Recognition: 2 theorem links
· Lean TheoremOGLS-SD: On-Policy Self-Distillation with Outcome-Guided Logit Steering for LLM Reasoning
Pith reviewed 2026-05-13 05:14 UTC · model grok-4.3
The pith
Outcome-guided logit steering calibrates teacher responses in on-policy self-distillation by contrasting successful and failed trajectories, reducing reflection bias for better LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
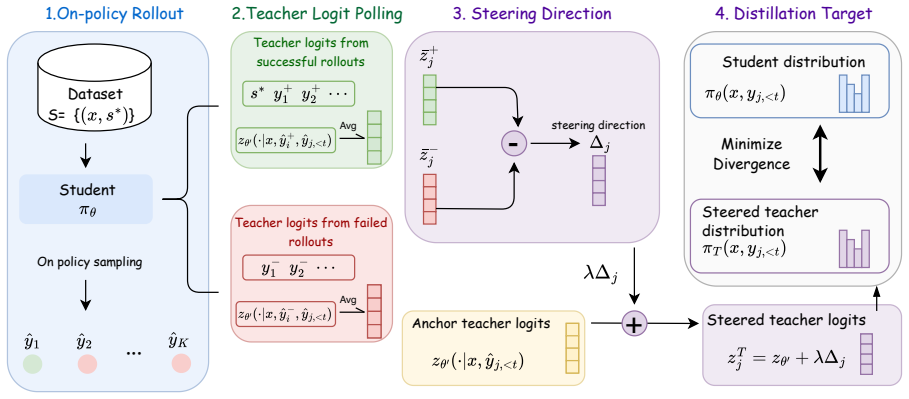
OGLS-SD mitigates the mismatch between teacher and student distributions in on-policy self-distillation by applying outcome-guided logit steering: verifiable rewards contrast successful and failed trajectories to re-calibrate teacher logits, thereby countering reflection-induced bias and delivering more accurate token-level supervision that improves model reasoning performance.
What carries the argument
Outcome-guided logit steering, which contrasts successful and failed on-policy trajectories using verifiable rewards to adjust teacher logit distributions for token-level guidance.
If this is right
- Stabilizes on-policy self-distillation by correcting for reflection bias in teacher responses.
- Yields higher reasoning accuracy than standard OPSD and related variants on diverse benchmarks.
- Allows effective use of on-policy data without external privileged teacher models.
- Combines sparse outcome correctness with dense per-token signals in a single steering step.
Where Pith is reading between the lines
- The steering step may generalize to other self-improvement loops where partial trajectories can be scored by final outcome.
- It offers one route to reduce dependence on carefully curated external supervision data in LLM training.
- Similar contrastive logit adjustments could address other sources of self-generated bias beyond reflection templates.
Load-bearing premise
Verifiable outcome rewards can reliably separate successful from failed trajectories to calibrate teacher logits without creating fresh miscalibration or depending on tasks where outcomes are hard to check.
What would settle it
A controlled run on math or code benchmarks where applying the logit steering step produces no measurable drop in teacher-student mismatch or no gain in final answer accuracy relative to unsteered on-policy self-distillation.
Figures




read the original abstract
We study {on-policy self-distillation} (OPSD), where a language model improves its reasoning ability by distilling privileged teacher distributions along its own on-policy trajectories. Despite the performance gains of OPSD, we identify a common but often overlooked mismatch between teacher and student responses: self-reflected teacher responses can be shifted by reflection-induced bias and response templates, leading to miscalibrated token-level supervision. To mitigate this issue, we propose \methodname, an outcome-guided logit-steering framework that leverages verifiable outcome rewards to contrast successful and failed on-policy trajectories and calibrate teacher logits. By combining outcome-level correctness with dense token-level guidance through logit steering, \methodname stabilizes self-distillation and improves reasoning performance over standard OPSD and other variants across diverse benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OGLS-SD, an outcome-guided logit-steering framework for on-policy self-distillation (OPSD) in LLMs. It identifies a mismatch between teacher and student responses due to reflection-induced bias and response templates, then proposes using verifiable outcome rewards to contrast successful and failed on-policy trajectories in order to calibrate teacher logits. The method combines outcome-level correctness signals with dense token-level guidance, claiming to stabilize self-distillation and yield improved reasoning performance over standard OPSD and other variants across diverse benchmarks.
Significance. If the empirical gains hold under rigorous controls, the work provides a practical mechanism for mitigating teacher-student misalignment in self-improvement loops without requiring external privileged teachers. The integration of sparse outcome rewards with dense logit steering is a targeted contribution to LLM reasoning literature and could be extended to other verifiable-outcome domains.
major comments (2)
- [§3.3] §3.3, Eq. (7): the logit-steering update is defined using a contrast between successful and failed trajectories, but the paper does not derive or bound how the steering coefficient interacts with the original teacher distribution; without this, it is unclear whether the claimed bias mitigation is guaranteed or merely empirical.
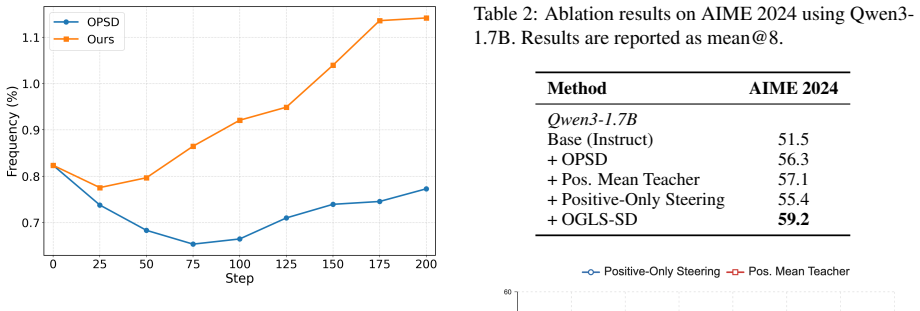
- [Table 2] Table 2, GSM8K and MATH rows: the reported gains over OPSD are 2.1–3.4 points, yet no standard errors, number of runs, or statistical significance tests are provided; this weakens the central claim that OGLS-SD “stabilizes” self-distillation.
minor comments (3)
- [§2.1] §2.1: the definition of “reflection-induced bias” is introduced informally; a short formalization or illustrative example would improve clarity.
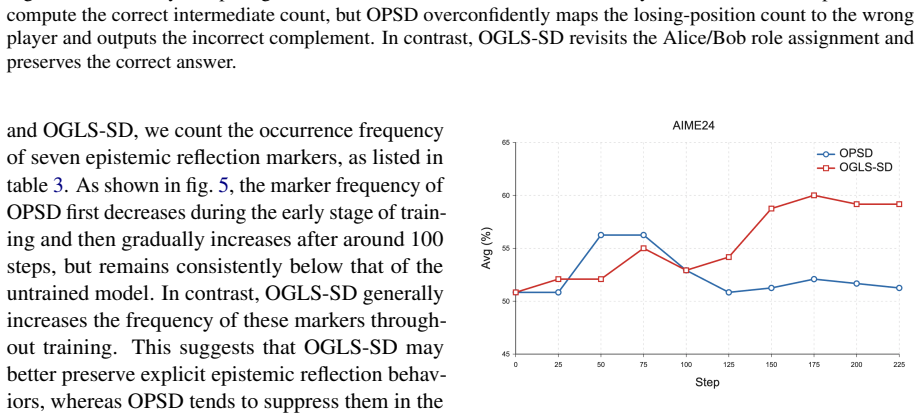
- [Figure 3] Figure 3: the caption does not specify the exact hyperparameter values used for the logit-steering strength, making reproduction difficult.
- [Related Work] Related-work section: the discussion of prior logit-calibration methods omits recent work on outcome-conditioned distillation (e.g., papers from 2024 on process vs. outcome supervision).
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We provide detailed responses to the major comments below and indicate the revisions we plan to incorporate in the updated manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3, Eq. (7): the logit-steering update is defined using a contrast between successful and failed trajectories, but the paper does not derive or bound how the steering coefficient interacts with the original teacher distribution; without this, it is unclear whether the claimed bias mitigation is guaranteed or merely empirical.
Authors: We agree that a theoretical derivation or bound would provide stronger justification for the logit-steering approach. However, our method is primarily empirical, leveraging verifiable outcome rewards to guide the calibration. In the revised manuscript, we will expand Section 3.3 to include a discussion on the interaction of the steering coefficient with the teacher distribution, including sensitivity analysis and the empirical rationale for bias mitigation. We note that while not theoretically guaranteed, the approach consistently improves performance across benchmarks. revision: partial
-
Referee: Table 2, GSM8K and MATH rows: the reported gains over OPSD are 2.1–3.4 points, yet no standard errors, number of runs, or statistical significance tests are provided; this weakens the central claim that OGLS-SD “stabilizes” self-distillation.
Authors: We acknowledge this limitation in the current presentation. To strengthen the evidence, we will update Table 2 to include results from multiple runs with standard errors and perform statistical significance tests for the reported gains on GSM8K and MATH. This will better substantiate the stabilization claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe OGLS-SD as a framework that applies external verifiable outcome rewards to contrast on-policy trajectories and calibrate teacher logits via steering. No derivation chain, equations, or self-citations are shown that reduce the claimed stabilization or performance gains to fitted parameters, self-definitions, or prior author results by construction. The method is presented as building on standard OPSD with an added outcome-guided component whose inputs (verifiable rewards) are external to the distillation process itself. This keeps the central claim self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
free parameters (1)
- logit steering hyperparameters
axioms (2)
- domain assumption Self-reflected teacher responses in OPSD are shifted by reflection-induced bias and response templates, causing miscalibrated token-level supervision.
- domain assumption Verifiable outcome rewards can be used to contrast successful and failed trajectories for calibration.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesconstructs an outcome-guided logit-steering direction by contrasting teacher logits induced by successful and failed rollouts
Reference graph
Works this paper leans on
-
[1]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. 2026 , eprint=
work page 2026
- [2]
-
[3]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. 2026 , eprint=
work page 2026
- [4]
- [5]
-
[6]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[7]
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
work page 2026
-
[8]
Reinforcement Learning via Self-Distillation , author=. 2026 , eprint=
work page 2026
-
[9]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation , author=. 2026 , eprint=
work page 2026
-
[10]
Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing , author=. 2026 , eprint=
work page 2026
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
-
[12]
The Twelfth International Conference on Learning Representations , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. The Twelfth International Conference on Learning Representations , year=
-
[13]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[14]
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , booktitle=. Mini. 2024 , url=
work page 2024
-
[15]
Jongwoo Ko and Tianyi Chen and Sungnyun Kim and Tianyu Ding and Luming Liang and Ilya Zharkov and Se-Young Yun , booktitle=. Disti. 2025 , url=
work page 2025
- [16]
-
[17]
FlowRL: Matching Reward Distributions for LLM Reasoning , author=. 2025 , eprint=
work page 2025
-
[18]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? , author=. 2026 , eprint=
work page 2026
-
[19]
HDPO: Hybrid Distillation Policy Optimization via Privileged Self-Distillation , author=. 2026 , eprint=
work page 2026
-
[20]
The Thirteenth International Conference on Learning Representations , year=
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[21]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision , author=. 2026 , eprint=
work page 2026
-
[22]
Learning to Reason under Off-Policy Guidance , url =
Yan, Jianhao and Li, Yafu and Hu, Zican and Wang, Zhi and Cui, Ganqu and Qu, Xiaoye and Cheng, Yu and Zhang, Yue , booktitle =. Learning to Reason under Off-Policy Guidance , url =
-
[23]
A lign D istil: Token-Level Language Model Alignment as Adaptive Policy Distillation
Zhang, Songming and Zhang, Xue and Zhang, Tong and Hu, Bojie and Chen, Yufeng and Xu, Jinan. A lign D istil: Token-Level Language Model Alignment as Adaptive Policy Distillation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.972
-
[24]
The Fourteenth International Conference on Learning Representations , year=
Explain in Your Own Words: Improving Reasoning via Token-Selective Dual Knowledge Distillation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[25]
American Invitational Mathematics Examination (AIME) 2024 , author=
work page 2024
-
[26]
American Invitational Mathematics Examination (AIME) 2025 , author=
work page 2025
-
[27]
First Workshop on Foundations of Reasoning in Language Models , year=
OpenThoughts: Data Recipes for Reasoning Models , author=. First Workshop on Foundations of Reasoning in Language Models , year=
-
[28]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
-
[29]
International Conference on Learning Representations , year=
Efficient Estimation of Word Representations in Vector Space , author=. International Conference on Learning Representations , year=
-
[30]
Learning to Steer: Input-dependent Steering for Multimodal LLMs , url =
Parekh, Jayneel and KHAYATAN, Pegah and Shukor, Mustafa and Dapogny, Arnaud and Newson, Alasdair and Cord, Matthieu , booktitle =. Learning to Steer: Input-dependent Steering for Multimodal LLMs , url =
-
[31]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , url =
Li, Kenneth and Patel, Oam and Vi\'. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , url =. Advances in Neural Information Processing Systems , editor =
-
[32]
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
work page 2024
-
[33]
Steering llama 2 via contrastive activation addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[34]
Refusal in Language Models Is Mediated by a Single Direction , author=. 2024 , eprint=
work page 2024
-
[35]
Forty-second International Conference on Machine Learning , year=
Mitigating Object Hallucination in Large Vision-Language Models via Image-Grounded Guidance , author=. Forty-second International Conference on Machine Learning , year=
-
[36]
Black-Box On-Policy Distillation of Large Language Models , author=. 2026 , eprint=
work page 2026
-
[37]
The Fourteenth International Conference on Learning Representations , year=
pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[38]
Tobias Jülg and Wolfram Burgard and Florian Walter , year=
-
[39]
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
work page 2023
-
[40]
von Werra, Leandro and Belkada, Younes and Tunstall, Lewis and Beeching, Edward and Thrush, Tristan and Lambert, Nathan and Huang, Shengyi and Rasul, Kashif and Gallouédec, Quentin , license =
-
[41]
Reflexion: language agents with verbal reinforcement learning , url =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle =. Reflexion: language agents with verbal reinforcement learning , url =
-
[42]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.