Recognition: no theorem link
Events as Triggers for Behavioral Diversity in Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-13 03:43 UTC · model grok-4.3
The pith
Events decouple agent identities from behaviors in multi-agent reinforcement learning, enabling precise role changes while preserving reward maximization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
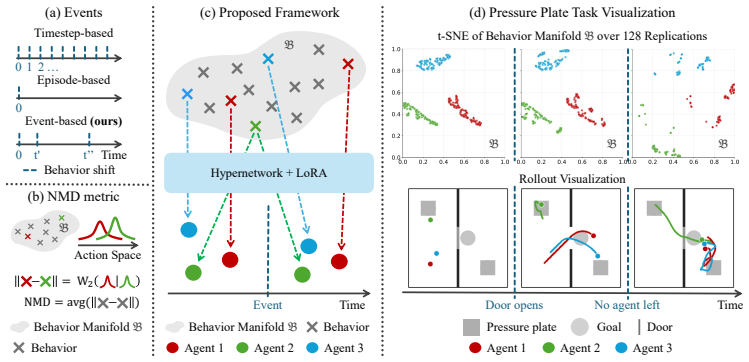
Events serve as triggers that let agents instantiate behaviors from a manifold without fixed identity bindings. An event-based hypernetwork generates LoRA modules over a shared team policy to enable immediate policy reconfiguration. Neural Manifold Diversity supplies a well-defined distance for these transient behaviors. The overall design guarantees that diversity supports reward maximization rather than interfering with it.
What carries the argument
Event-based hypernetwork generating Low-Rank Adaptation (LoRA) modules over a shared team policy, together with the Neural Manifold Diversity (NMD) metric for transient agent-agnostic behaviors.
If this is right
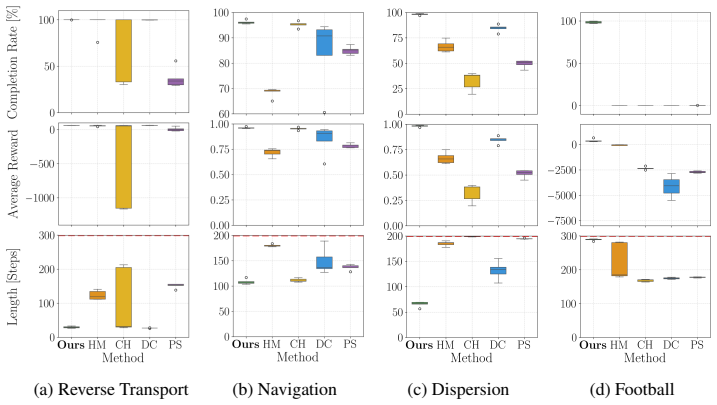
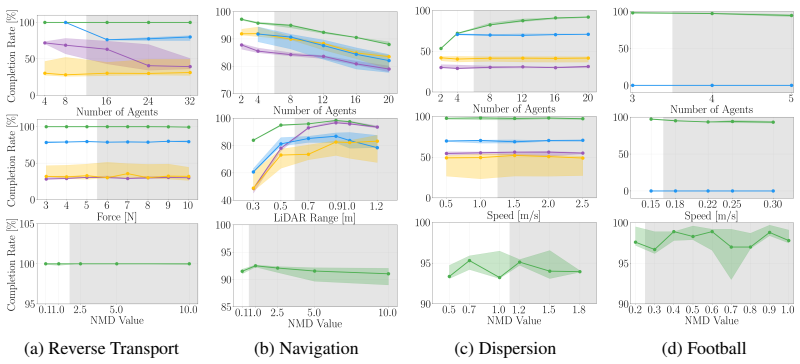
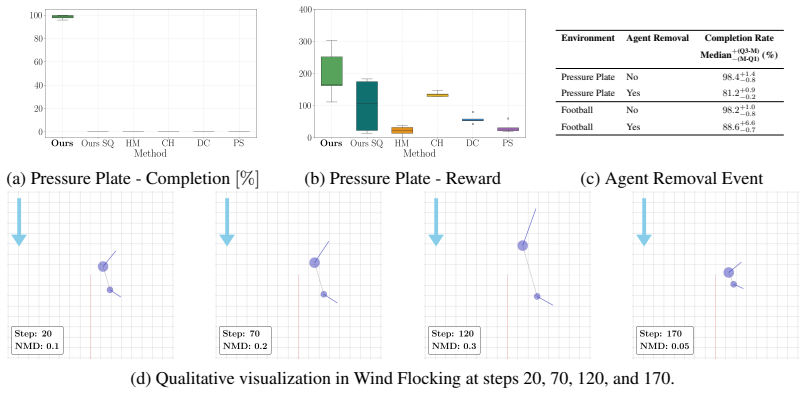
- The framework outperforms established baselines on multiple benchmarks.
- It achieves zero-shot generalization to unseen tasks.
- It is the only tested method that solves tasks requiring agents to reassign behaviors in sequence.
- Diversity is guaranteed by construction not to reduce reward maximization.
Where Pith is reading between the lines
- The same event-driven manifold could be tested in single-agent settings where internal state changes require policy switches.
- Scaling the approach to larger teams might reveal whether event detection remains tractable without central coordination.
- Physical robot experiments could check whether sensor-based events substitute for the simulated qualitative changes used here.
Load-bearing premise
Events can be reliably defined and detected as qualitative state changes that induce task-relevant behavioral transitions, and the Neural Manifold Diversity metric stays meaningful for short-lived behaviors not tied to specific agents.
What would settle it
A controlled test in which the manually supplied events do not align with the moments when agents must change roles, or in which applying the NMD metric produces measurable drops in team reward on tasks the proof claims to protect.
Figures


read the original abstract
Effective multi-agent cooperation requires agents to adopt diverse behaviors as task conditions evolve-and to do so at the right moment. Yet, current Multi-Agent Reinforcement Learning (MARL) frameworks that facilitate this diversity are still limited by the fact that they bind fixed behaviors to fixed agent identities. Consequently, they are ill-equipped for tasks where agents need to take on different roles at very specific moments in time. We argue that, to define these behavioral transitions, the missing ingredient is $\textbf{events}$. Events are changes in the state of the system that induce qualitative changes in the task. Based on this view, we introduce a framework that decouples agent identity from behavior, capturing a continuous manifold from which agents instantiate their behaviors in response to events. This framework is based on two elements. First, to build an expressive behavior manifold, we introduce Neural Manifold Diversity (NMD), a formal distance metric that remains well-defined when behaviors are transient and agent-agnostic. Second, we use an event-based hypernetwork that generates Low-Rank Adaptation (LoRA) modules over a shared team policy, enabling on-the-fly agent-policy reconfiguration in response to events. We prove that this construction ensures that diversity does not interfere with reward maximization by design. Empirical results demonstrate that our framework outperforms established baselines across benchmarks while exhibiting zero-shot generalization, and being the only method that solves tasks requiring sequential behavior reassignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an event-triggered framework for multi-agent reinforcement learning that decouples agent identity from behavior to enable dynamic role reassignment. It defines events as qualitative state changes inducing task-relevant behavioral transitions, constructs a continuous behavior manifold via Neural Manifold Diversity (NMD) as a formal distance metric for transient, agent-agnostic behaviors, and employs an event-based hypernetwork to generate LoRA modules over a shared team policy for on-the-fly reconfiguration. The authors prove that this construction ensures diversity injection does not interfere with reward maximization by design, and report empirical outperformance over baselines on benchmarks, zero-shot generalization, and unique success on tasks requiring sequential behavior reassignment.
Significance. If the central claims hold, the work addresses a genuine limitation in existing MARL diversity methods that tie behaviors to fixed agent identities, enabling more flexible cooperation in evolving tasks. The 'by design' separation of diversity from optimality and the NMD metric for transient behaviors represent potentially useful technical contributions, particularly if the proof is rigorous and the metric satisfies the required properties without hidden dependencies.
major comments (2)
- [Proof section (likely §4, Theorem on reward preservation)] The proof that the event-based hypernetwork + LoRA construction 'ensures that diversity does not interfere with reward maximization by design' (abstract and likely §4) rests on the unverified conditions that events are reliably detectable as qualitative changes triggering exactly the intended transitions and that NMD is a well-defined metric on short-lived, agent-agnostic trajectories. If event signals are noisy or ambiguous, or if NMD fails to satisfy metric properties (e.g., triangle inequality) for transient policies, the separation guarantee no longer follows by construction, undermining the claim that the framework solves sequential reassignment tasks.
- [§2 (definitions of events and NMD)] §2 (or wherever events and NMD are formalized): The definition of events as 'changes in the state of the system that induce qualitative changes in the task' and the claim that NMD 'remains well-defined when behaviors are transient and agent-agnostic' require explicit construction showing that NMD reduces to a true distance without implicit parameter dependencies or agent-specific assumptions. The abstract provides no derivation details, so the load-bearing step from manifold construction to the optimality guarantee cannot be verified.
minor comments (2)
- [Abstract and experimental section] The abstract states empirical superiority and zero-shot generalization but provides no details on experimental setup, benchmarks, or statistical significance; these should be expanded with specific tables or figures in the main text for reproducibility.
- [Method section (hypernetwork description)] Notation for the hypernetwork and LoRA generation should be clarified with an equation or diagram showing how events map to specific LoRA parameters without affecting the shared policy's optimality.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of the formal guarantees and definitions. We address each major comment below, clarifying the existing proofs and constructions in the manuscript while proposing targeted revisions for additional explicitness and robustness discussion.
read point-by-point responses
-
Referee: [Proof section (likely §4, Theorem on reward preservation)] The proof that the event-based hypernetwork + LoRA construction 'ensures that diversity does not interfere with reward maximization by design' (abstract and likely §4) rests on the unverified conditions that events are reliably detectable as qualitative changes triggering exactly the intended transitions and that NMD is a well-defined metric on short-lived, agent-agnostic trajectories. If event signals are noisy or ambiguous, or if NMD fails to satisfy metric properties (e.g., triangle inequality) for transient policies, the separation guarantee no longer follows by construction, undermining the claim that the framework solves sequential reassignment tasks.
Authors: The theorem in §4 establishes the separation by construction under the framework's definitions: the shared base policy is optimized solely for reward, while the event-triggered hypernetwork produces LoRA modules that act as transient, additive adaptations without modifying the base parameters or gradients. This ensures diversity injection is orthogonal to the optimality objective by design, independent of specific event realizations. We acknowledge that practical event detection may involve noise; the manuscript assumes events are detected as qualitative state changes per the problem setup (common in event-triggered control). We will add a dedicated paragraph in §4 and the discussion section addressing robustness to noisy or ambiguous events, including a simple threshold-based detector and sensitivity analysis. For NMD, the appendix contains the full proof that it satisfies metric axioms (including triangle inequality) on transient, agent-agnostic trajectory segments via the neural embedding; a summary of this verification will be moved into the main text of §2 for accessibility. revision: partial
-
Referee: [§2 (definitions of events and NMD)] §2 (or wherever events and NMD are formalized): The definition of events as 'changes in the state of the system that induce qualitative changes in the task' and the claim that NMD 'remains well-defined when behaviors are transient and agent-agnostic' require explicit construction showing that NMD reduces to a true distance without implicit parameter dependencies or agent-specific assumptions. The abstract provides no derivation details, so the load-bearing step from manifold construction to the optimality guarantee cannot be verified.
Authors: Section 2 provides the explicit formalization: events are defined as state transitions crossing task-specific qualitative thresholds (with a mathematical characterization as discontinuities in the task reward landscape), and NMD is constructed as the geodesic distance on a learned behavior manifold embedded via a neural network, with the distance defined as the integral of a positive-definite kernel over short trajectory segments. This construction is deliberately agent-agnostic and independent of policy parameters by using only state-action distributions; the appendix derives that it reduces to a true metric (non-negativity, symmetry, triangle inequality) without hidden dependencies. The optimality guarantee in §4 follows directly from this metric property combined with the hypernetwork's parameter separation. While the abstract is necessarily concise, the body and appendix contain the full derivations. We will revise §2 to include a self-contained one-paragraph summary of the metric proof and add a forward reference from the abstract to these sections. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The paper defines NMD as a new formal distance metric for transient agent-agnostic behaviors and introduces an event-triggered hypernetwork generating LoRA modules over a shared policy. The central claim of proving non-interference with reward maximization 'by design' is presented as following from the architectural separation of diversity injection from the base policy optimization, rather than from any fitted parameter, self-citation chain, or renaming of prior results. No load-bearing step in the provided abstract or described framework reduces an output to its inputs by construction; the derivation remains self-contained with independent mathematical and empirical content.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Reinforcement learning environments are modeled as Markov decision processes where agents maximize expected cumulative reward.
- domain assumption Events are observable changes in system state that induce qualitative shifts in the task requiring behavioral transitions.
invented entities (2)
-
Neural Manifold Diversity (NMD)
no independent evidence
-
Event-based hypernetwork
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.