Recognition: 2 theorem links
· Lean TheoremDelay-Empowered Causal Hierarchical Reinforcement Learning
Pith reviewed 2026-05-13 05:37 UTC · model grok-4.3
The pith
DECHRL learns causal structures and stochastic delay distributions from delayed observations to drive empowerment-based exploration in hierarchical reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
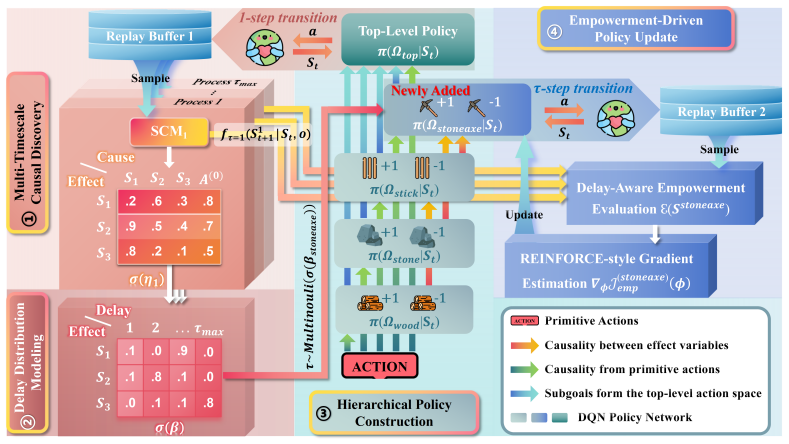
DECHRL explicitly models both the causal structure of state transitions and their associated stochastic delay distributions. These are then incorporated into a delay-aware empowerment objective that drives proactive exploration toward highly controllable states, thereby improving performance under temporal uncertainty.
What carries the argument
The delay-aware empowerment objective, built on learned causal models of state transitions and stochastic delay distributions inside a hierarchical reinforcement learning architecture.
If this is right
- Agents can manage variable and unknown delays without requiring advance knowledge of their statistics.
- The combination of hierarchy, causal modeling, and delay-aware empowerment produces more robust decision-making than state-augmentation or prior-knowledge baselines.
- Proactive exploration is directed toward states that remain controllable even when effects are stochastically delayed.
- Performance gains appear in both grid-world and Minecraft-like domains once stochastic delays are introduced.
Where Pith is reading between the lines
- The same modeling approach could be applied to continuous-control domains such as robotic manipulation where actuator or sensor delays vary with load.
- If the learned causal graphs remain stable under changing delay statistics, the method might serve as a building block for lifelong learning under non-stationary timing.
- One could test whether the empowerment term still yields gains when delays are allowed to depend on the chosen actions rather than being independent.
Load-bearing premise
The causal structure of state transitions and the stochastic delay distributions can be accurately learned from delayed observations alone without prior knowledge or non-delayed data.
What would settle it
In a controlled test environment with known ground-truth causal structure and delay distributions, measure whether DECHRL recovers those distributions accurately and whether removing the causal or delay components causes a clear drop in performance relative to the full method.
Figures







read the original abstract
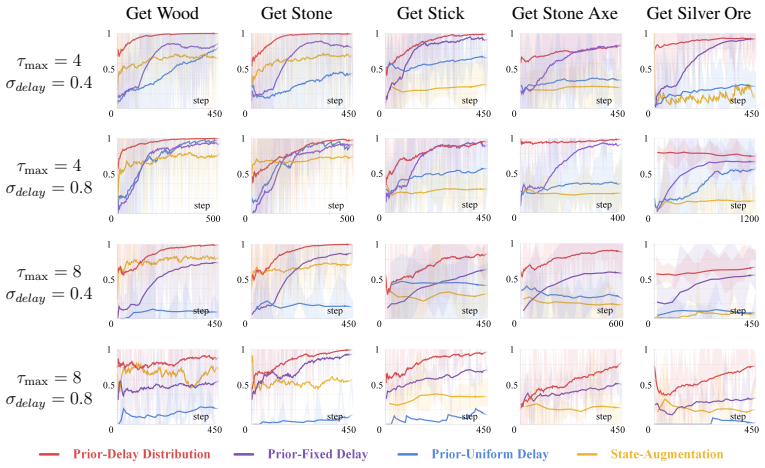
Many real-world tasks involve delayed effects, where the outcomes of actions emerge after varying time lags. Existing delay-aware reinforcement learning methods often rely on state augmentation, prior knowledge of delay distributions, or access to non-delayed data, limiting their generalization. Hierarchical reinforcement learning, by contrast, inherently offers advantages in handling delays due to its hierarchical structure, yet existing methods are restricted to fixed delays. To address these limitations, we propose Delay-Empowered Causal Hierarchical Reinforcement Learning (DECHRL). DECHRL explicitly models both the causal structure of state transitions and their associated stochastic delay distributions. These are then incorporated into a delay-aware empowerment objective that drives proactive exploration toward highly controllable states, thereby improving performance under temporal uncertainty. We evaluate DECHRL in modified 2D-Minecraft and MiniGrid environments featuring stochastic delays. Experimental results show that DECHRL effectively models temporal delays and significantly outperforms baselines in decision-making under temporal uncertainty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Delay-Empowered Causal Hierarchical Reinforcement Learning (DECHRL) for RL tasks with stochastic action delays. It claims to jointly learn the causal structure of state transitions and the associated per-transition stochastic delay distributions p(τ|s,a,s') directly from delayed observation sequences, embed these into a delay-aware empowerment objective that promotes exploration of controllable states, and thereby achieve superior decision-making compared to baselines. Evaluation is performed on modified 2D-Minecraft and MiniGrid environments that inject stochastic delays; the abstract states that DECHRL effectively models delays and significantly outperforms existing methods.
Significance. If the identifiability and performance claims hold, the work would offer a meaningful step toward practical hierarchical RL in real-world settings with unknown temporal uncertainties, by removing the need for prior delay knowledge or non-delayed data that limits prior delay-aware methods. The integration of causal discovery with empowerment-style objectives is conceptually attractive and could generalize beyond the tested domains.
major comments (2)
- [Abstract and §3 (Method)] Abstract and §3 (Method): The central claim that the causal graph and delay distribution p(τ|s,a,s') can be recovered solely from sequences of delayed (s_t, a_t, s_{t+τ}) tuples is load-bearing yet unsupported by any identifiability argument or set of sufficient conditions. In stochastic-delay regimes each observed transition is a mixture over unknown lags; without known delay support, parametric restrictions on the kernel, or access to non-delayed rollouts, multiple (graph, delay) pairs are consistent with the same marginal transition statistics. Consequently the delay-aware empowerment objective operates on a potentially mis-specified model, and any reported performance gain is conditional on successful disentanglement that has not been demonstrated.
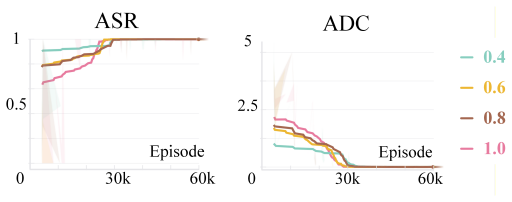
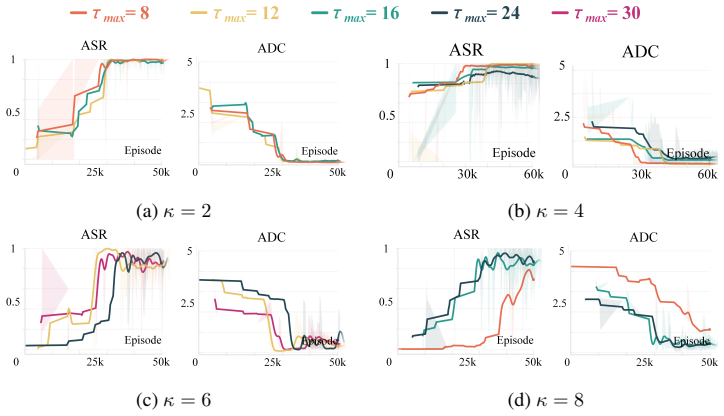
- [§4 (Experiments)] §4 (Experiments): The abstract asserts that DECHRL 'significantly outperforms baselines' and 'effectively models temporal delays,' but the provided description contains no quantitative metrics, error bars, ablation results isolating the causal-modeling or delay-distribution components, or statistical significance tests. Without these, it is impossible to assess whether the empirical results actually support the superiority claim or merely reflect implementation details.
minor comments (2)
- [§3] Notation for the delay distribution and empowerment objective should be introduced with explicit equations rather than descriptive prose alone.
- [§4] The environments are described only as 'modified' 2D-Minecraft and MiniGrid; a precise description of how stochastic delays are injected (support, sampling procedure) belongs in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address the two major concerns point by point below. Both points are valid and will be incorporated into a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] Abstract and §3 (Method): The central claim that the causal graph and delay distribution p(τ|s,a,s') can be recovered solely from sequences of delayed (s_t, a_t, s_{t+τ}) tuples is load-bearing yet unsupported by any identifiability argument or set of sufficient conditions. In stochastic-delay regimes each observed transition is a mixture over unknown lags; without known delay support, parametric restrictions on the kernel, or access to non-delayed rollouts, multiple (graph, delay) pairs are consistent with the same marginal transition statistics. Consequently the delay-aware empowerment objective operates on a potentially mis-specified model, and any reported performance gain is conditional on successful disentanglement that has not been demonstrated.
Authors: We agree that the manuscript lacks a formal identifiability argument or sufficient conditions for unique recovery of the causal graph and per-transition delay distributions from delayed observation sequences alone. This is a genuine limitation of the current presentation. Our method relies on joint optimization of the causal model parameters together with the delay-aware empowerment objective inside the hierarchical policy; the hierarchical decomposition and the controllability-driven exploration provide an inductive bias that promotes disentanglement in practice. We will revise §3 to explicitly state the absence of a general identifiability guarantee, discuss the mixture-of-lags problem, and articulate the modeling assumptions (e.g., finite delay support, Markovian state transitions, and the role of the empowerment term) under which the learned model remains useful. We will also add a short synthetic-data experiment illustrating recovery quality under controlled stochastic-delay conditions. revision: partial
-
Referee: [§4 (Experiments)] §4 (Experiments): The abstract asserts that DECHRL 'significantly outperforms baselines' and 'effectively models temporal delays,' but the provided description contains no quantitative metrics, error bars, ablation results isolating the causal-modeling or delay-distribution components, or statistical significance tests. Without these, it is impossible to assess whether the empirical results actually support the superiority claim or merely reflect implementation details.
Authors: We concur that the experimental section requires substantially more quantitative detail. While the manuscript contains performance plots, the accompanying text does not report numerical values, variability measures, component ablations, or statistical tests. In the revised version we will expand §4 with tables reporting mean returns and standard deviations over at least five independent seeds, ablation variants that disable either the causal-graph learner or the explicit delay-distribution estimator, and paired t-test p-values comparing DECHRL against each baseline. These additions will allow readers to evaluate the magnitude and reliability of the reported gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a pipeline of learning causal transition structure and stochastic delay distributions from delayed observations, then feeding those learned quantities into a delay-aware empowerment objective for exploration. This is a standard modeling-then-optimize structure in RL and does not reduce by construction to its inputs; the objective is defined on the outputs of the learned models rather than being a tautological re-expression of the fitting loss. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are indicated in the abstract or description. The method is evaluated on modified environments with external performance metrics, keeping the central claim falsifiable and independent of the fitting process itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- stochastic delay distribution parameters
axioms (1)
- domain assumption Hierarchical reinforcement learning inherently offers advantages in handling delays due to its hierarchical structure
invented entities (1)
-
delay-aware empowerment objective
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDECHRL explicitly models both the causal structure of state transitions and their associated stochastic delay distributions. These are then incorporated into a delay-aware empowerment objective that drives proactive exploration toward highly controllable states
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe propose DECHRL, a novel Causal Hierarchical Reinforcement Learning (CHRL) framework that explicitly integrates stochastic delay distribution modeling with a delay-aware empowerment objective
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton, A. G. Barto, et al., Reinforcement learning, Journal of Cognitive Neuroscience 11 (1) (1999) 126–134
work page 1999
-
[2]
S. Nath, M. Baranwal, H. Khadilkar, Revisiting state augmentation methods for reinforcement learning with stochastic delays, in: Proceedings of the 30th ACM international conference on information & knowledge management, 2021, pp. 1346–1355
work page 2021
-
[3]
Y . Bouteiller, S. Ramstedt, G. Beltrame, C. Pal, J. Binas, Reinforcement learning with random delays, in: International conference on learning repre- sentations, 2020
work page 2020
- [4]
-
[5]
A. Karamzade, K. Kim, M. Kalsi, R. Fox, Reinforcement learning from delayed observations via world models, CoRR abs/2403.12309 (2024). arXiv:2403.12309,doi:10.48550/ARXIV.2403.12309. URLhttps://doi.org/10.48550/arXiv.2403.12309
-
[6]
M. Agarwal, V . Aggarwal, Blind decision making: Reinforcement learning with delayed observations, Pattern Recognit. Lett. 150 (2021) 176–182. doi: 10.1016/J.PATREC.2021.06.022. URLhttps://doi.org/10.1016/j.patrec.2021.06.022 41
-
[7]
Z. Yu, C. Fu, H. Zhong, W. Wang, W. Wu, C. J. Xue, Delay-aware reinforce- ment learning: Insights from delay distributional perspective
-
[8]
E. Schuitema, L. Bu¸ soniu, R. Babuška, P. Jonker, Control delay in reinforce- ment learning for real-time dynamic systems: A memoryless approach, in: 2010 IEEE/RSJ international conference on intelligent robots and systems, IEEE, 2010, pp. 3226–3231
work page 2010
-
[9]
W. Wang, D. Han, X. Luo, D. Li, Addressing signal delay in deep reinforcement learning, in: ICLR 2024, 2024. URL https://www.microsoft.com/en-us/research/ publication/addressing-signal-delay-in-deep-reinforcement-learning/
work page 2024
- [10]
- [11]
- [12]
- [13]
-
[14]
C. Zhao, D. Shi, M. Wang, J. Xia, H. Yang, S. Jin, S. Yang, C. Qiu, D3hrl: A distributed hierarchical reinforcement learning approach based on causal discovery and spurious correlation detection, Neural Networks 195 (2026) 108275. doi:https://doi.org/10.1016/j.neunet. 2025.108275. URL https://www.sciencedirect.com/science/article/ pii/S0893608025011566
-
[15]
X. Hu, R. Zhang, K. Tang, J. Guo, Q. Yi, R. Chen, Z. Du, L. Li, Q. Guo, Y . Chen, et al., Causality-driven hierarchical structure discovery for reinforce- ment learning, Advances in Neural Information Processing Systems 35 (2022) 20064–20076. 42
work page 2022
- [16]
-
[17]
S. Sohn, J. Oh, H. Lee, Hierarchical reinforcement learning for zero-shot generalization with subtask dependencies, Advances in neural information processing systems 31 (2018)
work page 2018
-
[18]
M. Chevalier-Boisvert, B. Dai, M. Towers, R. de Lazcano, L. Willems, S. Lahlou, S. Pal, P. S. Castro, J. Terry, Minigrid & miniworld: Modu- lar & customizable reinforcement learning environments for goal-oriented tasks, CoRR abs/2306.13831 (2023)
- [19]
-
[20]
Y . Li, Y . Wang, X. Tan, Highly valued subgoal generation for efficient goal- conditioned reinforcement learning, Neural Networks 181 (2025) 106825. doi:10.1016/J.NEUNET.2024.106825. URLhttps://doi.org/10.1016/j.neunet.2024.106825
-
[21]
O. Corcoll, R. Vicente, Disentangling controlled effects for hierarchical reinforcement learning, in: Conference on Causal Learning and Reasoning, PMLR, 2022, pp. 178–200
work page 2022
-
[22]
T. E. Lee, S. Vats, S. Girdhar, O. Kroemer, Scale: Causal learning and discovery of robot manipulation skills using simulation, in: CoRL 2023 Workshop on Learning Effective Abstractions for Planning (LEAP), 2023
work page 2023
- [23]
-
[24]
B. Chen, Z. Cao, W. Mayer, M. Stumptner, R. Kowalczyk, Hcpi-hrl: Human causal perception and inference-driven hierarchical reinforcement learning, Neural Networks 187 (2025) 107318
work page 2025
-
[25]
M. H. Nguyen, H. Le, S. Venkatesh, Variable-agnostic causal exploration for reinforcement learning, in: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer, 2024, pp. 216–232. 43
work page 2024
-
[26]
S. Mohamed, D. Jimenez Rezende, Variational information maximisation for intrinsically motivated reinforcement learning, Advances in neural informa- tion processing systems 28 (2015)
work page 2015
- [27]
-
[28]
B. Eysenbach, A. Gupta, J. Ibarz, S. Levine, Diversity is all you need: Learn- ing skills without a reward function, arXiv preprint arXiv:1802.06070 (2018)
- [29]
-
[30]
H. Bharadhwaj, M. Babaeizadeh, D. Erhan, S. Levine, Information prior- itization through empowerment in visual model-based rl, arXiv preprint arXiv:2204.08585 (2022)
- [31]
- [32]
- [33]
-
[34]
Y . Bengio, T. Deleu, N. Rahaman, N. R. Ke, S. Lachapelle, O. Bilaniuk, A. Goyal, C. J. Pal, A meta-transfer objective for learning to disentangle causal mechanisms, in: 8th International Conference on Learning Represen- tations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, OpenRe- view.net, 2020. URLhttps://openreview.net/forum?id=ryxWIgBFPS
work page 2020
-
[35]
P. Spirtes, C. Glymour, R. Scheines, Causation, Prediction, and Search, Second Edition, Adaptive computation and machine learning, MIT Press, 2000. 44
work page 2000
-
[36]
C. Boutilier, R. Dearden, M. Goldszmidt, Stochastic dynamic programming with factored representations, Artif. Intell. 121 (1-2) (2000) 49–107. doi: 10.1016/S0004-3702(00)00033-3. URLhttps://doi.org/10.1016/S0004-3702(00)00033-3
-
[37]
Pearl, Models, reasoning and inference, Cambridge, UK: CambridgeUni- versityPress 19 (2) (2000) 3
J. Pearl, Models, reasoning and inference, Cambridge, UK: CambridgeUni- versityPress 19 (2) (2000) 3
work page 2000
-
[38]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal policy optimization algorithms, CoRR abs/1707.06347 (2017). arXiv: 1707.06347. URLhttp://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [39]
-
[40]
M. Andrychowicz, D. Crow, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, P. Abbeel, W. Zaremba, Hindsight experience replay, in: I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V . N. Vishwanathan, R. Garnett (Eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing...
work page 2017
-
[41]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.