Recognition: no theorem link
Fast Image Super-Resolution via Consistency Rectified Flow
Pith reviewed 2026-05-13 07:11 UTC · model grok-4.3
The pith
Rectified flow from low-resolution to high-resolution images enables single-step super-resolution when trained with consistency constraints and dual scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
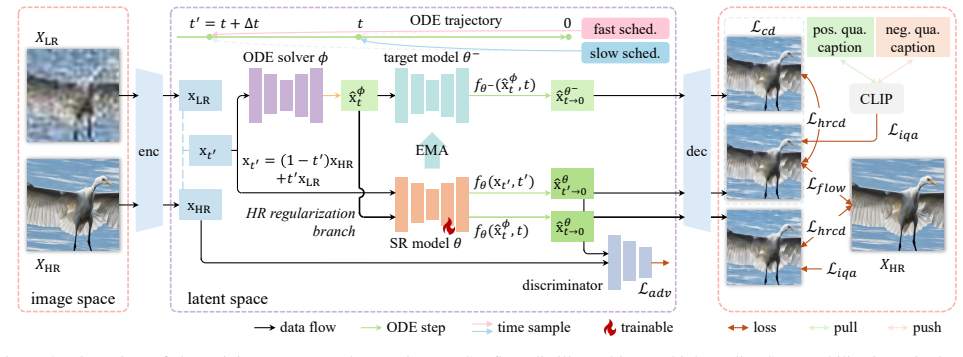
FlowSR reformulates the super-resolution problem as a rectified flow from low-resolution to high-resolution images and uses an improved consistency learning strategy that incorporates high-resolution regularization to enforce precise convergence to ground-truth targets, together with a fast-slow scheduling strategy that samples adjacent timesteps from two distinct schedulers to balance efficiency and texture fidelity, thereby enabling high-quality super-resolution in a single step.
What carries the argument
Rectified flow from low-resolution inputs to high-resolution outputs, refined through consistency distillation with high-resolution regularization and dual fast-slow timestep schedulers.
If this is right
- Super-resolution inference completes in one forward pass while retaining quality previously requiring many diffusion steps.
- The learned flow converges directly to ground-truth high-resolution images rather than stopping at approximate self-consistent points.
- Fine-grained textures are preserved by the slow scheduler without the efficiency penalty of using many timesteps throughout training.
- The overall pipeline runs substantially faster than prior diffusion-based super-resolution methods on the same hardware.
Where Pith is reading between the lines
- The same flow-plus-regularization pattern could be tested on related restoration tasks such as denoising or deblurring by swapping the low-resolution input definition.
- If the single-step outputs prove stable, the approach might reduce the need for ensemble or post-processing steps common in current fast super-resolution pipelines.
- The dual-scheduler idea suggests a general way to trade compute for detail in other consistency-based generative models.
Load-bearing premise
The assumption that high-resolution regularization combined with fast-slow scheduling forces the single-step flow to reach exact ground-truth targets without introducing artifacts or losing fine detail.
What would settle it
A direct comparison on standard super-resolution benchmarks where single-step FlowSR outputs are measured against multi-step diffusion baselines for both quantitative metrics like PSNR and perceptual quality; significant drops in fidelity or visible artifacts would falsify the claim.
Figures









read the original abstract
Diffusion models (DMs) have demonstrated remarkable success in real-world image super-resolution (SR), yet their reliance on time-consuming multi-step sampling largely hinders their practical applications. While recent efforts have introduced few- or single-step solutions, existing methods either inefficiently model the process from noisy input or fail to fully exploit iterative generative priors, compromising the fidelity and quality of the reconstructed images. To address this issue, we propose FlowSR, a novel approach that reformulates the SR problem as a rectified flow from low-resolution (LR) to high-resolution (HR) images. Our method leverages an improved consistency learning strategy to enable high-quality SR in a single step. Specifically, we refine the original consistency distillation process by incorporating HR regularization, ensuring that the learned SR flow not only enforces self-consistency but also converges precisely to the ground-truth HR target. Furthermore, we introduce a fast-slow scheduling strategy, where adjacent timesteps for consistency learning are sampled from two distinct schedulers: a fast scheduler with fewer timesteps to improve efficiency, and a slow scheduler with more timesteps to capture fine-grained texture details. Extensive experiments demonstrate that FlowSR achieves outstanding performance in both efficiency and image quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlowSR, which reformulates the image super-resolution (SR) task as a rectified flow mapping from low-resolution (LR) to high-resolution (HR) images. It proposes an improved consistency learning strategy that incorporates HR regularization to ensure the flow converges to ground-truth HR targets and a fast-slow scheduling strategy for sampling timesteps to balance efficiency and detail capture, enabling high-quality single-step inference. The authors claim that extensive experiments show outstanding performance in both efficiency and image quality compared to prior methods.
Significance. If the empirical claims are substantiated, this work could have significant impact in the field of efficient generative models for computer vision by providing a single-step solution for real-world image super-resolution, addressing the computational bottleneck of diffusion models. The integration of rectified flows with consistency distillation and the proposed regularization and scheduling techniques represent a thoughtful extension of recent generative modeling advances, potentially enabling practical applications in resource-constrained settings.
major comments (3)
- Abstract: The central claim of 'outstanding performance' in efficiency and image quality is asserted based on 'extensive experiments,' yet no quantitative metrics (e.g., PSNR, SSIM, inference time), baseline comparisons, or ablation studies are provided. This makes it impossible to evaluate the load-bearing empirical support for the superiority over existing few-step or single-step SR methods.
- Method section on HR regularization: The description claims that incorporating HR regularization ensures the learned SR flow 'converges precisely to the ground-truth HR target.' Without a specific equation defining the regularization term or analysis demonstrating how it modifies the consistency objective to enforce this without introducing bias, the claim that it forces precise convergence remains unsubstantiated and is load-bearing for the single-step fidelity assertion.
- Method section on fast-slow scheduling: The strategy samples adjacent timesteps from a fast scheduler (fewer timesteps) and slow scheduler (more timesteps) to improve efficiency while capturing textures. No details are given on scheduler definitions, timestep counts, or how this avoids artifacts in single-step inference, which directly relates to the weakest assumption that fine-grained details are preserved without fidelity loss.
minor comments (2)
- The abstract could include a brief mention of the datasets and key baselines used to contextualize the claimed performance gains.
- Notation for the rectified flow, consistency distillation objective, and scheduling parameters should be introduced with clear definitions at the start of the method section for improved readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recognition of FlowSR's potential impact. We address each major comment below and revise the manuscript to provide the requested details and clarifications.
read point-by-point responses
-
Referee: Abstract: The central claim of 'outstanding performance' in efficiency and image quality is asserted based on 'extensive experiments,' yet no quantitative metrics (e.g., PSNR, SSIM, inference time), baseline comparisons, or ablation studies are provided. This makes it impossible to evaluate the load-bearing empirical support for the superiority over existing few-step or single-step SR methods.
Authors: We agree that the abstract would benefit from explicit quantitative support. The full paper reports these results in Section 4 (Tables 1-3) with PSNR/SSIM/LPIPS on DIV2K/RealSR, inference times, and ablations. In the revision we will add a concise sentence to the abstract highlighting the key gains (e.g., single-step PSNR improvement and speed-up factors) while remaining within length limits. revision: yes
-
Referee: Method section on HR regularization: The description claims that incorporating HR regularization ensures the learned SR flow 'converges precisely to the ground-truth HR target.' Without a specific equation defining the regularization term or analysis demonstrating how it modifies the consistency objective to enforce this without introducing bias, the claim that it forces precise convergence remains unsubstantiated and is load-bearing for the single-step fidelity assertion.
Authors: We thank the referee for noting the missing formalization. The HR regularization term is an L2 penalty between the flow's endpoint and the ground-truth HR image, added to the consistency loss with a small coefficient. We will insert the explicit equation, a short derivation showing it does not bias the learned distribution, and a supporting ablation in the revised Method section. revision: yes
-
Referee: Method section on fast-slow scheduling: The strategy samples adjacent timesteps from a fast scheduler (fewer timesteps) and slow scheduler (more timesteps) to improve efficiency while capturing textures. No details are given on scheduler definitions, timestep counts, or how this avoids artifacts in single-step inference, which directly relates to the weakest assumption that fine-grained details are preserved without fidelity loss.
Authors: We appreciate the request for implementation specifics. The fast scheduler uses 4 timesteps and the slow scheduler uses 20 timesteps; adjacent pairs are drawn uniformly from each. We will add the exact scheduler definitions, sampling algorithm, and empirical analysis (including artifact-free single-step results and texture visualizations) to the Method and Experiments sections. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper reformulates image super-resolution as a rectified flow from LR to HR images and augments consistency distillation with an HR regularization term plus fast-slow scheduling. These are presented as explicit methodological additions whose correctness is asserted via empirical results rather than by reducing any target quantity to a fitted parameter or self-referential definition. No equation is shown to equal its own input by construction, no uniqueness theorem is imported from the authors' prior work, and no ansatz is smuggled via self-citation. The central performance claims therefore rest on external validation and remain independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rectified flows can be distilled via consistency learning to enable single-step SR while preserving generative priors.
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. In CVPRW, 2017. 11
work page 2017
-
[2]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. InICCV, 2019. 6, 7
work page 2019
-
[3]
Adversarial diffu- sion compression for real-world image super-resolution
Bin Chen, Gehui Li, Rongyuan Wu, Xindong Zhang, Jie Chen, Jian Zhang, and Lei Zhang. Adversarial diffu- sion compression for real-world image super-resolution. In CVPR, 2025. 2
work page 2025
-
[4]
Taming diffusion prior for image super-resolution with domain shift sdes.NeurIPS, 2024
Qinpeng Cui, Yixuan Liu, Xinyi Zhang, Qiqi Bao, Zhong- dao Wang, Qingmin Liao, Li Wang, Tian Lu, and Emad Barsoum. Taming diffusion prior for image super-resolution with domain shift sdes.NeurIPS, 2024. 1, 3, 4, 6, 12
work page 2024
-
[5]
Image quality assessment: Unifying structure and texture similarity.TPAMI, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.TPAMI, 2020. 6
work page 2020
-
[6]
Learning a deep convolutional network for image super-resolution
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. InECCV, 2014. 2
work page 2014
-
[7]
Tsd-sr: One-step diffusion with target score distillation for real-world image super-resolution
Linwei Dong, Qingnan Fan, Yihong Guo, Zhonghao Wang, Qi Zhang, Jinwei Chen, Yawei Luo, and Changqing Zou. Tsd-sr: One-step diffusion with target score distillation for real-world image super-resolution. InCVPR, 2025. 2
work page 2025
-
[8]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InICML, 2024. 12
work page 2024
-
[9]
Generative adversarial nets.NeurIPS, 2014
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.NeurIPS, 2014. 2
work page 2014
-
[10]
Xiao He, Huaao Tang, Zhijun Tu, Junchao Zhang, Kun Cheng, Hanting Chen, Yong Guo, Mingrui Zhu, Nan- nan Wang, Xinbo Gao, et al. One step diffusion-based super-resolution with time-aware distillation.arXiv preprint arXiv:2408.07476, 2024. 2
-
[11]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium.NeruIPS, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.NeruIPS, 2017. 6
work page 2017
-
[12]
Denoising diffu- sion probabilistic models.NeruIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.NeruIPS, 2020. 1, 2
work page 2020
-
[13]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022. 6
work page 2022
-
[14]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019. 6
work page 2019
-
[15]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InICCV, 2021. 6
work page 2021
-
[16]
Consistency trajectory mod- els: Learning probability flow ode trajectory of diffusion
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Mu- rata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory mod- els: Learning probability flow ode trajectory of diffusion. In ICLR, 2024. 3
work page 2024
-
[17]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 12
work page 2024
-
[18]
Photo- realistic single image super-resolution using a generative ad- versarial network
Christian Ledig, Lucas Theis, Ferenc Husz´ar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo- realistic single image super-resolution using a generative ad- versarial network. InCVPR, 2017. 2
work page 2017
-
[19]
Jianze Li, Jiezhang Cao, Zichen Zou, Xiongfei Su, Xin Yuan, Yulun Zhang, Yong Guo, and Xiaokang Yang. Distillation-free one-step diffusion for real-world image super-resolution.arXiv preprint arXiv:2410.04224, 2024. 2
-
[20]
Lsdir: A large scale dataset for image restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Deman- dolx, et al. Lsdir: A large scale dataset for image restoration. InCVPR, 2023. 6
work page 2023
-
[21]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InICCV Workshop, 2021. 2
work page 2021
-
[22]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InECCV, 2024. 2, 6, 12
work page 2024
-
[23]
Flow matching for generative mod- eling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. InICLR, 2023. 4
work page 2023
-
[24]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023. 2, 3, 4
work page 2023
-
[25]
Instaflow: One step is enough for high-quality diffusion- based text-to-image generation
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. Instaflow: One step is enough for high-quality diffusion- based text-to-image generation. InICLR, 2024. 3
work page 2024
-
[26]
Eric Luhman and Troy Luhman. Knowledge distillation in iterative generative models for improved sampling speed. arXiv preprint arXiv:2101.02388, 2021. 2
-
[27]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high- resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Anish Mittal, Rajiv Soundararajan, and Alan C Bovik. Mak- ing a “completely blind” image quality analyzer.IEEE Sig- nal processing letters, 2012. 6
work page 2012
-
[29]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InAAAI, 2024. 2 9
work page 2024
-
[30]
You only need one step: Fast super-resolution with stable diffusion via scale distillation
Mehdi Noroozi, Isma Hadji, Brais Martinez, Adrian Bulat, and Georgios Tzimiropoulos. You only need one step: Fast super-resolution with stable diffusion via scale distillation. InECCV, 2024. 2
work page 2024
-
[31]
Towards realis- tic data generation for real-world super-resolution
Long Peng, Wenbo Li, Renjing Pei, Jingjing Ren, Jiaqi Xu, Yang Wang, Yang Cao, and Zheng-Jun Zha. Towards realis- tic data generation for real-world super-resolution. InICLR,
-
[32]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 5
work page 2021
-
[33]
Ultrapixel: Advancing ultra high-resolution image synthesis to new peaks.NeurIPS, 2024
Jingjing Ren, Wenbo Li, Haoyu Chen, Renjing Pei, Bin Shao, Yong Guo, Long Peng, Fenglong Song, and Lei Zhu. Ultrapixel: Advancing ultra high-resolution image synthesis to new peaks.NeurIPS, 2024. 2
work page 2024
-
[34]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 1, 2, 5, 6, 11
work page 2022
-
[35]
Image super- resolution via iterative refinement.TPAMI, 2022
Chitwan Saharia, Jonathan Ho, William Chan, Tim Sali- mans, David J Fleet, and Mohammad Norouzi. Image super- resolution via iterative refinement.TPAMI, 2022. 2
work page 2022
-
[36]
Fast high- resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high- resolution image synthesis with latent adversarial diffusion distillation. InSIGGRAPH Asia, 2024. 5, 12
work page 2024
-
[37]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InECCV, 2024. 2
work page 2024
-
[38]
Boosting latent diffusion with flow match- ing
Johannes Schusterbauer, Ming Gui, Pingchuan Ma, Nick Stracke, Stefan Andreas Baumann, Vincent Tao Hu, and Bj¨orn Ommer. Boosting latent diffusion with flow match- ing. InECCV, 2024. 3, 4
work page 2024
-
[39]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InICLR, 2021. 1
work page 2021
-
[40]
Score-based generative modeling through stochastic differential equa- tions
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions. InICLR, 2021. 1, 2
work page 2021
-
[41]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InICML, 2023. 2, 3, 5, 8
work page 2023
-
[42]
Coser: Bridging image and language for cognitive super-resolution
Haoze Sun, Wenbo Li, Jianzhuang Liu, Haoyu Chen, Ren- jing Pei, Xueyi Zou, Youliang Yan, and Yujiu Yang. Coser: Bridging image and language for cognitive super-resolution. InCVPR, 2024. 2
work page 2024
-
[43]
Phased consistency models.NeurIPS, 2024
Fu-Yun Wang, Zhaoyang Huang, Alexander Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, et al. Phased consistency models.NeurIPS, 2024. 3, 5
work page 2024
-
[44]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. In AAAI, 2023. 6
work page 2023
-
[45]
Exploiting diffusion prior for real-world image super-resolution.IJCV, 2024
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.IJCV, 2024. 1, 2, 6, 11, 12
work page 2024
-
[46]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InICCV Workshop, 2021. 2, 6
work page 2021
-
[48]
Sinsr: diffusion-based image super- resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super- resolution in a single step. InCVPR, 2024. 1, 2, 6, 12
work page 2024
-
[49]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.NeurIPS, 2023. 2
work page 2023
-
[50]
Component divide-and-conquer for real-world image super-resolution
Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qix- iang Ye, Wangmeng Zuo, and Liang Lin. Component divide-and-conquer for real-world image super-resolution. In ECCV, 2020. 6, 7, 11
work page 2020
-
[51]
One-step effective diffusion network for real-world image super-resolution.NeurIPS, 2024
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.NeurIPS, 2024. 1, 2, 6, 12
work page 2024
-
[52]
Seesr: Towards semantics-aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics-aware real-world image super-resolution. InCVPR, 2024. 1, 2, 6, 12
work page 2024
-
[53]
Tack- ling the generative learning trilemma with denoising diffu- sion gans
Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tack- ling the generative learning trilemma with denoising diffu- sion gans. InICLR, 2022. 2
work page 2022
-
[54]
Rui Xie, Ying Tai, Chen Zhao, Kai Zhang, Zhenyu Zhang, Jun Zhou, Xiaoqian Ye, Qian Wang, and Jian Yang. Addsr: Accelerating diffusion-based blind super- resolution with adversarial diffusion distillation.arXiv preprint arXiv:2404.01717, 2024. 2
-
[55]
Perflow: Piecewise rectified flow as universal plug-and-play accelerator.NeurIPS, 2024
Hanshu Yan, Xingchao Liu, Jiachun Pan, Jun Hao Liew, Qiang Liu, and Jiashi Feng. Perflow: Piecewise rectified flow as universal plug-and-play accelerator.NeurIPS, 2024. 3
work page 2024
-
[56]
arXiv preprint arXiv:2407.02398 , year=
Ling Yang, Zixiang Zhang, Zhilong Zhang, Xingchao Liu, Minkai Xu, Wentao Zhang, Chenlin Meng, Stefano Er- mon, and Bin Cui. Consistency flow matching: Defin- ing straight flows with velocity consistency.arXiv preprint arXiv:2407.02398, 2024. 3
-
[57]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InCVPR, 2022. 6
work page 2022
-
[58]
Pixel-aware stable diffusion for realistic im- age super-resolution and personalized stylization
Tao Yang, Rongyuan Wu, Peiran Ren, Xuansong Xie, and Lei Zhang. Pixel-aware stable diffusion for realistic im- age super-resolution and personalized stylization. InECCV,
-
[59]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Micha ¨el Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis. NeurIPS, 2024. 5 10
work page 2024
-
[60]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In CVPR, 2024. 2
work page 2024
-
[61]
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo- realistic image restoration in the wild. InCVPR, 2024. 1, 2
work page 2024
-
[62]
Resshift: Efficient diffusion model for image super- resolution by residual shifting.NeurIPS, 2023
Zongsheng Yue, Jianyi Wang, and Chen Change Loy. Resshift: Efficient diffusion model for image super- resolution by residual shifting.NeurIPS, 2023. 1, 2, 4, 6, 7, 12
work page 2023
-
[63]
Arbitrary-steps image super-resolution via diffusion inver- sion
Zongsheng Yue, Kang Liao, and Chen Change Loy. Arbitrary-steps image super-resolution via diffusion inver- sion. InCVPR, 2025. 2
work page 2025
-
[64]
arXiv preprint arXiv:2409.17058 (2024)
Aiping Zhang, Zongsheng Yue, Renjing Pei, Wenqi Ren, and Xiaochun Cao. Degradation-guided one-step im- age super-resolution with diffusion priors.arXiv preprint arXiv:2409.17058, 2024. 1, 2
-
[65]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timo- fte. Designing a practical degradation model for deep blind image super-resolution. InICCV, 2021. 2
work page 2021
-
[66]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, 2023. 2
work page 2023
-
[67]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 5, 6 In this supplementary material, we first provide addi- tional details about our FlowSR in Sec. 7. Next, we present more experimental results in Sec. 8. Finally, we discuss the limitations ...
work page 2018
-
[68]
The fine-tuned SR flow model is then used to initialize both the SR modelθand the teacher modelϕ
Implementation Details We first fine-tune the pre-trained SD model [34] to adapt it to our SR flow learning objectives. The fine-tuned SR flow model is then used to initialize both the SR modelθand the teacher modelϕ. A default text prompt is used for the SD model. During consistency SR flow training, each train- ing batch is split into two groups: one fo...
-
[69]
Evaluation on DIV2K-Val We also evaluate our method on the DIV2K-Val dataset [1, 45]
More Results 8.1. Evaluation on DIV2K-Val We also evaluate our method on the DIV2K-Val dataset [1, 45]. Table 6 provides a quantitative comparison of var- ious SR methods. Across all reference-based metrics, our FlowSR achieves state-of-the-art performance or performs on par with the best existing methods. For no-reference metrics, while FlowSR performs w...
-
[70]
Limitations and Future Works In this work, we tackle one-step SR from the perspective of flow and consistency. We provide valuable insights into the effective use of flow-based techniques and consistency learning to achieve competitive SR results in a single-step setting. While our study demonstrates promising results, there are some limitations. First, d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.