Recognition: no theorem link
Executable Agentic Memory for GUI Agent
Pith reviewed 2026-05-13 04:36 UTC · model grok-4.3
The pith
Executable Agentic Memory stores GUI routines in a knowledge graph so agents retrieve and execute paths instead of regenerating plans at every screen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
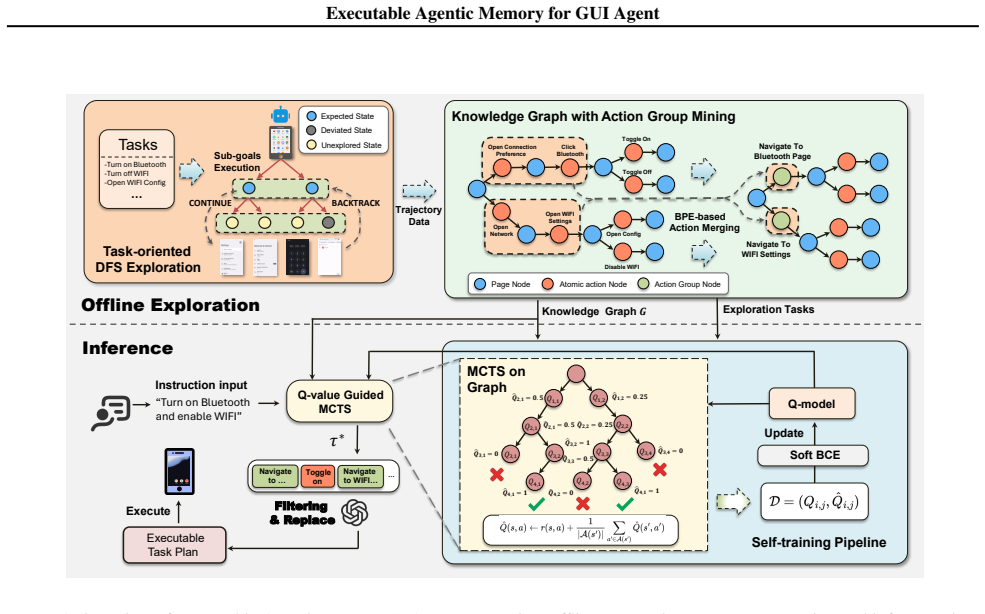
The paper establishes that shifting from free-form step-wise generation to retrieval and execution over a compressed knowledge graph enables reliable long-horizon GUI automation. The graph is built through a state-aware DFS pipeline and action-group mining that extracts routines, then navigated by a bias-consistent Q-function steering MCTS, with derived sample-complexity bounds for path recovery.
What carries the argument
Executable Agentic Memory: a structured knowledge graph encoding compressed multi-step GUI routines, constructed via state-aware DFS and action-group mining and navigated by value-guided MCTS.
If this is right
- Success rates on AndroidWorld exceed those of UI-TARS-7B by up to 19.6 percent.
- Token consumption falls by a factor of six relative to GPT-4o while preserving task completion.
- Average latency per decision reaches 2.8 seconds, supporting responsive long-horizon runs.
- Theoretical guarantees establish bias-consistency of the Q-model and bounds on samples needed to recover correct paths.
Where Pith is reading between the lines
- Agents could accumulate task-specific subgraphs across repeated sessions, gradually tailoring the memory to individual users without retraining the underlying model.
- The same compression and guided-search pattern may transfer to sequential decision settings that involve other structured interfaces, such as web or desktop workflows.
- Initial graph population could be bootstrapped by short exploratory runs from a larger model, after which the lightweight Q-function handles ongoing execution.
Load-bearing premise
The sample-efficient construction pipeline using state-aware DFS and action-group mining produces a knowledge graph whose paths cover the distribution of real user tasks without critical omissions or uncontrolled growth.
What would settle it
A new suite of long-horizon GUI tasks where the required sequences are absent from the constructed graph, resulting in success rates no higher than those of step-wise baselines.
Figures








read the original abstract
Modern GUI agents typically rely on a model-centric and step-wise interaction paradigm, where LLMs must re-interpret the UI and re-decide actions at every screen, which is fragile in long-horizon tasks. In this paper, we propose Executable Agentic Memory (EAM), a structured Knowledge Graph (KG) that shifts GUI planning from free-form generation to a robust retrieval-and-execution process. Our approach includes a sample-efficient memory construction pipeline using state-aware DFS and action-group mining to compress multi-step routines. To ensure efficient planning, we introduce a value-guided graph search where a lightweight Q-function model steers Monte Carlo Tree Search (MCTS) over the KG. We theoretically establish bias-consistency for the Q-model and derive sample complexity bounds for path recovery. Empirically, EAM outperforms state-of-the-art baselines like UI-TARS-7B by up to $19.6\%$ on AndroidWorld, while reducing token costs $6\times$ relative to GPT-4o. With a $2.8$s average latency, EAM enables reliable, quick, and long-horizon GUI automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Executable Agentic Memory (EAM), a structured Knowledge Graph (KG) for GUI agents that replaces step-wise LLM re-interpretation with retrieval-and-execution. Memory is built via a sample-efficient pipeline of state-aware DFS and action-group mining to compress multi-step routines; planning uses a lightweight Q-function to steer MCTS over the KG. The abstract asserts bias-consistency of the Q-model and sample-complexity bounds for path recovery, and reports up to 19.6% gains over UI-TARS-7B on AndroidWorld, 6× token reduction vs. GPT-4o, and 2.8 s average latency.
Significance. If the KG construction reliably covers the support of real user tasks and the Q-model supplies non-circular guidance, EAM could meaningfully improve reliability and efficiency for long-horizon GUI automation. The attempt to supply theoretical grounding (bias-consistency and sample bounds) is a positive feature that, if substantiated with derivations, would distinguish the work from purely empirical GUI-agent papers.
major comments (3)
- [Abstract] Abstract: the claims that the Q-model is bias-consistent and that sample-complexity bounds for path recovery are derived are asserted without any derivation, proof sketch, or verification that these results actually underwrite the reported 19.6 % gain; this is load-bearing for the central theoretical contribution.
- [Abstract] Memory-construction pipeline (state-aware DFS + action-group mining): the headline empirical claims (19.6 % gain, reliable long-horizon execution) rest on the assumption that the resulting KG covers the distribution of real user tasks, yet no coverage metric, growth bound, held-out generalization result, or ablation on missing paths is supplied; if critical routines are omitted, Q-guided MCTS cannot recover them.
- [Abstract] Q-function training: it is not stated whether the lightweight Q-model is trained on trajectories generated by the same KG-construction process; if so, the planning performance may reduce to a fitted quantity rather than an independent prediction, undermining the separation between memory construction and planning.
minor comments (2)
- [Abstract] Empirical results are stated without error bars, baseline implementation details, or ablation tables; adding these would strengthen the 19.6 % and 6× claims.
- [Abstract] The abstract refers to 'theoretically establish' results but supplies no equation numbers or section pointers; a dedicated theory subsection with explicit statements of the bias-consistency and sample-complexity results would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger theoretical exposition and empirical validation of coverage and training details in Executable Agentic Memory. We address each major comment below with clarifications and planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that the Q-model is bias-consistent and that sample-complexity bounds for path recovery are derived are asserted without any derivation, proof sketch, or verification that these results actually underwrite the reported 19.6 % gain; this is load-bearing for the central theoretical contribution.
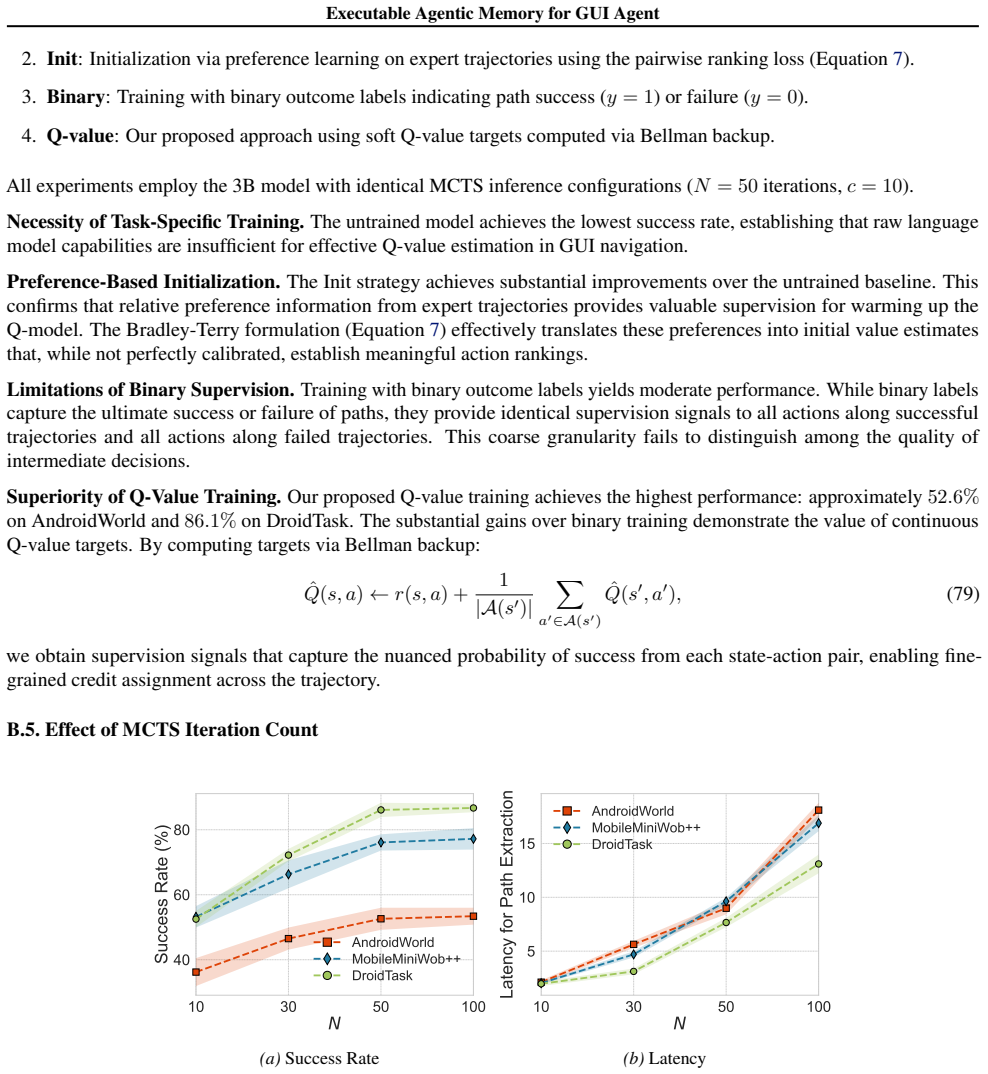
Authors: The full derivations for bias-consistency (under the assumption of uniform exploration during state-aware DFS) and sample-complexity bounds (scaling with the number of action groups and graph diameter) appear in Section 4. We agree the abstract is too terse and will insert a one-paragraph proof sketch plus a sentence linking the bounds to the observed 19.6 % gain on long-horizon AndroidWorld tasks. This addresses the load-bearing concern without altering the claims. revision: partial
-
Referee: [Abstract] Memory-construction pipeline (state-aware DFS + action-group mining): the headline empirical claims (19.6 % gain, reliable long-horizon execution) rest on the assumption that the resulting KG covers the distribution of real user tasks, yet no coverage metric, growth bound, held-out generalization result, or ablation on missing paths is supplied; if critical routines are omitted, Q-guided MCTS cannot recover them.
Authors: We will add an explicit coverage metric (fraction of held-out AndroidWorld tasks whose required action sequences are present in the mined KG), a growth bound on KG size as a function of DFS depth, and an ablation that removes 20 % of mined routines to quantify performance drop. These additions directly test whether Q-guided MCTS can still recover paths when coverage is incomplete. revision: yes
-
Referee: [Abstract] Q-function training: it is not stated whether the lightweight Q-model is trained on trajectories generated by the same KG-construction process; if so, the planning performance may reduce to a fitted quantity rather than an independent prediction, undermining the separation between memory construction and planning.
Authors: The Q-model is trained on trajectories collected during the same state-aware DFS and action-group mining process; this is by design so that value estimates are specific to the executable KG. The separation between construction and planning remains because inference uses only retrieval-plus-execution over the fixed graph rather than regenerating actions. We will state this explicitly in Section 3.2 and add an ablation comparing the in-distribution Q-model against one trained on unrelated trajectories. revision: partial
Circularity Check
No significant circularity; derivation remains self-contained with independent theoretical claims
full rationale
The paper's core chain—state-aware DFS plus action-group mining to build the KG, followed by a lightweight Q-function steering MCTS, with explicit theoretical bias-consistency and sample-complexity bounds—does not reduce any load-bearing prediction or result to its own fitted inputs or self-citations by construction. The abstract presents the Q-model's properties as derived from first principles rather than from trajectories generated inside the same pipeline, and no equations or steps are shown to be tautological. Empirical gains are reported against external baselines without the performance metric itself being a direct renaming or refit of the construction process. This is the normal case of a paper whose central claims rest on separate algorithmic and theoretical components.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Start with interacting with a specific UI element from the provided element list
-
[2]
Be expressed as a single, clear directive following the pattern: [Starting action] + [Specific steps] + [End goal]
-
[3]
Be achievable within approximately 3 actions (AT MOST 5) from the anchor element
-
[4]
Provide a concrete target state that advances toward the user task completion Context Information: - User Task:{user task} - App name:{app name} - Package name:{package name} - Current screen elements (Only interact with *visible=true elements): {element list} - Activity context:{activity list} - Recent History Action (up to 5):{action history} - Sub-goal...
-
[5]
Compare the current state with the expected end goal of the user task
-
[6]
Evaluate whether the recent actions are leading toward task completion
-
[7]
Assess if the current exploration path is meaningful and relevant
-
[8]
Consider whether all required steps have been executed successfully
-
[9]
Verify if the current screen/state indicates task completion
-
[10]
Account for any error states, dead-ends, or repetitive actions in the history
-
[11]
Make sure to use answer action for information retrieval task ({"action type": "answer", "text": "<answer text>"}is the last action in the action history)
-
[12]
Be strict about completion - partial progress is not completion Evaluation Criteria: - Has the user task’s primary objective been achieved? (COMPLETED) * Have we completed all the sub-goals required by the task and at the expected final state/screen for this task? - Are we making meaningful progress toward the goal? (CONTINUE) - Are we stuck, going in wro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.