Recognition: no theorem link
ProfiliTable: Profiling-Driven Tabular Data Processing via Agentic Workflows
Pith reviewed 2026-05-13 05:54 UTC · model grok-4.3
The pith
Dynamic profiling in a multi-agent system turns ambiguous table instructions into accurate, compliant transformations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProfiliTable constructs a unified execution context by having a Profiler perform ReAct-style exploration to build semantic understanding of the tables, a Generator retrieve curated operators to produce task-aware code, and an Evaluator-Summarizer loop feed execution scores and diagnostic insights back for closed-loop refinement; experiments across 18 task types show this yields consistent gains over strong baselines, especially on multi-step scenarios.
What carries the argument
The ProfiliTable multi-agent framework that centers on dynamic profiling to build and refine a unified execution context through exploration, operator synthesis, and feedback-driven iteration.
If this is right
- Complex multi-step table workflows become feasible without extensive manual debugging of generated code.
- Syntactically valid but semantically wrong transformations decrease because diagnostic feedback is injected at each iteration.
- Governance and compliance constraints can be checked and enforced inside the same refinement loop rather than after the fact.
Where Pith is reading between the lines
- If profiling proves reliable, similar agent structures could be tested on other structured data formats such as JSON trees or graph data where intent is equally ambiguous.
- The separation of exploration from code synthesis suggests a testable design pattern for agentic systems in domains that require both data inspection and rule application.
- Over time the accumulated profiles might serve as reusable context that lowers the cost of repeated similar tasks within an organization.
Load-bearing premise
The interactive profiling plus evaluator-summarizer feedback loop will convert ambiguous user requests into code that is both semantically correct and governance-compliant without introducing fresh errors or needing human review.
What would settle it
Run the system on a fresh collection of tables with deliberately vague or underspecified instructions and measure whether semantic accuracy and compliance rates remain above the strongest baseline or drop sharply.
Figures


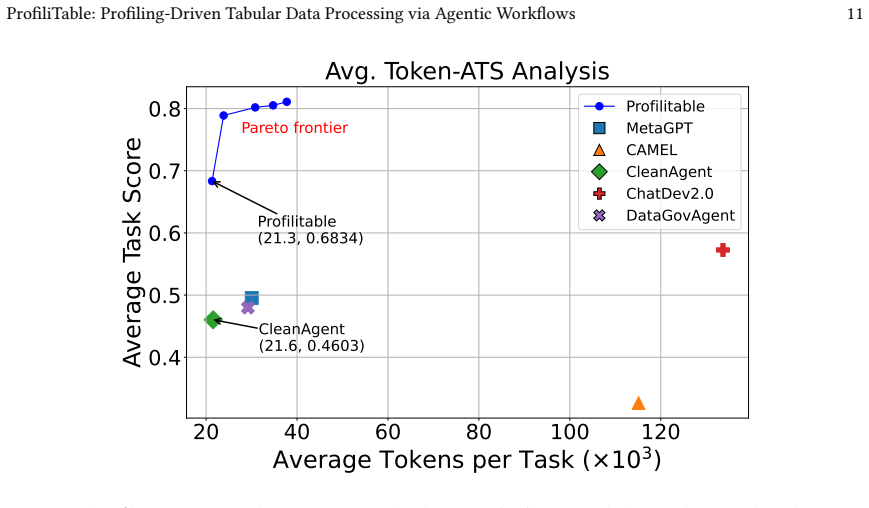


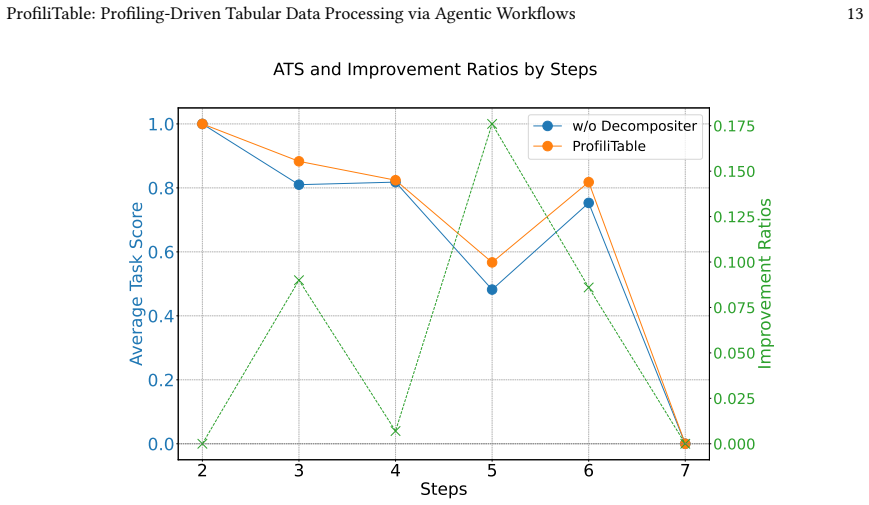





read the original abstract
Table processing-including cleaning, transformation, augmentation, and matching-is a foundational yet error-prone stage in real-world data pipelines. While recent LLM-based approaches show promise for automating such tasks, they often struggle in practice due to ambiguous instructions, complex task structures, and the lack of structured feedback, resulting in syntactically correct but semantically flawed code. To address these challenges, we propose ProfiliTable, an autonomous multi-agent framework centered on dynamic profiling, which constructs and iteratively refines a unified execution context through interactive exploration, knowledge-augmented synthesis, and feedback-driven refinement. ProfiliTable integrates (i) a Profiler that performs ReAct-style data exploration to build semantic understanding, (ii) a Generator that retrieves curated operators to synthesize task-aware code, and (iii) an Evaluator-Summarizer loop that injects execution scores and diagnostic insights to enable closed-loop refinement. Extensive experiments on a diverse benchmark covering 18 tabular task types demonstrate that ProfiliTable consistently outperforms strong baselines, particularly in complex multi-step scenarios. These results highlight the critical role of dynamic profiling in reliably translating ambiguous user intents into robust and governance-compliant table transformations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProfiliTable, an autonomous multi-agent framework for tabular data processing tasks such as cleaning, transformation, augmentation, and matching. It centers on dynamic profiling via a ReAct-style Profiler for semantic understanding, a Generator that retrieves operators to synthesize code, and an Evaluator-Summarizer loop for execution-based feedback and refinement. The central claim is that this architecture reliably handles ambiguous user intents and produces governance-compliant outputs, with extensive experiments on a benchmark of 18 tabular task types showing consistent outperformance over strong baselines, especially in complex multi-step scenarios.
Significance. If the empirical results hold under rigorous controls, the work could meaningfully advance LLM-driven data pipelines by demonstrating how interactive profiling and closed-loop feedback reduce semantic errors compared to direct generation approaches. The integration of knowledge-augmented synthesis and diagnostic insights represents a concrete architectural contribution worth testing in production settings.
major comments (3)
- [§4 and abstract] §4 (Experiments) and abstract: The headline claim that ProfiliTable 'consistently outperforms strong baselines' on 18 task types is load-bearing for the paper's contribution, yet the manuscript provides no quantitative metrics (e.g., success rates, exact-match vs. semantic-equivalence scores), baseline descriptions, error analysis, or details on how semantic correctness and governance compliance were measured. This absence prevents assessment of whether gains are attributable to the profiling + Evaluator-Summarizer loop rather than prompt differences or evaluation leniency.
- [§4.1] §4.1 (Benchmark construction): No information is given on how the 18 task types were sampled or instantiated with realistic ambiguity, whether all methods used identical LLM backbones and temperature settings, or whether results include multiple independent runs with statistical testing. These controls are required to support the cross-task outperformance claim.
- [§3.3] §3.3 (Evaluator-Summarizer loop): The assumption that the feedback loop reliably translates ambiguous intents into correct transformations without introducing new errors is central but unsupported by ablation studies isolating the loop's contribution or by analysis of failure modes where the loop fails to converge.
minor comments (2)
- [§3] Notation for the unified execution context and operator retrieval mechanism could be formalized with a diagram or pseudocode to improve clarity for readers implementing the system.
- [abstract] The abstract and introduction would benefit from a brief statement of the precise success metric used in the benchmark (e.g., execution success only, or full semantic + governance compliance).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional rigor and transparency are needed in the experimental reporting and methodological justification. We address each point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4 and abstract] §4 (Experiments) and abstract: The headline claim that ProfiliTable 'consistently outperforms strong baselines' on 18 task types is load-bearing for the paper's contribution, yet the manuscript provides no quantitative metrics (e.g., success rates, exact-match vs. semantic-equivalence scores), baseline descriptions, error analysis, or details on how semantic correctness and governance compliance were measured. This absence prevents assessment of whether gains are attributable to the profiling + Evaluator-Summarizer loop rather than prompt differences or evaluation leniency.
Authors: We agree that the current manuscript does not present the quantitative metrics, baseline details, error analysis, or evaluation methodology with sufficient explicitness in §4 or the abstract. In the revised version we will expand §4 to report success rates, exact-match and semantic-equivalence scores, full baseline descriptions, a dedicated error analysis, and precise definitions of how semantic correctness and governance compliance were assessed. The abstract will be updated to summarize these metrics. These additions will make clear that observed gains derive from the profiling and Evaluator-Summarizer components rather than prompt or evaluation artifacts. revision: yes
-
Referee: [§4.1] §4.1 (Benchmark construction): No information is given on how the 18 task types were sampled or instantiated with realistic ambiguity, whether all methods used identical LLM backbones and temperature settings, or whether results include multiple independent runs with statistical testing. These controls are required to support the cross-task outperformance claim.
Authors: We will revise §4.1 to document the sampling procedure and instantiation of the 18 task types, including how realistic ambiguity was introduced. The revised text will explicitly state that all compared methods used identical LLM backbones and temperature settings, and will report results aggregated over multiple independent runs together with statistical testing (means, standard deviations, and significance measures). These additions will provide the necessary controls for the cross-task outperformance claim. revision: yes
-
Referee: [§3.3] §3.3 (Evaluator-Summarizer loop): The assumption that the feedback loop reliably translates ambiguous intents into correct transformations without introducing new errors is central but unsupported by ablation studies isolating the loop's contribution or by analysis of failure modes where the loop fails to converge.
Authors: We accept that the current manuscript lacks explicit ablation studies isolating the Evaluator-Summarizer loop and does not analyze failure modes. In the revision we will add ablation experiments that remove the loop and compare performance against the full system, as well as a new subsection that examines cases of non-convergence or error introduction. These additions will supply direct evidence for the loop's contribution and its limitations. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks, not self-referential definitions or fitted predictions
full rationale
The paper proposes an agentic multi-agent framework (Profiler + Generator + Evaluator-Summarizer) for tabular tasks and validates it via experiments on a benchmark of 18 task types. No mathematical derivation chain, equations, or first-principles predictions are present in the provided text. The central claim of outperformance is presented as an empirical result rather than a quantity derived from or equivalent to the framework's own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no parameters are fitted to a subset then renamed as predictions. The architecture is described as a design choice motivated by observed LLM limitations, with success measured externally against baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tommaso Bendinelli, Artur Dox, and Christian Holz. 2025. Exploring LLM Agents for Cleaning Tabular Machine Learning Datasets. InProceedings of the ICLR 2025 Workshop on Foundation Models in the Wild. https://arxiv.org/abs/2503.06664 Preprint available at https://arxiv.org/abs/2503.06664
- [2]
- [3]
- [4]
-
[5]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Xinrui He, Yikun Ban, Jiaru Zou, Tianxin Wei, Curtiss Cook, and Jingrui He. 2025. LLM-Forest: Ensemble Learning of LLMs with Graph-Augmented Prompts for Data Imputation. InFindings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, 6921–6936. doi:10.18653/v1/2025.findings-acl.361
-
[7]
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Chenxing Wei, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, Li Zhang, Lingyao Zhang, Min Yang, Mingchen Zhuge, Taicheng Guo, Tuo Zhou, Wei Tao, Xiangru Tang, Xiangtao Lu, Xiawu Zheng, Xinbing Liang, Yaying Fei, Yuheng Cheng, Zhibin Gou, Zongze Xu, and Chenglin Wu. 2024. Data Inte...
-
[8]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. InProceedings of the 12th International Conference on Learning Repre...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. 2025. Self-Evolving Multi-Agent Collaboration Networks for Software Development. InProceedings of the 13th International Conference on Learning Representations (ICLR 2025). https://arxiv.org/abs/2410.16946
- [10]
-
[11]
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2023. DS-1000: A natural and reliable benchmark for data science code generation. InInternational Conference on Machine Learning. PMLR, 18319–18345
work page 2023
- [12]
-
[13]
Ce Li, Xiaofan Liu, Zhiyan Song, Ce Chi, Chen Zhao, Jingjing Yang, Zhendong Wang, Kexin Yang, Boshen Shi, Xing Wang, Chao Deng, and Junlan Feng. 2025. TReB: A Comprehensive Benchmark for Evaluating Table Reasoning Capabilities of Large Language Models. arXiv:2506.18421 [cs.CL] https://arxiv.org/abs/2506.18421
-
[14]
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society. InAdvances in Neural Information Processing Systems (NeurIPS 2023), Vol. 36. Curran Associates, Inc
work page 2023
- [15]
- [16]
- [17]
-
[18]
Kiran Maharana, Surajit Mondal, and Bhushankumar Nemade. 2022. A Review: Data Pre-processing and Data Augmentation Techniques.Global Transitions Proceedings3 (2022), 91–99. doi:10.1016/j.gltp.2022.04.020
-
[19]
Meg Miller and Natalie Vielfaure. 2022. OpenRefine: an approachable open tool to clean research data.Bulletin-Association of Canadian Map Libraries and Archives (ACMLA)170 (2022)
work page 2022
- [20]
- [21]
-
[22]
Wei Ni, Kaihang Zhang, Xiaoye Miao, Xiangyu Zhao, Yangyang Wu, and Jianwei Yin. 2024. IterClean: An Iterative Data Cleaning Framework with Large Language Models. InProceedings of the ACM Turing A ward Celebration Conference (ACM-TURC ’24). Association for Computing Machinery, Changsha, China, 100–105. doi:10.1145/3674399.3674436
-
[23]
Chunjong Park, Anas Awadalla, Tadayoshi Kohno, and Shwetak N. Patel. 2021. Reliable and Trustworthy Machine Learning for Health Using Dataset Shift Detection. InProceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS). 3043–3055. https://proceedings. Paper under review 16 Wei Liu, Yang Gu, Xi Yan, Zihan Nan, Beicheng Xu, Keyao...
work page 2021
-
[24]
Yulu Pi. 2021. Machine Learning in Governments: Benefits, Challenges and Future Directions.JeDEM – eJournal of eDemocracy and Open Government 13, 1 (2021), 203–219. doi:10.29379/jedem.v13i1.625
-
[25]
Neoklis Polyzotis, Sudip Roy, Steven Euijong Whang, and Martin Zinkevich. 2017. Data Management Challenges in Production Machine Learning. InProceedings of the 2017 ACM International Conference on Management of Data (SIGMOD ’17). ACM, New York, NY, USA, 1723–1726. doi:10.1145/ 3035918.3054782
- [26]
-
[27]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative Agents for Software Development. arXiv:2307.07924 [cs.SE] https://arxiv.org/abs/2307.07924
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Fakhitah Ridzuan and Wan Mohd Nazmee Wan Zainon. 2019. A review on data cleansing methods for big data.Procedia Computer Science161 (2019), 731–738
work page 2019
-
[29]
Everyone wants to do the model work, not the data work
Nithya Sambasivan, Shivani Kapania, Hannah Highfill, Diana Akrong, Praveen Paritosh, and Lora M Aroyo. 2021. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. Inproceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–15
work page 2021
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL] https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [31]
- [32]
-
[33]
Yuan Sui, Mengyu Zhou, Mingjie Zhou, Shi Han, and Dongmei Zhang. 2024. Table Meets LLM: Can Large Language Models Understand Structured Table Data? A Benchmark and Empirical Study. InProceedings of the 17th ACM International Conference on Web Search and Data Mining (WSDM ’24). ACM, New York, NY, USA, 109–118. doi:10.1145/3616855.3635752
-
[34]
Xiangru Tang, Yuliang Liu, Zefan Cai, Yanjun Shao, Junjie Lu, Yichi Zhang, Zexuan Deng, Helan Hu, Kaikai An, Ruijun Huang, et al. 2023. ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code.arXiv preprint arXiv:2311.09835(2023)
-
[35]
Patara Trirat, Wonyong Jeong, and Sung Ju Hwang. 2025. AutoML-Agent: A Multi-Agent LLM Framework for Full-Pipeline AutoML. InProceedings of the 42nd International Conference on Machine Learning (ICML 2025) (Proceedings of Machine Learning Research, Vol. 267). PMLR, to appear. https://arxiv.org/abs/2410.02958
-
[36]
He Wang, Alexander Hanbo Li, Yiqun Hu, Sheng Zhang, Hideo Kobayashi, Jiani Zhang, Henry Zhu, Chung-Wei Hang, and Patrick Ng. 2025. DSMentor: Enhancing Data Science Agents with Curriculum Learning and Online Knowledge Accumulation. arXiv:2505.14163 [cs.AI] https: //arxiv.org/abs/2505.14163
-
[37]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903 [cs.CL] https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, et al. 2025. Tablebench: A comprehensive and complex benchmark for table question answering. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25497–25506
work page 2025
-
[39]
Junjie Xing, Yeye He, Mengyu Zhou, Haoyu Dong, Shi Han, Dongmei Zhang, and Surajit Chaudhuri. 2025. Table-LLM-Specialist: Language Model Specialists for Tables using Iterative Fine-tuning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025). Association for Computational Linguistics, 35443–35460. https://a...
-
[40]
Hongyang Yang, Boyu Zhang, Neng Wang, Cheng Guo, Xiaoli Zhang, Likun Lin, Junlin Wang, Tianyu Zhou, Mao Guan, Runjia Zhang, and Christina Dan Wang. 2024. FinRobot: An Open-Source AI Agent Platform for Financial Applications using Large Language Models. arXiv:2405.14767 [q-fin.ST]
-
[41]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [42]
- [43]
- [44]
-
[45]
Shujian Zhang, Chengyue Gong, Lemeng Wu, Xingchao Liu, and Mingyuan Zhou. 2023. AutoML-GPT: Automatic Machine Learning with GPT. arXiv:2305.02499 [cs.CL] https://arxiv.org/abs/2305.02499 Paper under review ProfiliTable: Profiling-Driven Tabular Data Processing via Agentic Workflows 17 A Additional Discussions This section presents the results of DeepAnaly...
-
[46]
**operation**: Clearly describe the required operator operation in natural language, use orders like 1. ..., 2. ... to list multiple operations if needed. You should describe as detailed as possible
-
[47]
**reason**: Briefly explain the rationale for selecting this operator (1–2 sentences), possibly referencing missing rates, data distribution, or task objectives in the metadata
-
[48]
The chosen type must strictly align with both the table metadata and the user's intent
**task_type**: Select exactly one matching task type from: {benchmark_task_types}. The chosen type must strictly align with both the table metadata and the user's intent
-
[49]
**suffix**: Specify the output file format, e.g., "csv", "jsonl", etc. Your output must be a valid JSON object only, with no additional text, explanations, Markdown formatting (such as ```json), or line breaks. Strictly follow the format in the example below. [Example]: User request: Fill missing values in the age column using an LSTM model trained on oth...
-
[50]
Decompose the task into independent sub-tasks
-
[51]
Each sub-task should be executable and can be found in {benchmark_task_types}
-
[52]
Output the result strictly in JSON format, mapping each sub-task type to its specific operation description, no ```json wrapping
-
[53]
TableTransformation-SplittingANDConcatenation
Each key in the JSON should be a different sub-task type, and the corresponding value should be the specific operation description. [Example]: User request: Merge multiple CSV files and deduplicate entries based on a primary key. Your output: {"TableTransformation-SplittingANDConcatenation":"Merge multiple CSV files", "TableCleaning-Deduplication":"Dedupl...
-
[54]
Metadata of the data table: {task_meta}
-
[55]
But do not copy them directly, you need to adapt them to fit the current task
Retrieved similar operator code snippets: {retrieved_operators}, If there exits, you can refer to them when writing the code. But do not copy them directly, you need to adapt them to fit the current task
-
[56]
Operator specification: {user_query} [OUTPUT RULES]:
-
[57]
The code must be executable, safe, step by step and output as a complete code block in the format ```python ... ```
-
[58]
The code must include a main() function that accepts command-line arguments for input and output file paths. Use a fixed argparse format with two required arguments: --input (input file path or list of paths) and -- output_path_dir (output file path directory)
-
[59]
The function must fulfill all user requirements. Ensure the output file format matches the user's request and contains no extra columns beyond those in the input
-
[60]
If the task involves multiple tables, the --input argument should be treated as a list of file paths, this list can have 1,2... paths. And the --output_path_dir argument will be the directory where the results will be saved
-
[61]
Please avoid modifying the original input files; read from them and write results to new files in the specified(--output_path_dir) output directory
-
[62]
no BOM in output csv file means that don't use encoding='utf-8-sig' when saving csv file
-
[63]
Let the code step by step and don't use complex logic in one step. Use as many steps as needed to ensure clarity and correctness. [Example] [INPUT] User request: Fill missing values in the age column using an LSTM model trained on other columns Operator specification: {"operators": "fill missing values in the column age using LSTM model trained on other c...
-
[64]
code" (with the complete corrected code) and
The response must be strictly in JSON format, containing only the keys "code" (with the complete corrected code) and "reason" (explaining the modification); no extra keys, explanations, comments, or markdown syntax are allowed
-
[65]
The code's --input and --output_path_dir arguments should be kept unchanged
-
[66]
The code must include an `if __name__ == '__main__':` block to ensure the script can be run independently
-
[67]
All parser arguments should have default values except --input and -- output_path_dir
-
[68]
Your output must be a valid JSON object only, with no additional text, explanations, Markdown formatting (such as ```json), or line breaks
-
[69]
No additional files or external references should be included unless explicitly required to resolve the error, and if needed, they must be handled within the code itself. Fig. 10. System Prompt for Debugger Paper under review ProfiliTable: Profiling-Driven Tabular Data Processing via Agentic Workflows 23 System prompt for Summarizer [ROLE] You are a caref...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.