Recognition: no theorem link
A Semi-Supervised Framework for Speech Confidence Detection using Whisper
Pith reviewed 2026-05-13 03:54 UTC · model grok-4.3
The pith
Fusing Whisper embeddings with acoustic prosodic features in a semi-supervised setup improves speaker confidence detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
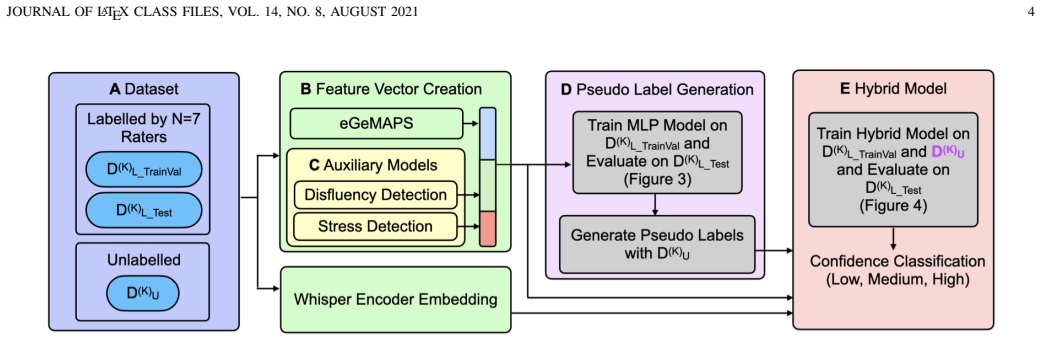
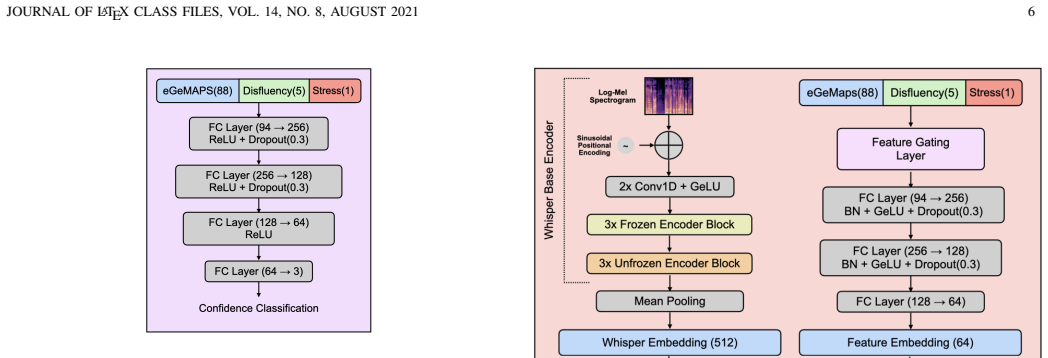
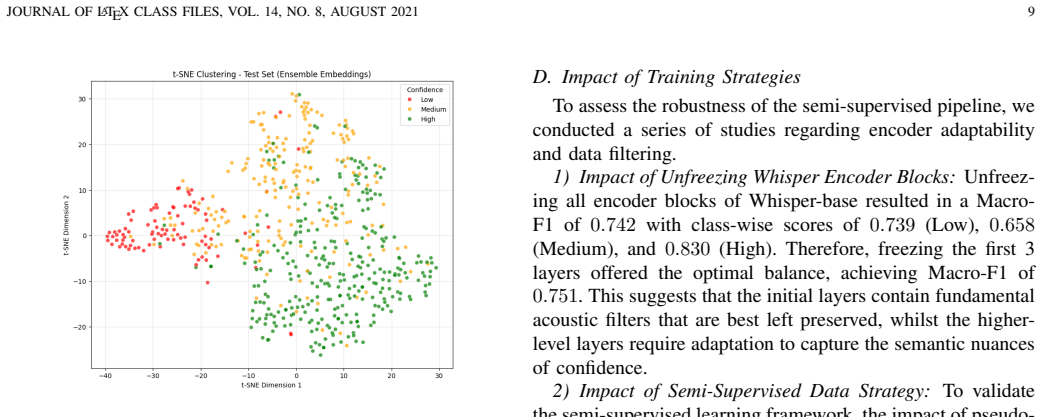
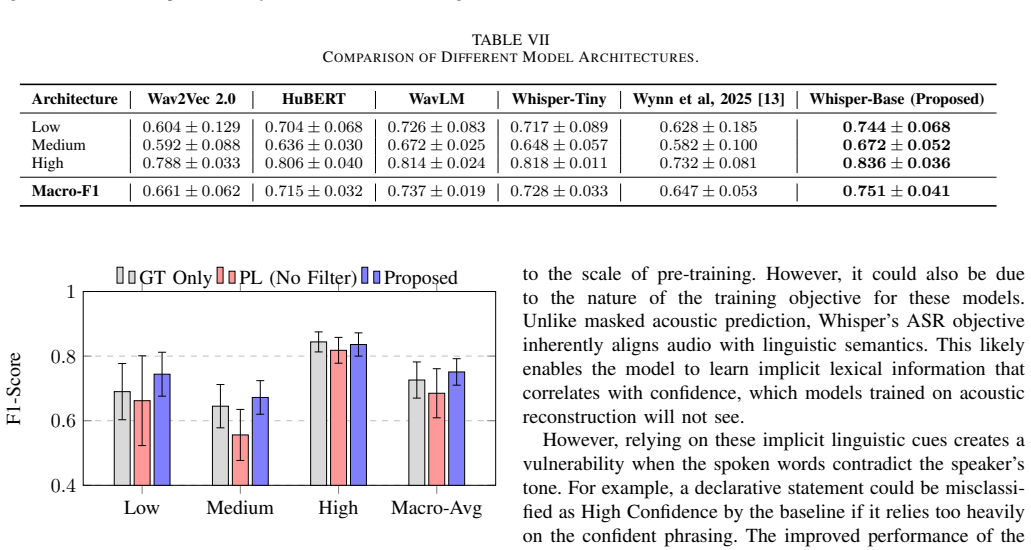
The hybrid semi-supervised framework fuses deep semantic embeddings from the Whisper encoder with an interpretable acoustic feature vector of eGeMAPS descriptors and auxiliary probability estimates of vocal stress and disfluency. Using an Uncertainty-Aware Pseudo-Labelling strategy to select high-quality samples from unlabelled data, the approach achieves a Macro-F1 score of 0.751, outperforming self-supervised baselines such as WavLM, HuBERT, and Wav2Vec 2.0, and improves the minority class by 3% over the unimodal Whisper baseline.
What carries the argument
The Uncertainty-Aware Pseudo-Labelling strategy combined with fusion of Whisper encoder embeddings and eGeMAPS plus prosodic auxiliary features, which supplies corrective acoustic signals missing from deep semantic representations alone.
If this is right
- Explicit prosodic and auxiliary features correct for information lost in deep semantic representations.
- High-quality curated pseudo-labels outperform indiscriminate large-scale data augmentation.
- The hybrid model surpasses self-supervised audio models like WavLM, HuBERT, and Wav2Vec 2.0.
- Data quality matters more than quantity for perceived confidence detection tasks.
Where Pith is reading between the lines
- Similar fusion approaches could improve detection of other speaker states such as emotion or engagement in low-data settings.
- The emphasis on uncertainty in pseudo-labelling may help other speech classification tasks with subjective labels.
- Testing the framework on real-world applications like virtual assistants could reveal practical benefits for adaptive responses.
Load-bearing premise
That the added acoustic features supply information not already captured in the Whisper embeddings and that the uncertainty-aware method picks unbiased high-quality pseudo-labels.
What would settle it
Running the same experiments on an independent dataset and observing no gain in Macro-F1 score or minority class performance from adding the acoustic features or the pseudo-labelling step.
Figures


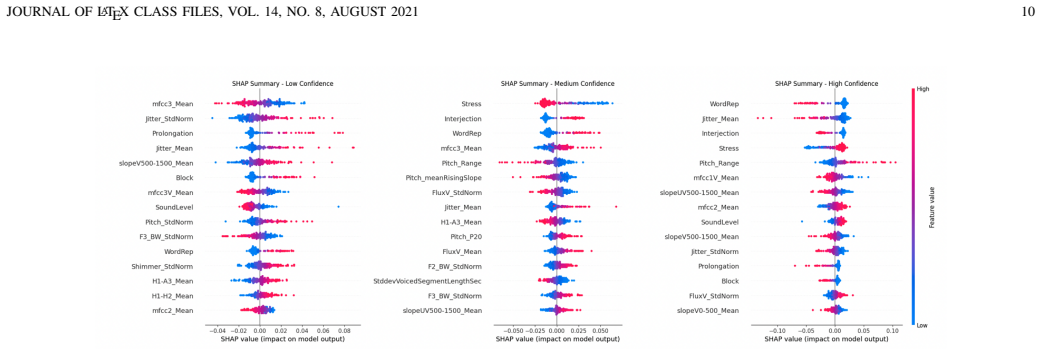
read the original abstract
Automatic detection of speaker confidence is critical for adaptive computing but remains constrained by limited labelled data and the subjectivity of paralinguistic annotations. This paper proposes a semi-supervised hybrid framework that fuses deep semantic embeddings from the Whisper encoder with an interpretable acoustic feature vector composed of eGeMAPS descriptors and auxiliary probability estimates of vocal stress and disfluency. To mitigate reliance on scarce ground truth data, we introduce an Uncertainty-Aware Pseudo-Labelling strategy where a model generates labels for unlabelled data, retaining only high-quality samples for training. Experimental results demonstrate that the proposed approach achieves a Macro-F1 score of 0.751, outperforming self-supervised baselines, including WavLM, HuBERT, and Wav2Vec 2.0. The hybrid architecture also surpasses the unimodal Whisper baseline, yielding a 3\% improvement in the minority class, confirming that explicit prosodic and auxiliary features provide necessary corrective signals which are otherwise lost in deep semantic representations. Ablation studies further show that a curated set of high confidence pseudo-labels outperforms indiscriminate large scale augmentation, confirming that data quality outweighs quantity for perceived confidence detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a semi-supervised hybrid framework for automatic detection of speaker confidence in speech. It fuses Whisper encoder embeddings with an interpretable acoustic feature vector (eGeMAPS descriptors plus auxiliary probabilities for vocal stress and disfluency). An Uncertainty-Aware Pseudo-Labelling strategy generates and filters pseudo-labels from unlabelled data, retaining only high-quality samples. The method reports a Macro-F1 of 0.751, outperforming self-supervised baselines (WavLM, HuBERT, Wav2Vec 2.0) and the unimodal Whisper baseline (with a 3% gain on the minority class). Ablations indicate that curated high-confidence pseudo-labels outperform indiscriminate large-scale augmentation.
Significance. If the performance claims hold after validation, the work would demonstrate a practical way to combine deep semantic representations with hand-crafted prosodic features for subjective paralinguistic tasks under label scarcity. The emphasis on filtering for pseudo-label quality rather than scale offers a transferable insight for semi-supervised speech classification.
major comments (2)
- [Uncertainty-Aware Pseudo-Labelling strategy (methods and experiments)] The headline Macro-F1 of 0.751 and the 3% minority-class improvement rest on the Uncertainty-Aware Pseudo-Labelling component. No held-out validation of pseudo-label accuracy against human ground truth (e.g., precision, recall, or confusion matrix on retained samples) is reported. Because confidence is a subjective trait with known annotator disagreement, the uncertainty filter may retain the model's own biased predictions rather than genuinely high-quality labels, undermining the claim that the hybrid acoustic features supply corrective signals absent from Whisper embeddings.
- [Ablation studies (experiments)] The ablation comparing curated high-confidence pseudo-labels to indiscriminate augmentation does not substitute for an external accuracy check on the pseudo-labels themselves. Without such a check, it remains possible that the reported gains arise from an altered training distribution rather than from the added prosodic features.
minor comments (4)
- [Abstract and experimental setup] The abstract and experimental sections provide no dataset name, size, train/test split, class distribution, or annotation protocol, making it impossible to assess the reliability of the reported Macro-F1 and minority-class results.
- [Experimental results] No statistical significance tests (e.g., McNemar or paired t-tests) are reported for the performance differences versus baselines or the unimodal Whisper model.
- [Methods] Implementation details are absent: the exact definition of uncertainty used for filtering, the threshold value, the proportion of unlabelled data retained, and the training hyperparameters for the hybrid model.
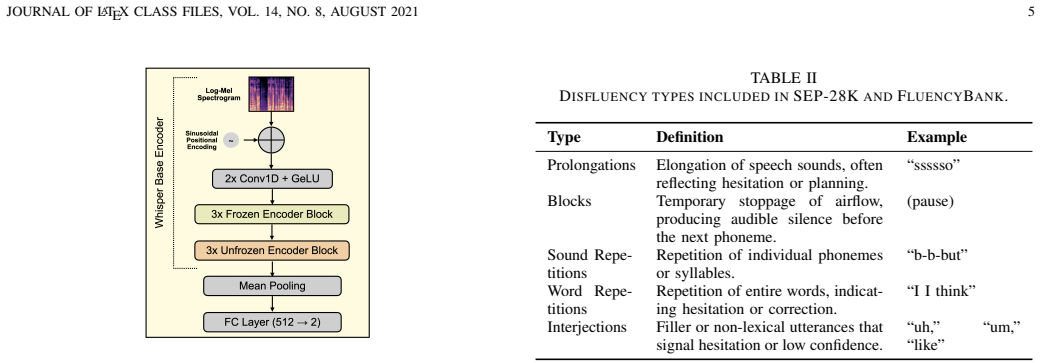
- [Feature extraction] The paper does not discuss how the auxiliary vocal-stress and disfluency probability estimates are obtained or whether they are derived from the same Whisper model or separate modules.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of validating the semi-supervised component, and we address each point below with planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Uncertainty-Aware Pseudo-Labelling strategy (methods and experiments)] The headline Macro-F1 of 0.751 and the 3% minority-class improvement rest on the Uncertainty-Aware Pseudo-Labelling component. No held-out validation of pseudo-label accuracy against human ground truth (e.g., precision, recall, or confusion matrix on retained samples) is reported. Because confidence is a subjective trait with known annotator disagreement, the uncertainty filter may retain the model's own biased predictions rather than genuinely high-quality labels, undermining the claim that the hybrid acoustic features supply corrective signals absent from Whisper embeddings.
Authors: We agree that direct validation of pseudo-label accuracy against human annotations would provide stronger evidence for the quality of the retained samples. The unlabelled data lacks ground-truth labels by design, which is the core motivation for the semi-supervised setting; obtaining new human annotations for a held-out subset would require additional resources not available in the current study. The Uncertainty-Aware Pseudo-Labelling uses model uncertainty to filter samples, and the reported ablations demonstrate that high-confidence selection yields better performance than indiscriminate augmentation. In the revised manuscript, we will expand the methods section to detail the uncertainty estimation procedure and add a limitations discussion addressing potential biases arising from subjectivity. We will also include an analysis correlating uncertainty scores with downstream test-set performance as a proxy validation. revision: partial
-
Referee: [Ablation studies (experiments)] The ablation comparing curated high-confidence pseudo-labels to indiscriminate augmentation does not substitute for an external accuracy check on the pseudo-labels themselves. Without such a check, it remains possible that the reported gains arise from an altered training distribution rather than from the added prosodic features.
Authors: The ablation isolates the effect of pseudo-label curation by holding the model architecture, features, and training procedure fixed while varying only the selection strategy. The main results separately demonstrate the benefit of the hybrid acoustic features over the Whisper-only baseline under identical pseudo-labelling conditions. To clarify this distinction, we will revise the experiments section to add an explicit ablation that applies the same high-confidence pseudo-labelling regime both with and without the eGeMAPS plus auxiliary features, thereby showing that the performance lift from the hybrid component is not solely attributable to distribution shift. revision: yes
Circularity Check
No circularity: empirical claims rest on external baselines and ablations
full rationale
The paper reports an empirical Macro-F1 of 0.751 on (presumably held-out) test data, with direct comparisons to independent external models (WavLM, HuBERT, Wav2Vec 2.0) and an ablation contrasting curated high-confidence pseudo-labels versus indiscriminate augmentation. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described claims. The Uncertainty-Aware Pseudo-Labelling strategy is presented as a methodological choice whose value is checked by ablation against quantity-based augmentation; the final performance numbers are not forced by construction from the training inputs themselves. This is a standard supervised/semi-supervised evaluation setup against external benchmarks, so the derivation chain does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Social psychological models of interpersonal communication,
R. M. Krauss and S. R. Fussell, “Social psychological models of interpersonal communication,” inSocial psychology: Handbook of basic principles, E. T. Higgins and A. W. Kruglanski, Eds. New York, NY: Guilford Press, 1996, pp. 655–701
work page 1996
-
[2]
Effects of self-confidence and diction on speaking skills in junior high school students,
M. Mardiana, B. Laksmana, and S. Sukardi, “Effects of self-confidence and diction on speaking skills in junior high school students,”Indo- Fintech Intellectuals: Journal of Economics and Business, vol. 4, no. 4, pp. 1333–1344, Aug. 2024
work page 2024
-
[3]
J. J. Guyer, L. R. Fabrigar, and T. I. Vaughan-Johnston, “Speech rate, intonation, and pitch: Investigating the bias and cue effects of vocal confidence on persuasion,”Personality and Social Psychology Bulletin, vol. 45, no. 3, pp. 389–405, 2019
work page 2019
-
[4]
Automatic feedback in online learning environments: A systematic literature review,
A. P. Cavalcanti, A. Barbosa, R. Carvalho, F. Freitas, Y .-S. Tsai, D. Ga ˇsevi´c, and R. F. Mello, “Automatic feedback in online learning environments: A systematic literature review,”Computers and Educa- tion: Artificial Intelligence, vol. 2, p. 100027, 2021
work page 2021
-
[5]
A cognitive model of social phobia,
D. M. Clark and A. Wells, “A cognitive model of social phobia,” in Social phobia: Diagnosis, assessment, and treatment, R. G. Heimberg and M. R. Liebowitz, Eds. New York: Guilford Press, 1995, pp. 69–93
work page 1995
-
[6]
Encoding and decoding confidence information in speech,
X. Jiang and M. Pell, “Encoding and decoding confidence information in speech,” inProc. Speech Prosody 2014, 2014, pp. 573–576
work page 2014
-
[7]
Recognizing uncertainty in speech,
H. Pon-Barry and S. M. Shieber, “Recognizing uncertainty in speech,” EURASIP Journal on Advances in Signal Processing, vol. 2011, no. 1, Dec. 2010
work page 2011
-
[8]
On finding the best learning model for assessing confidence in speech,
S. Nair, M. Mohan, J. Rajesh, and P. Chandran, “On finding the best learning model for assessing confidence in speech,” in2020 The 3rd In- ternational Conference on Machine Learning and Machine Intelligence, ser. MLMI ’20. New York, NY , USA: Association for Computing Machinery, 2020, p. 58–64
work page 2020
-
[9]
Ted-lium 3: Twice as much data and corpus repartition for experiments on speaker adaptation,
F. Hernandez, V . Nguyen, S. Ghannay, N. Tomashenko, and Y . Esteve, “Ted-lium 3: Twice as much data and corpus repartition for experiments on speaker adaptation,” inSpeech and Computer: 20th International Conference, SPECOM 2018, Leipzig, Germany, September 18–22, 2018, Proceedings 20. Springer, 2018, pp. 198–208
work page 2018
-
[10]
Sep-28k: A dataset for stuttering event detection from podcasts with people who stutter,
C. Lea, V . Mitra, A. Joshi, S. Kajarekar, and J. Bigham, “Sep-28k: A dataset for stuttering event detection from podcasts with people who stutter,” inICASSP, 2021. [Online]. Available: https://arxiv.org/pdf/2102.12394.pdf
-
[11]
Multimodal senti- ment intensity analysis in videos: Facial gestures and verbal messages,
A. Zadeh, R. Zellers, E. Pincus, and L.-P. Morency, “Multimodal senti- ment intensity analysis in videos: Facial gestures and verbal messages,” IEEE Intelligent Systems, vol. 31, no. 6, pp. 82–88, 2016
work page 2016
-
[12]
The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,
D. Galvez, G. Diamos, J. Ciro, J. F. Cer ´on, K. Achorn, A. Gopi, D. Kanter, M. Lam, M. Mazumder, and V . J. Reddi, “The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,”CoRR, 2021. [Online]. Available: https://arxiv.org/abs/2111.09344
-
[13]
Semi-supervised speech confidence detection using pseudo-labelling and whisper embeddings,
A. Wynn, J. Wang, and X. Tan, “Semi-supervised speech confidence detection using pseudo-labelling and whisper embeddings,” inArtificial Intelligence in Education. Cham: Springer Nature Switzerland, 2025, pp. 266–274
work page 2025
-
[14]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” 2022. [Online]. Available: https://arxiv.org/abs/2212.04356 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “Wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS’20. Red Hook, NY , USA: Curran Associates Inc., 2020
work page 2020
-
[16]
Pseudo-label : The simple and efficient semi-supervised learning method for deep neural networks,
D.-H. Lee, “Pseudo-label : The simple and efficient semi-supervised learning method for deep neural networks,”ICML 2013 Workshop : Challenges in Representation Learning (WREPL), 07 2013
work page 2013
-
[17]
The geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing,
F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. Andre, C. Busso, L. Y . Devillers, J. Epps, P. Laukka, S. S. Narayanan, and K. P. Truong, “The geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing,”IEEE Transactions on Affective Computing, vol. 7, no. 2, pp. 190–202, Apr. 2016. [Online]. Available: https:/...
-
[18]
A. Mehrabian, “Pleasure-arousal-dominance: A general framework for describing and measuring individual differences in temperament,” Current Psychology, vol. 14, no. 4, p. 261–292, Dec. 1996. [Online]. Available: http://dx.doi.org/10.1007/BF02686918
-
[19]
Evidence for a three-factor theory of emotions,
J. A. Russell and A. Mehrabian, “Evidence for a three-factor theory of emotions,”Journal of research in Personality, vol. 11, no. 3, pp. 273– 294, 1977
work page 1977
-
[20]
C. Chappuis and D. Grandjean, “Set the tone: Trustworthy and dominant novel voices classification using explicit judgement and machine learning techniques,”PLOS ONE, vol. 17, no. 6, p. e0267432, Jun. 2022. [Online]. Available: http://dx.doi.org/10.1371/journal.pone.0267432
-
[21]
The sound of confidence and doubt,
X. Jiang and M. D. Pell, “The sound of confidence and doubt,”Speech Communication, vol. 88, pp. 106–126, 2017
work page 2017
-
[22]
Robocop: A robotic coach for oral presentations,
H. Trinh, R. Asadi, D. Edge, and T. Bickmore, “Robocop: A robotic coach for oral presentations,”Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., vol. 1, no. 2, jun 2017
work page 2017
-
[23]
A deep audiovisual approach for human confidence classification,
S. Chanda, K. Fitwe, G. Deshpande, B. W. Schuller, and S. Patel, “A deep audiovisual approach for human confidence classification,” Frontiers in Computer Science, vol. 3, 2021. [Online]. Available: https://www.frontiersin.org/articles/10.3389/fcomp.2021.674533
-
[24]
Speech disfluency and gestures production in undergraduate students’confidence level of speaking,
N. L. E. Astuti, N. N. Padmadewi, and I. N. A. J. Putra, “Speech disfluency and gestures production in undergraduate students’confidence level of speaking,”Media Bina Ilmiah, vol. 19, no. 4, p. 4453, 2024
work page 2024
-
[25]
Fluency bank: A new re- source for fluency research and practice,
N. Bernstein Ratner and B. MacWhinney, “Fluency bank: A new re- source for fluency research and practice,”Journal of Fluency Disorders, vol. 56, pp. 69–80, 2018
work page 2018
-
[26]
T. Kourkounakis, A. Hajavi, and A. Etemad, “Detecting multiple speech disfluencies using a deep residual network with bidirectional long short- term memory,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 6089–6093
work page 2020
-
[27]
E. Boughariou, Y . Bahou, and L. H. Belguith, “Detecting speech disor- ders using a machine-learning guided method in spontaneous tunisian dialect speech,”SN Computer Science, vol. 5, no. 5, Apr. 2024
work page 2024
-
[28]
Speech disfluency detection with contextual representation and data distillation,
P. Mohapatra, A. Pandey, B. Islam, and Q. Zhu, “Speech disfluency detection with contextual representation and data distillation,” inPro- ceedings of the 1st ACM International Workshop on Intelligent Acoustic Systems and Applications, ser. IASA ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 19–24
work page 2022
-
[29]
J. Liu, A. Wumaier, D. Wei, and S. Guo, “Automatic speech disfluency detection using wav2vec2.0 for different languages with variable lengths,”Applied Sciences, vol. 13, no. 13, 2023. [Online]. Available: https://www.mdpi.com/2076-3417/13/13/7579
work page 2023
-
[30]
Whisper in focus: En- hancing stuttered speech classification with encoder layer optimization,
H. Ameer, S. Latif, R. Latif, and S. Mukhtar, “Whisper in focus: En- hancing stuttered speech classification with encoder layer optimization,” 2023
work page 2023
-
[31]
Mfcc and its applications in speaker recognition,
V . Tiwari, “Mfcc and its applications in speaker recognition,”
-
[32]
Available: https://api.semanticscholar.org/CorpusID: 212584631
[Online]. Available: https://api.semanticscholar.org/CorpusID: 212584631
-
[33]
MFCC in audio signal processing for voice disorder: a review,
M. S. Sidhu, N. A. A. Latib, and K. K. Sidhu, “MFCC in audio signal processing for voice disorder: a review,”Multimed. Tools Appl., 2024
work page 2024
-
[34]
Automatic detection of alzheimers disease using spontaneous speech only,
J. Chen, J. Ye, F. Tang, and J. Zhou, “Automatic detection of alzheimers disease using spontaneous speech only,” inInterspeech 2021. ISCA, Aug. 2021
work page 2021
-
[35]
Emotion Recognition from Speech Using wav2vec 2.0 Embeddings,
L. Pepino, P. Riera, and L. Ferrer, “Emotion Recognition from Speech Using wav2vec 2.0 Embeddings,” inProc. Interspeech 2021, 2021, pp. 3400–3404
work page 2021
-
[36]
Dawn of the transformer era in speech emotion recognition: closing the valence gap,
J. Wagner, A. Triantafyllopoulos, H. Wierstorf, M. Schmitt, F. Burkhardt, F. Eyben, and B. W. Schuller, “Dawn of the transformer era in speech emotion recognition: closing the valence gap,” 2022. [Online]. Available: https://arxiv.org/abs/2203.07378
-
[37]
Improving domain general- ization in speech emotion recognition with whisper,
E. Goron, L. Asai, E. Rut, and M. Dinov, “Improving domain general- ization in speech emotion recognition with whisper,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 11 631–11 635
work page 2024
-
[38]
Ser evals: In-domain and out-of-domain benchmarking for speech emotion recognition,
M. Osman, D. Z. Kaplan, and T. Nadeem, “Ser evals: In-domain and out-of-domain benchmarking for speech emotion recognition,” 2024. [Online]. Available: https://arxiv.org/abs/2408.07851
-
[39]
Pseudo-labeling and confirmation bias in deep semi-supervised learning,
E. Arazo, D. Ortego, P. Albert, N. E. O’Connor, and K. McGuinness, “Pseudo-labeling and confirmation bias in deep semi-supervised learning,” 2020. [Online]. Available: https://arxiv.org/abs/1908.02983
-
[40]
D., Kurakin, A., Zhang, H., and Raffel, C
K. Sohn, D. Berthelot, C.-L. Li, Z. Zhang, N. Carlini, E. D. Cubuk, A. Kurakin, H. Zhang, and C. Raffel, “Fixmatch: Simplifying semi-supervised learning with consistency and confidence,” 2020. [Online]. Available: https://arxiv.org/abs/2001.07685
-
[41]
Maximum likelihood estimation of observer error-rates using the em algorithm,
A. P. Dawid and A. M. Skene, “Maximum likelihood estimation of observer error-rates using the em algorithm,”Journal of the Royal Statistical Society: Series C (Applied Statistics), vol. 28, no. 1, pp. 20– 28, 1979
work page 1979
-
[42]
T. Sainburg, “timsainb/noisereduce: v1.0,” Jun. 2019. [Online]. Available: https://doi.org/10.5281/zenodo.3243139
-
[43]
Opensmile: the munich versatile and fast open-source audio feature extractor,
F. Eyben, M. W ¨ollmer, and B. Schuller, “Opensmile: the munich versatile and fast open-source audio feature extractor,” inProceedings of the 18th ACM International Conference on Multimedia, ser. MM ’10. NY , USA: Association for Computing Machinery, 2010, p. 1459–1462
work page 2010
-
[44]
The influence of dataset partitioning on dysfluency detection systems,
S. P. Bayerl, D. Wagner, E. N ¨oth, T. Bocklet, and K. Riedhammer, “The influence of dataset partitioning on dysfluency detection systems,” inText, Speech, and Dialogue, P. Sojka, A. Hor ´ak, I. Kope ˇcek, and K. Pala, Eds. Springer International Publishing, 2022, pp. 423–436
work page 2022
-
[45]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”
-
[46]
Decoupled Weight Decay Regularization
[Online]. Available: https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,”PLOS ONE, vol. 13, no. 5, 2018
work page 2018
-
[48]
Surrey Audio-Visual Expressed Emotion (SAVEE) Database,
P. Jackson and S. Haq, “Surrey Audio-Visual Expressed Emotion (SAVEE) Database,” http://kahlan.eps.surrey.ac.uk/savee/Database.html
-
[49]
Toronto emotional speech set (TESS),
M. K. Pichora-Fuller and K. Dupuis, “Toronto emotional speech set (TESS),” 2020
work page 2020
-
[50]
Arushi, R. Dillon, and A. N. Teoh, “Real-time stress detection model and voice analysis: An integrated vr-based game for training public speaking skills,” in2021 IEEE Conference on Games (CoG), 2021, pp. 1–4
work page 2021
-
[51]
Performance evaluation of different speech-based emotional stress level detection approaches,
J. Sta ˇs, S. Ond ´aˇs, and J. Juh ´ar, “Performance evaluation of different speech-based emotional stress level detection approaches,” IEEE Access, vol. 13, p. 112880–112904, 2025. [Online]. Available: http://dx.doi.org/10.1109/ACCESS.2025.3584534
-
[52]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” 2017
work page 2017
-
[53]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”
-
[54]
Adam: A Method for Stochastic Optimization
[Online]. Available: https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” inAdvances in Neural Information Processing Systems 30, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds. Curran Associates, Inc., 2017, pp. 4765–4774
work page 2017
-
[56]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
work page 2021
-
[57]
Wavlm: Large-scale self-supervised pre- training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre- training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, p. 1505–1518, Oct. 2022
work page 2022
-
[58]
The look of (un)confidence: Visual markers for inferring speaker confidence in speech,
Y . Mori and M. D. Pell, “The look of (un)confidence: Visual markers for inferring speaker confidence in speech,”Frontiers in Communication, vol. 4, Nov. 2019. VII. BIOGRAPHYSECTION Adam Wynnis a PhD student in the Department of Computer Science at Durham University. He is interested in AI in education, automatic feedback, adaptive learning and educationa...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.