Recognition: 2 theorem links
· Lean TheoremPriorZero: Bridging Language Priors and World Models for Decision Making
Pith reviewed 2026-05-13 05:19 UTC · model grok-4.3
The pith
PriorZero integrates LLM priors into MCTS-based planning by injecting them only at the root node while using world model values for alternating LLM fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PriorZero is a framework that bridges language priors and world models through a decoupled rollout-training design. In rollout, a root-prior injection mechanism places LLM priors exclusively at the MCTS root to focus on semantically good actions while keeping the world model's full lookahead. In training, the world model is updated continuously, and its value estimates provide signals for alternating optimization to fine-tune the LLM stably.
What carries the argument
Root-prior injection in MCTS with decoupled training using world-model value estimates for LLM adaptation.
If this is right
- Improves exploration efficiency in Jericho text-based games and BabyAI gridworld tasks
- Achieves better asymptotic performance than baselines
- Enables stable fine-tuning of LLMs in long-horizon decision tasks
- Preserves world model deep planning while incorporating conceptual priors
Where Pith is reading between the lines
- The method may generalize to other model-based RL algorithms beyond MCTS if the root guidance principle holds
- It suggests that partial integration of priors can avoid the pitfalls of full end-to-end training in hybrid systems
- Future work could test if this leads to better transfer across environments sharing similar language concepts
Load-bearing premise
That injecting priors only at the MCTS root and alternating with world-model training will produce stable credit assignment without optimization conflicts over long horizons.
What would settle it
Running the method on a long-horizon task where it fails to outperform static LLM priors or end-to-end fine-tuning, or shows instability in value estimates.
Figures

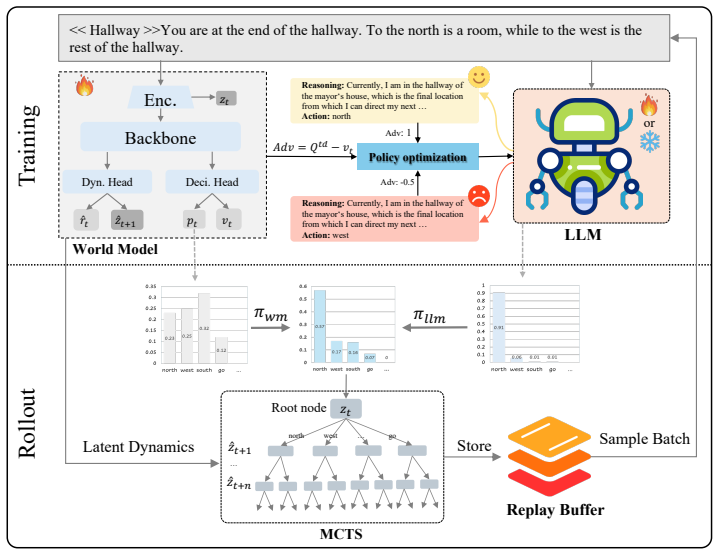



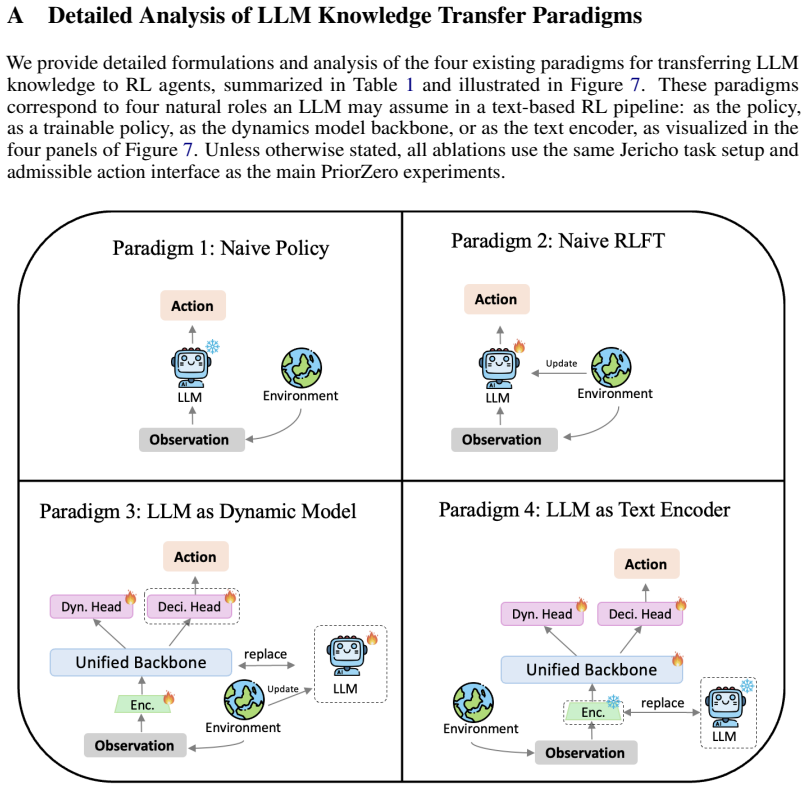





read the original abstract
Leveraging the rich world knowledge of Large Language Models (LLMs) to enhance Reinforcement Learning (RL) agents offers a promising path toward general intelligence. However, a fundamental prior-dynamics mismatch hinders existing approaches: static LLM knowledge cannot directly adapt to the complex transition dynamics of long-horizon tasks. Using LLM priors as fixed policies limits exploration diversity, as the prior is blind to environment-specific dynamics; while end-to-end fine-tuning suffers from optimization instability and credit assignment issues. To bridge this gap, we propose PriorZero, a unified framework that integrates LLM-derived conceptual priors into world-model-based planning through a decoupled rollout-training design. During rollout, a novel root-prior injection mechanism incorporates LLM priors exclusively at the root node of Monte Carlo Tree Search (MCTS), focusing search on semantically promising actions while preserving the world model's deep lookahead capability. During training, PriorZero decouples world-model learning from LLM adaptation: the world model is continuously refined on interaction data to jointly improve its dynamics, policy, and value predictions, its value estimates are then leveraged to provide fine-grained credit assignment signals for stable LLM fine-tuning via alternating optimization. Experiments across diverse benchmarks, including text-based adventure games in Jericho and instruction-following gridworld tasks in BabyAI, demonstrate that PriorZero consistently improves both exploration efficiency and asymptotic performance, establishing a promising framework for LLM-empowered decision-making. Our code is available at https://github.com/opendilab/LightZero.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PriorZero, a framework that integrates LLM-derived conceptual priors into world-model-based RL planning. It introduces a root-prior injection mechanism that applies LLM priors only at the MCTS root node during rollout to guide search toward semantically promising actions while retaining the world model's deep lookahead. Training is decoupled: the world model is updated continuously on interaction data to improve dynamics, policy, and value predictions, after which its value estimates supply credit-assignment signals for alternating LLM fine-tuning. Experiments on Jericho text-adventure games and BabyAI instruction-following tasks are reported to show gains in exploration efficiency and asymptotic performance.
Significance. If the empirical claims hold under rigorous validation, the decoupled root-injection plus alternating-optimization design would constitute a concrete advance over both fixed LLM priors and end-to-end fine-tuning for long-horizon tasks. The public code release at https://github.com/opendilab/LightZero is a clear strength that enables direct reproducibility and extension.
major comments (3)
- [§3.2] §3.2 (root-prior injection): the claim that root-only LLM prior injection preserves the world model's deep lookahead while focusing search is load-bearing for the method, yet the manuscript provides no analysis of how the injected prior interacts with tree depth or with inaccurate early-stage dynamics; without this, it is unclear whether the mechanism remains effective when the world model has not yet converged.
- [§4.2] §4.2 (alternating optimization): the stability of LLM fine-tuning is asserted to rest on value estimates from the jointly trained world model, but no ablation isolating the alternating schedule, no learning curves of value-prediction error versus LLM update magnitude, and no discussion of credit-assignment noise in the first many iterations are supplied; this directly undermines the central claim that the design avoids optimization conflicts in long-horizon tasks.
- [Experiments] Experiments section: the abstract and results state that PriorZero 'consistently improves' exploration and asymptotic performance on Jericho and BabyAI, yet no quantitative deltas, error bars, statistical tests, or baseline comparisons with ablated variants are referenced; without these, the magnitude and reliability of the reported gains cannot be assessed.
minor comments (2)
- [§3.2] Notation for the root-prior injection (e.g., how the LLM distribution is combined with the world-model policy at the root) is introduced without an explicit equation; adding a short formal definition would improve clarity.
- [Figures] Figure captions and axis labels in the experimental plots should explicitly state the number of random seeds and whether shaded regions represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify key areas where further analysis and experimental rigor would strengthen the manuscript. We will revise the paper to address each point, adding the requested analysis, ablations, and quantitative details while preserving the core contributions of the decoupled root-injection and alternating-optimization design.
read point-by-point responses
-
Referee: [§3.2] §3.2 (root-prior injection): the claim that root-only LLM prior injection preserves the world model's deep lookahead while focusing search is load-bearing for the method, yet the manuscript provides no analysis of how the injected prior interacts with tree depth or with inaccurate early-stage dynamics; without this, it is unclear whether the mechanism remains effective when the world model has not yet converged.
Authors: We agree that explicit analysis of the root-prior injection's interaction with tree depth and early-stage dynamics is needed. In the revised manuscript we will expand §3.2 with a dedicated paragraph explaining that the LLM prior is applied exclusively to root-node action probabilities; all subsequent expansions and evaluations remain driven solely by the world model, thereby preserving its deep lookahead. We will also add empirical results from Jericho at multiple training epochs, showing that root-prior guidance improves early exploration efficiency even under higher dynamics error, without reducing average search depth or introducing instability. Comparative plots of tree depth, action entropy, and success rate with/without the prior at early versus late stages will be included. revision: yes
-
Referee: [§4.2] §4.2 (alternating optimization): the stability of LLM fine-tuning is asserted to rest on value estimates from the jointly trained world model, but no ablation isolating the alternating schedule, no learning curves of value-prediction error versus LLM update magnitude, and no discussion of credit-assignment noise in the first many iterations are supplied; this directly undermines the central claim that the design avoids optimization conflicts in long-horizon tasks.
Authors: We acknowledge that the current version lacks these supporting elements. The revised §4.2 will include (i) an ablation comparing the alternating schedule against joint world-model/LLM updates, (ii) learning curves plotting world-model value-prediction MSE against LLM update magnitude across iterations, and (iii) a discussion of how progressively refined value estimates reduce credit-assignment noise in early training. These additions will empirically demonstrate lower update variance and fewer optimization conflicts relative to end-to-end fine-tuning on long-horizon tasks. revision: yes
-
Referee: Experiments section: the abstract and results state that PriorZero 'consistently improves' exploration and asymptotic performance on Jericho and BabyAI, yet no quantitative deltas, error bars, statistical tests, or baseline comparisons with ablated variants are referenced; without these, the magnitude and reliability of the reported gains cannot be assessed.
Authors: We thank the referee for highlighting the need for clearer quantitative reporting. Although performance tables appear in the full manuscript, we will revise the Experiments section to explicitly report percentage deltas in success rate and steps-to-goal, error bars from five random seeds, p-values from paired t-tests, and direct comparisons against ablated variants (no root-prior injection; no alternating training). These details will be added to the main tables and figures so that the magnitude and statistical reliability of the gains can be properly evaluated. revision: yes
Circularity Check
No circularity: empirical framework with external benchmarks and no self-referential equations
full rationale
The paper introduces PriorZero as a decoupled rollout-training design using root-only LLM prior injection in MCTS and alternating optimization between world-model training and LLM fine-tuning. All load-bearing claims rest on experimental results from independent benchmarks (Jericho, BabyAI) rather than any derivation that reduces a prediction to a fitted parameter or prior self-citation by construction. No equations appear in the abstract or described framework that equate outputs to inputs via definition or renaming; the alternating schedule and value-based credit assignment are presented as design choices justified by empirical outcomes, not as tautological consequences of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM priors supply semantically useful action guidance even when the environment dynamics differ from the model's training distribution
invented entities (1)
-
root-prior injection mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearroot-prior injection mechanism incorporates LLM priors exclusively at the root node of Monte Carlo Tree Search (MCTS)... alternating optimization
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearn-step bootstrapped TD advantage... world-model value estimates
Reference graph
Works this paper leans on
-
[1]
World models , author=. arXiv preprint arXiv:1803.10122 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
International conference on machine learning , pages=
Curl: Contrastive unsupervised representations for reinforcement learning , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[3]
International Conference on Machine Learning , pages=
Reinforcement learning with action-free pre-training from videos , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[4]
Advances in Neural Information Processing Systems , volume=
Pre-trained image encoder for generalizable visual reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2210.00030 , year=
Vip: Towards universal visual reward and representation via value-implicit pre-training , author=. arXiv preprint arXiv:2210.00030 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Pre-training contextualized world models with in-the-wild videos for reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Starling: Self-supervised training of text-based reinforcement learning agent with large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
work page 2024
-
[8]
Advances in Neural Information Processing Systems , volume=
Pre-trained language models for interactive decision-making , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Do as i can, not as i say: Grounding language in robotic affordances , author=. arXiv preprint arXiv:2204.01691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2401.07382 , year=
Beyond sparse rewards: Enhancing reinforcement learning with language model critique in text generation , author=. arXiv preprint arXiv:2401.07382 , year=
-
[11]
arXiv preprint arXiv:2402.02392 , year=
Dellma: Decision making under uncertainty with large language models , author=. arXiv preprint arXiv:2402.02392 , year=
-
[12]
arXiv preprint arXiv:2504.16855 , year=
Monte carlo planning with large language model for text-based game agents , author=. arXiv preprint arXiv:2504.16855 , year=
-
[13]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[14]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[15]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[16]
arXiv preprint arXiv:2502.02384 , year=
Stair: Improving safety alignment with introspective reasoning , author=. arXiv preprint arXiv:2502.02384 , year=
-
[17]
arXiv , author =:2501.04519 , primaryclass =
RStar-math: Small LLMs can master math reasoning with self-evolved deep thinking , author=. arXiv preprint arXiv:2501.04519 , year=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Docr1: Evidence page-guided grpo for multi-page document understanding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities , author=. 2025 , eprint=
work page 2025
-
[20]
Rlaif: Scaling reinforcement learning from human feedback with ai feedback , author=
-
[21]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
work page 2022
-
[23]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International Conference on Learning Representations , year=
BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning , author=. International Conference on Learning Representations , year=
-
[25]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
AgentGym: Evolving Large Language Model-based Agents across Diverse Environments , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
-
[26]
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning , author=. arXiv preprint arXiv:2509.08755 , year=
-
[27]
Proceedings of the 39th International Conference on Machine Learning , pages =
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , volume =
work page 2022
-
[28]
Proceedings of The 6th Conference on Robot Learning , pages =
Inner Monologue: Embodied Reasoning through Planning with Language Models , author =. Proceedings of The 6th Conference on Robot Learning , pages =. 2023 , volume =
work page 2023
-
[29]
Proceedings of the 40th International Conference on Machine Learning , pages =
Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , volume =
work page 2023
-
[30]
Proceedings of the 41st International Conference on Machine Learning , pages =
Learning to Model the World With Language , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
work page 2024
-
[31]
Proceedings of the 39th International Conference on Machine Learning , pages =
History Compression via Language Models in Reinforcement Learning , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , volume =
work page 2022
-
[32]
Hansen, Nick and Su, Hao and Wang, Xiaolong , booktitle =
-
[33]
Proceedings of the 41st International Conference on Machine Learning , year =
EfficientZero V2: Mastering Discrete and Continuous Control with Limited Data , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[34]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Interactive Fiction Games: A Colossal Adventure , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[35]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
Efficient Memory Management for Large Language Model Serving with PagedAttention , author =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =
-
[36]
International Conference on Learning Representations , year =
Large Language Models as Generalizable Policies for Embodied Tasks , author =. International Conference on Learning Representations , year =
-
[37]
Reinforcement World Model Learning for
Reinforcement World Model Learning for LLM-based Agents , author =. arXiv preprint arXiv:2602.05842 , year =
-
[38]
Advances in Neural Information Processing Systems , year =
Learning to Modulate Pre-trained Models in RL , author =. Advances in Neural Information Processing Systems , year =
-
[39]
arXiv preprint arXiv:2404.16364 , year=
Rezero: Boosting mcts-based algorithms by backward-view and entire-buffer reanalyze , author=. arXiv preprint arXiv:2404.16364 , year=
-
[40]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in neural information processing systems , volume=
Fine-tuning large vision-language models as decision-making agents via reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[42]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Reasoning with language model is planning with world model , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[43]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Making large language models into world models with precondition and effect knowledge , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
VLMs-Guided Representation Distillation for Efficient Vision-Based Reinforcement Learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
Llm- empowered state representation for reinforcement learning,
Llm-empowered state representation for reinforcement learning , author=. arXiv preprint arXiv:2407.13237 , year=
-
[46]
13th International Conference on Learning Representations Iclr 2025 , pages=
Efficient reinforcement learning with large language model priors , author=. 13th International Conference on Learning Representations Iclr 2025 , pages=. 2025 , organization=
work page 2025
-
[47]
Advances in Neural Information Processing Systems , volume=
LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
UniZero: Generalized and Efficient Planning with Scalable Latent World Models , author=
-
[49]
arXiv preprint arXiv:2509.07945 , year=
One Model for All Tasks: Leveraging Efficient World Models in Multi-Task Planning , author=. arXiv preprint arXiv:2509.07945 , year=
-
[50]
LightRFT: Light, Efficient, Omni-modal & Reward-model Driven Reinforcement Fine-Tuning Framework , author=
-
[51]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework , author=. arXiv preprint arXiv:2405.11143 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.