improvement of radiotherapy planning. Medical Physics40(8), 081917 (2013)
work page 2013
-
[23]
Park, H.S., Lee, S.M., Kim, H.P., Seo, J.K., Chung, Y.E.: Ct sinogram-consistency learning for metal-induced beam hardening correction. Med. Phys.45(12), 5376– 5384 (2018)
work page 2018
-
[24]
IEEE Transactions on Medical Imaging 35(2), 480–487 (2016)
Park, H.S., Hwang, D., Seo, J.K.: Metal artifact reduction for polychromatic x-ray ct based on a beam-hardening corrector. IEEE Transactions on Medical Imaging 35(2), 480–487 (2016). https://doi.org/10.1109/TMI.2015.2481173 H3D-MarNet 15
-
[25]
In: Image Analysis and Processing – ICIAP 2025
Rehman, M., Martinel, N., Avanzo, M., Spizzo, R., Micheloni, C.: Remar-ds: Recal- ibrated feature learning for metal artifact reduction and ct domain transformation. In: Image Analysis and Processing – ICIAP 2025. pp. 212–223. Springer Nature Switzerland, Cham (2026)
work page 2025
-
[26]
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: 2015 18th Int. Conf. Med. Image Comput. Comput.- Assist. Interv.–MICCAI Munich Germany October 5-9 2015 Proc. Part III. vol. 18, pp. 234–241 (2015)
work page 2015
-
[27]
Serrano-Antón, B., Rehman, M., Martinel, N., Avanzo, M., Spizzo, R., Fanetti, G., P. Muñuzuri, A., Micheloni, C.: Mar-dtn: Metal artifact reduction using domain transformation network for radiotherapy planning. In: Pattern Recognition. pp. 143–159. Springer Nature Switzerland (2025)
work page 2025
-
[28]
Wang, H., Li, Y., He, N., Ma, K., Meng, D., Zheng, Y.: Dicdnet: Deep interpretable convolutional dictionary network for metal artifact reduction in ct images. IEEE Trans. Med. Imag.41(4), 869–880 (Apr 2022)
work page 2022
-
[29]
Wang, H., Li, Y., Meng, D., Zheng, Y.: Adaptive convolutional dictionary net- work for ct metal artifact reduction. In: Raedt, L.D. (ed.) Proc. 31st Int. Joint Conf. Artif. Intell. IJCAI-22. pp. 1401–1407. Int. Joint Conf. Artif. Intell. Org. (2022), https://doi.org/10.24963/ijcai.2022/195, [online] Available: https://doi.org/10.24963/ijcai.2022/195
-
[30]
Medical im- age computing and computer-assisted intervention : MICCAI
Wang, J., Zhao, Y., Noble, J.H., Dawant, B.M.: Conditional generative adver- sarial networks for metal artifact reduction in ct images of the ear. Medical im- age computing and computer-assisted intervention : MICCAI ... International Conference on Medical Image Computing and Computer-Assisted Intervention 11070, 3—11 (September 2018). https://doi.org/10....
-
[31]
Wang, S., Li, L., Zhuang, X.: AttU-NET: Attention U-Net for brain tumor seg- mentation. In: Crimi, A., Bakas, S. (eds.) Brainlesion: Glioma, Multiple Scle- rosis, Stroke and Traumatic Brain Injuries, Lecture Notes in Computer Sci- ence, vol. 13218, pp. 302–311. Springer International Publishing, Cham (2022). https://doi.org/10.1007/978-3-031-09002-8_27
-
[32]
Xu, L., Zhou, S., Guo, J., Tian, W., Tang, W., Yi, Z.: Metal artifact reduction for oral and maxillofacial computed tomography images by a generative adversarial network. Appl. Intell.52(11), 13184–13194 (2022)
work page 2022
-
[33]
In: The IEEE Conference on Computer Vision and Pattern Recognition(CVPR) (2018)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: The IEEE Conference on Computer Vision and Pattern Recognition(CVPR) (2018)
work page 2018
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.