Recognition: no theorem link
Detecting overfitting in Neural Networks during long-horizon grokking using Random Matrix Theory
Pith reviewed 2026-05-13 05:20 UTC · model grok-4.3
The pith
Overfitting during long-horizon grokking appears as growing Correlation Traps in layer weights that random matrix theory can detect without any data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
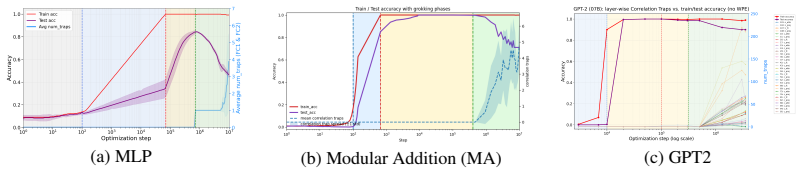
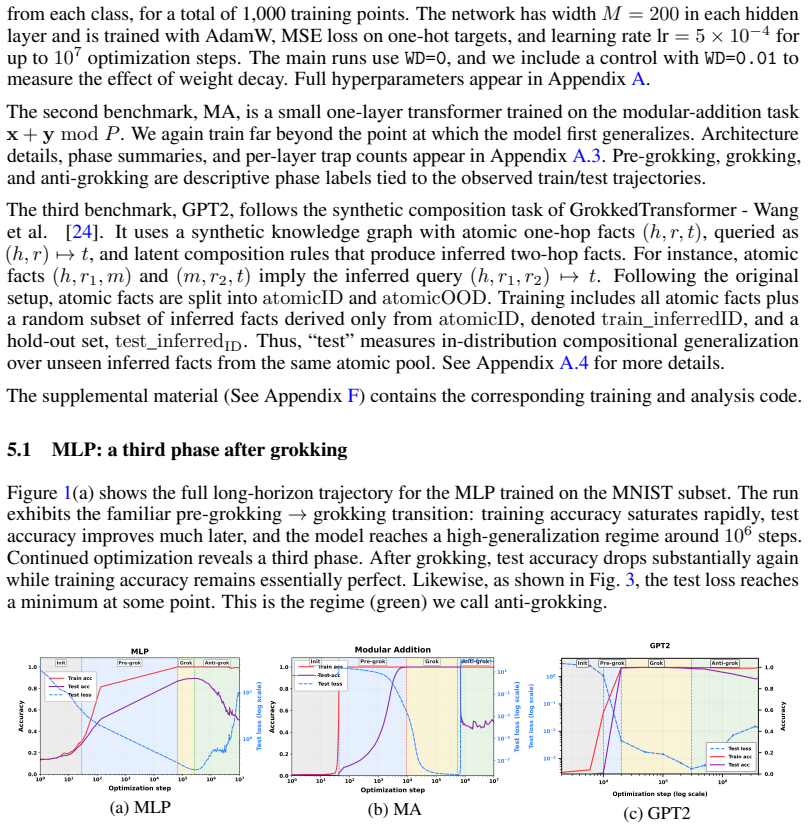
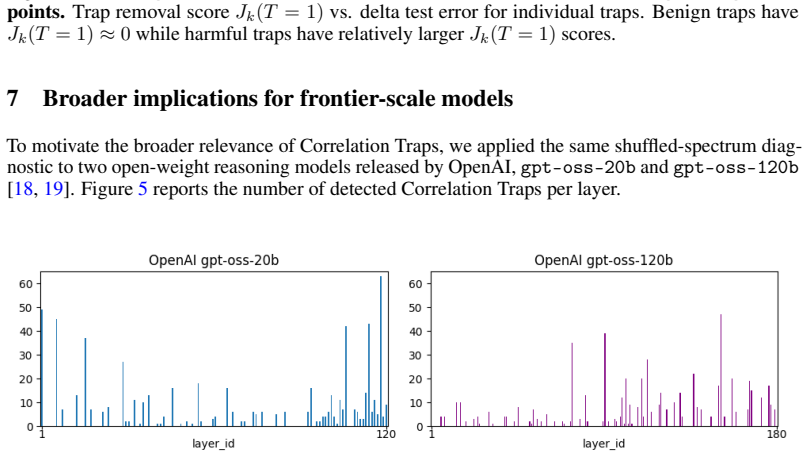
During the anti-grokking phase of long-horizon grokking—where training accuracy stays high while test accuracy falls—element-wise randomization of each layer weight matrix produces empirical spectral distributions that develop large outliers relative to a Marchenko-Pastur fit; these outliers, termed Correlation Traps, increase in number and magnitude as generalization degrades. The traps are structurally absent in the earlier pre-grokking phase. Passing random data through the trained model and computing Jensen-Shannon divergence between output logit distributions distinguishes benign traps from those that degrade test performance. Foundation-scale LLMs exhibit analogous outliers.
What carries the argument
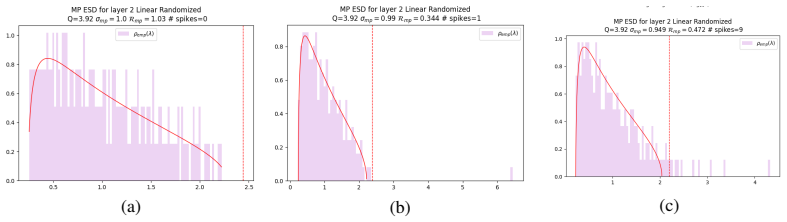
Correlation Traps, defined as large outliers in the empirical spectral distribution of an element-wise randomized weight matrix that violate the self-averaging property of a Marchenko-Pastur fit, which track the buildup of correlations responsible for overfitting.
If this is right
- Anti-grokking constitutes a distinct training phase separate from pre-grokking, identifiable solely from weight spectra.
- Overfitting can be monitored layer by layer during training without ever accessing train or test examples.
- Jensen-Shannon divergence on random inputs provides an empirical test to decide whether detected traps are harmful.
- The same spectral signature appears in some foundation-scale LLMs, indicating the mechanism may operate at large scale.
- Structural absence of traps before grokking and their growth afterward distinguishes benign from harmful weight evolution.
Where Pith is reading between the lines
- Periodic checks for trap formation could be inserted into training loops to trigger early stopping or regularization before test accuracy collapses.
- If traps prove causal, weight-update rules that penalize large outliers in the randomized spectrum might shorten or eliminate the anti-grokking interval.
- The method offers a route to compare generalization dynamics across architectures by counting trap statistics rather than relying on held-out data.
- Detecting traps in already-deployed models might flag latent overfitting even when current test sets no longer reveal it.
Load-bearing premise
Large spectral outliers relative to a Marchenko-Pastur fit on randomized weights reliably mark the formation of correlations that cause overfitting rather than arising for unrelated reasons.
What would settle it
Train a network through the anti-grokking regime, confirm that test accuracy has declined, yet find that the randomized weight spectra show no outliers above the Marchenko-Pastur bulk edge.
Figures

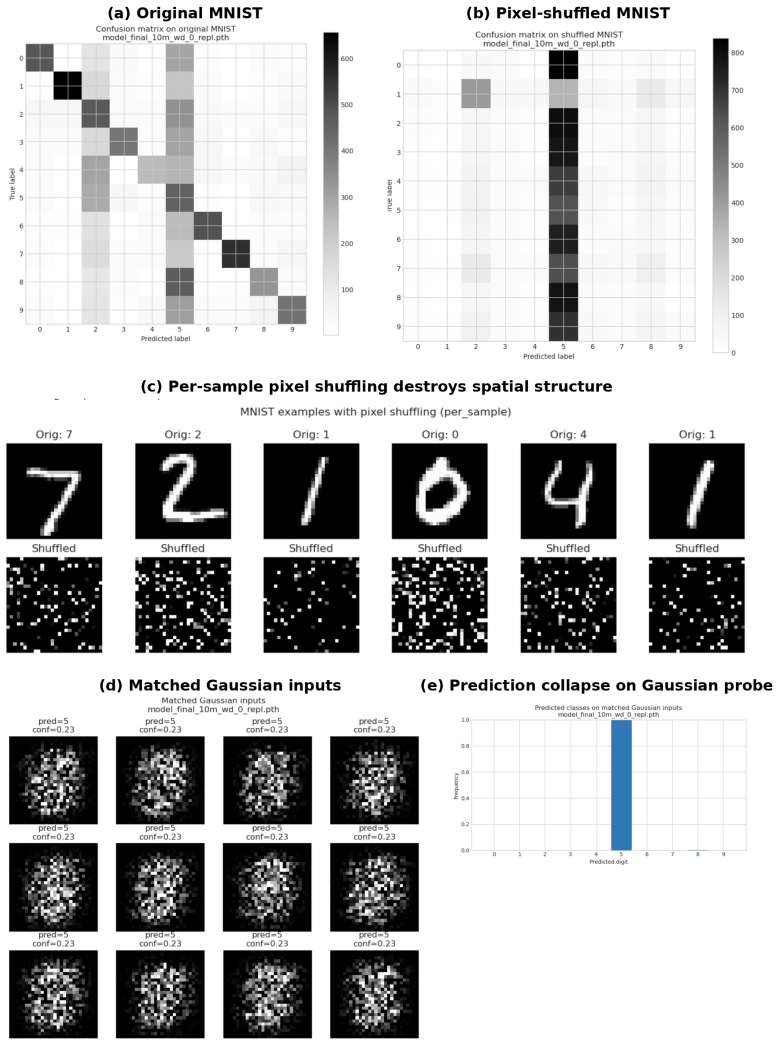
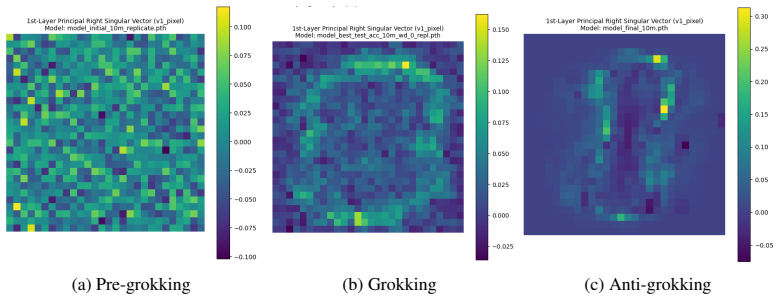



read the original abstract
Training Neural Networks (NNs) without overfitting is difficult; detecting that overfitting is difficult as well. We present a novel Random Matrix Theory method that detects the onset of overfitting in deep learning models without access to train or test data. For each model layer, we randomize each weight matrix element-wise, $\mathbf{W} \to \mathbf{W}_{\mathrm{rand}}$, fit the randomized empirical spectral distribution with a Marchenko-Pastur distribution, and identify large outliers that violate self-averaging. We call these outliers Correlation Traps. During the onset of overfitting, which we call the "anti-grokking" phase in long-horizon grokking, Correlation Traps form and grow in number and scale as test accuracy decreases while train accuracy remains high. Traps may be benign or may harm generalization; we provide an empirical approach to distinguish between them by passing random data through the trained model and evaluating the JS divergence of output logits. Our findings show that anti-grokking is an additional grokking phase with high train accuracy and decreasing test accuracy, structurally distinct from pre-grokking through its Correlation Traps. More broadly, we find that some foundation-scale LLMs exhibit the same Correlation Traps, indicating potentially harmful overfitting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Random Matrix Theory method to detect overfitting in neural networks during long-horizon grokking without access to train or test data. For each layer, weights are randomized element-wise to W_rand, the empirical spectral distribution is fit to a Marchenko-Pastur law, and large outliers violating self-averaging are identified as 'Correlation Traps.' These traps are claimed to form and grow during an 'anti-grokking' phase (high train accuracy, falling test accuracy), with JS divergence on random inputs used to label them benign or harmful; similar traps are reported in some foundation-scale LLMs.
Significance. If the empirical claims are substantiated, the work could supply a data-free diagnostic for overfitting and a new lens on grokking phases via spectral outliers. The RMT framing and the proposed distinction between benign/harmful traps are conceptually interesting, but the absence of quantitative validation, baselines, or causal tests limits immediate impact.
major comments (4)
- [Abstract and Experimental Results] The abstract and method description supply no quantitative results, baselines, error bars, or validation experiments, rendering it impossible to judge whether the observed growth of outliers actually tracks the anti-grokking phase or supports the central claim.
- [Method (randomization and MP fitting procedure)] The Marchenko-Pastur fit is performed on the same randomized matrices whose outliers are then declared 'Correlation Traps'; without explicit details on parameter estimation (variance, aspect ratio) or threshold choice, the diagnostic risks circularity and being partly defined by the data it diagnoses.
- [Results and Discussion] The manuscript reports that outliers appear in tandem with the accuracy curves and that JS divergence on random inputs can label traps, yet no intervention (e.g., targeted regularization of the outlier subspace) is shown to alter the test-accuracy trajectory, leaving the causal status of the traps unestablished.
- [JS divergence classification subsection] The claim that JS divergence on unstructured random inputs reliably distinguishes harmful from benign traps assumes that such inputs expose the relevant feature correlations; this is plausible but unproven for the structured data on which generalization actually fails.
minor comments (2)
- [Method] Notation for W_rand and the precise definition of 'large outliers' should be formalized with an equation or algorithm box for reproducibility.
- [LLM experiments] The extension to LLMs would benefit from specifying model names, layer indices, and quantitative outlier counts rather than the qualitative statement 'some foundation-scale LLMs exhibit the same Correlation Traps.'
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below, clarifying aspects of the work and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The abstract and method description supply no quantitative results, baselines, error bars, or validation experiments, rendering it impossible to judge whether the observed growth of outliers actually tracks the anti-grokking phase or supports the central claim.
Authors: We acknowledge that the abstract is high-level and omits specific numbers. The full manuscript contains figures and descriptions documenting the growth of Correlation Traps alongside accuracy curves across multiple models and runs. In revision we will expand the abstract with key quantitative observations (e.g., average increase in outlier count and magnitude during anti-grokking), add error bars from repeated trials to the experimental figures, and include a brief baseline comparison against standard overfitting indicators. revision: yes
-
Referee: [Method (randomization and MP fitting procedure)] The Marchenko-Pastur fit is performed on the same randomized matrices whose outliers are then declared 'Correlation Traps'; without explicit details on parameter estimation (variance, aspect ratio) or threshold choice, the diagnostic risks circularity and being partly defined by the data it diagnoses.
Authors: We appreciate the referee noting the risk of circularity. The procedure randomizes weights element-wise to obtain a reference spectrum that is fitted to the Marchenko-Pastur law (estimating aspect ratio q and variance σ² from the randomized matrix), after which outliers are identified in the spectrum of the original weight matrix as deviations beyond the fitted bulk edge. This separation prevents circularity. We will revise the method section to provide explicit formulas for parameter estimation and the precise outlier threshold rule (e.g., MP edge plus a fixed multiple of the bulk standard deviation). revision: yes
-
Referee: [Results and Discussion] The manuscript reports that outliers appear in tandem with the accuracy curves and that JS divergence on random inputs can label traps, yet no intervention (e.g., targeted regularization of the outlier subspace) is shown to alter the test-accuracy trajectory, leaving the causal status of the traps unestablished.
Authors: The manuscript presents the alignment between trap emergence and accuracy degradation as an observational diagnostic signal rather than a causal claim. We agree that intervention experiments would be needed to establish causality and will add an explicit limitations paragraph in the discussion stating the correlational nature of the current evidence while outlining targeted regularization of the outlier subspace as a concrete direction for future work. revision: partial
-
Referee: [JS divergence classification subsection] The claim that JS divergence on unstructured random inputs reliably distinguishes harmful from benign traps assumes that such inputs expose the relevant feature correlations; this is plausible but unproven for the structured data on which generalization actually fails.
Authors: This is a valid point about the proxy. Random inputs are used to obtain a data-free probe of output statistics. We will revise the subsection to include a clearer justification of the choice, discuss its limitations as a proxy for structured data, and add a short sensitivity analysis using mildly perturbed structured inputs where feasible. revision: yes
- Establishing causality via intervention experiments (e.g., regularizing the outlier subspace and measuring resulting test-accuracy changes) would require new empirical work outside the scope of the present submission.
Circularity Check
No significant circularity in the derivation or detection method.
full rationale
The paper's core procedure randomizes weight matrices element-wise to obtain W_rand, fits a Marchenko-Pastur law to its empirical spectral distribution, and flags large outliers relative to that fit as Correlation Traps. These outliers are then observed to appear and grow in tandem with the anti-grokking phase (high train accuracy, falling test accuracy). This is an empirical correlation between an RMT-derived statistic on the weights and separately measured accuracy curves; the definition of the traps is not constructed from the accuracy labels, nor is any claimed prediction equivalent to the fitted parameters by construction. The JS-divergence test on random inputs is likewise an independent empirical probe. No load-bearing self-citation, uniqueness theorem, or ansatz imported from prior author work appears in the provided text, and the method remains self-contained against external RMT benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Marchenko-Pastur fit parameters (variance, aspect ratio)
axioms (1)
- domain assumption Element-wise randomized weight matrices obey the Marchenko-Pastur law
invented entities (2)
-
Correlation Traps
no independent evidence
-
anti-grokking phase
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amit, Hanoch Gutfreund, and Haim Sompolinsky
Daniel J. Amit, Hanoch Gutfreund, and Haim Sompolinsky. Spin-glass models of neural networks.Physical Review A, 32(2):1007–1018, 1985. doi: 10.1103/PhysRevA.32.1007
-
[2]
Philip W. Anderson. Absence of diffusion in certain random lattices.Physical Review, 109(5): 1492–1505, 1958. doi: 10.1103/PhysRev.109.1492
-
[3]
Jinho Baik, Gérard Ben Arous, and Sandrine Péché. Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices.The Annals of Probability, 33(5):1643–1697, 2005
work page 2005
-
[4]
Siegfried Bös. Statistical mechanics approach to early stopping and weight decay.Physical Review E, 58(1):833–847, 1998. doi: 10.1103/PhysRevE.58.833
-
[5]
Plancks Gesetz und Lichtquantenhypothese.Zeitschrift für Physik, 26(1): 178–181, 1924
Satyendra Nath Bose. Plancks Gesetz und Lichtquantenhypothese.Zeitschrift für Physik, 26(1): 178–181, 1924. doi: 10.1007/BF01327326
-
[6]
Albert Einstein. Quantentheorie des einatomigen idealen Gases.Sitzungsberichte der Preussis- chen Akademie der Wissenschaften, pages 3–14, 1925
work page 1925
-
[7]
E. Gardner. The space of interactions in neural network models.Journal of Physics A: Mathematical and General, 21(1):257–270, 1988. doi: 10.1088/0305-4470/21/1/030
-
[8]
John J. Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982. doi: 10.1073/pnas.79.8.2554
-
[9]
Grokfast: Accelerated grokking by amplifying slow gradients, 2024
Jaerin Lee, Bong Gyun Kang, Kihoon Kim, and Kyoung Mu Lee. Grokfast: Accelerated grokking by amplifying slow gradients, 2024. URL https://arxiv.org/abs/2405.20233
-
[10]
Jiping Li and Rishi Sonthalia. Risk phase transitions in spiked regression: Alignment driven benign and catastrophic overfitting.arXiv preprint arXiv:2510.01414, 2025
-
[11]
Ziming Liu, Ouail Kitouni, Niklas S. Nolte, Eric J. Michaud, Max Tegmark, and Mike Williams. Towards understanding grokking: An effective theory of representation learning. InAdvances in Neural Information Processing Systems, volume 35, pages 34651–34663. Curran Associates, Inc., 2022. URLhttps://arxiv.org/abs/2205.10343
-
[12]
Marchenko and Leonid Andreevich Pastur
Vladimir A. Marchenko and Leonid Andreevich Pastur. Distribution of eigenvalues for some sets of random matrices.Matematicheskii Sbornik, 72(114)(4):507–536, 1967
work page 1967
-
[13]
Charles H. Martin. WeightWatcher: Analyze Deep Learning Models without Training or Data. https://github.com/CalculatedContent/WeightWatcher, 2018-2024. Version 0.7.5.5 used in this study. Accessed May 12, 2025
work page 2018
-
[14]
Martin and Christopher Hinrichs
Charles H. Martin and Christopher Hinrichs. SETOL: A semi-empirical theory of (deep) learning.arXiv preprint arXiv:2507.17912, 2025. URL https://arxiv.org/abs/2507. 17912
-
[15]
Charles H. Martin and Michael W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(1):165, January 2021. URL http://jmlr.org/papers/ v22/20-410.html. 10
work page 2021
-
[16]
Martin, Tian Peng, and Michael W
Charles H. Martin, Tian Peng, and Michael W. Mahoney. Predicting trends in the quality of state- of-the-art neural networks without access to training or testing data.Nature Communications, 12:4122, jul 2021. doi: 10.1038/s41467-021-24025-8. URL https://doi.org/10.1038/ s41467-021-24025-8
-
[17]
Progress measures for grokking via mechanistic interpretability,
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability, 2023. URL https://arxiv.org/ abs/2301.05217
-
[18]
OpenAI. Introducing gpt-oss. https://openai.com/index/introducing-gpt-oss/, Au- gust 2025. Accessed: 2026-03-28
work page 2025
-
[19]
gpt-oss-120b & gpt-oss-20b model card
OpenAI. gpt-oss-120b & gpt-oss-20b model card. https://openai.com/index/ gpt-oss-model-card/, August 2025. Accessed: 2026-03-28
work page 2025
-
[20]
C. E. Porter and R. G. Thomas. Fluctuations of nuclear reaction widths.Physical Review, 104 (2):483–491, 1956
work page 1956
-
[21]
Cambridge University Press, 2021
Marc Potters and Jean-Philippe Bouchaud.A First Course in Random Matrix Theory: F or Physi- cists, Engineers and Data Scientists. Cambridge University Press, 2021. ISBN 9781108768900
work page 2021
-
[22]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. URL https://arxiv. org/abs/2201.02177
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Sebastian Seung, Haim Sompolinsky, and Naftali Tishby
H. Sebastian Seung, Haim Sompolinsky, and Naftali Tishby. Statistical mechanics of learning from examples.Physical Review A, 45(8):6056–6091, 1992. doi: 10.1103/PhysRevA.45.6056
-
[24]
Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun. Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://arxiv.org/pdf/2405.15071
-
[25]
train” curve for inferred facts test_inferredID No Main “test
Pierre Weiss. L’hypothèse du champ moléculaire et la propriété ferromagnétique.Jour- nal de Physique Théorique et Appliquée, 6(1):661–690, 1907. doi: 10.1051/jphystap: 019070060066100. 11 A Experimental Setup and Additional Notes: MLP, MA, and GPT2 A.1 MLP Experimental Setup We train a Multi-Layer Perceptron (MLP) on a subset of the MNIST dataset using th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.