Recognition: 1 theorem link
· Lean TheoremPretraining Exposure Explains Popularity Judgments in Large Language Models
Pith reviewed 2026-05-13 05:50 UTC · model grok-4.3
The pith
LLM popularity judgments align more closely with pretraining exposure than with Wikipedia popularity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
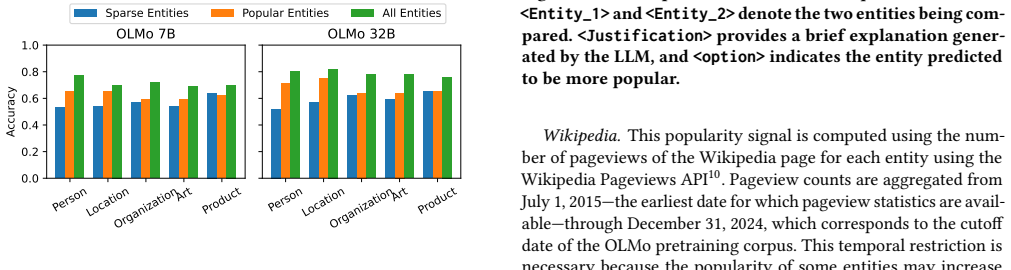
Large language models exhibit systematic preferences for well-known entities. Direct analysis reveals that pretraining exposure strongly correlates with Wikipedia popularity, serving as a proxy for real-world salience. LLM popularity judgments, however, align more closely with pretraining exposure than with Wikipedia pageviews, with this alignment being strongest for larger models and in the long tail where Wikipedia data is less reliable. Pairwise comparisons elicit judgments that match exposure better than scalar estimations.
What carries the argument
Precise entity-level exposure statistics from the complete pretraining corpus, compared to Wikipedia pageviews and LLM popularity signals elicited via scalar estimation and pairwise comparison.
If this is right
- Pretraining statistics are the primary source of popularity priors in LLMs rather than external popularity signals.
- Pairwise comparison methods reveal stronger alignment with exposure than direct scalar estimation.
- Larger models exhibit stronger correspondence between their judgments and pretraining exposure.
- LLM judgments remain consistent with exposure even for entities where Wikipedia popularity is unreliable.
Where Pith is reading between the lines
- Modifying the frequency of entities in training data could adjust popularity biases in model outputs.
- LLMs may offer more reliable salience estimates than Wikipedia for long-tail entities based on data exposure.
- This connects popularity bias to the broader issue of how training distributions influence model behavior on factual and preferential tasks.
- Similar patterns could be tested for other elicited judgments such as perceived importance or sentiment associations.
Load-bearing premise
The token-level exposure counts in the pretraining corpus accurately reflect the patterns that influenced the models' internal representations of these entities.
What would settle it
If a model trained on a corpus with altered exposure for the entities produced popularity judgments that did not shift to match the new exposure levels, the claim would be falsified.
Figures



read the original abstract
Large language models (LLMs) exhibit systematic preferences for well-known entities, a phenomenon often attributed to popularity bias. However, the extent to which these preferences reflect real-world popularity versus statistical exposure during pretraining remains unclear, largely due to the inaccessibility of most training corpora. We provide the first direct, large-scale analysis of popularity bias grounded in fully observable pretraining data. Leveraging the open OLMo models and their complete pretraining corpus, Dolma, we compute precise entity-level exposure statistics across 7.4 trillion tokens. We analyze 2,000 entities spanning five types (Person, Location, Organization, Art, Product) and compare pretraining exposure against Wikipedia pageviews and two elicited LLM popularity signals: direct scalar estimation and pairwise comparison. Our results show that pretraining exposure strongly correlates with Wikipedia popularity, validating exposure as a meaningful proxy for real-world salience during the training period. More importantly, we find that LLM popularity judgments align more closely with exposure than with Wikipedia, especially when elicited via pairwise comparisons. This alignment is strongest for larger models and persists in the long tail, where Wikipedia popularity becomes unreliable. Overall, our findings demonstrate that popularity priors in LLMs are primarily shaped by pretraining statistics rather than external popularity signals, offering concrete evidence that data exposure plays a central role in driving popularity bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes popularity bias in LLMs by leveraging the open OLMo models and their full Dolma pretraining corpus (7.4T tokens). For 2,000 entities across five types, it computes precise token-level exposure counts and compares them to Wikipedia pageviews as well as two LLM-elicited signals (scalar estimates and pairwise comparisons). The central claims are that exposure correlates strongly with Wikipedia popularity (validating it as a proxy), but LLM judgments align more closely with exposure than with Wikipedia—especially via pairwise elicitation, for larger models, and in the long tail where Wikipedia is unreliable—indicating that pretraining statistics primarily shape these priors.
Significance. If the core measurements hold, the work provides the first large-scale, direct evidence tying LLM popularity judgments to observable pretraining exposure rather than external signals, using a fully open training setup. This is a clear strength for reproducibility and for isolating data-driven effects; the long-tail persistence and pairwise advantage are potentially impactful for understanding and mitigating bias.
major comments (2)
- [Methods] Methods (entity mention detection and exposure computation): the central claim that exposure is a reliable proxy for the statistics shaping LLM representations requires that token-level counts accurately capture mentions despite aliases, abbreviations, homonyms, and contextual variants. If detection relies on simple string matching without normalization or disambiguation (especially for Persons/Organizations in the long tail), relative rankings become noisy; this noise could artifactually strengthen or weaken the reported alignment advantage over Wikipedia pageviews.
- [Results] Results (correlation comparisons and controls): the claim that LLM signals (particularly pairwise) align more closely with exposure than Wikipedia rests on correlation differences. Without explicit reporting of entity selection criteria for the 2,000 items, statistical tests for the significance of exposure-vs-Wikipedia correlation gaps, or controls for potential confounders (e.g., entity type imbalances or frequency artifacts), it is difficult to rule out that post-hoc choices inflate the advantage.
minor comments (2)
- [Methods] Clarify the exact definition of 'exposure' (raw token counts, normalized frequencies, or log-transformed) and how pairwise judgments are aggregated when cycles or ties occur.
- [Results] Figure or table showing per-entity-type breakdowns would help assess whether the long-tail effect is uniform or driven by specific categories.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications from the manuscript and outlining planned revisions to improve rigor and transparency.
read point-by-point responses
-
Referee: [Methods] Methods (entity mention detection and exposure computation): the central claim that exposure is a reliable proxy for the statistics shaping LLM representations requires that token-level counts accurately capture mentions despite aliases, abbreviations, homonyms, and contextual variants. If detection relies on simple string matching without normalization or disambiguation (especially for Persons/Organizations in the long tail), relative rankings become noisy; this noise could artifactually strengthen or weaken the reported alignment advantage over Wikipedia pageviews.
Authors: We agree that accurate mention detection is foundational to interpreting exposure counts as a proxy. Our approach, detailed in Section 3.2, relies on exact string matching against the canonical entity names in our curated set of 2,000 entities (drawn from Wikipedia categories chosen to reduce homonymy). We did not apply alias normalization or full disambiguation pipelines. This is a limitation, particularly in the long tail, and the referee is correct that unaccounted variants could introduce noise. We will revise the Methods section to explicitly describe the matching procedure, add a small-scale manual validation of detection precision on sampled Dolma documents, and include a limitations paragraph discussing potential impacts on correlation estimates. revision: yes
-
Referee: [Results] Results (correlation comparisons and controls): the claim that LLM signals (particularly pairwise) align more closely with exposure than Wikipedia rests on correlation differences. Without explicit reporting of entity selection criteria for the 2,000 items, statistical tests for the significance of exposure-vs-Wikipedia correlation gaps, or controls for potential confounders (e.g., entity type imbalances or frequency artifacts), it is difficult to rule out that post-hoc choices inflate the advantage.
Authors: The entity selection process is described in Section 3.1, including balanced sampling across the five types and minimum pageview thresholds. However, we acknowledge that the description could be more explicit and that formal tests for correlation differences and confounder controls are absent. We will add: (i) a dedicated subsection with precise selection criteria and a summary table, (ii) statistical tests (Steiger’s test for dependent correlations) comparing exposure-LLM vs. Wikipedia-LLM coefficients, and (iii) stratified analyses by entity type and by exposure-frequency bins to address imbalances and frequency artifacts. These will be incorporated into the revised Results and Appendix. revision: yes
Circularity Check
No circularity: correlations between independent corpus counts, Wikipedia views, and model outputs
full rationale
The paper computes token-level exposure counts directly from the public Dolma corpus (7.4T tokens) for 2,000 entities and correlates them against two external signals: Wikipedia pageviews and LLM-elicited popularity judgments (scalar and pairwise). No parameters are fitted to the target popularity data, no equations reduce one quantity to a definition of another, and no self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim—that pairwise LLM judgments align more closely with exposure than with Wikipedia—rests on observable statistical comparisons rather than any self-referential construction. This is the most common honest non-finding for observational corpus-analysis papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wikipedia pageviews during the relevant period serve as a reasonable proxy for real-world popularity of the selected entities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe compute precise entity-level exposure statistics across 7.4 trillion tokens... Spearman correlation between popularity signals and entity exposure
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondrej Dusek. 2024. Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed- Source LLMs. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Yvette Graham and Matthew Purver (Eds.). Association ...
- [3]
-
[4]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21). 2633–2650
work page 2021
-
[5]
Jesse Dodge, Maarten Sap, Ana Marasović, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. 2021. Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Spec...
-
[6]
Vitaly Feldman. 2020. Does learning require memorization? a short tale about a long tail. InProceedings of the 52nd Annual ACM SIGACT Symposium on The- ory of Computing(Chicago, IL, USA)(STOC 2020). Association for Computing Machinery, New York, NY, USA, 954–959. doi:10.1145/3357713.3384290
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. 2023. Large Language Models Can Self-Improve. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 1051–1068. doi:10.18653/v1/202...
-
[9]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, et al. 2022. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Hans Hergen Lehmann, Jae Hee Lee, Steven Schockaert, and Stefan Wermter
- [11]
-
[12]
Jiacheng Liu, Sewon Min, Luke Zettlemoyer, Yejin Choi, and Hannaneh Hajishirzi. [n. d.]. Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens. InFirst Conference on Language Modeling
-
[13]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, an...
work page 2023
-
[14]
Roberto Navigli, Simone Conia, and Björn Ross. 2023. Biases in Large Language Models: Origins, Inventory, and Discussion.J. Data and Information Quality15, 2, Article 10 (June 2023), 21 pages. doi:10.1145/3597307
-
[15]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. 2025. Olmo 3.arXiv preprint arXiv:2512.13961(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
2019.PyTorch: an imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019.PyTorch: an imperative style, high-per...
work page 2019
-
[17]
Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language Models as Knowledge Bases?. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP), Kentaro Inui, Jing ...
-
[18]
Andrea Pozzi, Alessandro Incremona, Daniele Tessera, and Daniele Toti. 2025. Mitigating exposure bias in large language model distillation: an imitation learning approach.Neural Comput. Appl.37, 18 (March 2025), 12013–12029. doi:10.1007/s00521-025-11162-0
-
[19]
Gabriele Prato, Jerry Huang, Prasanna Parthasarathi, Shagun Sodhani, and Sarath Chandar. 2024. Do Large Language Models Know How Much They Know?. InProceedings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 6054–
work page 2024
-
[20]
doi:10.18653/v1/2024.emnlp-main.348
-
[21]
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. 2023. Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789(2023). SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Jamshid Mozafari, Bhawna Piryani, and Adam Jatowt
-
[22]
Kurt Shuster, Mojtaba Komeili, Leonard Adolphs, Stephen Roller, Arthur Szlam, and Jason Weston. 2022. Language Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion. InFindings of the Association for Computational Linguistics: EMNLP 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Compu...
-
[23]
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkin- son, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lam- bert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew Peters, Abhilasha Ravichander, Kyl...
- [24]
-
[25]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupati- raju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Ziyi Tong, Feifei Sun, and Le Minh Nguyen. 2025. Pretraining Data Exposure in Large Language Models: A Survey of Membership Inference, Data Contami- nation, and Security Implications. InNatural Language Processing and Informa- tion Systems: 30th International Conference on Applications of Natural Language to Information Systems, NLDB 2025, Kanazawa, Japan...
-
[27]
Fei Wang, Wenjie Mo, Yiwei Wang, Wenxuan Zhou, and Muhao Chen. 2023. A Causal View of Entity Bias in (Large) Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 15173–15184. doi:10.18653/v1/2023.findings-emnlp.1013
-
[28]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. [n. d.]. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InThe Eleventh International Conference on Learning Representations
-
[29]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-...
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Pengfei Yu and Heng Ji. 2024. Information Association for Language Model Updating by Mitigating LM-Logical Discrepancy. InProceedings of the 28th Con- ference on Computational Natural Language Learning, Libby Barak and Malihe Alikhani (Eds.). Association for Computational Linguistics, Miami, FL, USA, 117–129. doi:10.18653/v1/2024.conll-1.10
-
[32]
Weichao Zhang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2024. Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Compu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.