Recognition: no theorem link
VIP: Visual-guided Prompt Evolution for Efficient Dense Vision-Language Inference
Pith reviewed 2026-05-14 21:39 UTC · model grok-4.3
The pith
VIP evolves text prompts with visual guidance to correct semantic ambiguity in dino.txt and deliver more accurate dense open-vocabulary segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VIP integrates alias expansion with a visual-guided distillation mechanism to mine and aggregate semantic cues from dino.txt interactions, rectifying the semantic expressiveness of text queries and producing high-fidelity dense predictions that surpass leading methods by 1.4 to 8.4 percent average mIoU while adding only marginal time and memory overhead.
What carries the argument
Visual-guided Prompt Evolution (VIP), the mechanism that performs alias expansion followed by visual-guided distillation and saliency-aware aggregation to refine text queries inside dino.txt.
If this is right
- Outperforms current top methods by 1.4 to 8.4 percent average mIoU on standard benchmarks.
- Maintains strong generalization across diverse and challenging visual domains.
- Adds only marginal extra inference time and memory compared with the base dino.txt pipeline.
- Enables training-free dense prediction that avoids the spatial bias typical of CLIP-based approaches.
Where Pith is reading between the lines
- The same prompt-evolution steps could be tested on other spatially-aware vision-language backbones to measure transfer.
- Efficiency gains may support deployment in resource-constrained settings such as mobile or embedded vision systems.
- Saliency-aware aggregation might be further tuned to handle long-tail categories without additional supervision.
Load-bearing premise
Alias expansion together with visual-guided distillation can reliably resolve semantic ambiguity in dino.txt cross-modal interactions without creating new biases or domain-specific failures.
What would settle it
A controlled test on a dataset rich in ambiguous object categories where VIP produces lower mIoU than the unmodified dino.txt baseline or visibly introduces new mislabeling patterns.
Figures












read the original abstract
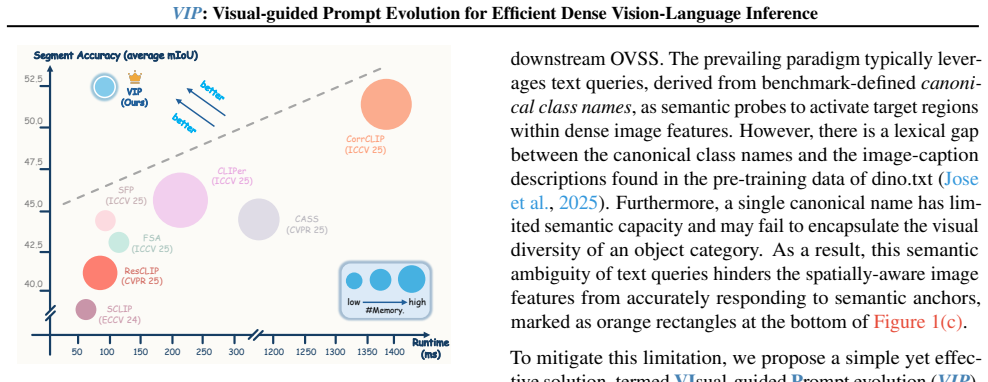
Pursuing training-free open-vocabulary semantic segmentation in an efficient and generalizable manner remains challenging due to the deep-seated spatial bias in CLIP. To overcome the limitations of existing solutions, this work moves beyond the CLIP-based paradigm and harnesses the recent spatially-aware dino$.$txt framework to facilitate more efficient and high-quality dense prediction. While dino$.$txt exhibits robust spatial awareness, we find that the semantic ambiguity of text queries gives rise to severe mismatch within its dense cross-modal interactions. To address this, we introduce Visual-guided Prompt evolution (VIP) to rectify the semantic expressiveness of text queries in dino$.$txt, unleashing its potential for fine-grained object perception. Towards this end, VIP integrates alias expansion with a visual-guided distillation mechanism to mine valuable semantic cues, which are robustly aggregated in a saliency-aware manner to yield a high-fidelity prediction. Extensive evaluations demonstrate that VIP: 1. surpasses the top-leading methods by 1.4%-8.4% average mIoU, 2. generalizes well to diverse challenging domains, and 3. requires marginal inference time and memory overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Visual-guided Prompt Evolution (VIP) as an add-on to the dino.txt framework for training-free open-vocabulary semantic segmentation. It addresses semantic ambiguity in text queries via alias expansion combined with visual-guided distillation, followed by saliency-aware aggregation of mined cues, claiming 1.4-8.4% average mIoU gains over leading methods, strong generalization to challenging domains, and negligible inference overhead.
Significance. If the performance claims and generalization hold after proper validation, VIP would offer a practical route to leverage spatially-aware vision-language models beyond CLIP for dense prediction, with efficiency advantages that could influence downstream applications in segmentation and related tasks.
major comments (2)
- [Experiments] Experiments section: the abstract and reported mIoU gains (1.4%-8.4%) are presented without any description of experimental protocol, baseline re-implementations, statistical tests, or ablation results that isolate alias expansion from visual-guided distillation; this renders the central performance claim unevaluable from the supplied text.
- [Method] Method description of visual-guided distillation and saliency-aware aggregation: no control experiment or parameter-free derivation is provided to separate the contribution of image-derived saliency cues from baseline dino.txt behavior, leaving open the possibility that reported gains arise from dataset-specific visual correlations rather than resolution of text ambiguity.
minor comments (1)
- [Abstract] Abstract: notation 'dino$.$txt' appears to be a LaTeX artifact and should be rendered consistently as dino.txt throughout.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that additional details and controls are needed to make the claims fully evaluable and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and reported mIoU gains (1.4%-8.4%) are presented without any description of experimental protocol, baseline re-implementations, statistical tests, or ablation results that isolate alias expansion from visual-guided distillation; this renders the central performance claim unevaluable from the supplied text.
Authors: We acknowledge the need for greater transparency. In the revised version we will expand the Experiments section with a complete description of the evaluation protocol (including datasets, metrics, and hardware), explicit details on baseline re-implementations (code links and hyper-parameter settings), statistical significance tests across multiple runs, and dedicated ablations that separately quantify the contribution of alias expansion versus visual-guided distillation. These additions will allow readers to fully reproduce and assess the reported 1.4–8.4 % mIoU gains. revision: yes
-
Referee: [Method] Method description of visual-guided distillation and saliency-aware aggregation: no control experiment or parameter-free derivation is provided to separate the contribution of image-derived saliency cues from baseline dino.txt behavior, leaving open the possibility that reported gains arise from dataset-specific visual correlations rather than resolution of text ambiguity.
Authors: We agree that isolating the effect of the saliency cues is important. We will add control experiments that disable the visual-guided distillation and saliency-aware aggregation modules while keeping all other components fixed, together with a parameter-free analysis showing how the mined cues reduce cross-modal mismatch independently of dataset-specific correlations. These results will be presented in a new ablation subsection to demonstrate that the gains stem from improved handling of text ambiguity rather than incidental visual statistics. revision: yes
Circularity Check
No significant circularity: additive method on external dino.txt framework
full rationale
The paper presents VIP as an additive procedure (alias expansion + visual-guided distillation + saliency-aware aggregation) applied to the external dino.txt framework to address semantic ambiguity in text queries. No equations, fitted parameters, or self-referential derivations are described in the provided text that reduce predictions to inputs by construction. The central claims rest on empirical evaluations rather than a closed derivation chain. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are evident. This is the common case of an engineering contribution whose validity is tested externally rather than derived internally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pp. 1877–1901,
work page 1901
-
[2]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Dong, H., Sheng, L., Liang, J., He, R., Chatzi, E., and Fink, O. Adapting vision-language models without labels: A comprehensive survey.arXiv preprint arXiv:2508.05547,
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Sim´eoni, O., V o, H. V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M. F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y ., Mustafa, B., et al. Siglip 2: Multilingual vision-language encoders with improved semantic under- standing, localization, and dense features.arXiv preprint arXiv:2502.14786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
In this work, we employ the latest version to ensure optimal performance
as its visual backbone, and was then upgraded in tandem with the release of DINO v3 (Sim´eoni et al., 2025). In this work, we employ the latest version to ensure optimal performance. To ensure a fair comparison, our data processing pipeline strictly follows to the protocols established in previous studies (Wang et al., 2024; Zhu et al., 2024; Chi et al., ...
work page 2025
-
[9]
However, in practice, the alias distillation process already computes the similarity maps between the dense image features and all text queries, which can be cached. This enables the aggregation of logits maps and the final segmentation results can be obtained directly, bypassing the need for a repeated model forward pass, thereby significantly reducing i...
work page 2023
-
[10]
and SC Score(cf.Eq. 6), and utilize the mean scores of the 80 CLIP templates as a reference. Mirroring our filtering strategy for class aliases, we retain only those templates that surpass the reference value in VG Score while remaining lower than the reference in SC Score. In addition, we maintain two foundational templates across all scenarios,i.e., “a ...
work page 2024
-
[11]
We also adopted this practice in our early experimental validation
72.8 46.5 55.1 28.8 50.8 GPT-5 73.2 47.3 55.7 29.1 51.3 Semantic expansion by category descriptors.Leveraging LLMs to generate visual context descriptors for each category has been extensively studied in prior works on zero-shot image classification via VLMs (Menon & V ondrick, 2023; Pratt et al., 2023; Roth et al., 2023). We also adopted this practice in...
work page 2023
-
[12]
One layer modulation46.4 61.5 60.8 Two layers modulation54.7 73.8 69.6 ∆ +8.3 +12.3 +8.8 refinement to the last-layer image features of both dino.txt and CLIP, and further extend this operation to the penultimate layer. Build upon this, we conduct a quantitative analysis of the induced changes, which assesses their variations in intra-class image-feature ...
work page 2025
-
[13]
onObject,ADE,Context60, andVOC21benchmarks, respectively. As shown in Figure 10-13, through the proposed text evolution, ourVIPsuccessfully corrects misclassifications and avoids missing objects found in existing counterparts. C. Limitations and Future Work C.1. Limitations Although VIP can substantially improve the quality of text queries in dino.txt, th...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.