Recognition: 2 theorem links
· Lean TheoremGeometric Factual Recall in Transformers
Pith reviewed 2026-05-13 04:44 UTC · model grok-4.3
The pith
Transformers memorize facts with logarithmic embedding dimensions by encoding linear superpositions of attributes in subject embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a single-layer transformer trained to memorize random bijections from subjects to a shared attribute set, subject embeddings encode linear superpositions of their associated attribute vectors. The MLP serves as a relation-conditioned selector that extracts the relevant attribute via ReLU gating rather than as an associative key-value mapping. This construction requires only logarithmic embedding dimension. The results extend to multi-hop relational queries, with explicit constructions both using and avoiding chain-of-thought that exhibit a provable capacity-depth tradeoff, matched by an information-theoretic lower bound. Gradient descent discovers solutions with exactly the predicted form
What carries the argument
Linear superpositions of attribute vectors inside subject embeddings, combined with the MLP as a ReLU-gated relation-conditioned selector.
If this is right
- Only logarithmic embedding dimension is required rather than linear scaling with the number of facts.
- The MLP learns a generic selection mechanism that transfers zero-shot to new bijections.
- Multi-hop queries admit constructions with and without chain-of-thought that display a capacity-depth tradeoff.
- Information-theoretic lower bounds match the capacity achieved by the geometric constructions.
Where Pith is reading between the lines
- Deeper multi-layer models trained on natural text may rely on analogous geometric superposition rather than dense associative memory.
- Probing real embeddings for linear attribute combinations could directly test whether the geometric mechanism is at work.
- The transferable selector points to possible improvements in fact editing and continual learning without full retraining.
- Extending the analysis to natural data distributions could clarify how pretraining induces such geometric encodings.
Load-bearing premise
The controlled setting of random bijections over a shared attribute set in a single-layer transformer captures the essential mechanism of factual recall in real multi-layer language models trained on natural data.
What would settle it
Training the single-layer model on the bijection task and observing that it requires embedding dimension that scales linearly with the number of facts, or that the MLP fails to transfer zero-shot to new bijections after subject-embedding re-initialization.
Figures
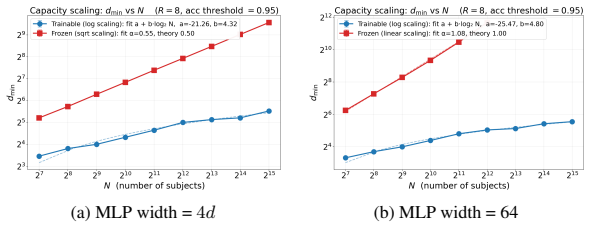

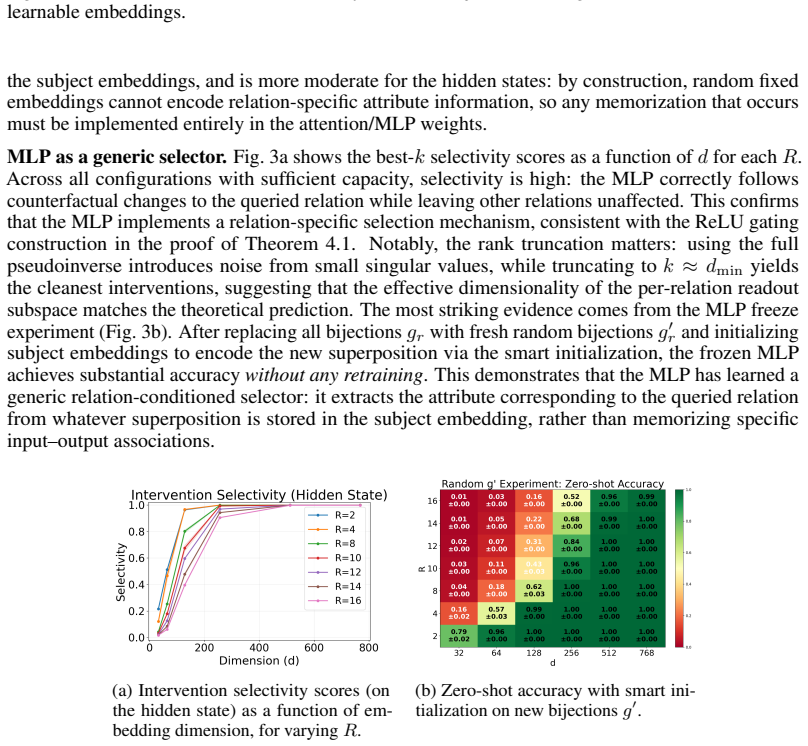
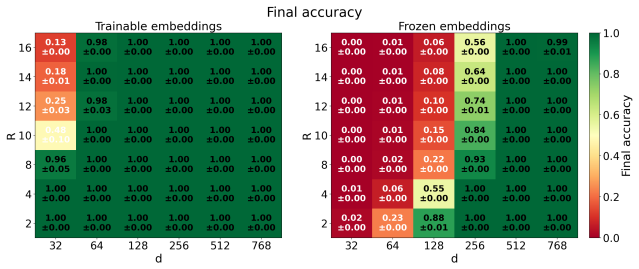
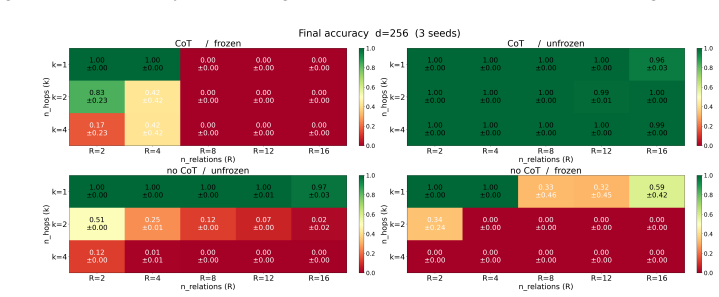
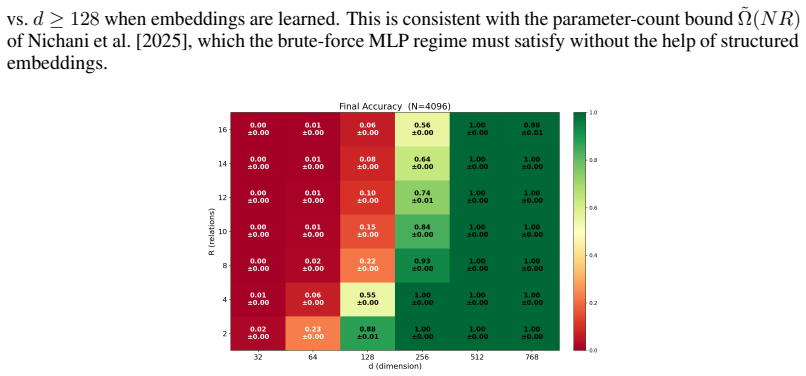
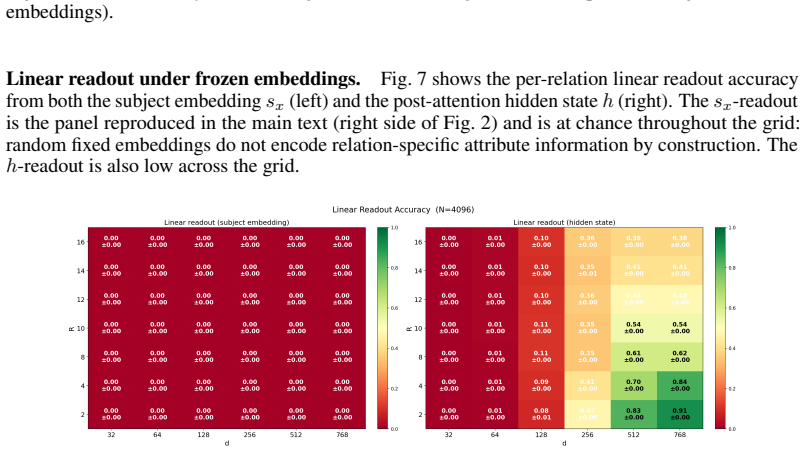


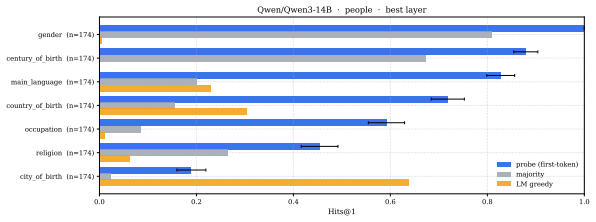
read the original abstract
How do transformer language models memorize factual associations? A common view casts internal weight matrices as associative memories over pairs of embeddings, requiring parameter counts that scale linearly with the number of facts. We develop a theoretical and empirical account of an alternative, \emph{geometric} form of memorization in which learned embeddings encode relational structure directly, and the MLP plays a qualitatively different role. In a controlled setting where a single-layer transformer must memorize random bijections from subjects to a shared attribute set, we prove that a logarithmic embedding dimension suffices: subject embeddings encode \emph{linear superpositions} of their associated attribute vectors, and a small MLP acts as a relation-conditioned selector that extracts the relevant attribute via ReLU gating, and not as an associative key-value mapping. We extend these results to the multi-hop setting -- chains of relational queries such as ``Who is the mother of the wife of $x$?'' -- providing constructions with and without chain-of-thought that exhibit a provable capacity-depth tradeoff, complemented by a matching information-theoretic lower bound. Empirically, gradient descent discovers solutions with precisely the predicted structure. Once trained, the MLP transfers zero-shot to entirely new bijections when subject embeddings are appropriately re-initialized, revealing that it has learned a generic selection mechanism rather than memorized any particular set of facts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a geometric account of factual recall in transformers. In a controlled single-layer transformer trained to memorize random bijections from subjects to a shared set of attributes, it proves that logarithmic embedding dimension is sufficient. Subject embeddings encode linear superpositions of attribute vectors, and the MLP functions as a relation-conditioned selector using ReLU gating rather than an associative key-value store. The results are extended to multi-hop relational queries with constructions showing a capacity-depth tradeoff and a matching information-theoretic lower bound. Empirically, gradient descent recovers the predicted structure, and the trained MLP enables zero-shot transfer to new bijections upon re-initialization of subject embeddings.
Significance. If the theoretical constructions and empirical findings hold, this work offers a compelling alternative to the associative memory view of factual memorization in transformers, highlighting a more parameter-efficient geometric mechanism. Key strengths include the explicit mathematical constructions and proofs for both single-layer and multi-hop cases, the demonstration that gradient descent discovers the predicted geometry, and the zero-shot transfer result indicating a general selection mechanism. This could influence how we understand and design models for knowledge storage. However, the reliance on a highly controlled toy setting with random bijections and shared attributes means the significance for real-world multi-layer language models on natural data remains to be established.
major comments (2)
- [Abstract and Introduction] Abstract and §1: The framing as an account of how transformers memorize factual associations in general depends on the random-bijection toy model capturing the essential mechanism. The paper should include a dedicated discussion (perhaps in §6 or a new subsection) of how the linear-superposition + ReLU-selector geometry would or would not arise under natural-data correlations, sparse attributes, or multi-layer interactions, with a concrete prediction or test.
- [Multi-hop extension] Multi-hop section (likely §4): The capacity-depth tradeoff constructions and information-theoretic lower bound are central, but the manuscript must explicitly state whether the lower bound is tight against the provided constructions or leaves a gap; if the latter, this weakens the claimed tradeoff.
minor comments (3)
- [Theoretical sections] Ensure all proofs (single-layer and multi-hop) are fully derived in the main text or a clearly labeled appendix rather than summarized, to allow verification of the logarithmic-dimension claim and ReLU gating construction.
- [Experiments and figures] Figure captions and experimental details should report the exact embedding dimension used relative to the theoretical log bound and the number of attributes/subjects in the random bijections.
- [Zero-shot transfer experiment] Clarify the precise re-initialization procedure for subject embeddings in the zero-shot transfer experiment to avoid ambiguity about what is being transferred.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We will incorporate clarifications and a new discussion section to address both major comments.
read point-by-point responses
-
Referee: [Abstract and Introduction] Abstract and §1: The framing as an account of how transformers memorize factual associations in general depends on the random-bijection toy model capturing the essential mechanism. The paper should include a dedicated discussion (perhaps in §6 or a new subsection) of how the linear-superposition + ReLU-selector geometry would or would not arise under natural-data correlations, sparse attributes, or multi-layer interactions, with a concrete prediction or test.
Authors: We agree that the toy setting requires explicit discussion of its relation to natural data for the framing to be appropriately scoped. In the revised manuscript we will add a new subsection (in §6) analyzing how linear superposition and ReLU-based selection could arise under natural correlations versus sparse attributes, how multi-layer stacking might interact with or modify the mechanism, and concrete predictions such as observable ReLU gating signatures in factual circuits of larger models together with suggested tests (e.g., activation patching on real factual recall tasks). revision: yes
-
Referee: [Multi-hop extension] Multi-hop section (likely §4): The capacity-depth tradeoff constructions and information-theoretic lower bound are central, but the manuscript must explicitly state whether the lower bound is tight against the provided constructions or leaves a gap; if the latter, this weakens the claimed tradeoff.
Authors: We appreciate the request for explicitness. The information-theoretic lower bound is constructed to be tight against the provided capacity-depth constructions (no gap), which is what allows us to claim a matching tradeoff. We will revise §4 to state this tightness explicitly, including a short proof sketch confirming that the lower bound saturates the construction. revision: yes
Circularity Check
No significant circularity; derivations are explicit constructions and proofs
full rationale
The paper establishes its core results via explicit mathematical constructions and proofs showing that logarithmic embedding dimension suffices for subject embeddings to encode linear superpositions of attribute vectors, with the MLP acting as a ReLU-gated selector rather than key-value memory. These hold inside the defined single-layer transformer on random bijections, with matching information-theoretic lower bounds for the multi-hop case. Gradient descent discovering the structures is reported as an empirical finding separate from the existence proofs. No steps reduce by construction to fitted parameters, self-citations, or ansatzes; the controlled setting is stated as an assumption rather than derived from the results themselves.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Linear algebra over real vectors: any set of attribute vectors can be superposed and later isolated by linear projections or gating.
- domain assumption The task is exactly memorizing random bijections from a subject set to a fixed attribute set.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearsubject embeddings encode linear superpositions of their associated attribute vectors, and a small MLP acts as a relation-conditioned selector that extracts the relevant attribute via ReLU gating
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono uncleard = 4R log(N) + 1 ... 3-layer MLP of width R
Reference graph
Works this paper leans on
-
[1]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Birth of a Transformer: A Memory Viewpoint , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[2]
International Conference on Learning Representations (ICLR) , year=
Scaling Laws for Associative Memories , author=. International Conference on Learning Representations (ICLR) , year=
-
[3]
International Conference on Learning Representations (ICLR) , year=
Understanding factual recall in transformers via associative memories , author=. International Conference on Learning Representations (ICLR) , year=
-
[4]
arXiv preprint arXiv:2510.26745 , year=
Deep sequence models tend to memorize geometrically; it is unclear why , author=. arXiv preprint arXiv:2510.26745 , year=
-
[5]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Emergence of Linear Truth Encodings in Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[6]
arXiv preprint arXiv:2502.11162 , year=
Logarithmic Width Suffices for Robust Memorization , author=. arXiv preprint arXiv:2502.11162 , year=
-
[7]
arXiv preprint arXiv:2512.00207 , year=
Constructing Efficient Fact-Storing MLPs for Transformers , author=. arXiv preprint arXiv:2512.00207 , year=
-
[8]
Linearity of Relation Decoding in Transformer Language Models , author=. CoRR , year=
- [9]
-
[10]
International Conference on Learning Representations (ICLR) , year=
On Linear Representations and Pretraining Data Frequency in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
An introduction to Kolmogorov complexity and its applications , author=. 2008 , publisher=
work page 2008
-
[12]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2021
-
[13]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , journal=. Locating and Editing Factual Associations in
-
[14]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Dissecting Recall of Factual Associations in Auto-Regressive Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[15]
How Much Knowledge Can You Pack Into the Parameters of a Language Model? , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2020
-
[16]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Physics of Language Models: Part 3.1, Knowledge Storage and Extraction , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[17]
arXiv preprint arXiv:2309.14402 , year =
Physics of Language Models: Part 3.2, Knowledge Manipulation , author =. arXiv preprint arXiv:2309.14402 , year =
-
[18]
arXiv preprint arXiv:2404.05405 , year =
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws , author =. arXiv preprint arXiv:2404.05405 , year =
-
[19]
Knowledge Neurons in Pretrained Transformers , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[20]
The Eleventh International Conference on Learning Representations (ICLR) , year =
Mass-Editing Memory in a Transformer , author =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs.\ Knowledge Editing in Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[22]
Transformer Circuits Thread , year =
Toy Models of Superposition , author =. Transformer Circuits Thread , year =
-
[23]
Transformer Circuits Thread , year =
Towards Monosemanticity: Decomposing Language Models with Dictionary Learning , author =. Transformer Circuits Thread , year =
-
[24]
Transformer Circuits Thread , year =
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author =. Transformer Circuits Thread , year =
-
[25]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[26]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author =. arXiv preprint arXiv:2310.06824 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Language Models Represent Space and Time , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[28]
International Conference on Learning Representations (ICLR) , year =
Are Transformers Universal Approximators of Sequence-to-Sequence Functions? , author =. International Conference on Learning Representations (ICLR) , year =
-
[29]
International Conference on Learning Representations (ICLR) , year =
On the Optimal Memorization Power of ReLU Neural Networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[30]
Advances in Neural Information Processing Systems (NeurIPS) , year =
A Universal Law of Robustness via Isoperimetry , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[31]
The Eleventh International Conference on Learning Representations (ICLR) , year =
Provable Memorization Capacity of Transformers , author =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[32]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Memorization Capacity of Multi-Head Attention in Transformers , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[33]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Are Transformers with One Layer Self-Attention Using Low-Rank Weight Matrices Universal Approximators? , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[34]
International Conference on Learning Representations (ICLR) , year =
Hopfield Networks Is All You Need , author =. International Conference on Learning Representations (ICLR) , year =
-
[35]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Dense Associative Memory for Pattern Recognition , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[36]
Journal of Statistical Physics , volume =
On a Model of Associative Memory with Huge Storage Capacity , author =. Journal of Statistical Physics , volume =
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[38]
The Twelfth International Conference on Learning Representations (ICLR) , year =
The Expressive Power of Transformers with Chain of Thought , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[39]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems , author =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[40]
Proceedings of the 28th International Conference on Machine Learning (ICML) , pages =
A Three-Way Model for Collective Learning on Multi-Relational Data , author =. Proceedings of the 28th International Conference on Machine Learning (ICML) , pages =
-
[41]
International Conference on Learning Representations (ICLR) , year =
Embedding Entities and Relations for Learning and Inference in Knowledge Bases , author =. International Conference on Learning Representations (ICLR) , year =
-
[42]
Proceedings of the 33rd International Conference on Machine Learning (ICML) , pages =
Complex Embeddings for Simple Link Prediction , author =. Proceedings of the 33rd International Conference on Machine Learning (ICML) , pages =
-
[43]
Proceedings of the 35th International Conference on Machine Learning (ICML) , pages =
Canonical Tensor Decomposition for Knowledge Base Completion , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , pages =
-
[44]
Language models as knowledge bases? , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
work page 2019
-
[45]
Advances in Neural Information Processing Systems , volume=
Representational strengths and limitations of transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
arXiv preprint arXiv:2603.09906 , year=
Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs , author=. arXiv preprint arXiv:2603.09906 , year=
-
[47]
How Do Language Models Compose Functions? , author=. arXiv e-prints , pages=
-
[48]
Do large language models latently perform multi-hop reasoning? , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[49]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Hopping too late: Exploring the limitations of large language models on multi-hop queries , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[50]
Journal of Machine Learning Research , volume=
Knowledge graph completion via complex tensor factorization , author=. Journal of Machine Learning Research , volume=
-
[51]
arXiv preprint arXiv:2601.07372 , year=
Conditional memory via scalable lookup: A new axis of sparsity for large language models , author=. arXiv preprint arXiv:2601.07372 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.