Recognition: 2 theorem links
· Lean TheoremNCCLZ: Compression-Enabled GPU Collectives with Decoupled Quantization and Entropy Coding
Pith reviewed 2026-05-13 03:23 UTC · model grok-4.3
The pith
Decoupling quantization from entropy coding lets GPU collectives compress data at the interface and embed coding inside NCCL primitives for better overlap and speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
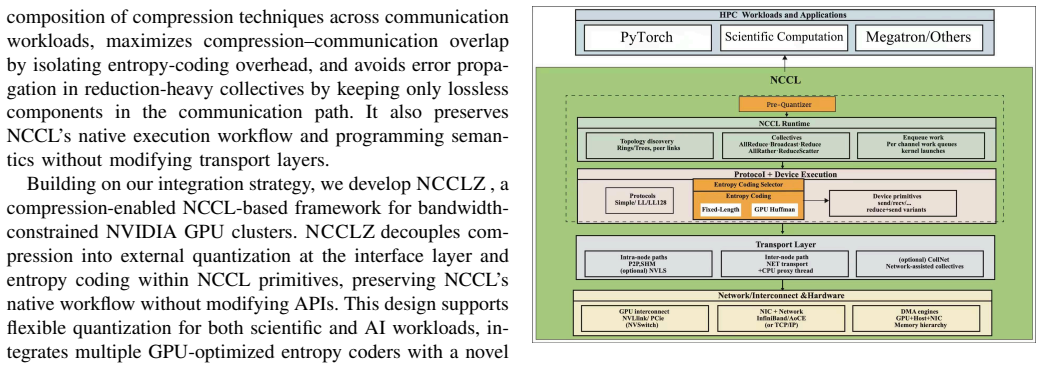
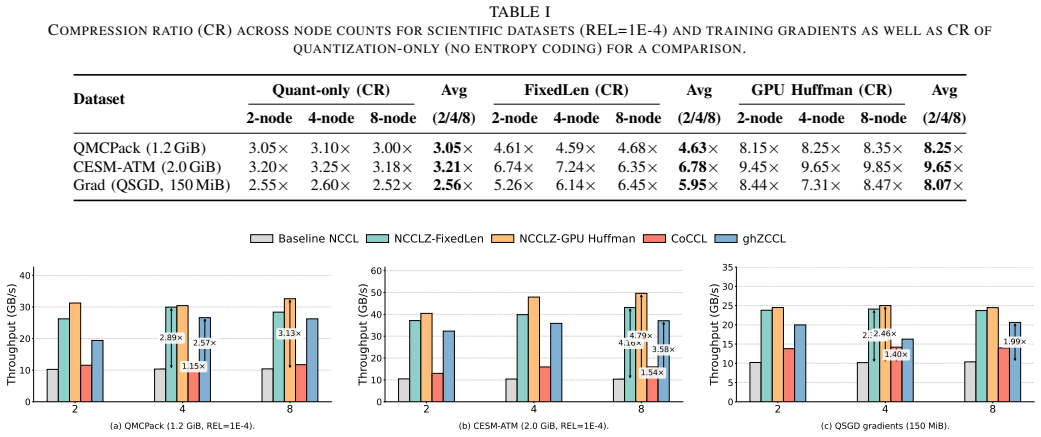
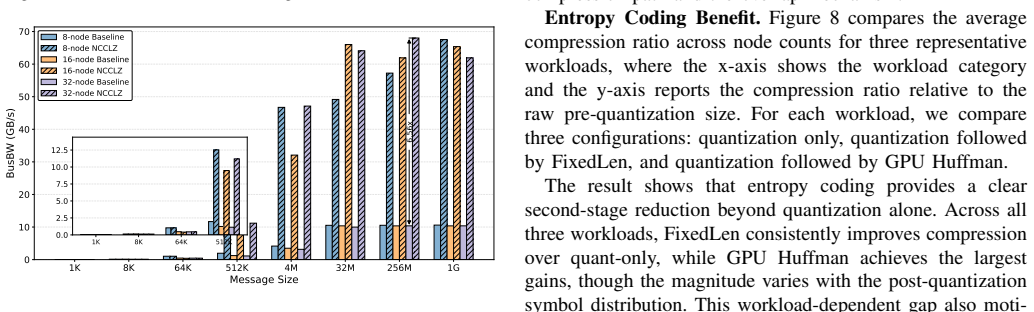
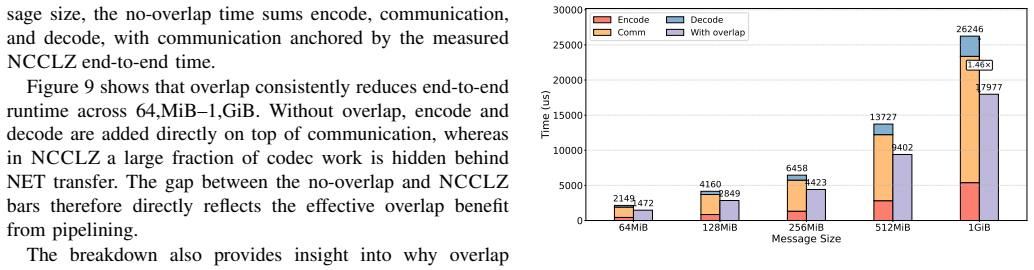
NCCLZ decouples quantization and entropy coding in GPU collectives by placing quantization at the interface, embedding entropy coding into NCCL primitives, using a lightweight device-side selector to choose coding strategies at runtime, and overlapping compression with communication, which yields up to 9.65 times speedup over plain NCCL and up to 3.34 times improvement over earlier compression-assisted libraries on scientific datasets, training gradients, and synthetic workloads.
What carries the argument
Decoupled quantization at the interface layer and entropy coding embedded inside NCCL primitives, driven by a device-side strategy selector
If this is right
- Large inter-node messages in scientific and deep-learning workloads spend less time on the wire.
- Compression work is hidden behind ongoing communication rather than adding to exposed latency.
- Coding strategies can be chosen per message or per workload without rewriting the collective stack.
- The same primitives remain compatible with existing NCCL-based applications.
Where Pith is reading between the lines
- The same separation of stages could be tested on other GPU communication patterns such as point-to-point transfers.
- Workloads with highly compressible data patterns would see the largest gains, suggesting a natural fit for certain simulation outputs.
- An adaptive selector trained offline on representative data might further reduce runtime decision cost.
Load-bearing premise
The lightweight device-side selector can choose effective coding strategies at runtime with negligible overhead and the added compression steps can be overlapped with communication without introducing unacceptable latency or accuracy loss.
What would settle it
Running the same workloads and measuring that selector overhead or added latency consistently exceeds the communication savings, or that gradient accuracy drops below acceptable thresholds for the training tasks.
Figures




read the original abstract
Collective communication is a major bottleneck for multi-node GPU workloads in scientific computing and distributed deep learning, especially when inter-node bandwidth is limited. Although NCCL provides optimized GPU-centric collectives, large messages can still dominate end-to-end performance. Existing compression-enabled collective libraries either rely on MPI-based stacks that cannot fully exploit NCCL, omit entropy coding, or tightly couple full compressors with communication primitives, limiting compression ratio, flexibility, and communication-computation overlap. This paper presents NCCLZ, a compression-enabled GPU collectives that decouples quantization and entropy coding and integrates them at different layers of the stack. NCCLZ places quantization at the interface, embeds entropy coding into NCCL primitives, uses a lightweight device-side selector to choose coding strategies, and overlaps compression with communication to reduce exposed overhead. Experiments on scientific datasets, training gradients, and synthetic workloads show up to 9.65x speedup over NCCL and up to 3.34x improvement over prior compression-assisted collective libraries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. NCCLZ presents a compression-enabled approach to GPU collectives that decouples quantization (placed at the interface) from entropy coding (embedded into NCCL primitives), employs a lightweight device-side selector to choose coding strategies at runtime, and overlaps compression steps with communication to reduce exposed latency. Experiments on scientific datasets, training gradients, and synthetic workloads report up to 9.65x speedup over NCCL and 3.34x over prior compression-assisted collective libraries.
Significance. If the empirical results are robust, the decoupling strategy and integration with NCCL primitives could meaningfully advance optimization of bandwidth-limited collective communication in distributed GPU workloads for scientific computing and deep learning, offering greater flexibility and overlap than tightly coupled prior designs.
major comments (2)
- The abstract reports concrete speedups (9.65x over NCCL, 3.34x over priors) but supplies no details on experimental setup, number of runs, error bars, data characteristics, or baseline configurations, preventing independent verification of the results.
- The central performance claims rest on the device-side selector incurring negligible overhead and compression being overlapped with NCCL primitives without adding exposed latency or accuracy loss. No microbenchmark data on selector decision latency, kernel launch overhead, or measured overlap fraction (e.g., via CUDA events or timeline traces) across message sizes and bandwidth regimes is provided.
minor comments (1)
- The abstract contains a minor grammatical issue ('a compression-enabled GPU collectives' should be rephrased for correctness).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve verifiability and provide supporting microbenchmark data.
read point-by-point responses
-
Referee: The abstract reports concrete speedups (9.65x over NCCL, 3.34x over priors) but supplies no details on experimental setup, number of runs, error bars, data characteristics, or baseline configurations, preventing independent verification of the results.
Authors: We agree that the abstract's brevity limits inclusion of full details. Section 5 of the manuscript already specifies the setup (8x A100 nodes with 100 Gbps InfiniBand, 10 runs per measurement reporting mean and standard deviation as error bars, scientific datasets from climate and molecular dynamics workloads, training gradients from ResNet/BERT, and baselines including NCCL 2.18 plus prior compression libraries). We will revise the abstract to add a concise clause referencing the evaluation methodology and include a summary table of configurations in the experiments section for easier verification. revision: partial
-
Referee: The central performance claims rest on the device-side selector incurring negligible overhead and compression being overlapped with NCCL primitives without adding exposed latency or accuracy loss. No microbenchmark data on selector decision latency, kernel launch overhead, or measured overlap fraction (e.g., via CUDA events or timeline traces) across message sizes and bandwidth regimes is provided.
Authors: This observation is valid; while Sections 3 and 4 describe the selector as a low-cost runtime table lookup and the overlap via asynchronous streams, we did not isolate microbenchmarks. In the revision we will add a dedicated subsection with CUDA-event measurements showing selector latency below 0.5 μs, kernel launch overhead, and overlap fractions (typically 80-95% for large messages) across message sizes and bandwidths, supported by nvprof timeline traces. Accuracy is preserved because entropy coding is lossless after quantization, as already quantified in the training results. revision: yes
Circularity Check
No circularity: empirical system evaluation with no derivation chain
full rationale
The paper describes a system architecture (decoupled quantization/entropy coding, device-side selector, overlap with NCCL) and reports empirical speedups from benchmarks on datasets and workloads. No equations, fitted parameters, predictions, or self-citations are presented as load-bearing steps in any derivation. The central claims rest on measured performance rather than any self-referential logic or imported uniqueness theorems, making the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearNCCLZ decouples quantization at the interface and entropy coding into NCCL primitives... lightweight device-side selector... overlaps compression with communication... up to 9.65× speedup over NCCL
Reference graph
Works this paper leans on
-
[1]
Horovod: fast and easy distributed deep learning in tensorflow,
A. Sergeev and M. Del Balso, “Horovod: fast and easy distributed deep learning in tensorflow,”arXiv preprint arXiv:1802.05799, vol. abs/1802.05799, pp. 1–13, 2018. [Online]. Available: https: //doi.org/10.48550/arXiv.1802.05799
-
[2]
Is network the bottleneck of distributed training?
Z. Zhang, C. Chang, H. Lin, Y . Wang, R. Arora, and X. Jin, “Is network the bottleneck of distributed training?” inWorkshop on Network Meets AI & ML, ser. NetAI ’20. Virtual Event, NY , USA: Association for Computing Machinery, 2020. [Online]. Available: https://doi.org/10.1145/3405671.3405810
-
[3]
Poseidon: An efficient communication architecture for distributed deep learning on gpu clusters,
H. Zhang, Z. Zheng, S. Xu, W. Dai, Q. Ho, X. Liang, Z. Hu, J. Wei, P. Xie, and E. P. Xing, “Poseidon: An efficient communication architecture for distributed deep learning on gpu clusters,” in2017 USENIX Annual Technical Conference (USENIX ATC 17). Santa Clara, CA, USA: USENIX Association, 2017, pp. 181–193. [Online]. Available: https://www.usenix.org/con...
work page 2017
-
[4]
Fast error-bounded lossy HPC data compression with SZ,
S. Di and F. Cappello, “Fast error-bounded lossy HPC data compression with SZ,” in2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS). Chicago, IL, USA: IEEE, 2016, pp. 730–739. [Online]. Available: https://szcompressor.org/tabs/publication/
work page 2016
-
[5]
cusz: An efficient GPU-based error-bounded lossy compression framework for scientific data,
J. Tian, S. Di, K. Zhao, C. Rivera, M. Hickman Fulp, R. Underwood, S. Jin, X. Liang, J. Calhoun, D. Tao, and F. Cappello, “cusz: An efficient GPU-based error-bounded lossy compression framework for scientific data,” inProceedings of the 29th International Conference on Parallel Architectures and Compilation Techniques (PACT). New York, NY , USA: Associati...
-
[6]
Greedy low-rank gradient compression for distributed learning with convergence guarantees,
C. Chen, Y . He, P. Li, W. Jia, and K. Yuan, “Greedy low-rank gradient compression for distributed learning with convergence guarantees,” arXiv preprint arXiv:2507.08784, 2025. [Online]. Available: https: //doi.org/10.48550/arXiv.2507.08784
-
[7]
H. Feng, B. Zhang, F. Ye, M. Si, C.-H. Chu, J. Tian, C. Yin, S. Deng, Y . Hao, P. Balaji, T. Geng, and D. Tao, “Accelerating communication in deep learning recommendation model training with dual-level adaptive lossy compression,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis, 2024, pp. 1–16. [Online]. A...
-
[8]
TAH-QUANT: Effective Activation Quantization in Pipeline Parallelism over Slow Network
G. He, Y . Cao, Y . He, T. Bai, K. Yuan, and B. Yuan, “Tah-quant: Effective activation quantization in pipeline parallelism over slow network,”arXiv preprint arXiv:2506.01352, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.01352
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01352 2025
-
[10]
gZCCL: Compression-accelerated collective communication framework for GPU clusters,
J. Huang, S. Di, X. Yu, Y . Zhai, J. Liu, Y . Huang, K. Raffenetti, H. Zhou, K. Zhao, X. Lu, Z. Chen, F. Cappello, Y . Guo, and R. Thakur, “gZCCL: Compression-accelerated collective communication framework for GPU clusters,” inProceedings of the 38th ACM International Conference on Supercomputing (ICS ’24). New York, NY , USA: Association for Computing Ma...
-
[11]
ghzccl: Advancing GPU-aware collective communications with homomorphic compression,
J. Huang, S. Di, Y . Huang, Z. Chen, F. Cappello, Y . Guo, and R. Thakur, “ghzccl: Advancing GPU-aware collective communications with homomorphic compression,” inProceedings of the 2025 International Conference on Supercomputing, ser. ICS ’25. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/37211...
-
[12]
X. Liu, H. Kong, H. Zhao, S. Lyu, Z. Wei, M. Liu, X. Tian, L. Zhao, Z. Chen, F. Wang, Z. Chen, Z. Wang, G. Tan, and D. Tao, “Coccl: A collective communication library supporting easy integration and configuration of customized compression for scalable llm training,” inProceedings of the 31st ACM SIGPLAN Annual Symposium on Principles and Practice of Paral...
-
[13]
NVIDIA collective communications library (NCCL),
NVIDIA, “NVIDIA collective communications library (NCCL),” 2025, accessed: 2026-01-16. [Online]. Available: https://github.com/NVIDIA/ nccl
work page 2025
-
[14]
NVIDIA collective communications library (NCCL),
——, “NVIDIA collective communications library (NCCL),” 2026, accessed: 2026-01-27. [Online]. Available: https://developer.nvidia.com/ nccl
work page 2026
-
[15]
Distributeddataparallel — PyTorch documentation,
PyTorch, “Distributeddataparallel — PyTorch documentation,” 2026, accessed: 2026-01-27. [Online]. Available: https://docs.pytorch.org/ docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html
work page 2026
-
[16]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,”arXiv preprint arXiv:1909.08053, vol. abs/1909.08053, pp. 1–12, 2019. [Online]. Available: https: //doi.org/10.48550/arXiv.1909.08053
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1909.08053 1909
-
[17]
Efficient Memory Management for Large Language Model Serving with PagedAttention
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,”arXiv preprint arXiv:2309.06180, vol. abs/2309.06180, pp. 1–17, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309.06180
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.06180 2023
-
[18]
SGLang: Efficient Execution of Structured Language Model Programs
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y . Sheng, “SGLang: Efficient execution of structured language model programs,” arXiv preprint arXiv:2312.07104, vol. abs/2312.07104, pp. 1–16, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2312.07104
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.07104 2024
-
[19]
Demystifying nccl: An in-depth analysis of GPU communication protocols and algorithms,
Z. Hu, S. Shen, T. Bonato, S. Jeaugey, C. Alexander, E. Spada, J. Dinan, J. Hammond, and T. Hoefler, “Demystifying nccl: An in-depth analysis of GPU communication protocols and algorithms,” arXiv preprint arXiv:2507.04786, vol. abs/2507.04786, pp. 1–24, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2507.04786
-
[20]
NVIDIA A100 80GB PCIe GPU (product brief),
NVIDIA, “NVIDIA A100 80GB PCIe GPU (product brief),” NVIDIA, Tech. Rep., 2022, reports up to 600 GB/s NVLink bandwidth with NVLink bridges. [Online]. Available: https://www.nvidia.com/content/ dam/en-zz/Solutions/Data-Center/a100/pdf/PB-10577-001 v02.pdf
work page 2022
-
[21]
Communication-efficient large-scale distributed deep learning: A comprehensive survey,
F. Liang, Z. Zhang, H. Lu, V . C. M. Leung, Y . Guo, and X. Hu, “Communication-efficient large-scale distributed deep learning: A comprehensive survey,” 2024. [Online]. Available: https://doi.org/10. 48550/arXiv.2404.06114
-
[22]
Efficient lossy compression for scientific data based on pointwise relative error bound,
S. Di, D. Tao, X. Liang, and F. Cappello, “Efficient lossy compression for scientific data based on pointwise relative error bound,”IEEE Transactions on Parallel and Distributed Systems, vol. 30, no. 2, pp. 331–345, 2018. [Online]. Available: https: //doi.org/10.1109/TPDS.2018.2859932
-
[24]
QSGD: Communication-efficient SGD via gradient quantization and encoding,
D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. V ojnovic, “QSGD: Communication-efficient SGD via gradient quantization and encoding,” arXiv preprint arXiv:1610.02132, vol. abs/1610.02132, pp. 1–14, 2017. [Online]. Available: https://doi.org/10.48550/arXiv.1610.02132
-
[25]
Y . Huang, S. Di, X. Yu, G. Li, and F. Cappello, “CuSZp: An ultra-fast GPU error-bounded lossy compression framework with optimized end- to-end performance,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’23. New York, NY , USA: Association for Computing Machinery,
-
[26]
Available: https://doi.org/10.1145/3581784.3607048
[Online]. Available: https://doi.org/10.1145/3581784.3607048
-
[27]
COCCL: Compression and precision co-aware collective communication library,
X. Liu, H. Kong, Z. Wei, L. Zhao, Y . Wang, and J. Yang, “COCCL: Compression and precision co-aware collective communication library,” 2025, accessed: 2026-01-26. [Online]. Available: https://github.com/ hpdps-group/COCCL
work page 2025
-
[28]
Designing high-performance MPI libraries with on-the-fly compression for modern GPU clusters,
Q. Zhou, C. Chu, N. S. Kumar, S. M. G. Pouya Kousha and, H. Subramoni, and D. K. Panda, “Designing high-performance MPI libraries with on-the-fly compression for modern GPU clusters,” in35th IEEE International Parallel and Distributed Processing Symposium, IPDPS 2021, Portland, OR, USA, May 17–21, 2021. Portland, OR, USA: IEEE, 2021, pp. 444–453. [Online]...
-
[29]
MV APICH Project, “Mvapich2-gdr user guide,” 2026, accessed: 2026- 02-06. [Online]. Available: https://mvapich.cse.ohio-state.edu/userguide/ gdr/
work page 2026
- [30]
-
[31]
Fixed-rate compressed floating-point arrays,
P. Lindstrom, “Fixed-rate compressed floating-point arrays,”IEEE Transactions on Visualization and Computer Graphics, vol. 20, no. 12, pp. 2674–2683, 2014. [Online]. Available: https://doi.org/10.1109/ TVCG.2014.2346458
-
[32]
zfp: Compressed floating-point and integer arrays (cuda support),
LLNL, “zfp: Compressed floating-point and integer arrays (cuda support),” GitHub repository, 2026, accessed 2026-02-06. [Online]. Available: https://github.com/LLNL/zfp
work page 2026
-
[33]
F. Seide, H. Fu, J. Droppo, G. Li, and D. Yu, “1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs,” inINTERSPEECH. Singapore: ISCA, 2014, pp. 1058–1062. [Online]. Available: https://www.microsoft.com/en-us/ research/wp-content/uploads/2016/02/IS140694.pdf
work page 2014
-
[34]
E. Jeannot and P. Strazdins, “Improving middleware performance with AdOC: An adaptive online compression library for data transfer,” in Proceedings of the 19th IEEE International Parallel and Distributed Processing Symposium (IPDPS). Denver, CO, USA: IEEE, 2005, pp. 1–8. [Online]. Available: https://doi.org/10.1109/IPDPS.2005.254
-
[35]
J. Ke, M. Burtscher, and E. Speight, “Runtime compression of MPI messages to improve the performance and scalability of parallel applications,” inProceedings of the ACM/IEEE Conference on Supercomputing (SC ’04). Pittsburgh, PA, USA: IEEE Computer Society, 2004, p. 59. [Online]. Available: https://doi.org/10.1109/SC. 2004.52
work page doi:10.1109/sc 2004
-
[36]
Compi: Enhancing MPI based applications performance and scalability using run-time compression,
R. Filgueira, D. E. Singh, A. Calder ´on, and J. Carretero, “Compi: Enhancing MPI based applications performance and scalability using run-time compression,” inRecent Advances in Parallel Virtual Machine and Message Passing Interface (EuroPVM/MPI 2009), ser. Lecture Notes in Computer Science, vol. 5759. Espoo, Finland: Springer, 2009, pp. 207–218. [Online...
-
[37]
An adaptive, scalable, and portable technique for speeding up MPI- based applications,
R. Filgueira, M. Atkinson, A. Nu ˜nez, and J. Fern ´andez, “An adaptive, scalable, and portable technique for speeding up MPI- based applications,” inEuro-Par 2012 Parallel Processing, ser. Lecture Notes in Computer Science, vol. 7484. Rhodes Island, Greece: Springer, 2012, pp. 729–740. [Online]. Available: https: //doi.org/10.1007/978-3-642-32820-6 72
-
[38]
Accelerating MPI all-to-all communication with online compression on modern GPU clusters,
Q. Zhou, P. Kousha, Q. Anthony, K. S. Khorassani, A. Shafi, H. Subramoni, and D. K. Panda, “Accelerating MPI all-to-all communication with online compression on modern GPU clusters,” inHigh Performance Computing – 37th International Conference, ISC High Performance 2022, Hamburg, Germany, May 29–June 2, 2022, Proceedings, ser. Lecture Notes in Computer Sc...
-
[39]
B. R. Qinghua Zhou and, A. Shafi, M. Abduljabbar, H. Subramoni, and D. K. Panda, “Accelerating MPI allreduce communication with efficient gpu-based, compression schemes on modern GPU clusters,” inISC High Performance 2024 Research Paper Proceedings (39th International, Conference), Hamburg, Germany, May 12-16, 2024. Hamburg, Germany: Prometeus GmbH / IEEE...
-
[40]
C-coll: Introducing error-bounded lossy compression into mpi collectives,
J. Huang, S. Di, X. Yu, Y . Zhai, J. Liu, K. Raffenetti, H. Zhou, K. Zhao, Z. Chen, F. Cappello, Y . Guo, and R. Thakur, “C-coll: Introducing error-bounded lossy compression into mpi collectives,” arXiv preprint arXiv:2304.03890, vol. abs/2304.03890, pp. 1–19, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.03890
-
[41]
MPICH Project, “Mpich overview,” 2026, accessed: 2026-02-06. [Online]. Available: https://www.mpich.org/about/overview/
work page 2026
-
[42]
A high-performance, portable implementation of the mpi message passing interface standard,
W. Gropp, E. Lusk, N. Doss, and A. Skjellum, “A high-performance, portable implementation of the mpi message passing interface standard,” Parallel Computing, vol. 22, no. 6, pp. 789–828, 1996. [Online]. Available: https://doi.org/10.1016/0167-8191(96)00024-5
-
[43]
Design of high performance mvapich2: Mpi2 over infiniband,
W. Huang, G. Santhanaraman, H.-W. Jin, Q. Gao, and D. K. Panda, “Design of high performance mvapich2: Mpi2 over infiniband,” in Proceedings of the Sixth IEEE International Symposium on Cluster Computing and the Grid (CCGRID). Singapore: IEEE, 2006, pp. 43–48. [Online]. Available: https://doi.org/10.1109/CCGRID.2006.32
-
[44]
Rccl documentation (rocm communication collectives library),
AMD, “Rccl documentation (rocm communication collectives library),” 2026, accessed: 2026-02-06. [Online]. Available: https://rocmdocs.amd. com/projects/rccl/en/latest/index.html
work page 2026
-
[45]
oneapi collective communications library (oneccl) documentation,
UXL Foundation, “oneapi collective communications library (oneccl) documentation,” 2026, accessed: 2026-02-06. [Online]. Available: https://uxlfoundation.github.io/oneCCL/index.html
work page 2026
-
[46]
Gloo: Collective communications library,
PyTorch, “Gloo: Collective communications library,” 2026, accessed: 2026-02-06. [Online]. Available: https://github.com/pytorch/gloo
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.