Recognition: no theorem link
What makes a word hard to learn? Modeling L1 influence on English vocabulary difficulty
Pith reviewed 2026-05-13 04:57 UTC · model grok-4.3
The pith
Word familiarity is the main driver of English vocabulary difficulty for learners whose first language is Spanish, German, or Chinese, with orthographic transfer adding explanatory power only for the first two groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
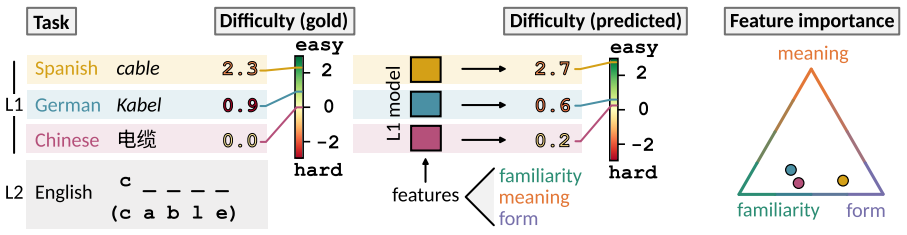
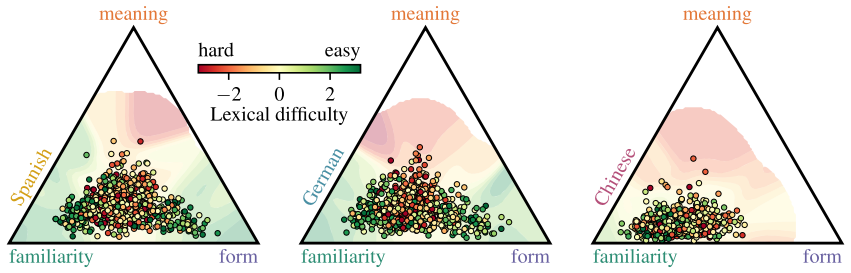
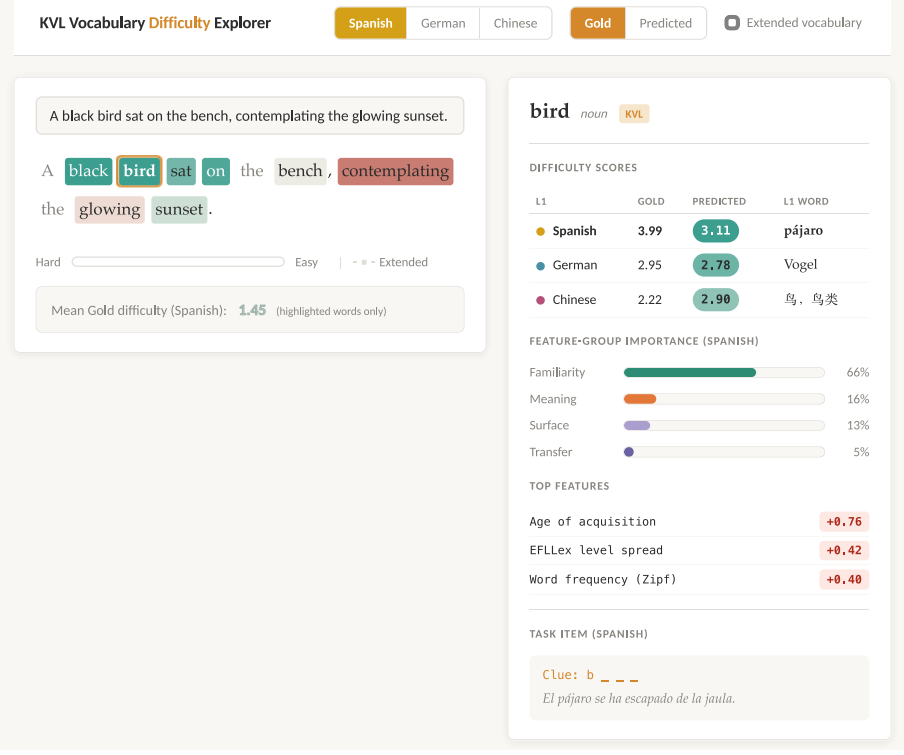
Gradient-boosted models trained on familiarity, meaning, surface-form, and cross-linguistic-transfer features and interpreted with Shapley values establish that word familiarity is the dominant feature group for vocabulary difficulty in all three learner populations. Spanish and German learners additionally depend on orthographic transfer, a mechanism unavailable to Chinese learners whose difficulty is instead shaped by familiarity combined with surface features.
What carries the argument
Gradient-boosted regression models whose predictions are decomposed with Shapley additive explanations to measure the contribution of four feature groups: familiarity, meaning, surface form, and cross-linguistic transfer.
If this is right
- L1-tailored difficulty estimates can be used directly to select and sequence vocabulary in language curricula.
- Teaching materials for Spanish- and German-speaking learners should exploit orthographic similarities where they exist.
- Materials for Chinese-speaking learners should instead emphasize surface-form properties such as length and spelling regularity.
- The same modeling approach can generate difficulty scores for any new English word without requiring fresh learner data.
Where Pith is reading between the lines
- If orthographic transfer is confirmed as the differentiating mechanism, language apps could automatically highlight cognate forms for Romance and Germanic learners but skip that cue for Chinese learners.
- The surface-feature reliance observed for Chinese speakers suggests that explicit instruction on English spelling patterns may yield larger gains for this group than for the others.
Load-bearing premise
The selected feature groups and the Shapley analysis of gradient-boosted models are sufficient to identify the true factors that drive L1-influenced vocabulary difficulty.
What would settle it
A replication that collects new difficulty ratings from the same learner groups and finds that adding unmodeled variables such as semantic neighborhood density or individual learner exposure history reverses the ranking of familiarity versus orthographic transfer for Spanish or German speakers.
Figures









read the original abstract
What makes a word difficult to learn, and how does the difficulty depend on the learner's native language? We computationally model vocabulary difficulty for English learners whose first language is Spanish, German, or Chinese with gradient-boosted models trained on features related to a word's familiarity (e.g., frequency), meaning, surface form, and cross-linguistic transfer. Using Shapley values, we determine the importance of each feature group. Word familiarity is the dominant feature group shared by all three languages. However, predictions for Spanish- and German-speaking learners rely additionally on orthographic transfer. This transfer mechanism is unavailable to Chinese learners, whose difficulty is shaped by a combination of familiarity and surface features alone. Our models provide interpretable, L1-tailored difficulty estimates that can be used to design vocabulary curricula.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper computationally models the difficulty of English words for learners with L1 Spanish, German, or Chinese using gradient-boosted models. Features are grouped into familiarity (e.g., frequency), meaning, surface form, and cross-linguistic transfer. SHAP values are used to assess the importance of each group. The main result is that familiarity is the dominant factor for all L1s, with additional reliance on orthographic transfer for Spanish and German learners, while Chinese learners' difficulty is determined by familiarity and surface features. The models aim to provide L1-specific difficulty estimates for curriculum design.
Significance. If the SHAP-based attributions hold after accounting for potential feature dependencies, this work would contribute meaningfully to understanding L1 effects on vocabulary learning by providing a data-driven, interpretable framework that differentiates between alphabetic and logographic L1 influences. It builds on standard ML techniques in NLP but applies them to a practical educational question, with potential applications in adaptive language learning systems. The explicit comparison across three L1s strengthens the cross-linguistic aspect.
major comments (2)
- [Feature importance attribution] The key finding that orthographic transfer is important only for Spanish and German (but not Chinese) depends on the stability of SHAP group-level attributions. However, the paper does not report correlations between feature groups (e.g., between familiarity features like log-frequency and transfer features like orthographic similarity). If such correlations exist, SHAP may misallocate importance, weakening the claim of distinct L1 mechanisms. An ablation study removing transfer features and comparing model performance or SHAP changes across L1s would strengthen this.
- [Model training and evaluation] The abstract and summary provide no details on model performance (e.g., R², accuracy on held-out data), dataset size, or validation methods. Without these, it is difficult to gauge whether the gradient-boosted models are reliable enough to support the SHAP interpretations and the central claims about feature group importance.
minor comments (2)
- Ensure all acronyms are defined on first use, such as SHAP.
- [Figure 1] The SHAP summary plots could benefit from clearer labeling of the four feature groups to aid reader interpretation.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback, which has helped us identify areas to strengthen the manuscript. We address each major comment below and will incorporate revisions to improve the robustness and transparency of our analyses.
read point-by-point responses
-
Referee: [Feature importance attribution] The key finding that orthographic transfer is important only for Spanish and German (but not Chinese) depends on the stability of SHAP group-level attributions. However, the paper does not report correlations between feature groups (e.g., between familiarity features like log-frequency and transfer features like orthographic similarity). If such correlations exist, SHAP may misallocate importance, weakening the claim of distinct L1 mechanisms. An ablation study removing transfer features and comparing model performance or SHAP changes across L1s would strengthen this.
Authors: We agree that unreported correlations between feature groups could potentially influence SHAP attributions and that an ablation analysis would provide stronger evidence for L1-specific mechanisms. In the revised manuscript, we will compute and report Pearson correlations between all feature groups (familiarity, meaning, surface form, and cross-linguistic transfer) separately for each L1. We will also conduct an ablation study by retraining the gradient-boosted models without the transfer features, then compare changes in overall model performance (R² on held-out data) and shifts in SHAP values for the remaining groups across the Spanish, German, and Chinese cohorts. These additions will directly address concerns about feature dependencies and the stability of our key claims. revision: yes
-
Referee: [Model training and evaluation] The abstract and summary provide no details on model performance (e.g., R², accuracy on held-out data), dataset size, or validation methods. Without these, it is difficult to gauge whether the gradient-boosted models are reliable enough to support the SHAP interpretations and the central claims about feature group importance.
Authors: We concur that explicit reporting of model performance, dataset characteristics, and validation procedures is necessary to support the reliability of the SHAP-based conclusions. In the revised manuscript, we will update the abstract to include summary performance metrics (e.g., mean R² on held-out test sets) and add a new subsection in the Methods detailing the dataset sizes (number of words rated per L1 and total learner responses), the train/validation/test split ratios, the cross-validation strategy employed, and the hyperparameter optimization process for the gradient-boosted models. These details will enable readers to assess the models' predictive validity and the robustness of the feature importance attributions. revision: yes
Circularity Check
No circularity: purely empirical modeling with post-hoc SHAP attributions
full rationale
The paper trains gradient-boosted regression models on a set of hand-crafted linguistic features (familiarity, meaning, surface form, cross-linguistic transfer) to predict vocabulary difficulty ratings for three L1 groups, then applies the established SHAP method to compute feature-group importances. No equations, derivations, or first-principles claims are present; the reported dominance of familiarity and the L1-specific role of orthographic transfer are direct outputs of the fitted models and their explanations rather than inputs restated by construction. No self-citations are load-bearing, no parameters are fitted on a subset and then relabeled as predictions, and no ansatz or uniqueness theorem is smuggled in. The analysis is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- Gradient boosting hyperparameters
- Feature grouping thresholds
axioms (2)
- domain assumption SHAP values accurately attribute the contribution of each feature group to model predictions.
- domain assumption The chosen word features adequately represent the linguistic influences on vocabulary difficulty.
Reference graph
Works this paper leans on
-
[1]
Lisa Beinborn, Torsten Zesch, and Iryna Gurevych. 2014. https://doi.org/10.1075/itl.165.2.02bei Readability for foreign language learning: The importance of cognates . ITL - International Journal of Applied Linguistics, 165(2):136--162
-
[2]
Lisa Beinborn, Torsten Zesch, and Iryna Gurevych. 2016. https://doi.org/10.18653/v1/W16-0508 Predicting the spelling difficulty of words for language learners . In Proceedings of the 11th Workshop on Innovative Use of NLP for Building Educational Applications , pages 73--83, San Diego, CA, USA. Association for Computational Linguistics
-
[3]
Marsha Bensoussan and Batia Laufer. 1984. https://doi.org/10.1111/j.1467-9817.1984.tb00252.x Lexical guessing in context in EFL reading comprehension . Journal of Research in Reading, 7(1):15--32
-
[4]
Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. https://doi.org/10.1162/tacl_a_00051 Enriching word vectors with subword information . Transactions of the Association for Computational Linguistics, 5:135--146
-
[5]
Roger Brown and David McNeill. 1966. https://doi.org/10.1016/S0022-5371(66)80040-3 The ``tip of the tongue'' phenomenon . Journal of Verbal Learning and Verbal Behavior, 5(4):325--337
-
[6]
Bram Bult \'e , Alex Housen, and Gabriele Pallotti. 2025. https://doi.org/10.1111/lang.12669 Complexity and difficulty in second language acquisition: A theoretical and methodological overview . Language Learning, 75(2):533--574
-
[7]
Brent Culligan. 2015. https://doi.org/10.1177/0265532215572268 A comparison of three test formats to assess word difficulty . Language Testing, 32(4):503--520
-
[8]
Mihai Dascalu, Danielle McNamara, Scott Crossley, and Stefan Trausan-Matu . 2016. https://doi.org/10.1609/aaai.v30i1.10372 Age of exposure: A model of word learning . In Proceedings of the AAAI Conference on Artificial Intelligence , volume 30, Phoenix, AZ, USA. AAAI Press
-
[9]
Paul De Boeck. 2008. https://doi.org/10.1007/s11336-008-9092-x Random item IRT models . Psychometrika, 73(4):533--559
-
[10]
Annette M. B. De Groot and Rineke Keijzer. 2000. https://doi.org/10.1111/0023-8333.00110 What is hard to learn is easy to forget: The roles of word concreteness, cognate status, and word frequency in foreign-language vocabulary learning and forgetting . Language Learning, 50(1):1--56
-
[11]
Karen J. Dunn. 2024. https://doi.org/10.1016/j.rmal.2024.100143 Random-item rasch models and explanatory extensions: A worked example using L2 vocabulary test item responses . Research Methods in Applied Linguistics, 3(3):100143
-
[12]
Luise D \"u rlich and Thomas Fran c ois. 2018. https://aclanthology.org/L18-1140/ EFLLex : A graded lexical resource for learners of English as a foreign language . In Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018) , Miyazaki, Japan. European Language Resources Association (ELRA)
work page 2018
-
[13]
Nick C. Ellis. 2002. https://doi.org/10.1017/S0272263102002024 Frequency effects in language processing: A review with implications for theories of implicit and explicit language acquisition . Studies in Second Language Acquisition, 24(2):143--188
-
[14]
Nick C. Ellis and Alan Beaton. 1993. https://doi.org/10.1111/j.1467-1770.1993.tb00627.x Psycholinguistic determinants of foreign language vocabulary learning . Language Learning, 43(4):559--617
-
[15]
Europarat , editor. 2011. https://www.coe.int/lang-cefr Common European framework of reference for languages: Learning , teaching, assessment , 12th edition. Cambridge University Press, Cambridge, UK
work page 2011
-
[16]
Mariano Felice and Lucy Skidmore. 2026. Shared task on vocabulary difficulty prediction for English learners. In Proceedings of the 21st Workshop on Innovative Use of NLP for Building Educational Applications ( BEA 2026) , San Diego, CA, USA. Association for Computational Linguistics
work page 2026
-
[17]
Christiane Fellbaum, editor. 1998. https://doi.org/10.7551/mitpress/7287.001.0001 WordNet : An Electronic Lexical Database , 1st edition. The MIT Press, Cambridge, MA, USA
-
[18]
Pierre Finnimore, Elisabeth Fritzsch, Daniel King, Alison Sneyd, Aneeq Ur Rehman, Fernando Alva-Manchego , and Andreas Vlachos. 2019. https://doi.org/10.18653/v1/N19-1102 Strong baselines for complex word identification across multiple languages . In Proceedings of the 2019 Conference of the North , pages 970--977, Minneapolis, MN, USA. Association for Co...
-
[19]
Wolfgang H \"a rdle. 1990. https://doi.org/10.1017/CCOL0521382483 Applied Nonparametric Regression , 1st edition. Cambridge University Press, Cambridge, UK
-
[20]
Yusuke Ide, Masato Mita, Adam Nohejl, Hiroki Ouchi, and Taro Watanabe. 2023. https://doi.org/10.18653/v1/2023.bea-1.40 Japanese lexical complexity for non-native readers: A new dataset . In Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications ( BEA 2023) , pages 477--487, Toronto, Canada. Association for Computat...
-
[21]
Lori E. James and Deborah M. Burke. 2000. https://doi.org/10.1037/0278-7393.26.6.1378 Phonological priming effects on word retrieval and tip-of-the-tongue experiences in young and older adults . Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(6):1378--1391
-
[22]
Victor Kuperman, Hans Stadthagen-Gonzalez , and Marc Brysbaert. 2012. https://doi.org/10.3758/s13428-012-0210-4 Age-of-acquisition ratings for 30,000 English words . Behavior Research Methods, 44(4):978--990
-
[23]
Batia Laufer and Zahava Goldstein. 2004. https://doi.org/10.1111/j.0023-8333.2004.00260.x Testing vocabulary knowledge: Size , strength, and computer adaptiveness . Language Learning, 54(3):399--436
-
[24]
John Lee and Chak Yan Yeung. 2018 a . https://doi.org/10.1109/ICNLSP.2018.8374392 Automatic prediction of vocabulary knowledge for learners of Chinese as a foreign language . In 2018 2nd International Conference on Natural Language and Speech Processing ( ICNLSP ) , pages 1--4, Algiers. IEEE
-
[25]
John Lee and Chak Yan Yeung. 2018 b . https://aclanthology.org/C18-1019/ Personalizing lexical simplification . In Proceedings of the 27th International Conference on Computational Linguistics , pages 224--232, Santa Fe, NM, USA. Association for Computational Linguistics
work page 2018
-
[26]
Scott M. Lundberg, Gabriel G. Erion, and Su-In Lee. 2018. https://doi.org/10.48550/arXiv.1802.03888 Consistent individualized feature attribution for tree ensembles . arXiv preprint
-
[27]
Scott M. Lundberg and Su-In Lee. 2017. https://dl.acm.org/doi/10.5555/3295222.3295230 A unified approach to interpreting model predictions . In Proceedings of the 31st International Conference on Neural Information Processing Systems , pages 4768--4777, Long Beach, CA, USA. Curran Associates Inc
-
[28]
George A. Miller. 1995. https://doi.org/10.1145/219717.219748 WordNet : A lexical database for English . Communications of the ACM, 38(11):39--41
-
[29]
Theory of Probability & Its Applica- tions9(1), 141–142 (1964) https://doi.org/10.1137/1109020
\`E lizbar A. Nadaraya. 1964. https://doi.org/10.1137/1109020 On estimating regression . Theory of Probability and Its Applications, 9(1):141--142
-
[30]
Ian Stephen Paul Nation. 2000. https://doi.org/10.1017/CBO9781139524759 Learning Vocabulary in Another Language , 1st edition. Cambridge University Press, Cambridge, UK
-
[31]
Masashi Negishi, Tomoko Takada, and Yukio Tono. 2013. https://aclanthology.org/2016.jeptalnrecital-long.17/ A progress report on the development of the CEFR-J . In Evelina D. Galaczi and Cyril J. Weir, editors, Exploring language frameworks: Proceedings of the ALTE Krak\'ow Conference , July 2011 , 1st edition, number 36 in Studies in language testing. Ca...
work page 2013
-
[32]
Daiki Nishihara and Tomoyuki Kajiwara. 2020. https://aclanthology.org/2020.lrec-1.381/ Word complexity estimation for Japanese lexical simplification . In Proceedings of the Twelfth Language Resources and Evaluation Conference , pages 3114--3120, Marseille, France. European Language Resources Association
work page 2020
-
[33]
Adam Nohejl, Akio Hayakawa, Yusuke Ide, and Taro Watanabe. 2024. https://doi.org/10.18653/v1/2024.tsar-1.8 Difficult for whom? A study of Japanese lexical complexity . In Proceedings of the Third Workshop on Text Simplification , Accessibility and Readability ( TSAR 2024) , pages 69--81, Miami, FL, USA. Association for Computational Linguistics
-
[34]
Kai North and Marcos Zampieri. 2023. https://doi.org/10.3389/frai.2023.1236963 Features of lexical complexity: insights from L1 and L2 speakers . Frontiers in Artificial Intelligence, 6:1236963
-
[35]
Kai North, Marcos Zampieri, and Matthew Shardlow. 2023. https://doi.org/10.1145/3557885 Lexical complexity prediction: An overview . ACM Computing Surveys, 55(9):1--42
-
[36]
Terence Odlin. 1989. https://doi.org/10.1017/CBO9781139524537 Language Transfer : Cross-Linguistic Influence in Language Learning , 1st edition. Cambridge University Press, Cambridge, UK
-
[37]
Momose Oyama, Sho Yokoi, and Hidetoshi Shimodaira. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.131 Norm of word embedding encodes information gain . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 2108--2130, Singapore. Association for Computational Linguistics
-
[38]
Gustavo Paetzold and Lucia Specia. 2016. https://doi.org/10.18653/v1/S16-1085 SemEval 2016 task 11: Complex word identification . In Proceedings of the 10th International Workshop on Semantic Evaluation ( SemEval-2016 ) , pages 560--569, San Diego, CA, USA. Association for Computational Linguistics
-
[39]
Alessio Palmero Aprosio, Stefano Menini, and Sara Tonelli. 2020. https://doi.org/10.1145/3340631.3394857 Adaptive complex word identification through false friend detection . In Proceedings of the 28th ACM Conference on User Modeling , Adaptation and Personalization , pages 192--200, Genoa Italy. ACM
-
[40]
Elke Peters. 2019. https://www.routledge.com/The-Routledge-Handbook-of-Vocabulary-Studies/Webb/p/book/9781138735729 Factors affecting the learning of single-word items . In Stuart Webb, editor, The Routledge Handbook of Vocabulary Studies , 1st edition, Routledge handbooks in linguistics, pages 125--142. Routledge, Taylor & Francis Group, London, UK
-
[41]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. 2018. https://dl.acm.org/doi/10.5555/3327757.3327770 CatBoost : Unbiased boosting with categorical features . In Proceedings of the 32nd International Conference on Neural Information Processing Systems , NIPS '18, pages 6639--6649, Montr\'eal, Canada. Curran ...
-
[42]
Real Academia Espa\ nola . 2025. https://www.rae.es/corpes/ Corpus del Espa\ nol del Siglo XXI ( CORPES )
work page 2025
-
[43]
H kan Ringbom. 1987. The Role of the First Language in Foreign Language Learning , 1st edition. Number 34 in Multilingual matters. Multilingual Matters, Clevedon, UK
work page 1987
-
[44]
H kan Ringbom and Scott Jarvis. 2009. https://doi.org/10.1002/9781444315783.ch7 The importance of cross-linguistic similarity in foreign language learning . In Michael H. Long and Catherine J. Doughty, editors, The Handbook of Language Teaching , 1st edition. Wiley, Clevedon, UK
-
[45]
Susanne Rott. 1999. https://doi.org/10.1017/S0272263199004039 The effect of exposure frequency on intermediate language learners' incidental vocabulary acquisition and retention through reading . Studies in Second Language Acquisition, 21(4):589--619
-
[46]
Norbert Schmitt, Karen Dunn, Barry O'Sullivan, Laurence Anthony, and Benjamin Kremmel. 2021. https://doi.org/10.1002/tesj.622 Introducing knowledge-based vocabulary lists ( KVL ) . TESOL Journal, 12(4):e622
-
[47]
Norbert Schmitt and Diane Schmitt. 2020. https://doi.org/10.1017/9781108569057 Vocabulary in Language Teaching , 2nd edition. Cambridge University Press, Cambridge, UK
-
[48]
Lloyd S. Shapley. 1953. https://doi.org/10.1515/9781400881970-018 A Value for n- Person Games . In Harold William Kuhn and Albert William Tucker, editors, Contributions to the Theory of Games ( AM-28 ), Volume II , pages 307--318. Princeton University Press
-
[49]
Matthew Shardlow, Richard Evans, Gustavo Henrique Paetzold, and Marcos Zampieri. 2021. https://doi.org/10.18653/v1/2021.semeval-1.1 SemEval-2021 task 1: Lexical complexity prediction . In Proceedings of the 15th International Workshop on Semantic Evaluation ( SemEval-2021 ) , pages 1--16, Online. Association for Computational Linguistics
-
[50]
Matthew Shardlow et al . 2024. https://aclanthology.org/2024.bea-1.51/ The BEA 2024 shared task on the multilingual lexical simplification pipeline . In Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications ( BEA 2024) , pages 571--589, Mexico City, Mexico. Association for Computational Linguistics
work page 2024
-
[51]
Lucy Skidmore, Mariano Felice, and Karen Dunn. 2025. https://doi.org/10.18653/v1/2025.bea-1.12 Transformer architectures for vocabulary test item difficulty prediction . In Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications ( BEA 2025) , pages 160--174, Vienna, Austria. Association for Computational Linguistics
-
[52]
Ana \"i s Tack, Thomas Fran c ois, Anne-Laure Ligozat, and C \'e drick Fairon. 2016. https://aclanthology.org/2016.jeptalnrecital-long.17/ Mod\`eles adaptatifs pour pr\'edire automatiquement la comp\'etence lexicale d'un apprenant de fran cais langue \'etrang\`ere . In Actes de la conf\'erence conjointe JEP-TALN-RECITAL 2016 , Paris, France. AFCP - ATALA
work page 2016
-
[53]
Raquel Perez Urdaniz and Sophia Skoufaki. 2022. https://doi.org/10.1515/applirev-2018-0109 Spanish L1 EFL learners' recognition knowledge of English academic vocabulary: The role of cognateness, word frequency and length . Applied Linguistics Review, 13(4):661--703
-
[54]
Van Hell and Andrea Candia Mahn
Janet G. Van Hell and Andrea Candia Mahn. 1997. https://doi.org/10.1111/0023-8333.00018 Keyword mnemonics versus rote rehearsal: Learning concrete and abstract foreign words by experienced and inexperienced learners . Language Learning, 47(3):507--546
-
[55]
Walter J. B. Van Heuven, Pawel Mandera, Emmanuel Keuleers, and Marc Brysbaert. 2014. https://doi.org/10.1080/17470218.2013.850521 Subtlex- UK : A new and improved word frequency database for British English . Quarterly Journal of Experimental Psychology, 67(6):1176--1190
- [56]
-
[57]
Seid Muhie Yimam, Chris Biemann, Shervin Malmasi, Gustavo Paetzold, Lucia Specia, Sanja S tajner, Ana \"i s Tack, and Marcos Zampieri. 2018. https://doi.org/10.18653/v1/W18-0507 A report on the Complex Word Identification shared task 2018 . In Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications , pages 66-...
-
[58]
Tatu Ylonen. 2022. https://aclanthology.org/2022.lrec-1.140/ Wiktextract: Wiktionary as machine-readable structured data . In Proceedings of the Thirteenth Language Resources and Evaluation Conference , pages 1317--1325, Marseille, France. European Language Resources Association
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.